 夜雨聆风
夜雨聆风他们把Claude 3.7 Sonnet放进SWE-bench测试时,只给了两个工具:一个bash命令行,一个最基础的文件编辑器。没有复杂的文件检索系统,没有精心编排的Prompt流程,没有MCTS树搜索,也没有best-of-N拒绝采样。
结果?70.3%的真实GitHub issue解决率。
一年前,首个"AI程序员"Devin凭借厚重的外部框架才拿下13.86%。而到2026年2月,Claude 4.5 Opus 在同样极简的测试条件下,把公开纪录推高到了76.8%。
社交媒体上还有传闻——据说Anthropic内部有个叫 Mythos 的预览模型,已经逼近了94%。真假难辨。但Anthropic用70.3%到76.8%的极简实验告诉我们:真正重要的不是数字本身,而是模型不再需要外部导演了。它自己在报错和修正中,学会了怎么当工程师。
这不是某个产品的胜利,而是一场关于AI能力构建逻辑的深层革命。
一、两次跃迁:从"吃书"到"试错"
第一次跃迁:互联网被"吃光"了
传统大模型的训练逻辑很朴素:把人类写下的书、论文、代码、网页全塞进去,让模型记住模式。
但这套方法的天花板已经触手可及。高质量文本数据即将耗尽。Epoch AI预测,到2026年预训练将面临严重的"数据墙"。更关键的是,静态文本里只有正确答案,没有人会把自己"试错了127次的心路历程"写下来。
背得多,不等于会解决问题。2024-2025年,研究界达成共识:预训练不再是高潮,后训练(Post-training)才是现代AI能力的引擎。
第二次跃迁:从"外包工程"到"内化本能"
当模型需要"像人一样解决问题"时,业界的第一个反应是:加框架。
• 人工编排的思维链流程图
• 嵌入检索+Rerank的文件定位系统
• MCTS树搜索、best-of-N拒绝采样
• 成百上千行的Prompt工程
这些方法短期内有效,但本质上是在用静态的人类工程,弥补动态模型能力的不足。
一个尖锐的问题随之浮现:如果模型只能靠外部脚手架才能表现得像Agent,那它真的具备Agent能力吗?
2024年之后,答案开始变得清晰。模型开始在真实环境中产生海量执行轨迹——目标、感知、推理、行动、反馈、修正——并通过强化学习(RL)和过程监督,将这些策略逐步内化为自身的本能。
这不是简单的性能提升,而是AI能力建设的第二次跃迁。
二、轨迹训练:让模型"开窍"的秘密
Agent执行轨迹不是简单的"你问我答",而是一个完整的事件序列:
目标 → 环境感知 → 推理规划 → 行动执行 → 环境反馈 → 反思修正 → 结果验证
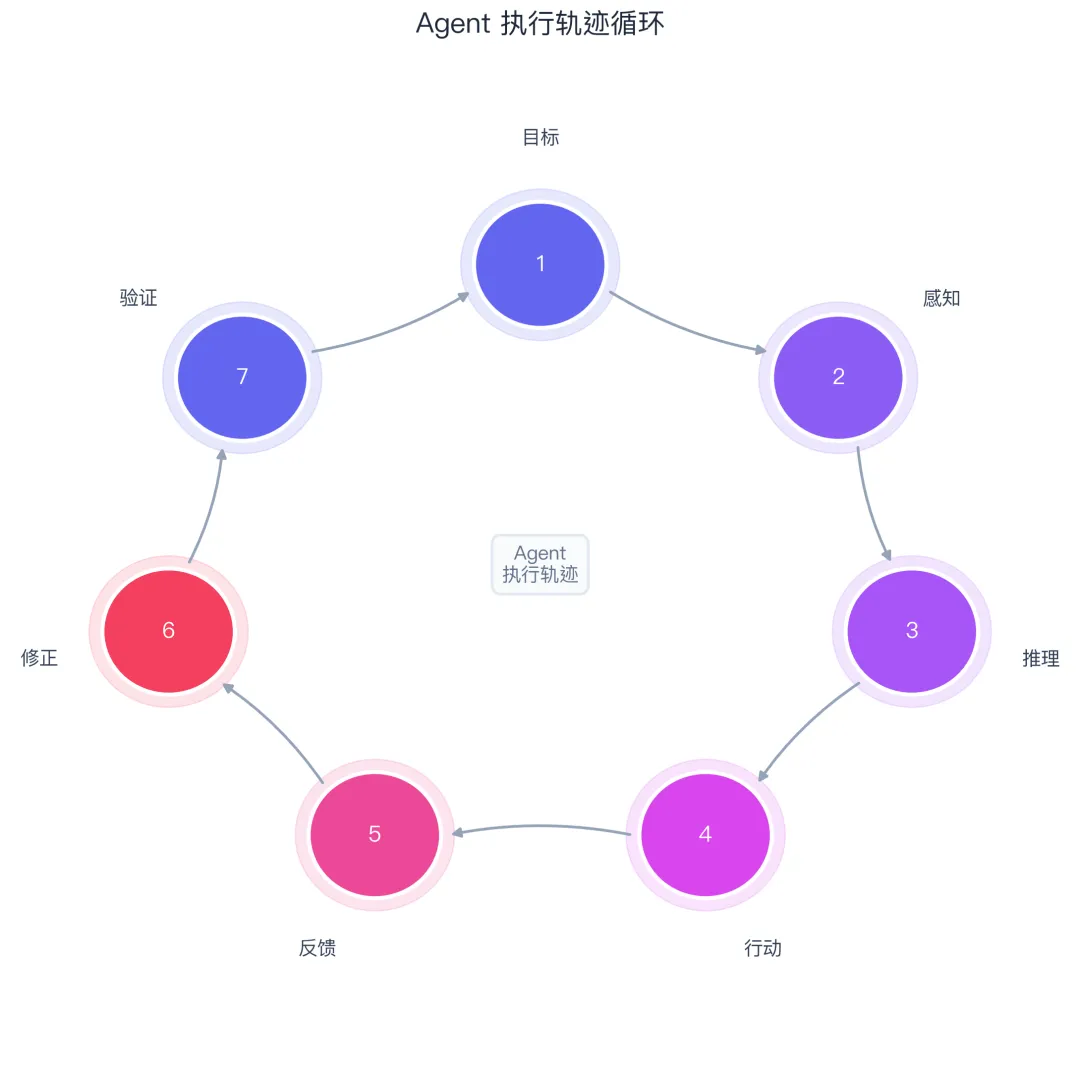
