 夜雨聆风
夜雨聆风
研究速览

眼科超声解读是诊断视网膜脱离、玻璃体积血等眼部疾病的关键手段,但高度依赖专家经验、耗时费力。随着超声数据量激增,传统AI模型只能做疾病筛查,无法同时定位病灶和生成报告,临床实用性大打折扣。
浙江大学医学院附属第二医院金凯团队联合多家单位,在《NPJ Digital Medicine》发表研究,提出视觉-语言分割模型——将视觉-语言模型与Segment Anything Model结合,首次在眼科超声领域实现“病灶自动勾画+诊断报告同步生成”。研究纳入三家医院共64,098张图像和21,355份报告,VLS模型在内部测试集BLEU4达66.37,外部测试集分别达85.36和73.77;病灶分割平均Dice系数59.6%,特异性超97%。
更关键的是,AI生成单份报告成本仅$1.3,而资深眼科医生需$39,成本骤降30倍;阅片时间从70秒压缩至6秒。在200例人机对比中,初级医生借助AI后诊断准确率从86.3%跃升至94.7%。这为眼科超声的智能化、低成本、广覆盖提供了可行路径。
清璟AI——清北医工交叉团队,擅长AI智能体、大模型、深度学习、机器学习、多模态与多组学等,能够为医学研究者和临床医生提供全方位的支持与创新解决方案。我们拥有顶级科研资源,欢迎咨询!共同探索AI与医学的无限可能,一起发顶刊!

研究亮点
首创“分割+报告”一体化:VLS模型首次将病灶定位与文本生成融合,解决传统AI“只分类不解释”的痛点,输出可直接临床使用的图文报告
跨中心泛化能力强:在两家外部医院数据上,VLS的BLEU4和ROUGE-L得分均显著超越纯语言模型,证明对不同设备和报告风格的强适应性
30倍成本直降:AI单份报告成本仅$1.3,远低于资深医生$39,为基层眼科筛查提供了经济学可行性证据
初级医生显著获益:AI辅助使初级医生诊断准确率从86.3%提升至94.7%,尤其在视网膜脱离、玻璃体积血等高发病中改善明显
代码开源可复现:全部源代码已公开于GitHub,便于其他机构验证和二次开发
研究结果
