 夜雨聆风
夜雨聆风你有没有这样的经历?
昨天刚跟 AI 助手聊了两个小时,把项目背景、业务需求、个人偏好交代得一清二楚。今天再打开对话框,它却像第一次见面一样,茫然地看着你:"请问有什么可以帮您的吗?"
这种「一夜醒来就失忆」的现象,正是今天我们要深入探讨的话题。
作为一名技术内容创作者,我每天都在和各种 AI 工具打交道。我发现很多用户对 AI 的记忆机制存在误解——有些人以为 AI 真的在"学习"他们,有些人则对"失忆"感到困惑甚至不满。
这篇文章,我将从技术架构的角度,为你揭开 AI 助手记忆机制的底层逻辑。我们会以 OpenClaw 为例,深入剖析 Session 隔离、无状态设计、持久化策略等核心概念。读完之后,你不仅会理解为什么 AI 会"失忆",还会知道如何让 AI 真正"记住"你。
一、现象:为什么每次对话都像第一次见面?
1.1 用户的典型困惑
让我们先看几个真实的用户场景:
场景 A:项目协作的挫败
"我花了整整一下午,把公司的技术架构、团队分工、项目排期都告诉了 AI。让它帮我写一份技术方案。结果第二天再问进度,它完全不知道我在说什么,所有背景都要重新讲一遍。"
场景 B:个人偏好的遗忘
"我明确告诉过 AI,我喜欢代码注释用英文,变量命名用蛇形命名法,函数不要超过 20 行。第一次它照做了,第二次又变回中文注释、驼峰命名、超长函数。"
场景 C:上下文的中断
"我们正在讨论一个复杂的多步问题,我已经提供了前三步的推导过程,正要进入第四步。突然网络抖动,对话刷新。回来后,AI 说:'抱歉,我没有看到之前的对话记录。'"
这三个场景,分别对应了 AI「失忆」的三种典型表现:长期记忆缺失、偏好记忆不稳定、短期上下文丢失。
1.2 用户的心理预期 vs 现实
为什么会出现这种落差?核心在于用户对 AI 的「记忆」存在认知偏差。
用户的这些假设并非无理取闹。事实上,很多消费级 AI 产品(如 ChatGPT Plus 的 Memory 功能、Claude 的 Projects)正在努力缩小这一落差。但在理解这些高级功能之前,我们必须先理解「无状态」这一基础架构设计。
1.3 问题的本质:记忆的三层模型
为了更准确地描述 AI 的「失忆」问题,我提出一个记忆三层模型:
┌─────────────────────────────────────────────────────────┐│ 记忆的三个层次 │├─────────────┬─────────────┬─────────────────────────────┤│ 上下文记忆 │ 会话记忆 │ 持久化记忆 ││ (Context) │ (Session) │ (Persistent Storage) │├─────────────┼─────────────┼─────────────────────────────┤│ 当前对话的 │ 本次会话的 │ 跨会话长期保存的 ││ 多轮消息 │ 临时状态 │ 用户画像/偏好/知识 │├─────────────┼─────────────┼─────────────────────────────┤│ 易失性:高 │ 易失性:中 │ 易失性:低 ││ 重启即丢失 │ 会话结束丢失 │ 显式删除才丢失 │└─────────────┴─────────────┴─────────────────────────────┘上下文记忆(Context Memory)
作用:维护当前对话的多轮消息历史,让 AI 能理解指代、承接上文 特点:容量有限(通常 4K-128K tokens),随对话进行会滑动窗口或压缩 风险:超长对话时,早期信息可能被截断或摘要丢失细节
会话记忆(Session Memory)
作用:在本次会话内维护临时状态,如已加载的技能、用户的临时偏好、对话的元数据 特点:服务端内存中保存,会话结束(如断开连接、超时)即释放 风险:用户以为"我已经告诉过 AI",但其实是上次会话的事了
持久化记忆(Persistent Memory)
作用:跨会话长期保存用户信息,如用户画像、长期偏好、历史对话摘要、重要的知识片段 特点:存储在数据库、文件系统或向量存储中,需要显式读写 风险:涉及隐私和权限控制,需要用户授权,且有存储成本
理解了这三层记忆的区别,你就能准确诊断"失忆"问题到底出在哪一层:
上下文截断 → 当前对话太长,早期信息被挤掉了 会话重置 → 新会话开始,上次的内容在内存里,这次没有 持久化缺失 → 根本就没存到硬盘,或者存了没加载
接下来,我们将以 OpenClaw 为例,深入它的技术架构,看看它是如何管理这三层记忆的。
二、原理:Session 隔离与无状态设计
2.1 什么是「无状态架构」?
要理解 AI 为什么会"失忆",我们必须先理解一个架构设计的核心概念:无状态(Stateless)。
在传统的有状态应用中,服务器会为每个连接维护一份状态信息。比如,当你登录一个网站后,服务器会在内存中保存你的登录态、购物车内容、浏览历史等。这种方式的优点是响应快,因为所有信息都在手边;缺点是扩展难,一旦服务器崩溃或需要扩容,状态迁移是个大问题。
而无状态架构则采取了截然不同的思路:服务器不保存任何客户端的状态信息。每个请求都必须是自包含的(self-contained),携带着所有必要的信息。

图1: 架构图
这张图清晰地展示了两种架构的本质区别:
有状态架构中:
客户端第一次请求后,服务器在内存中创建了 Session 后续请求必须落到同一台服务器,否则就找不到状态 扩容困难,某台服务器宕机会导致上面的 Session 全部丢失
无状态架构中:
第一次请求后,服务器返回一个 Token(如 JWT) 客户端后续请求携带这个 Token,任何服务器都能验证并处理 易于水平扩展,单台服务器宕机不影响整体服务
现代大规模互联网服务(如 Google、AWS、微服务架构)普遍采用无状态设计,因为它解决了扩展性和高可用性的核心痛点。
2.2 为什么 AI 系统普遍采用无状态设计?