这个链条里藏着纯静态文本无法提供的关键信号:思维链是怎么推导的、工具使用决策何时做出、走错了路如何掉头、以及模型对自己思考的再思考。
为什么轨迹能让能力"内化"?
第一,信息密度远超静态文本。 一篇数学论文可能只有500字,但作者真实的思考过程——尝试了3种辅助线、否定了2个错误假设、回溯了1次——等效于5000字的决策信息。轨迹数据把这座"冰山"完整地记录了下来。
第二,错误比正确答案更值钱。 静态数据集里全是 polished 的正确答案,但真实轨迹里充满了某条路径走不通、编译报错后如何调整、测试失败后怎么排查。没有经历过足够多"犯错-修正"循环的模型,永远无法将Agent能力真正内化。
三、最好的证明:AI编程能力的两年跃迁
数据不会说谎
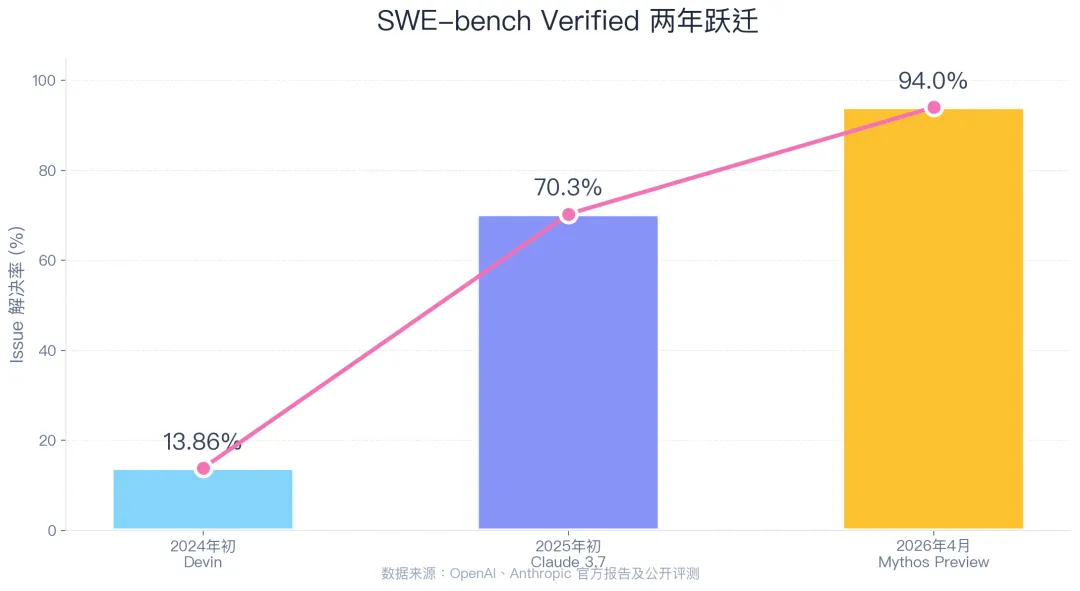
SWE-bench Verified,这个评估AI修复真实GitHub issue能力的黄金标准,两年内发生了惊人的跃迁:
• 2024年初:Devin拿到13.86%,靠厚重外部框架(Cognition Labs)
• 2025年初:Claude 3.7 Sonnet在极简脚手架下达到70.3%,OpenAI o3达到72%
• 2026年2月:Claude 4.5 Opus在公开 leaderboard 上达到76.8%,Gemini 3 Flash 追到 75.8%(数据来源:swebench.com)
截至2026年4月,公开 leaderboard 的最新纪录仍停留在2月这批数据。但趋势已经足够清晰:顶尖模型在"不加导演"的极简测试条件下,集体逼近了75%-76%的区间。
模型正在把一次次编译报错、测试失败、策略回溯,内化为不需要人类编排的本能反应。
为什么编程是最理想的实验室?
编程领域为轨迹训练提供了得天独厚的条件:
1. 可验证性最强:编译器和测试套件提供即时、自动、高可信的反馈
2. 交互密度最高:开发者与AI的"提示→生成→运行→修正"循环最频繁
3. 环境反馈最丰富:报错信息、堆栈跟踪、日志,都是结构化的监督信号
4. 合成数据最容易:在Docker沙箱里,模型可以自我对弈,自动生成海量轨迹
OpenAI o3在SWE-bench任务中,平均要执行37次容器化shell交互,复杂修复甚至超过100次。Greg Brockman更透露,在极端任务中,o3曾连续发出600次工具调用。到了2026年,这种长程交互已成为头部模型的常态——"行动→观察→再行动"被内化为自身的决策本能。
在代码领域率先验证的"试错-内化"范式,将在数学、科研、商业分析等领域快速复制。
