夜雨聆风
夜雨聆风
上一篇我们用AI搭了数据看板——指标金字塔、异常检测、策略实验。单点能力够用了。这一篇往上走一层:把这些能力组装成一个系统。
一、Harness Engineering
2026年初,OpenAI公开了一个内部实验。
一个团队花五个月做了一款产品。应用逻辑、测试、部署、文档、监控——零行手写代码。 全部由AI Agent生成和维护。
人做什么?
设计脚手架。 定义架构边界,编写调度规则,构建反馈回路。他们管这叫 Harness Engineering。
几乎同时,Anthropic发了一篇长文讲同一件事:让AI长时间自主完成复杂任务,单Agent撑不住。必须设计多角色架构——规划者、执行者、评审者各司其职,每阶段有交接物,有独立的质量检查。Anthropic
两家头部公司,同一个结论:AI时代的核心能力,不是"会用AI",是"会驾驭AI"。
Harness Engineering的三条底层原则——
人掌舵,AI执行。 人是架构师和审查者,不碰实现。只做三件事:定方向、设标准、做判断。OpenAI发现执行工作全交给AI之后,人的判断质量反而上升——认知带宽被释放了。
方法论即代码。 分析框架、决策标准、工作流程,不能停留在经验里。必须变成可版本管理、可迭代的显性资产。OpenAI管这叫"plans as first-class artifacts"——像代码一样写下来,签入仓库,定期更新。
反馈回路驱动进化。 必须有独立的评审者,不能让执行者自检。Anthropic的说法是——"调教一个独立的怀疑论者,远比让执行者自我批判容易。"每轮评审结果自动触发下一轮执行,系统靠这个回路越跑越准。
本节小结: Harness Engineering不是一套具体技术,是一组设计原则——人掌舵、方法论即代码、反馈回路驱动进化。这三条适用于任何AI工作系统。
二、三层架构
Harness的核心思路是:你不写实现,你设计脚手架——定义边界、规则和反馈回路,让AI在这个框架里执行。
落到PM的场景,我们的做法是:把分析方法论编码成可执行的Skill,让AI按你的框架跑。你不再亲手做分析,你设计做分析的规则。
PM Copilot就是按这个思路构建的开源项目。一句话记住骨架:
你管方向,Skill管方法,MCP管动手。
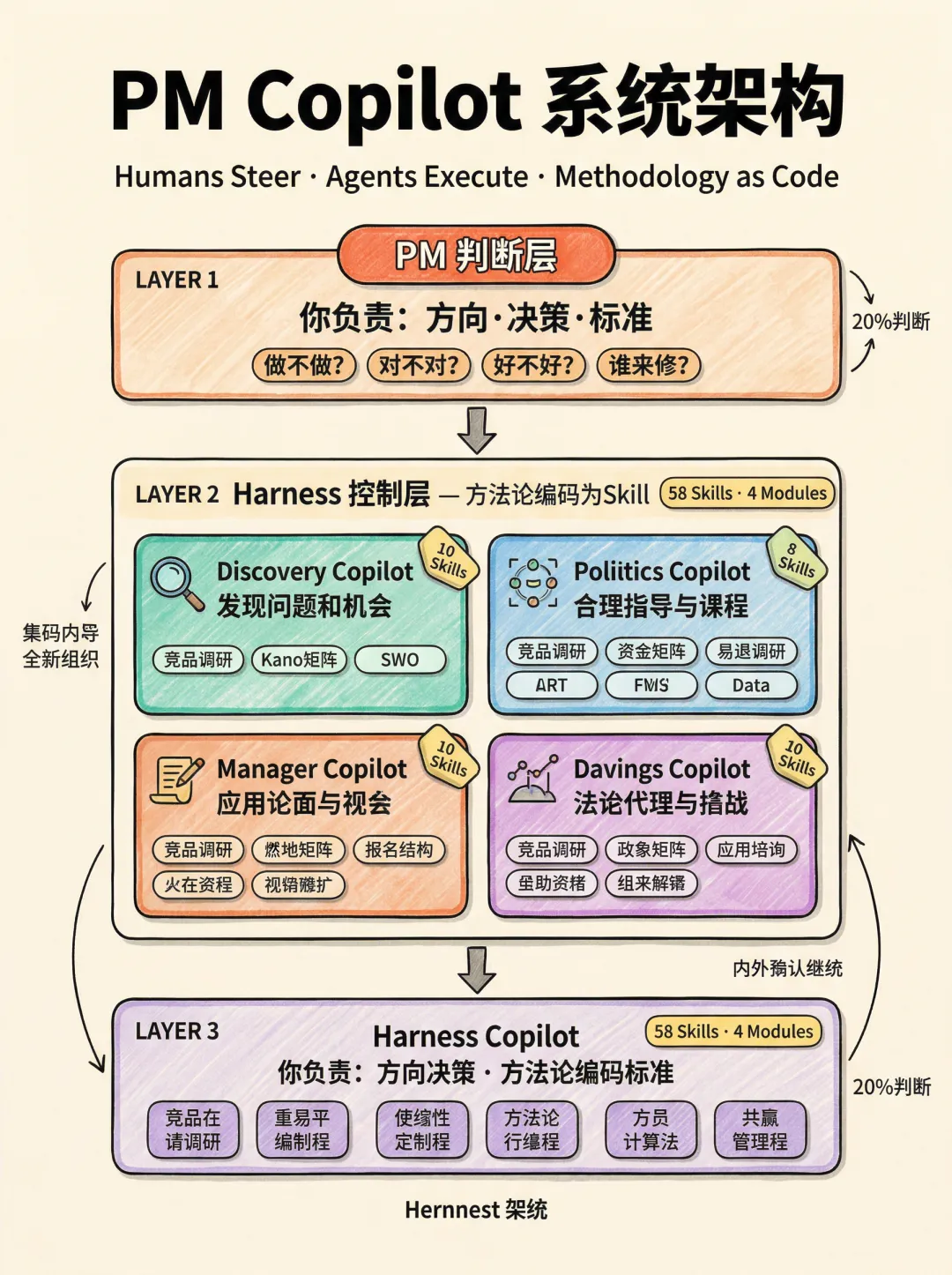
顶层:PM判断层。 系统跑完采集和分析之后,你做四个判断——做不做、对不对、好不好、谁来修。这一层只有你。系统的意义是让你把全部精力集中在这20%的判断上。
中层:Harness控制层。 58个Skill分属4个模块。每个Skill不是一条Prompt,是一段编码好的方法论——定义了用什么框架分析、调什么工具采集、按什么格式输出。
- Discovery Copilot(10个Skill)
——发现问题和机会。竞品调研、Kano矩阵、SWOT、用户画像、市场估算。 - Design Copilot(26个Skill)
