 夜雨聆风
夜雨聆风
很多人第一次看到 OpenClaw 的架构图时,会被它复杂的分层结构吸引住——网关层、插件层、记忆系统、Agent 运行时……但如果继续往下看,往往会在一个词上停下来:Harness。
说实话,Harness 不是一个容易讲清楚的概念。因为它本身就不是一个具体的东西,而是一组设计思路的集合。如果非要给它一个最简洁的定义,我更愿意这么说:Harness 是 AI 应用面向大模型的结构化运行壳,它决定了模型该看到什么、允许做什么、做错了怎么纠正。
但这句话还是太抽象。
今天我们想基于 OpenClaw 出发,结合 OpenAI 和 Anthropic 两篇原文的核心观点,把 Harness 的真实面貌拆开给你看。

Harness 在 OpenClaw 里长什么样
先说 OpenClaw。
如果你研究过 OpenClaw 的架构,会发现它本质上是一个 Gateway-First 的项目。
它上接多个渠道入口——飞书、WebChat、CLI、Telegram,下连会话路由、插件扩展、记忆系统和运行时。
中间那条统一的执行主链路,靠的就是 Harness 层。
具体来说,OpenClaw 的 Harness 承担了这样几件事:
它负责组装 Prompt,把 System Prompt、Skills Prompt、文档、Bootstrap 文件、运行时信息全部拼成最终给模型的提示词。它挂载 Tools 和 Skills,让模型能够调用外部能力。
它接入 Memory 系统,在合适的时机把记忆检索的结果注入上下文。
它处理策略与安全限制,决定模型的调用边界在哪里。
最后,它通过 Provider Adapter 与不同厂商的 LLM API 交互——无论是 Claude、GPT 还是其他模型,Harness 把这些差异屏蔽掉了。
换句话说,没有 Harness 基础理论,OpenClaw 就只是一个“把文本丢给模型”的简单代理。
有了 Harness,它才真正变成了一个可扩展、可控制、可落地的 Agent 运行容器。
但这还是从 OpenClaw 自身的角度在讲。
如果我们把视野拉开,会发现 Harness 这个词在 AI 行业里早就不是 OpenClaw 的专属用语。
它正在变成一个通用概念——描述的是如何给 AI 模型搭建一个完整的运行环境,让它不只是在做单轮问答,而是能够持续地、可靠地完成任务。
为什么 Harness 这个概念突然变重要了
要理解 OpenClaw 和 Harness 的关系,还需要理解另一个背景:模型本身已经足够强,但大家的痛点正在转移。
Anthropic 之前发过一篇关于 Harness 设计的长文,里面有一组实验数据,我认为是理解这个问题最好的切入点。
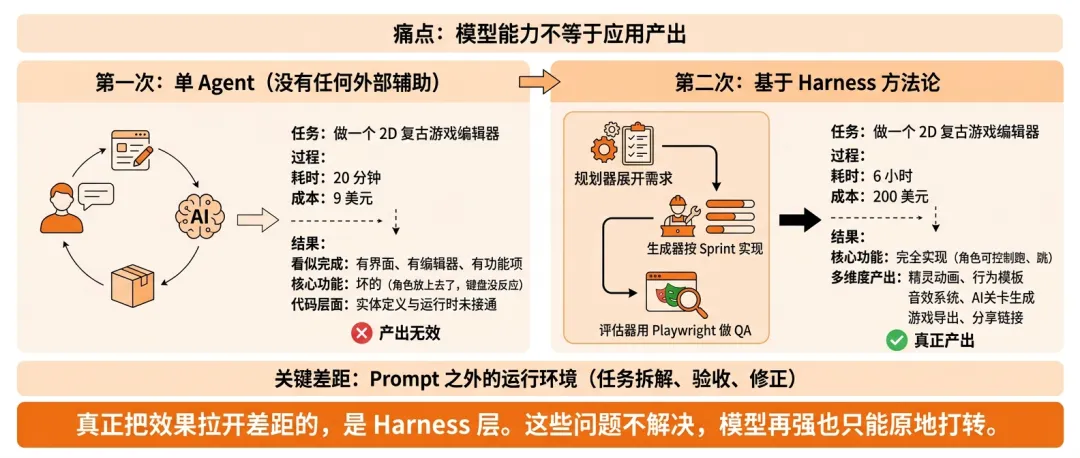
他们用同一句 Prompt——“做一个 2D 复古游戏编辑器”——让同一个模型跑了两次。
第一次,单 Agent,没有任何外部辅助。
跑了 20 分钟,花了 9 美元。
打开之后,界面有了,编辑器有了,看上去功能都做了。
但真正点进去,核心游戏功能是坏的。角色放上去了,键盘没反应。代码层面,实体定义和运行时之间的接线根本没接通。
看起来像是完成了,其实什么都没完成。
第二次,基于 Harness 方法论 ——规划器展开需求、生成器按 Sprint 逐步实现、评估器用 Playwright 跑页面做 QA。
同一个模型跑了 6 个小时,花了 200 美元。