理解了无状态架构的优势,我们来看看为什么主流的 AI 对话系统(包括 OpenAI、Claude、OpenClaw 等)都采用这种设计。
原因一:水平扩展是刚需
AI 对话系统的流量波动极大。平时可能只有几千用户在线,但某个热点事件爆发时,可能瞬间涌入几十万人。如果采用有状态设计,扩容时需要迁移 Session 状态,这是极其复杂且容易出错的。
无状态设计下,新启动的服务器实例可以立即加入集群处理请求,不需要关心之前的状态在哪里。这满足了 AI 服务"弹性伸缩"的核心需求。
原因二:高可用性要求
AI 服务一旦宕机,影响范围巨大。无状态架构天然具备故障隔离能力:某一台服务器挂了,负载均衡器会自动把流量切走,用户几乎无感知。如果是有状态架构,那台服务器上的所有 Session 都会瞬间丢失,正在对话的用户会立刻看到"会话已过期"的提示。
原因三:成本控制考量
AI 对话的状态(包括消息历史、上下文窗口)通常很大。一个长对话可能包含几十条消息,占用数万 tokens。如果要在服务器内存中维护数百万用户的 Session,这需要极其昂贵的内存成本。
无状态设计下,状态可以存储在客户端(如浏览器 localStorage)、共享缓存(如 Redis)或数据库中,服务器只保留最小化的临时状态,大大降低了成本。
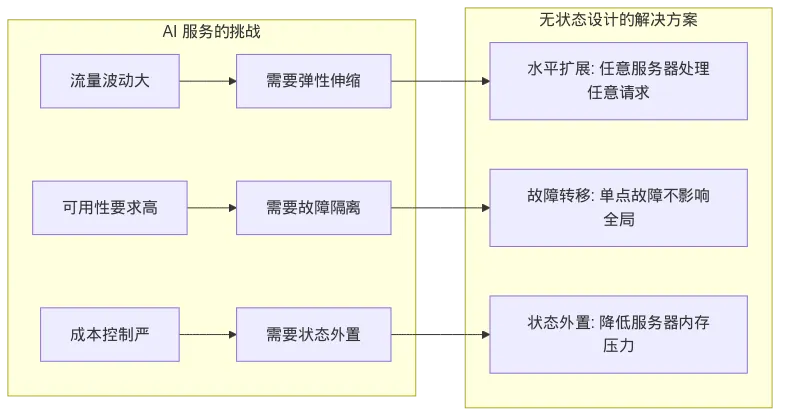
图2: 架构图
这张图概括了 AI 服务面临的三大挑战,以及无状态设计如何针对性地解决它们。
2.3 Session 隔离机制详解
现在我们来深入一个核心概念:Session 隔离(Session Isolation)。
Session 隔离是无状态架构下的一种安全和管理机制。它的核心思想是:不同用户的对话必须完全隔离,同一用户的不同对话也应该相互独立。
让我们用 OpenClaw 的架构来具体说明:
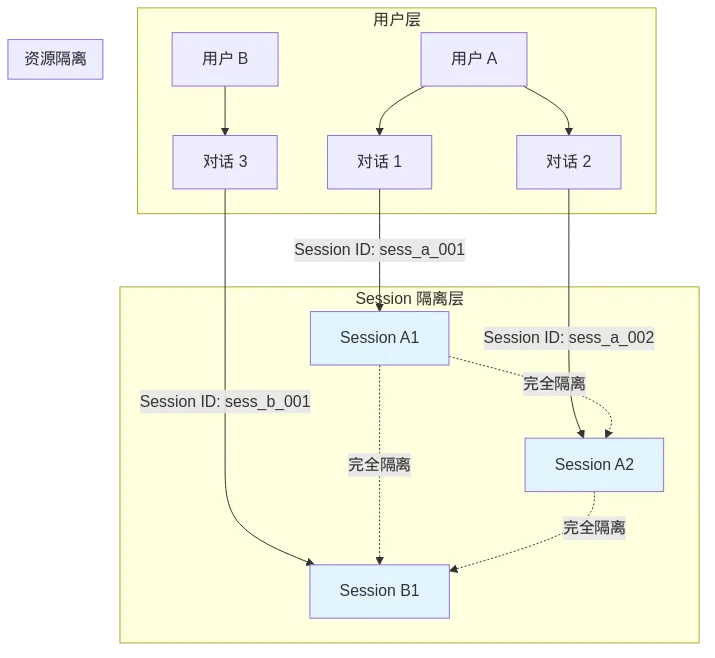
图3: 架构图
这张图展示了 Session 隔离的三个层面:
1. 用户间隔离(User Isolation)
用户 A 的 Session 和用户 B 的 Session 完全隔离 用户 A 无法访问用户 B 的对话历史,反之亦然 这是最基本的安全保障,确保隐私不泄露
2. 对话间隔离(Conversation Isolation)
即使是同一个用户,对话 1 和对话 2 也是独立的 Session 新对话开始时,旧的上下文不会自动带入 这就是为什么你昨天聊的内容,今天新开的对话里 AI 不知道
3. 资源隔离(Resource Isolation)
每个 Session 有独立的内存空间、上下文窗口、临时文件 一个 Session 的崩溃不会影响其他 Session 便于统计配额(如 tokens 消耗、API 调用次数)
2.4 为什么 Session 隔离会导致"失忆"?
理解了 Session 隔离机制,我们就能准确回答开头的问题了:
为什么 AI 一夜醒来就失忆?