——设计解决方案。Brief生成、原型构建、PRD评审、Design Review、AI Slop检测。 - Analytics Copilot(12个Skill)
——数据验证效果。自然语言查数据、看板构建、异常检测、A/B测试分析。 - Feedback Copilot(10个Skill)
——收集用户声音。多渠道接入、自动分类去重、情绪分析、优先级排序。
你以前学方法论是为了自己用。现在学方法论是为了教给AI用。
底层:MCP工具层。 Skill通过MCP协议调用实际工具——搜索用Tavily和RivalSearchMCP,浏览器自动化用playwright-mcp,数据库用PostgreSQL MCP和ToolFront MCP,设计协作用Figma MCP。为什么用MCP?Cursor和Claude Code都用这个协议来接入外部工具。 它是你的开发环境里连接AI和外部能力的标准方式。
有一点要说清楚。PM Copilot目前还不是一个自动运转的Agent系统。OpenAI和Anthropic讲的Harness Engineering,是Agent连续自主跑几个小时,人完全不介入执行过程。PM Copilot还不是这样——它是你手动调用的Skill系统。 但它的架构按Harness原则设计,当Agent能力成熟后可以直接升级。脚手架先搭好,等Agent进场。
本节小结: 三层架构——你管方向(判断层),Skill管方法(控制层),MCP管动手(工具层)。4个模块58个Skill,当前手动调用,架构预留了自动化升级空间。
三、调度与循环
四个模块首尾相连,形成一条流水线——
Discovery → Design → Analytics → Feedback → 回到Discovery
Discovery输出调研结论流入Design。Design出方案上线后进入Analytics。Analytics的数据对照Feedback——数据说转化率涨了,但用户说"找不到入口"。数据和体感不一致就是信号。Feedback把信号推回Discovery,新一轮循环开始。
这个循环靠什么协同?一个文件。
Cursor用户放.cursorrules,Claude Code用户放CLAUDE.md。它定义了系统的身份、能力和运转规则:
# 路由:关键词 → 模块routing:-trigger:"竞品/对手/市场/调研"module:Discovery Copilot-trigger:"原型/设计/PRD/方案"module:Design Copilot-trigger:"数据/指标/转化率/看板"module:Analytics Copilot-trigger:"反馈/用户说/评论/投诉"module:Feedback Copilot# 