产出多了不止一个量级:精灵动画、行为模板、音效系统、AI 辅助关卡生成、游戏导出和分享链接,全部做出来了。
最关键的是,你真的能控制角色跑和跳。
成本差了 20 多倍,但第一次那 9 美元的产出,严格说不算产出——因为核心功能是废的。
模型没换,Prompt 没换。
变的只是它跑在什么系统里。
这个对比说明了一个很简单的事实:模型的能力不等于应用的产出。 中间差的那一层,就是 Harness。
很多人以为只要选个最强的模型、调调 Prompt,应用效果就能上来。
但实际跑过复杂任务的人都知道,这套玩法的天花板很低。真正把效果拉开差距的,是 Prompt 之外的那套运行环境——任务怎么拆、谁来验收、做错了怎么修正。
这些问题不解决,模型再强也只能在原地打转。
Harness 至少在管四类事情
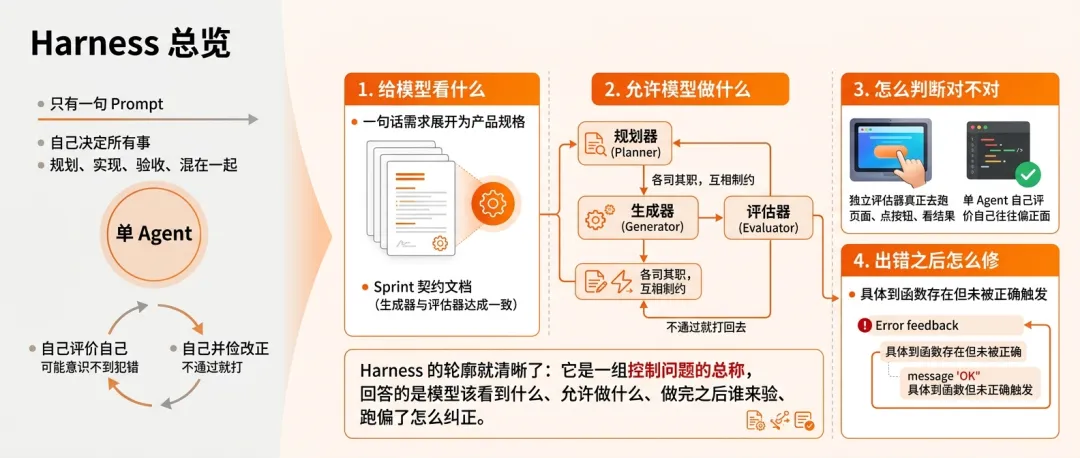
从那组对比往下拆,你会发现单 Agent 和完整 Harness 之间,至少差了四类东西。
第一类:给模型看什么。
单 Agent 只有一句 Prompt。完整 Harness 里,规划器会先把一句话需求展开成详细的产品规格,每个 Sprint 还有专门的契约文档——生成器和评估器先谈好“做到什么算完成”,再动手。
这不是多给一点信息,而是把需求从模糊变得可执行。
第二类:允许模型做什么。
单 Agent 自己决定所有事。
完整 Harness 里,职责被拆开了——规划、实现、验收三件事不该混在同一个脑子里。
Anthropic 把这个拆成了 Planner、Generator、Evaluator 三个角色,各司其职,互相制约。
第三类:怎么判断它做得对不对。
单 Agent 自己评价自己。
但模型在评估自己产出的时候,往往会自信地给出偏正面的评价,即使在人类看来质量只是一般。
所以完整 Harness 里,评估器是独立的,它真正去跑页面、点按钮、看结果,而不是读代码打分。
第四类:出错之后怎么修。
单 Agent 犯了错可能完全意识不到。
完整 Harness 里,Sprint 不通过就打回去,反馈信号具体到“这个函数存在但没被正确触发”。
把这四类事情合在一起,Harness 的轮廓就清晰了:它是一组控制问题的总称,回答的是模型该看到什么、允许做什么、做完之后谁来验、跑偏了怎么纠正。
Harness 内部的三层结构
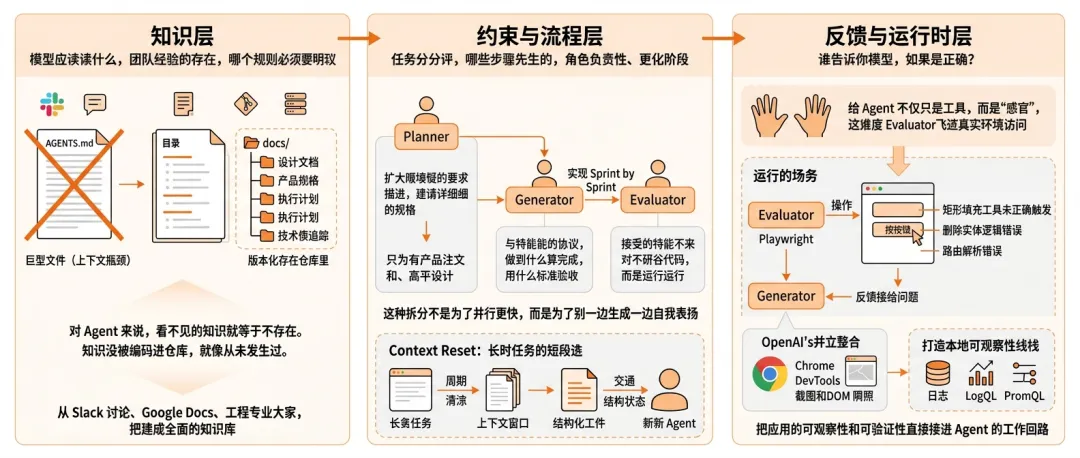
如果继续往下拆,把 OpenAI 和 Anthropic 的两篇原文放在一起对比,会发现 Harness 内部至少有三层——知识层、约束与流程层、反馈与运行时层。
这三层各有侧重,但彼此支撑,缺一不可。
知识层解决的是模型该读什么、团队经验放哪里、哪些规则必须显式可见。
OpenAI 在文章里讲过一个很典型的坑:他们最早试过写一份巨大的 AGENTS.md,把所有规则、约定、指引全塞进去。
结果很快撞了墙——上下文是稀缺资源,大文件会挤掉真正相关的信息;所有东西都标成重点,最后等于没有重点;文档很容易腐烂,而且没法做机械检查。
后来的做法是把 AGENTS.md 改成了一个内容目录,大约 100 行,只告诉 Agent 去哪里找什么。
真正的知识库被拆进结构化的 docs/ 目录里——设计文档、产品规格、执行计划、技术债追踪,全部版本化地存在仓库里。代码仓库本身变成了记录系统。
这里有一个很关键的判断:对 Agent 来说,看不见的知识就等于不存在。
Slack 里的讨论是知识,Google Docs 里的共识也是知识,某个资深工程师脑子里的隐性判断也是知识。但只要它没被编码进仓库,对 Agent 来说就像从未发生过。