原因一:新 Session = 新的大脑
当你关闭对话窗口、超过空闲超时时间、或主动开启新对话时,系统会创建一个新的 Session。这个 Session 和之前的 Session 在逻辑上是完全隔离的。新 Session 里没有旧 Session 的任何信息——就像换了一个全新的大脑。
原因二:无状态设计不保留历史
服务端的设计原则是"无状态",即服务器不会为每个用户持久化保存对话历史。每次请求只包含当前 Session 的上下文,而不是用户所有的历史对话。这意味着,即使服务端有记录,也不会自动加载到新 Session 中。
原因三:上下文窗口的限制
即使在一个 Session 内,AI 能"记住"的内容也是有限的,这受限于模型的上下文窗口(Context Window)。比如 GPT-4 的上下文窗口是 128K tokens,Claude 是 200K tokens。当对话超过这个限制时,最早的消息会被截断或摘要,导致"遗忘"。
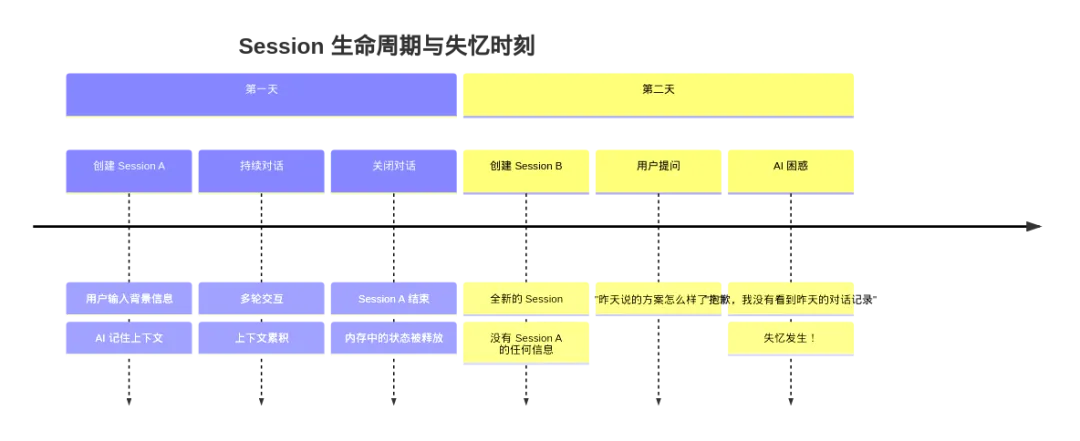
图4: 架构图
这个时序图清晰地展示了"失忆"发生的完整过程。关键在于:Session 的结束意味着该会话内所有未持久化的状态都会丢失。
三、技术架构:OpenClaw 的会话管理系统
了解了现象和原理,我们来深入 OpenClaw 的技术实现,看看一个生产级的 AI 助手系统是如何管理会话和记忆的。
3.1 OpenClaw 架构概览
OpenClaw 采用典型的分层架构,会话管理是其核心组件之一:
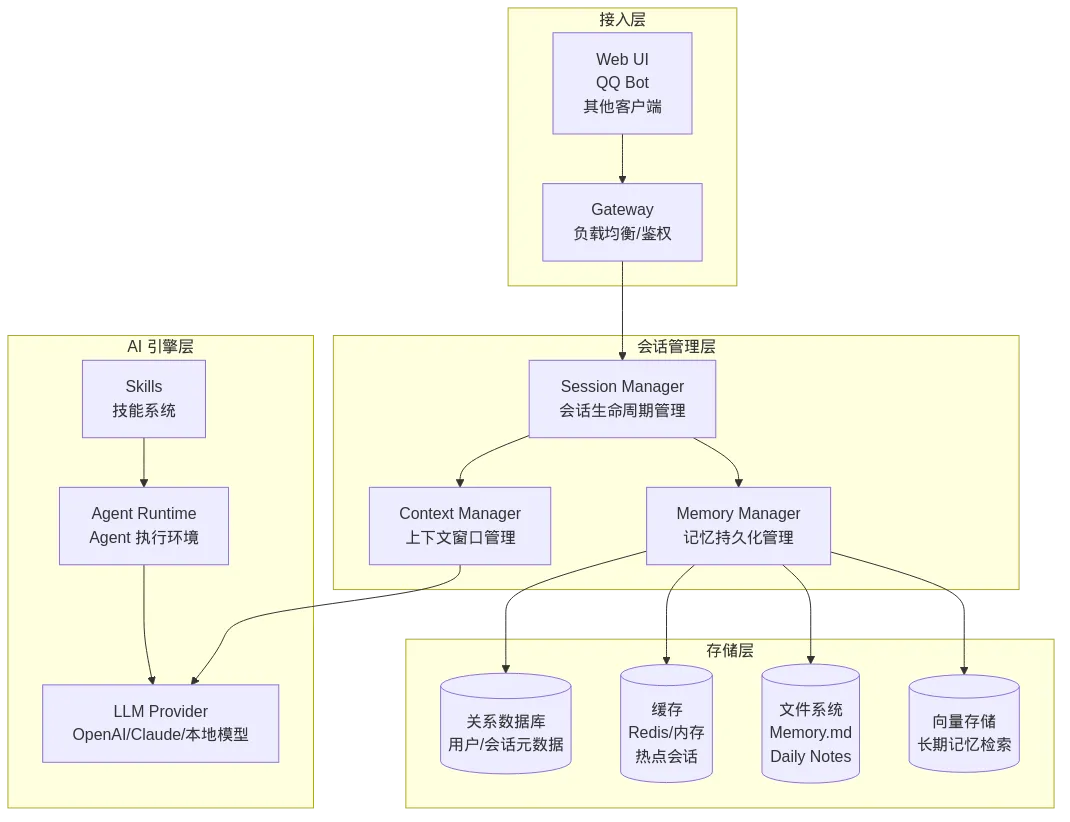
图5: 架构图
这张图展示了 OpenClaw 的完整架构。其中,**会话管理层(Session Management Layer)**是连接接入层和 AI 引擎层的关键枢纽,它决定了用户的状态如何被保存、恢复和使用。
3.2 Session Manager:会话生命周期管理
Session Manager 是会话管理层的核心组件,负责管理会话的整个生命周期:
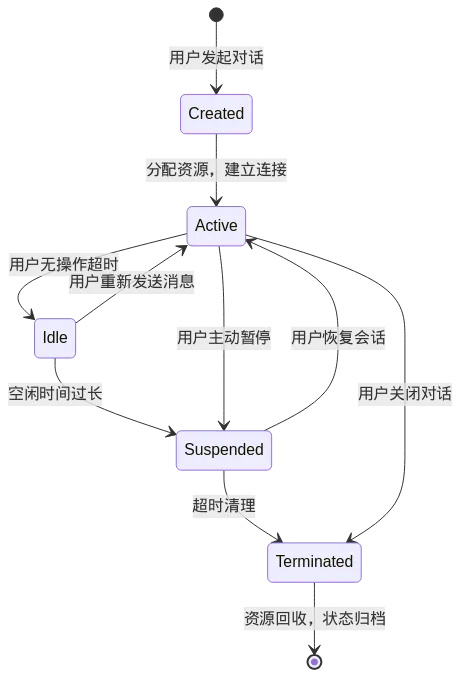
图6: 架构图
这是 Session Manager 的状态机。理解这些状态,有助于我们理解"失忆"发生的时机:
关键状态解析:
Created(创建):当用户首次发起对话时,系统创建一个新的 Session ID,分配基础资源。此时 Session 是"空"的,没有任何历史信息。
Active(活跃):用户与 AI 正在交互,Session 中维护着完整的上下文。此时 AI"记得"当前对话的所有内容。
Idle(空闲):用户暂时没有发送新消息,但连接还保持着。Session 仍在内存中,但如果空闲时间过长,可能会被转移到磁盘或清理。