四、Claude Code的"瘦身"史:最佳商业案例
没有比Claude Code的迭代更能清晰地展示"外部框架→模型本能"这条内化路径了。
早期:靠外部框架硬撑
根据Anthropic工程团队的回忆,最早的Claude Code极其简陋。它不能读取文件,不能执行bash命令,只能通过AppleScript做一些简单交互。那时的模型完全没有内化的Agent能力,任何复杂任务都需要人类工程师 handcrafted 的外部逻辑。
到了Claude 3.5 Sonnet时代,模型获得了屏幕感知和光标控制能力,但"何时调用工具、如何组合、错了怎么办",很大程度上仍由框架说了算。
2025年初:框架开始"退位"
这是转折点。Anthropic在测试Claude 3.7 Sonnet时,采用了"minimal scaffolding"策略:只给模型最基本的两个工具(bash命令行 + 字符串替换编辑器),文件定位、Bug分析、修复规划、测试决策,全部交给模型自己完成。
结果:70.3%的issue解决率。
这意味着,大量原本需要外部框架实现的策略——如何浏览代码库、如何定位Bug、如何根据测试反馈调整——已经被模型通过海量开发轨迹训练,内化为自身的推理本能。外部框架从"导演"退位为"舞台"。
2025-2026:舞台"扩容"
进入2026年,这条"内化"路径变得更清晰了。2026年2月,Anthropic 连发两弹:先是 Claude Opus 4.6(2月5日),然后是 Claude Sonnet 4.6(2月17日)。
看看公开 benchmark 上的成绩单:
• SWE-bench Verified:Claude 4.5 Opus 创下公开纪录 76.8%。同月发布的 Claude Opus 4.6 在 leaderboard 上略低一个百分点,但更像是单一测试配置下的正常波动——Anthropic 官方评估中,4.6 的综合 agentic 能力是全面超越 4.5 的
• Terminal-Bench 2.0(agentic 编程评估):Claude Opus 4.6 最高分
• GDPval-AA(高价值知识工作):Opus 4.6 比 GPT-5.2 高出约 144 Elo 分
• 长上下文:Opus 4.6 首次在 Opus 级别支持 100万 token 上下文,在 1M token 的 MRCR v2 测试中得分 76%,而 Sonnet 4.5 仅 18.5%
这些数字说明一件事:模型不是被框架"教会"了怎么做,而是自己在海量试错-修正的轨迹中,内化了策略。
