 夜雨聆风
夜雨聆风AI编程领域的各种文章,大多是吹嘘AI工具的强大,满屏都是几分钟开发个新App,却没人提“怎么维护那个跑了十几年的老系统”。一线的程序员们都很清楚,开发的难点从来不是搞新系统,而是那些运行了十几年,依赖链深度腐化,核心模块高度耦合的老旧系统,在这样的系统下维护并开发新的功能,人力成本极其高昂。真正让AI深入这样的场景,解决那些错综复杂的历史遗留问题,才能是AI编程的核心价值。
那么,是模型能力不够,还是工程化水平还没跟上?AI擅长解决的是标准问题,而老旧系统,本质上是一堆非标准问题的叠加体。
这样的系统往往不是设计出来的,而是在无数次线上事故、临时需求、客户定制中,一点点修补出来的。走进这样的系统,就像走进了一座没有地图的地下迷宫,里面的文档早就在几次人员更迭中失传了,即便翻出来几份,多半也和现有的代码对不上。那些写在代码里的数层嵌套if-else和不知道哪位前任开发才知道的业务潜规则,根本不会出现在AI的上下文窗口里。
而且,AI驱动开发的精髓在于“反馈循环”——写代码,运行测试,报错,再修改。但在老旧系统里,这套逻辑通常跑不通。这类系统的自动化测试往往是一片荒漠,修改一个A模块的变量,可能会让几万行代码外的一个Z流程突然瘫痪。在没有高覆盖率测试保护的情况下,AI的每一次优化和重构都是在裸奔,你敢让这样的改造上线么?
这里其实还有一个更隐蔽的问题,即便你把测试补上了,也要想清楚,你是在验证“对不对”,还是在验证“和现在一不一样”。老系统很多行为本身就不合理,但它已经成为线上事实。如果没有区分这两层,AI很容易自作主张改掉那些业务上早已默认的特殊逻辑,最终引发更隐蔽的事故。老系统给我们的不是正确答案,而只是当前答案。
既然我们都知道老旧系统是AI的噩梦,那我们总不能永远只让AI停留在写新逻辑,接管这些老旧系统,不仅需要AI能力的进化,更需要一套不同于新项目开发的技术方案。
第一步,先给屎山补全测试用例
很多老系统之所以成了禁区,是因为没人知道改了一行代码,会导致哪个遥远的业务逻辑崩盘。AI介入的第一件事,不应该是改代码,而是补全自动化测试。AI的强项在于读懂逻辑,通过全量扫描旧代码,它能反向推导出业务分支,并自动生成覆盖各种边界条件的单元测试。当然,别指望AI能够把事情都干完,测试用例必须要熟悉系统开发者来review,确认用例的正确性和全面性。
我更倾向于把重点放在外部接口测试上,而不是内部方法的单元测试,因为我们接下来会重写系统。但这里还有一个前提,要把核心数据的含义搞清楚。很多老系统的问题不在代码中,而在数据中:字段语义混乱、历史脏数据横行、同一张表被改过无数次结构。如果不先对数据做基本的梳理和约束,AI重写出来的逻辑很容易在真实数据面前失效。老系统的问题,代码只占一半,另一半在数据里。
第二步:不要缝缝补补,要用AI喜欢的架构重写
面对严重腐化的系统,继续在旧框架里修修补补,往往是在技术债上叠加利息,永远都还不完,只会让AI在噩梦中跌入深渊。更大胆而合理的策略是,让AI按照它最舒服的方式,用现代的架构重写。对,不是重构,是重写。