Suspended(挂起):会话被暂停,状态可能被序列化保存到持久化存储,内存中的资源被释放。这是从"活跃"到"终止"的过渡状态。
Terminated(终止):会话正式结束,内存中的状态被完全释放。如果没有持久化机制,所有未保存的信息都会丢失。
失忆发生的时机:
从 Active 到 Terminated:用户关闭对话,Session 结束,未持久化的信息丢失 从 Active 到 Suspended 再到 Terminated:长时间空闲,系统自动清理 Session 从 Created 开始:新 Session 默认不带任何历史,除非显式加载持久化数据
3.3 Context Manager:上下文窗口管理
即使在一个活跃的 Session 中,AI 的"记忆"也是有限的,这由 Context Manager 管理。
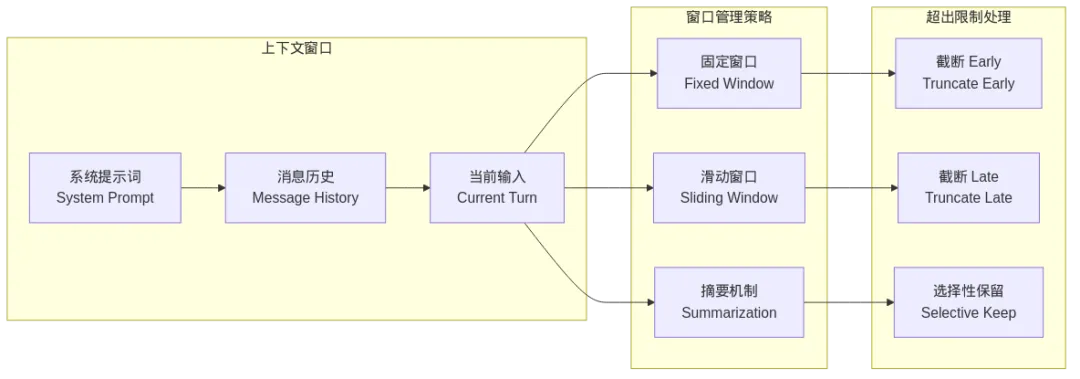
图7: 架构图
这张图展示了 Context Manager 的核心逻辑:
上下文窗口的组成:
System Prompt(系统提示词):通常是固定的,定义了 AI 的角色和行为规范 Message History(消息历史):用户和 AI 的多轮对话记录 Current Turn(当前输入):用户刚刚发送的最新消息
窗口管理策略:
固定窗口(Fixed Window):只保留最近 N 条消息,超过就丢弃
优点:简单可控,计算开销固定 缺点:可能丢失重要的早期信息 滑动窗口(Sliding Window):随着对话进行,窗口不断滑动,老消息被移出
与固定窗口类似,但通常按 token 数量而非消息数计算 摘要机制(Summarization):当消息历史过长时,对早期对话进行摘要压缩
优点:保留了关键信息,节省空间 缺点:摘要会丢失细节,且摘要本身需要时间生成
超出限制的处理方式:
Truncate Early(截断早期):丢弃最老的消息,保留最近的内容 Truncate Late(截断近期):特殊情况,如需要保留系统提示时 Selective Keep(选择性保留):智能识别重要信息,优先保留
理解了 Context Manager 的工作原理,你就明白为什么 AI 在同一个会话中也会"失忆"——因为上下文窗口有限,当对话太长时,早期的信息会被截断或摘要,细节自然就丢失了。
3.4 Memory Manager:记忆持久化管理
现在我们来解决最关键的问题:如何让 AI 真正"记住"?
这就是 Memory Manager 的工作——它负责将重要的信息从易失的内存中,持久化到可靠的存储介质中。
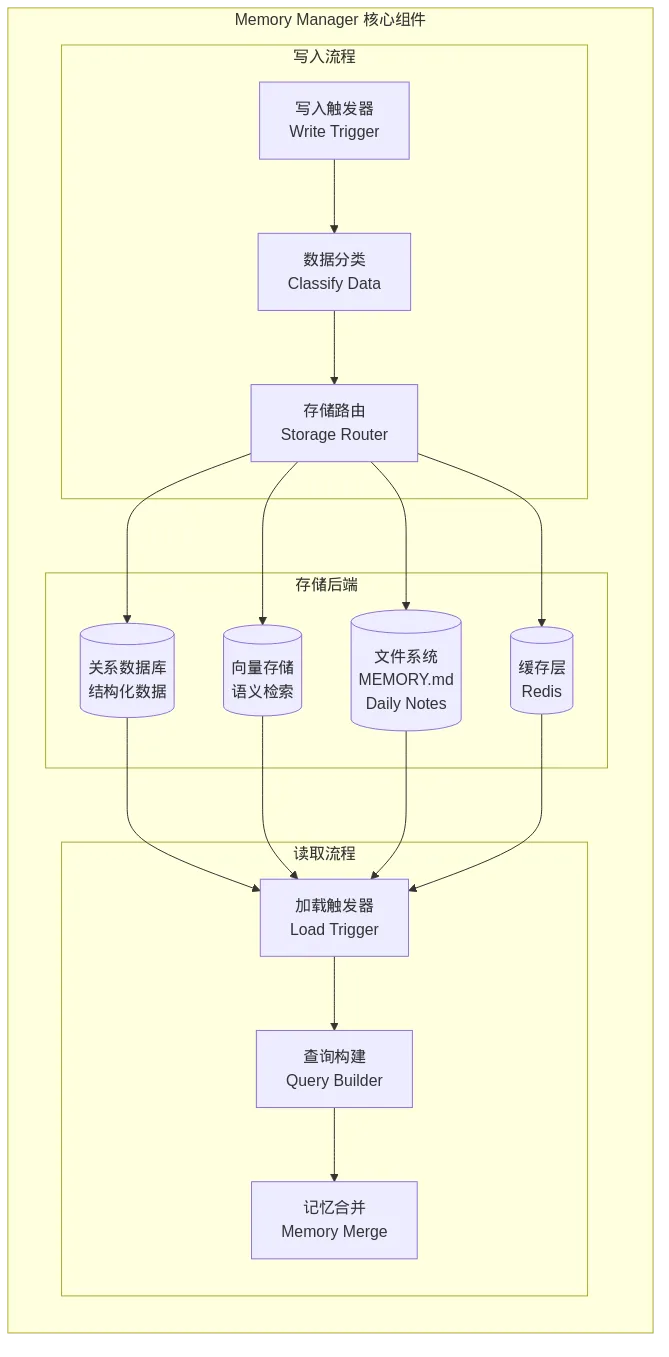
图8: 架构图
这张图展示了 Memory Manager 的完整数据流:
写入流程(Write Path):
写入触发器(Write Trigger):什么情况下会把内存中的数据持久化?