于是,Claude Code 这个框架的使命彻底变了。它不再是"导演",而是在重构边界:新增了 Channels、Agent Teams、compaction、adaptive thinking 等能力。正如 Anthropic 所说:
"Claude Code 是为 AI 能力将去往的方向而构建的,而非为发布时的能力水平。"
五、不止于代码:这场内化革命能走多远?
代码只是第一块试验田。轨迹训练+内化这个底层逻辑,本质上不取决于"会不会写代码",而取决于一个领域能否构建起足够密集、足够可信的"行动-反馈-修正"闭环。
按照"可验证性梯度",所有知识工作可以被划分为三类:
| 高确定性 | ||
| 半确定性 | ||
| 高关系性/高主观性 |
编程不是终点,而是起点。 决定一个领域何时被颠覆的,是它能否回答三个问题:
1. 行动后能否获得反馈?
2. 反馈能否被低成本地验证?
3. 验证信号能否被规模化地收集并回灌到训练流程中?
能回答"是"的领域,都将成为下一块"内化试验田"。
六、对你我的启示:选工具的新逻辑
既然"使用即训练、训练即内化"是核心规律,那选择AI工具时,除了看当前能力,更要看这四点:
| 可验证性 | |
| 闭环密度 | |
| 数据回流 | |
| 框架弹性 |
个人策略:既做轨迹生产者,也做驾驭者
你的每一次有效交互,都在参与塑造未来的AI。但比"用得勤"更重要的,是保持人的主导权:
1. 优先用能闭环的工具:记录反馈、修正和验证的应用
2. 在可验证领域深度使用:编程、数据分析是你和AI共同成长最快的领域
3. 给清晰的约束:目标明确、边界清晰、反馈及时
4. 关注"框架弹性":好产品会随模型能力增强而简化流程,而不是越做越重
5. 守住问题定义权:AI越擅长执行,人越要专注于"问对问题"和"定义终点"
6. 保持批判性验收:训练自己识别幻觉和逻辑漏洞的判断力
7. 主动设计人机分工:重复性工作交给AI,创意、权衡和决策留给人
写在最后
Agentic能力正在从外部工程框架,内化为模型本能。这场转移的起点是代码,但绝不会止于代码。它已经蔓延到数学推理、数据分析、科学实验,正在叩击法律、医疗、商业分析的大门。
驱动这一切的核心燃料,是每一次真实的交互——每一次提示、每一次运行、每一次报错、每一次修正——汇聚成的Agent执行轨迹。基座模型的竞争,已然从"谁的数据储量更大",转向"谁的轨迹质量更高、学习闭环更密"。
真正塑造智能的,不是人类已经知道什么,而是人类如何解决问题——尤其是如何在试错、反馈和修正中逼近目标。
使用即训练,交互即内化,轨迹即资产。
你最近在用AI工具时,有没有某个瞬间觉得它"越来越不用教就会了"?欢迎在评论区聊聊你的观察。