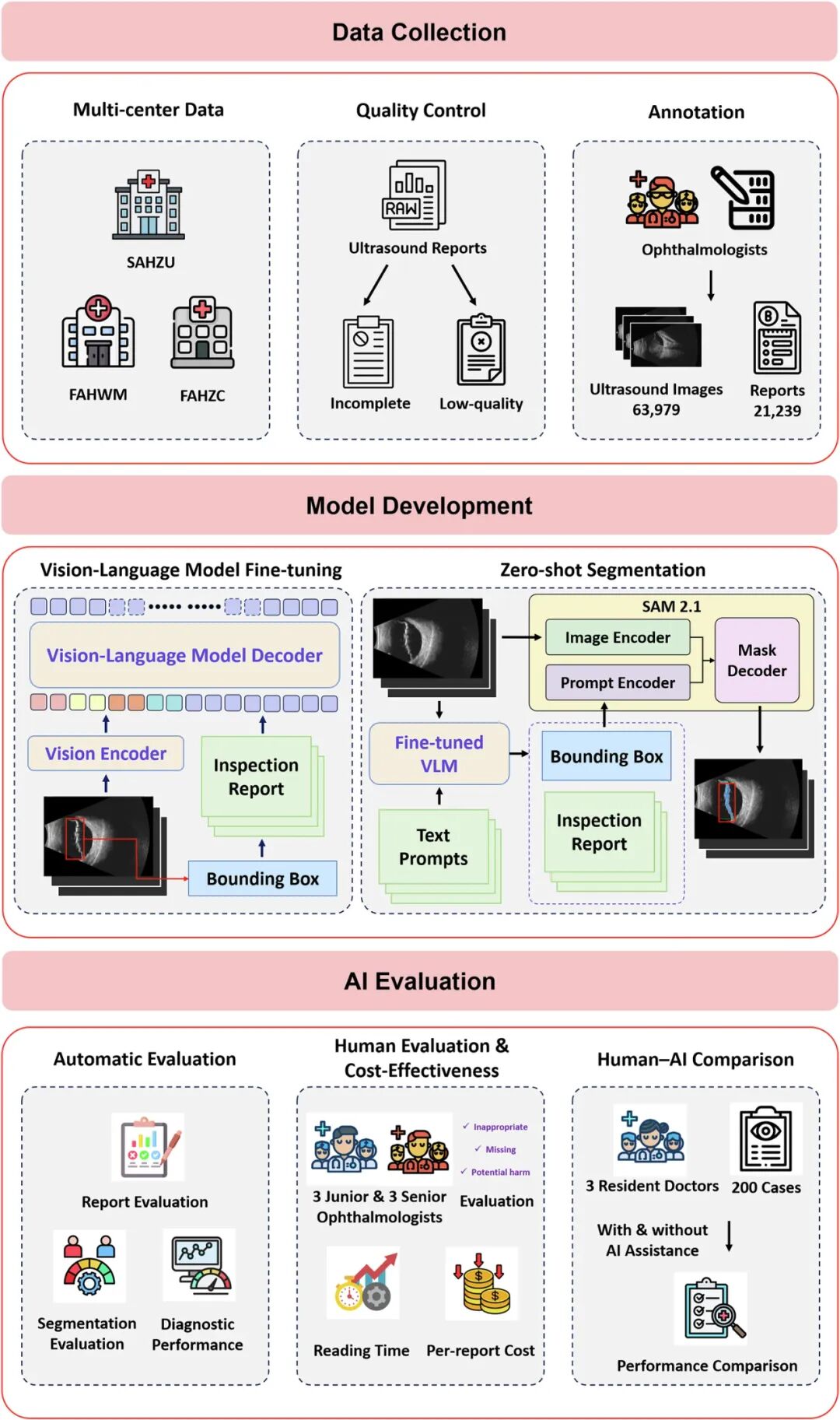
图1|整体研究设计框架
图注:研究整体流程图。数据来源于浙大二院、浙江中医药大学一附院、皖南医学院一附院三家机构;VLM代表视觉-语言模型,SAM代表分割一切模型。图标经Freepik授权使用。
解读:研究采用“三中心数据+双模型融合”架构。训练集、验证集、内部测试集来自浙大二院(SAHZU),两家外部医院数据作为独立验证。核心创新在于:VLM负责看懂图像并写报告,SAM负责精确勾画病灶边界,二者协同输出“带标注的图文报告”。
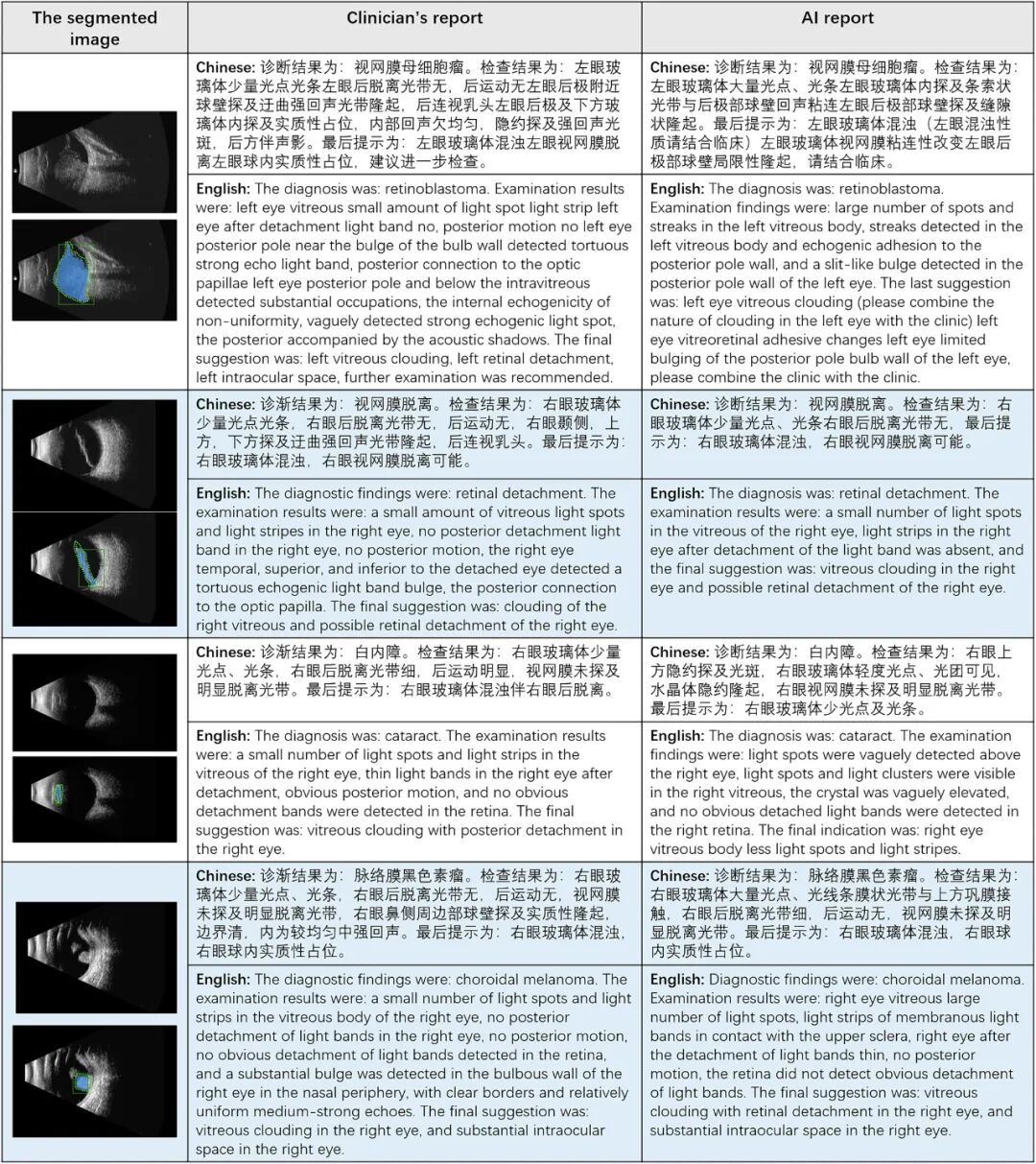
图2|VLS生成报告与医生报告对比实例
图注:真实眼科病例的AI生成报告示例,包含视网膜母细胞瘤、视网膜脱离、白内障、脉络膜黑色素瘤四种疾病。左列为原始超声图像叠加VLS分割结果(蓝色填充区域)和医生标注(绿色虚线圆圈);中列为医生撰写报告;右列为VLS系统生成报告。