用户显式要求:"记住这个" 系统检测到关键信息:如用户偏好、重要事实 会话结束时:自动归档本次对话的摘要 定期 checkpoint:防止意外崩溃丢失数据 数据分类(Classify Data):不同类型的信息存到哪里?
结构化数据(如用户配置):关系数据库 语义化内容(如对话记录):向量存储,便于检索 文档类数据(如项目文档):文件系统(MEMORY.md、Daily Notes) 热点数据:缓存层,加速访问 存储路由(Storage Router):根据分类结果,路由到合适的存储后端
存储后端(Storage Backends):
关系数据库(Relational DB):
存储:用户信息、配置项、权限数据、结构化元数据 特点:强一致性,支持复杂查询 向量存储(Vector Store):
存储:对话记录、文档片段、知识库 特点:支持语义检索,"找相似内容"而非"精确匹配" 文件系统(File System):
存储:MEMORY.md、Daily Notes、项目文档、临时文件 特点:用户可读写,格式灵活,便于版本控制 缓存层(Cache):
存储:热点数据、最近使用的记忆 特点:高速访问,自动过期,不保证持久化
读取流程(Read Path):
加载触发器(Load Trigger):什么时候加载记忆?
新会话开始时:加载用户的长期偏好和背景知识 用户提问时:检索相关的历史信息作为上下文 检测到特定关键词时:加载关联的记忆模块 查询构建(Query Builder):如何找到相关记忆?
结构化查询:从数据库查用户配置 语义检索:用向量相似度找相关对话 关键字匹配:从文件系统查包含关键词的文档 记忆合并(Memory Merge):如何把加载的记忆整合进当前上下文?
优先级排序:最近的信息 > 旧信息,显式保存的 > 自动归档的 冲突解决:如果两条记忆矛盾,用时间戳或置信度决定 格式转换:把不同来源的记忆统一成模型能理解的格式
理解了 Memory Manager 的工作原理,你就掌握了让 AI"不失忆"的核心方法:关键信息必须通过 Memory Manager 写入持久化存储,新会话开始时必须通过 Memory Manager 读取并加载。
接下来,我们将通过具体的时序图,展示 OpenClaw 中一个完整会话的记忆管理流程。
四、实战:OpenClaw 会话管理时序图
4.1 场景一:新用户首次对话
让我们从最简单的场景开始:一个新用户第一次打开 OpenClaw,发送了一条消息。
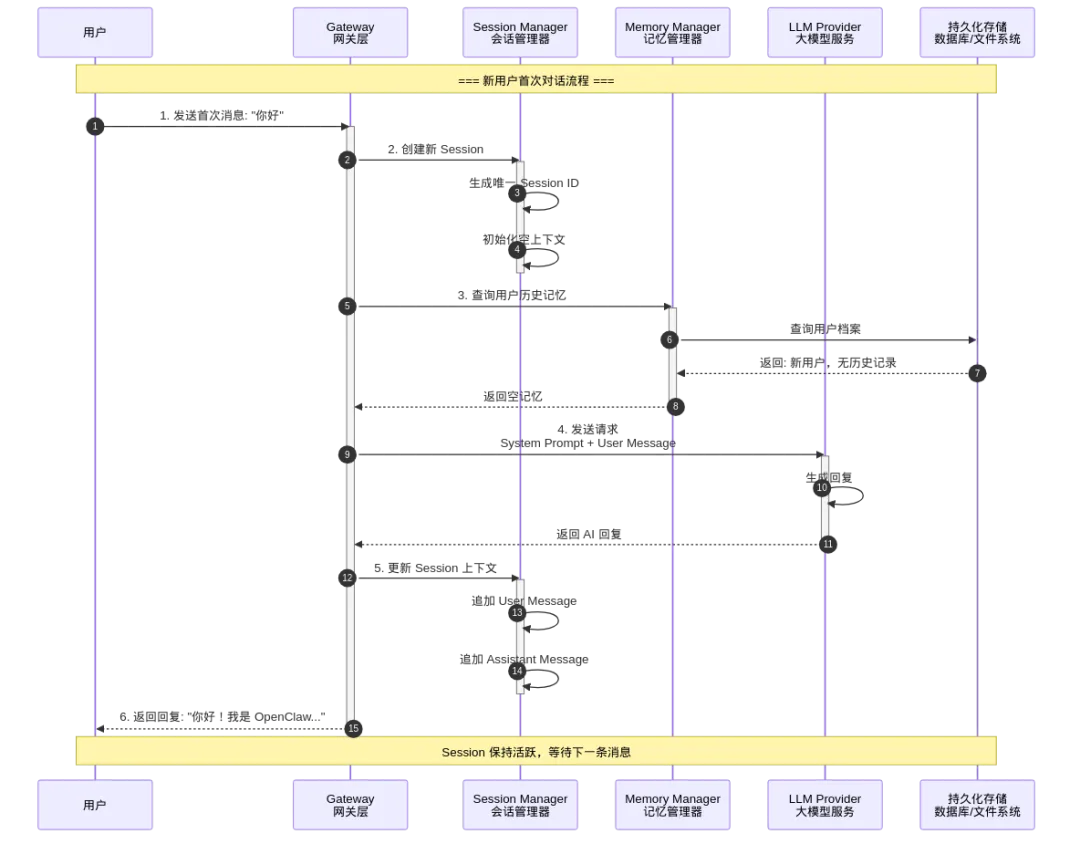
图9: 架构图
这个时序图展示了新用户首次对话的完整流程。关键点:
创建新 Session:系统生成唯一的 Session ID,这是一个全新的、空的会话上下文 查询历史记忆:Memory Manager 检查是否有该用户的历史记录,新用户返回空 调用 LLM:只携带 System Prompt 和当前用户消息,没有历史上下文 更新 Session:将本轮对话追加到 Session 的上下文中,供后续轮次使用
为什么 AI"失忆"了?
因为这个流程中,新 Session 没有任何历史记忆加载进来。对于新用户来说这是正常的,但对于老用户,如果没有正确加载持久化记忆,就会感觉 AI"忘了"之前的事情。
4.2 场景二:老用户加载历史记忆
现在来看老用户的场景。用户之前用过 OpenClaw,今天再次打开,系统能否记住他?