但重写并非盲目冒进,毕竟改造历史逻辑的风险极高。可以让AI配合开发人员,从另一个维度分析代码库,不是看具体的代码逻辑,而是看耦合度和脆弱点,分析出哪部分代码最容易出Bug,哪部分代码已经成了无人能懂的死区,分别做上标记,这样在进行重构时,也能尽量降低风险,搬不动的古董逻辑也不要死搬,把它们标记隔离出来,区别处理。
第三步:通过线上流量,进行有效的验证
重写完了,除了通过接口测试兜底,“线上流量验证”是效果最好的方式,特别是在数据层面的真实性。我们可以通过AI辅助构建一套双跑系统:将线上的真实请求同时拷贝一份发送给AI重写的新逻辑,但只记录结果,不实际生效。一方面做数据对账,对比新老系统的返回结果和数据变更;另一方面做差异预警,一旦出现不一致,就回溯定位问题。这种基于真实环境的验证,比任何测试都更接近系统的真实状态。
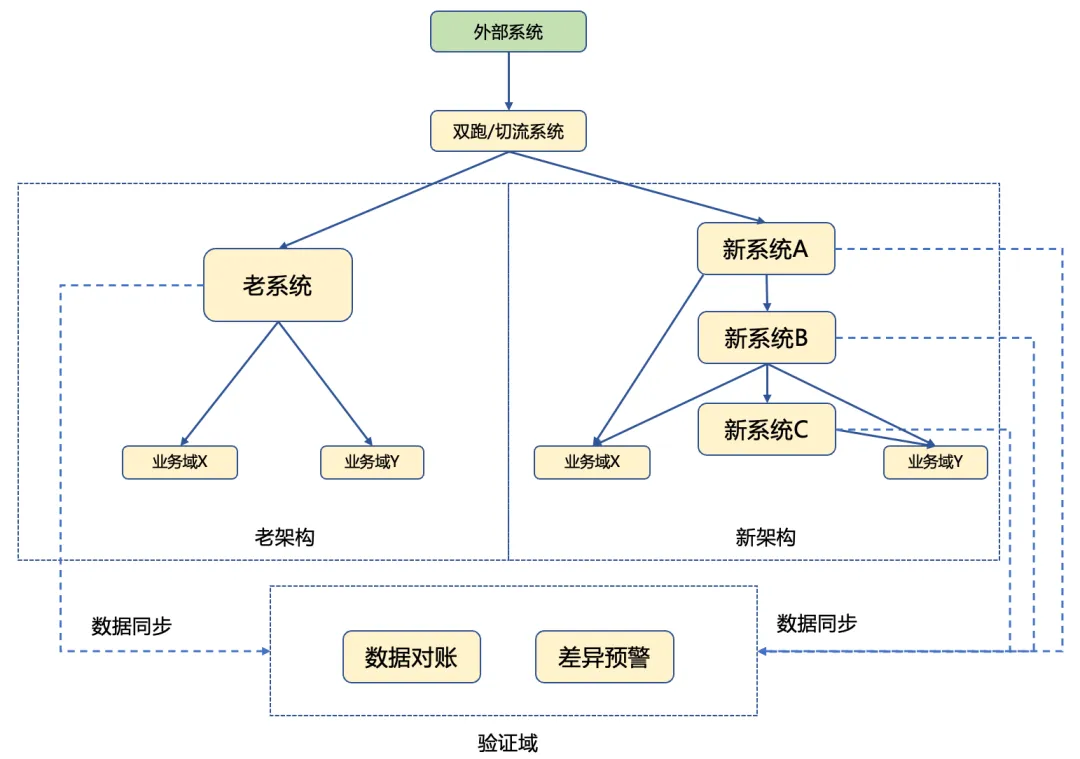
在迁移过程中,也不必追求一步到位。可以借助AI分析系统的耦合结构,识别出老系统里最容易剥离的边缘模块,自动生成切流逻辑,把流量一点点导向新重构的服务。这种渐进式的迁移,比一次性推倒重来风险低得多。
另外,在AI驱动的软件工程新范式中,我们必须修正一个长久以来的观念:文档不是代码的附属品,文档本身就是生产力。
程序员们最讨厌两件事:一是写文档,二是别人不写文档。但在AI时代,这种心态必须转变。当前流行的AI开发范式:spec-kit和Harness,都极为重视文档的结构化管理。Markdown之所以流行,就是它的格式很适合描述结构化的内容。
老旧系统最可怕的不是代码乱,而是逻辑断代。一个看似愚蠢的if-else背后,可能隐藏着六年前某个大客户的定制需求,或者是为了绕过当年某个依赖方的逻辑问题,搞了个临时方案,结果这个临时方案变为了永久方案。
在没有AI的时代,这些背景知识沉没在成千上万条git提交记录、PRD原型、陈旧的往来邮件,甚至散落在钉钉聊天记录的碎片里。我们可以借助AI扫描这些非结构化数据,梳理出一份历史决策树,告诉后来者,这里不要动,因为这是六年前为了解决哪个场景问题而打的补丁。
要让AI实现从逻辑设计到代码生成的全托管,文档与代码的同步就十分必要。在传统开发中,代码一上线,文档就过时了。但在 AI 时代,文档就是逻辑的准确来源。我们要让 AI 在修改代码时同步更新文档,反之也是如此。
以上说的这些,并不只是理论,而是我们在真实老旧系统改造中一轮一轮踩坑、反复验证后沉淀出来的方法。在实际项目中,我们用这套方式完成过多次老系统的迁移:没有大规模停机,没有灾难级事故,通过测试兜底、流量双跑和渐进切换,把一套原本没人敢动的系统,一点点平滑替换成新的架构。
更重要的不是迁移成功这件事本身,而是迁移完成之后,系统的状态发生了根本变化,很多过去需要反复试错的改动,现在可以在变更前就被识别风险;很多过去只能靠老员工口口相传的隐性规则,现在已经沉淀成结构化的能力。
当系统不再依赖某个维护屎山代码的开发,而是变成能够被我们和AI共同理解和演进,这才是AI真正接管老系统的开始。