闭环规则(当前需手动触发,未来可自动化)feedback_loop:-when:Analytics指标偏离基线>10%then:触发Discovery调研原因-when:Feedback同一主题>20次/周then:自动生成Design修复Brief-when:Design标记"已上线"then:触发Analytics拉7日效果数据# 上下文:渐进式披露context:shared_memory:docs/handoff_format:markdowndisclosure:progressive
最后一行的disclosure: progressive来自OpenAI实验的一条关键经验:上下文是稀缺资源。 "把AGENTS.md当目录用,不要当百科全书用。"先给AI摘要,它需要什么再去读什么。
本节小结: 四模块形成闭环流水线,.cursorrules一个文件管全局调度。路由规则决定"谁来干",闭环规则决定"接下来干什么",上下文规则决定"给多少信息"。
四、用原则审视系统
写到这里,系统看起来完整了。三层架构,四模块循环,调度规则。
但Harness Engineering有一条铁律:不要让执行者评审自己。
所以我们反过来,拿OpenAI和Anthropic的原文对了一遍PM Copilot的设计。三个地方露出来了。
第一个问题:Skill开跑之前,没有定义"什么算完成"。
Anthropic有一条关键实践:执行开始之前,必须就"完成标准"达成契约。不是做完再看对不对,是动手之前就定好验收清单。PM Copilot最初只在Design Copilot里有验收标准,但它应该是系统级规则——每个Skill执行前先生成验收清单,执行完对照检查。
第二个问题:只有Design模块有独立评审。
Design Copilot有Design Review和AI Slop检测,本质就是"独立评审者"。但Discovery呢?AI会编造竞品信息——很自信地说某竞品有某功能,实际上没有。没有验证环节,错误信息一路流进Design,污染整个链条。每个模块都需要自己的质量检查点。
第三个问题:模块间传的是对话记录,不是结构化交接。
Anthropic区分了两种上下文传递。Compaction是压缩对话继续跑,噪音累积。Reset是给下一步一张白纸加一份结构化摘要。 长周期任务,Reset更好。每次模块交接应该只传结构化摘要——关键发现、数据来源、建议方向、风险提示。不传对话记录。
三个缺口,补进配置:
# 验收契约execution_contract:before_run:自动生成验收清单after_run:逐条对照检查on_fail:打回重做(最多2次),仍不通过升级给PM# 独立质检quality_check:discovery:playwright-mcp验证关键事实analytics:SQL结果校验(行数/空值/范围)feedback:情绪判断抽样对照原文# 结构化交接(Reset模式)handoff_template:sections: [关键发现, 数据来源, 建议方向, 风险提示]rule:只传摘要,不传对话记录
这件事本身就在演示Harness Engineering——构建系统,用独立标准检查它,发现问题,修复,系统变得更好。 Anthropic说:新模型出来后,重新审视你的Harness,把不再需要的部分拆掉。系统永远在演进。