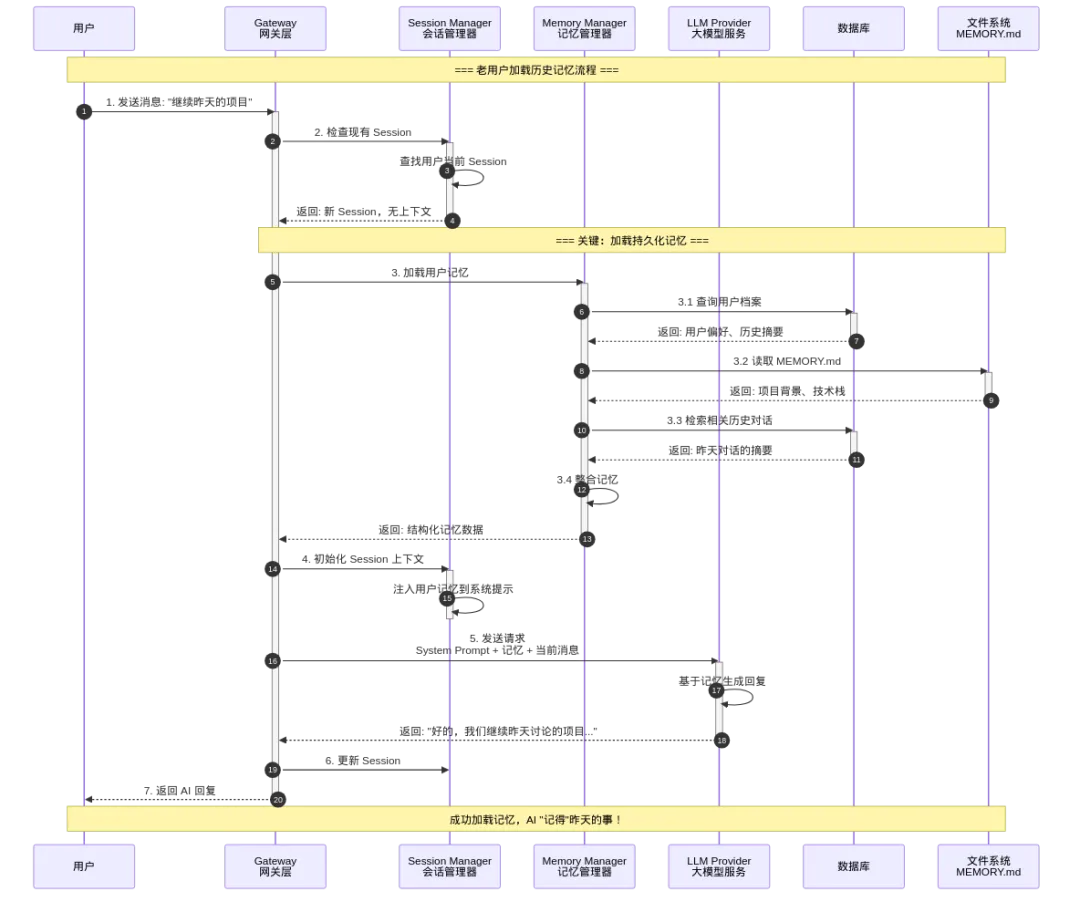
图10: 架构图
这个时序图展示了老用户如何加载历史记忆的关键流程。与首次对话的区别在于步骤 3:Memory Manager 从多个持久化存储中加载用户记忆。
关键步骤解析:
查询用户档案(3.1):从数据库获取用户的基本信息、长期偏好设置、历史对话的元数据摘要
读取 MEMORY.md(3.2):从文件系统读取用户或项目目录下的 MEMORY.md 文件,这是 OpenClaw 特有的记忆机制
检索相关历史(3.3):基于向量相似度,从长期记忆库中检索与当前话题相关的历史对话片段
整合记忆(3.4):将来自不同源的记忆整合成结构化的数据,按优先级排序
注入系统提示(步骤 4):把整合好的记忆注入到 System Prompt 中,这样 LLM 在生成回复时就能"看到"这些背景信息
为什么这样能解决"失忆"?
因为记忆已经从易失的 Session 内存,转移到了持久的存储介质(数据库、文件系统、向量库)。新 Session 开始时,通过 Memory Manager 显式加载这些记忆,AI 就能"记得"之前的事情了。
4.3 场景三:Memory Manager 持久化流程
现在来看记忆的另一个方向:当 AI 在对话中获得了重要信息,如何让它"记住"?这需要 Memory Manager 的持久化流程。
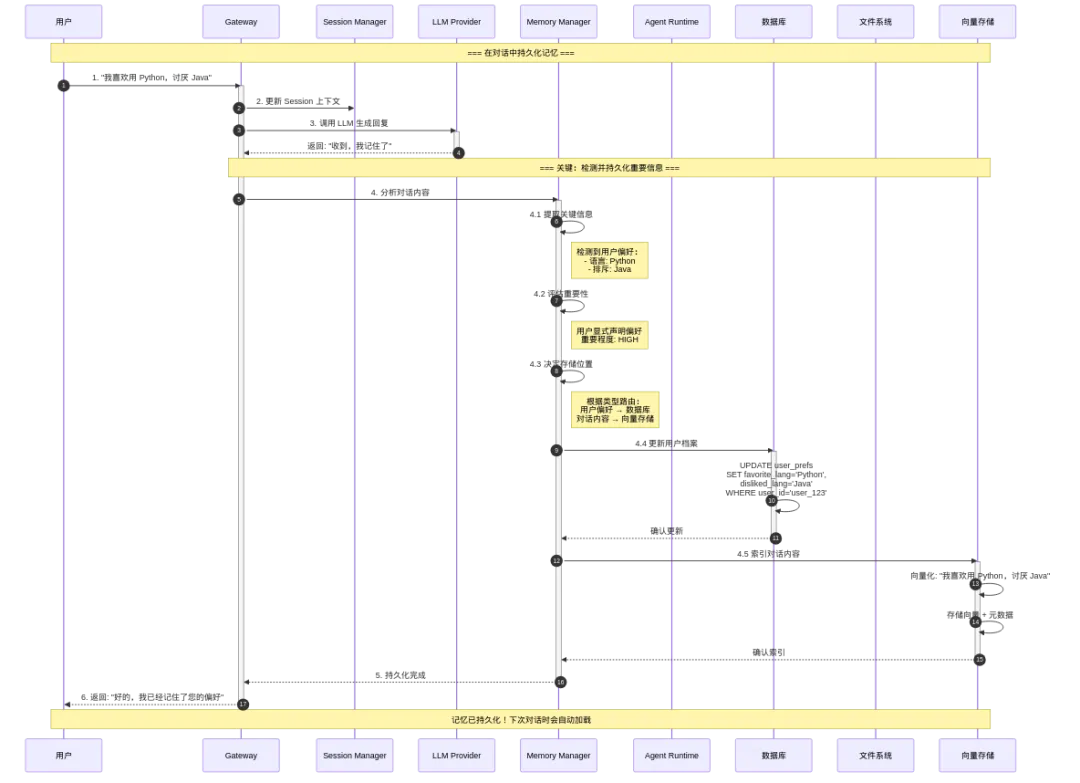
图11: 架构图
这个时序图展示了当用户告诉 AI 重要信息时,系统如何将其持久化的完整流程。关键点:
步骤 4:Memory Manager 的分析与持久化
提取关键信息(4.1):从对话中识别出结构化信息,如"喜欢 Python"、"讨厌 Java"
评估重要性(4.2):判断这条信息是否值得持久化。用户显式声明的偏好通常优先级很高
决定存储位置(4.3):根据数据类型选择存储后端:
结构化偏好 → 关系数据库 语义化内容 → 向量存储 项目文档 → 文件系统 执行持久化(4.4 - 4.5):
更新数据库中的用户档案表 将对话内容向量化并存储到向量数据库
为什么这样能解决"失忆"?