知识层不补,模型永远只能靠临场发挥。
约束与流程层解决的是任务怎么拆、哪些步骤必须先发生、哪个角色负责什么、什么情况下该切换阶段。
Anthropic 对这一层的处理最有代表性。
他们的做法是把系统拆成 Planner、Generator、Evaluator 三个角色。Planner 负责把模糊需求扩成详细规格,而且刻意只聚焦产品上下文和高层设计,不去规定细粒度的技术细节——因为他们发现,如果规划器一开始就在实现细节上犯了错,错误会级联传导到下游所有实现中。
Generator 负责真正实现,按 Sprint 逐个做 feature,每个 Sprint 开始前要和 Evaluator 谈好一份契约——做到什么算完成,用什么标准验收。
Evaluator 负责验收,它不是读代码打分,而是真正去跑。
这个结构表面上像多 Agent 编排,但背后的工程含义更重要:原本混在一个模型里的几种职责,被拆成了不同的流程角色。这种拆分不是为了并行更快,而是为了别一边生成一边自我表扬。
Anthropic 还补了一个很关键的点——context reset。
长任务里光靠原地压缩历史还不够,有些模型会随着上下文越来越满,开始出现“提前收尾”或“失去一致性”的问题。
所以他们会定期清空上下文窗口,重新启一个新会话,再通过结构化工件把状态交接给下一个 Agent。这个设计听上去笨,但很工程。
反馈与运行时层解决的是模型做完之后,谁来告诉它对不对。
这是 Harness 里最容易被低估的一层。很多人对 Harness 的理解停在“给模型配上工具”,但工具本身不是反馈,工具只是让模型有了手,反馈是让它有了感官。
Anthropic 文中让我印象最深的地方就在这里。
他们发现真正拉开差距的,不只是让模型多做一轮,而是给它一个足够挑剔、能接触真实环境的 Evaluator。
这个 Evaluator 会用 Playwright 真正去跑页面、点按钮、看行为、发现没接上的地方,再把这些问题作为反馈交给 Generator。
原文里列了几个 Evaluator 实际发现的问题:矩形填充工具的 fillRectangle 函数存在但没被正确触发;删除实体只设置了 selectedEntityId 但没设置 selection;FastAPI 路由顺序写反导致 reorder 被解析成整数返回 422。这些不是“看代码打分”能发现的问题,它们只有在真正跑起来、点进去之后才会暴露。
OpenAI 对反馈层的做法方向一致,但路径不同。
他们把 Chrome DevTools 协议接入 Agent 运行时,让它能截图、查 DOM 快照、驱动页面导航;把日志、指标、追踪做成本地可观测性堆栈,Agent 可以直接用 LogQL 查日志、PromQL 查指标。
做的不是“再多给点说明”,而是把应用的可观察性和可验证性直接接进 Agent 的工作回路。
结语
回到最开头的问题:OpenClaw 和 Harness 是什么关系?
现在可以给一个更清晰的答案了。
OpenClaw 是一个 Gateway-First 的 Agent 运行时框架,而 Harness 是它面向大模型的那一层方法论。
如果你正在做 AI 应用相关的事情,花时间想清楚 Harness 这层该怎么搭,可能比纠结用什么模型、调什么 Prompt 更有价值。
差距往往不在模型,在系统。

🔗 欢迎加入【臻成AI大模型】学习交流👇


点击下方蓝字关注臻成AI大模型