本节小结: 用Harness原则审视PM Copilot自身,发现三个缺口——缺验收契约、缺独立评审、缺结构化交接。三个补丁对应三条设计纪律:做之前定标准、做完后独立查、交接只传摘要。
五、跑起来
架构和规则到位了,落到日常是一个周级节奏。
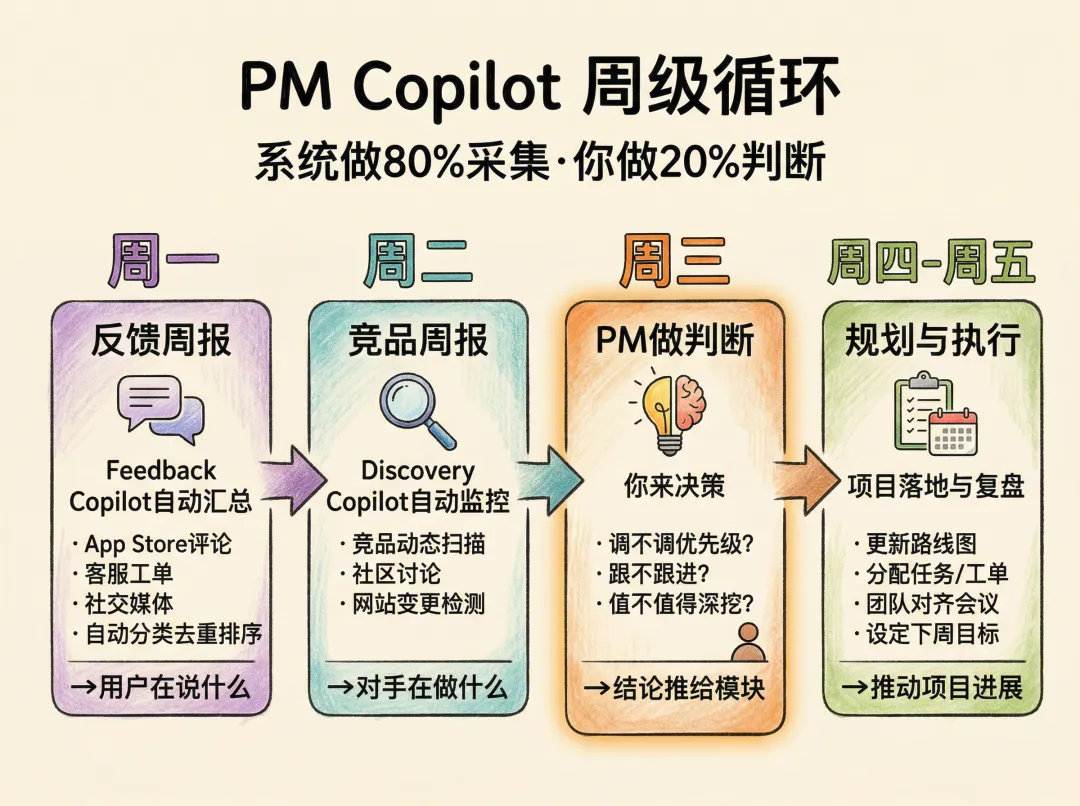
周一:反馈周报。 Feedback Copilot汇总上周用户反馈。自动分类、去重、按频率×强度排优先级。5分钟看完:用户在说什么。
周二:竞品周报。 Discovery Copilot跑竞品监控。搜动态、扫社区、检测网站变更。5分钟看完:对手在做什么。
周三:你做判断。 拿着周一和周二的材料决策——调不调优先级?跟不跟进?值不值得深挖?写下结论推给对应模块。15分钟。
周五:数据周报。 Analytics Copilot生成核心指标报告。异常标红,上线功能效果数据。5分钟看完:数据和体感一致吗?
每周主动投入约30分钟。 目前每步手动触发。未来Agent成熟后,采集和整理可以全自动,你只保留周三的判断。
最后一件事:Skill不是写完就不动了。 每季度审查一次。连续两个季度没用过就删。输出不稳定就调框架。有重叠就合并。OpenAI专门跑了一个"文档清理Agent"定期扫过时规则。一个越来越精简的系统,比一个越来越臃肿的系统好用得多。
本节小结: 四天四个动作一个闭环,每周30分钟。Skill每季度审查,保持精简。
PM Copilot完整代码已开源:github.com/wanghui2323/pm-copilot
4个模块,58个Skill定义,.cursorrules模板,MCP工具配置。

当前它还只是你手动调用的Skill系统。架构按Harness原则设计,等Agent能力到位,它可以进化为自主运转的工作系统。
方法论是代码,Skill越用越准,系统持续演进。
PM Copilot 建设进度
Design Copilot — 26 Skill
Discovery Copilot — 10 Skill
Analytics Copilot — 12 Skill
Feedback Copilot — 10 Skill
.cursorrules 全局调度
周级循环
4/4 模块全部就位。
下一篇预告
系统有了,能力有了。
但有个问题一直没正面聊——当AI能干这么多事,"产品经理"会怎样?
BCG最新数据:AI将重塑50-55%的PM工作内容。岗位需求创三年新高,但初中级下滑42%。
门槛在变。下一篇,最后一篇,聊这件事。
评论区回复 「实操手册」,获取PM Copilot完整配置包 + .cursorrules模板 + 58个Skill清单。