因为重要的信息已经从易失的 Session 上下文,转移到了可靠的持久化存储中。即使用户关闭对话、Session 结束,这些信息依然存在。下次创建新 Session 时,Memory Manager 会从这些存储中加载数据,AI 就能"记得"用户的偏好了。
五、最佳实践:如何正确使用 MEMORY.md 和 Daily Notes
理解了 OpenClaw 的记忆机制,接下来我们进入实战环节:如何正确使用 MEMORY.md 和 Daily Notes,让 AI 真正"记住"你。
5.1 MEMORY.md:项目级的长期记忆
MEMORY.md 是 OpenClaw 特有的记忆机制,它是一个位于项目目录下的 Markdown 文件,用于存储该项目的背景信息、技术栈、团队规范等长期有效的信息。
MEMORY.md 的典型结构:
# Project: OpenClaw 技术博客系统## 基本信息- 项目代号: claw-blog- 启动日期: 2024-01-15- 负责人: 阿飞## 技术栈- 前端: Next.js 14 + Tailwind CSS- 后端: Node.js + Express- 数据库: PostgreSQL- 部署: Vercel## 开发规范- 代码风格: ESLint + Prettier- 提交规范: Conventional Commits- 分支策略: Git Flow## 常用命令```bash# 本地开发npm run dev# 数据库迁移npm run db:migrate# 部署到生产npm run deploy:prod重要决策记录
2024-01-20: 从 MongoDB 迁移到 PostgreSQL 2024-02-05: 引入 Next.js App Router
**为什么 MEMORY.md 能解决"失忆"?***图12: 架构图*这张图对比了两种工作流:- **左边(红色)**:没有 MEMORY.md 时,每次新 Session 用户都要重新交代背景,重复劳动,效率低下。- **右边(绿色)**:有了 MEMORY.md,背景信息一次性写入,持久化存储。之后每个新 Session 都会自动加载,AI 始终"记得"项目背景。**最佳实践建议**:1. **每个项目一个 MEMORY.md**:放在项目根目录下,方便 OpenClaw 自动发现2. **结构化编写**:使用 Markdown 标题、列表、代码块,便于 AI 解析3. **定期更新**:项目有重要变更时及时同步到 MEMORY.md4. **保持简洁**:只放长期有效的信息,临时细节用 Daily Notes### 5.2 Daily Notes:会话级的短期记忆如果说 MEMORY.md 是"长期记忆",那么 Daily Notes 就是"短期记忆"。它是按日期组织的笔记,用于记录当天的对话要点、临时决策、待办事项等。**Daily Notes 的典型使用场景**:```markdown# 2024-03-15 Daily Notes## 今日目标- [ ] 完成用户认证模块的 API 设计- [ ] 评审前端团队的 PR- [ ] 更新项目文档## 重要讨论记录### 14:30 - 与产品经理讨论权限模型- 决定采用 RBAC(基于角色的访问控制)- 角色:admin, editor, viewer- 权限粒度到资源级别(document:read, document:write)- 不采用 ABAC,太复杂### 16:00 - 技术选型讨论- 缓存:Redis(主从 + Sentinel)- 消息队列:RabbitMQ- 不考虑 Kafka,运维成本高## 临时决策- 用户头像存储:对象存储(OSS)而非本地- 默认分页:每页 20 条,最大 100 条## 明日待办- 画出权限模型 ER 图- 写 Redis 缓存策略文档- 准备周会分享材料Daily Notes 的价值:
会话间衔接:今天的对话要点记下来,明天新 Session 时 OpenClaw 可以加载,快速进入状态 信息密度高:过滤掉了闲聊,只保留有价值的信息 行动导向:明确待办事项,便于跟进
使用建议:
每天一个文件:按 YYYY-MM-DD.md命名,放在daily-notes/目录下结构化模板:使用固定模板(目标、讨论记录、决策、待办) 定期归档:周/月末把重要的决策沉淀到 MEMORY.md,删除过期的临时笔记 让 OpenClaw 帮你写:可以直接告诉 AI "把刚才的讨论记录到今天的 Daily Notes"
5.3 记忆管理的黄金法则
基于前面的分析,我总结出使用 OpenClaw 记忆机制的黄金法则:
┌────────────────────────────────────────────────────────────────┐│ 记忆管理黄金法则 │├────────────────────────────────────────────────────────────────┤│ ││ 1. 区分记忆的保质期 ││ ├─ 长期有效 → MEMORY.md ││ ├─ 短期有用 → Daily Notes ││ └─ 一次性 → 直接对话,不存储 ││ ││ 2. 显式优于隐式 ││ ├─ 不要说 "你应该知道..." ││ ├─ 而要 say "请记录到 MEMORY.md: ..." ││ └─ 显式声明,避免误解 ││ ││ 3. 定期整理,防止信息膨胀 ││ ├─ 每周 review Daily Notes,重要内容迁移 ││ ├─ 每月整理 MEMORY.md,删除过时信息 ││ └─ 保持记忆库的"整洁",提高检索效率 ││ ││ 4. 分层加载,按需取用 ││ ├─ 项目背景 → 自动从 MEMORY.md 加载 ││ ├─ 今日要点 → 从 Daily Notes 加载 ││ └─ 历史相关 → 向量检索按需加载 ││ │└────────────────────────────────────────────────────────────────┘遵循这四条法则,你就能高效地使用 OpenClaw 的记忆机制,让 AI 真正成为"记得"你的智能助手。
六、对比:与其他 AI 工具的记忆机制
理解了 OpenClaw 的记忆机制,我们再来横向对比一下其他主流 AI 工具,看看它们是如何解决"失忆"问题的。
6.1 主流 AI 工具记忆机制对比

图13: 架构图
这张图展示了四类主流 AI 工具的记忆机制:
6.2 详细对比分析
| 会话持久化 | ||||
| 项目级记忆 | ||||
| 显式记忆 | ||||
| 上下文窗口 | ||||
| 隐私控制 | ||||
| 记忆粒度 |
6.3 各方案优缺点分析
OpenClaw 的 MEMORY.md 方案
优点:
完全文件化,可用 Git 版本控制 项目级隔离,不同项目有不同记忆 用户完全控制,可编辑、可审计 支持 Markdown,格式丰富
缺点:
需要用户主动维护,不够自动化 没有语义检索,依赖文件组织 需要显式告诉 AI 读取哪个文件
ChatGPT 的 Memory 功能
优点:
完全自动化,AI 自动判断什么值得记住 用户界面友好,可查看和管理记忆 跨会话生效,一次记住,永久使用
缺点:
黑盒机制,用户不清楚什么被记住了 可能出现记忆错误或冗余 隐私敏感内容可能被上传到云端
Claude 的 Projects 功能
优点:
项目级组织,文档、代码、对话集中管理 超大上下文窗口(200K),能"记住"更多 Artifacts 可持久化保存生成的内容
缺点:
仅适用于付费用户 记忆仅限于 Project 内,跨 Project 不共享 没有显式的"记忆管理"功能
6.4 选择建议
根据不同的使用场景,我的建议:
七、总结与行动建议
通过前面的深入分析,我们完整解答了"OpenClaw 为什么一夜醒来就失忆"这个问题。现在来做个总结,并给出可落地的行动建议。
7.1 核心知识点回顾
让我们用一张图来回顾全文的核心内容:
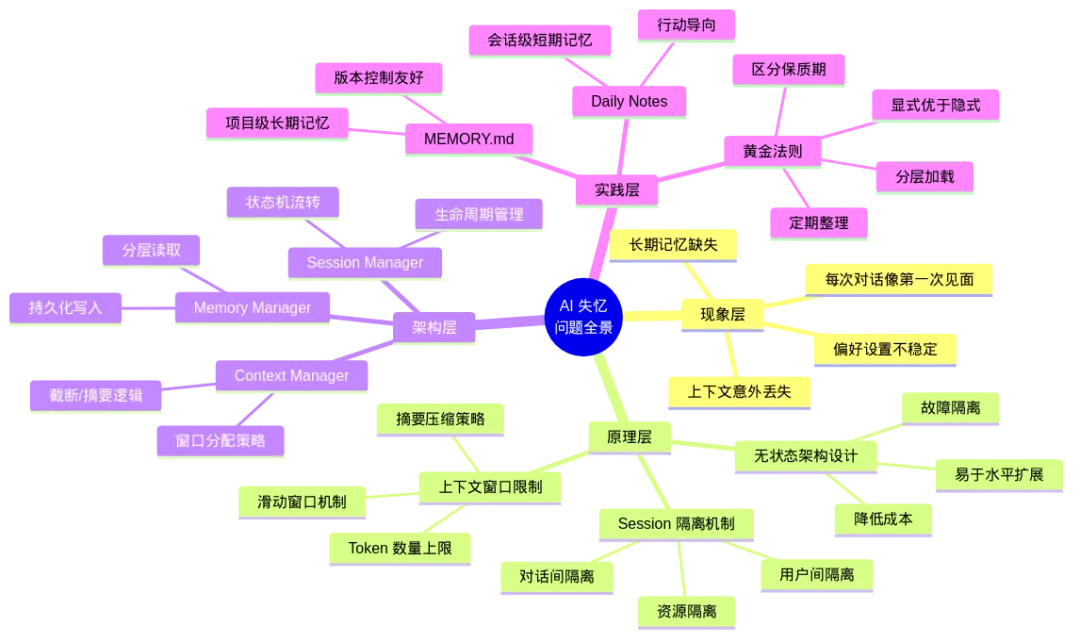
图14: 架构图
这张思维导图涵盖了从现象到实践的全部知识点。建议保存下来,作为日常使用的参考。
7.2 行动清单:从今天开始改变
知识如果不转化为行动,就只是信息。以下是你可以立即执行的行动清单:
【立即执行】基础设置(5 分钟)
在你常用的项目目录下创建 MEMORY.md文件复制本文 5.1 节的模板,填入你的项目信息 在 .openclaw/目录下创建daily-notes/文件夹
【本周完成】优化工作流(30 分钟)
回顾最近 3 个项目,为每个项目创建 MEMORY.md 在 Daily Notes 中记录今天的关键决策 测试一下:新 Session 中询问项目背景,验证 AI 是否"记得"
【持续践行】养成习惯(每日/每周)
每天结束时,花 2 分钟更新 Daily Notes 每周五下午,回顾本周 Daily Notes,重要内容迁移到 MEMORY.md 每月月初,整理所有项目的 MEMORY.md,删除过时信息
7.3 写在最后
"OpenClaw 为什么一夜醒来就失忆?"
现在你知道答案了:这不是 Bug,而是架构设计的必然结果。无状态架构让系统可以水平扩展、故障隔离、成本可控,但代价就是每次新 Session 都是一张白纸。
但这并不意味着我们只能接受"失忆"。相反,OpenClaw 提供了强大的记忆管理工具——MEMORY.md、Daily Notes、向量检索——让我们可以显式地控制什么是值得记住的、应该如何组织记忆、在什么时候加载记忆。
最终,AI 的记忆质量,取决于使用它的人是否有意识地管理记忆。
就像你不会期望一个刚见面的陌生人完全理解你的背景,你也不应该期望一个没有持久化记忆的 AI 自动"记得"一切。但如果你愿意花几分钟建立 MEMORY.md,每天花几秒钟更新 Daily Notes,你会发现 AI 助手变得前所未有的"懂"你。
这不是魔法,只是良好的信息管理习惯。
从今天开始,让你的 AI 真正记住你。