解读:这张图直观展示了VLS的“看图说话”能力。以视网膜脱离为例,AI不仅准确勾画出脱离的视网膜区域(蓝色填充),还在报告中描述了“玻璃体腔内可见带状回声,与视盘相连”——与医生描述高度吻合。这种“所见即所得”的可视化报告,大幅提升了AI输出的可信度和临床可接受度。
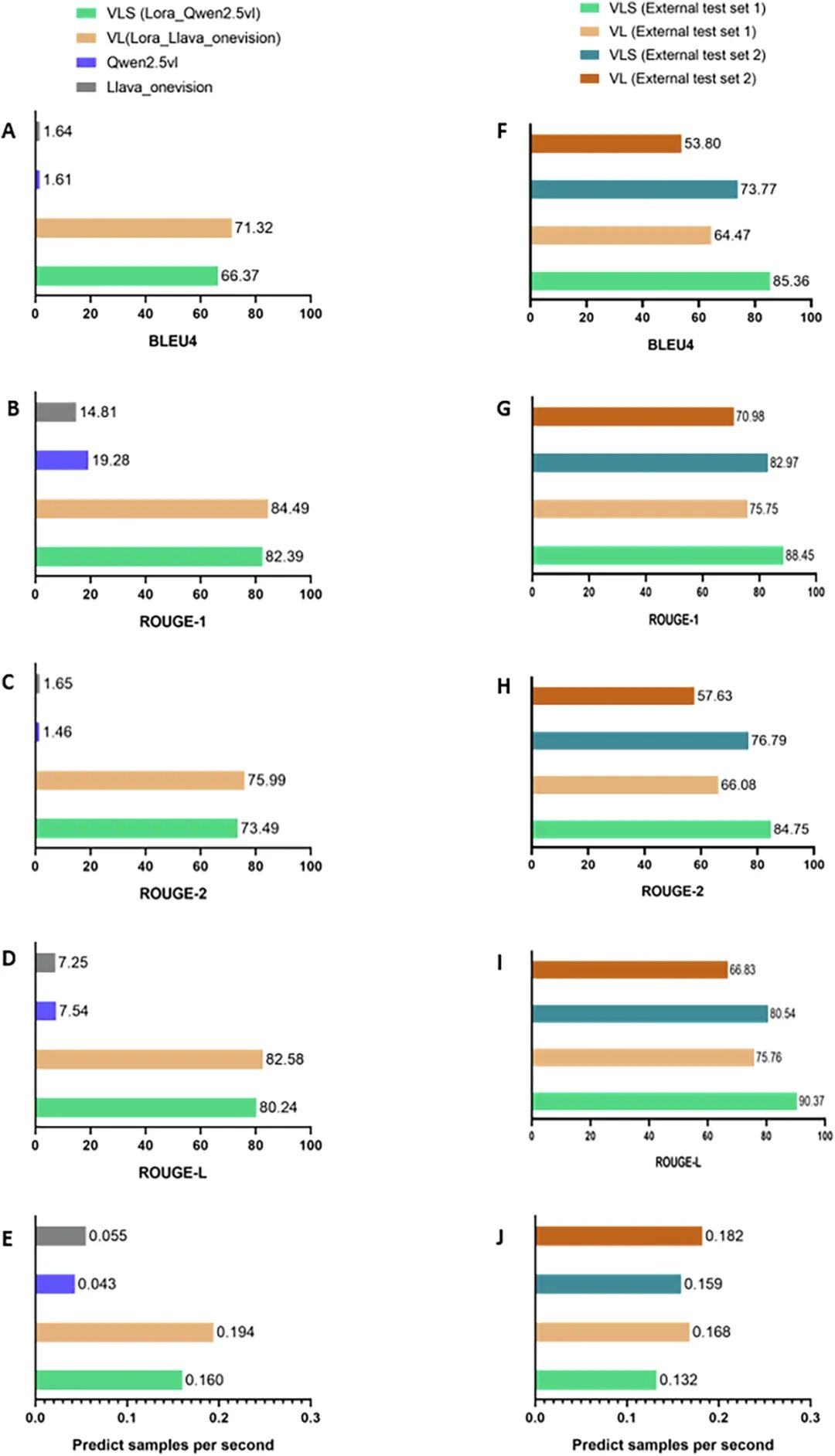
图3|报告生成性能评估
图注:报告生成性能对比。A-E为内部测试集结果,F-J为外部测试集结果。VLS代表视觉-语言分割模型,VL代表纯视觉-语言模型。
解读:
内部测试集:VL的BLEU4略高于VLS(71.32 vs 66.37),但差异不大,两者均展现出优秀的报告流畅度
外部测试集:VLS全面反超——在外部集1上BLEU4达85.36(VL仅64.47),ROUGE-L达90.37(VL仅75.76);外部集2趋势一致
关键启示:加了SAM“眼睛”的VLS,跨中心泛化能力显著更强。纯语言模型容易过拟合单一中心的数据风格,而VLS因有视觉定位的“锚定”,生成的描述更稳健
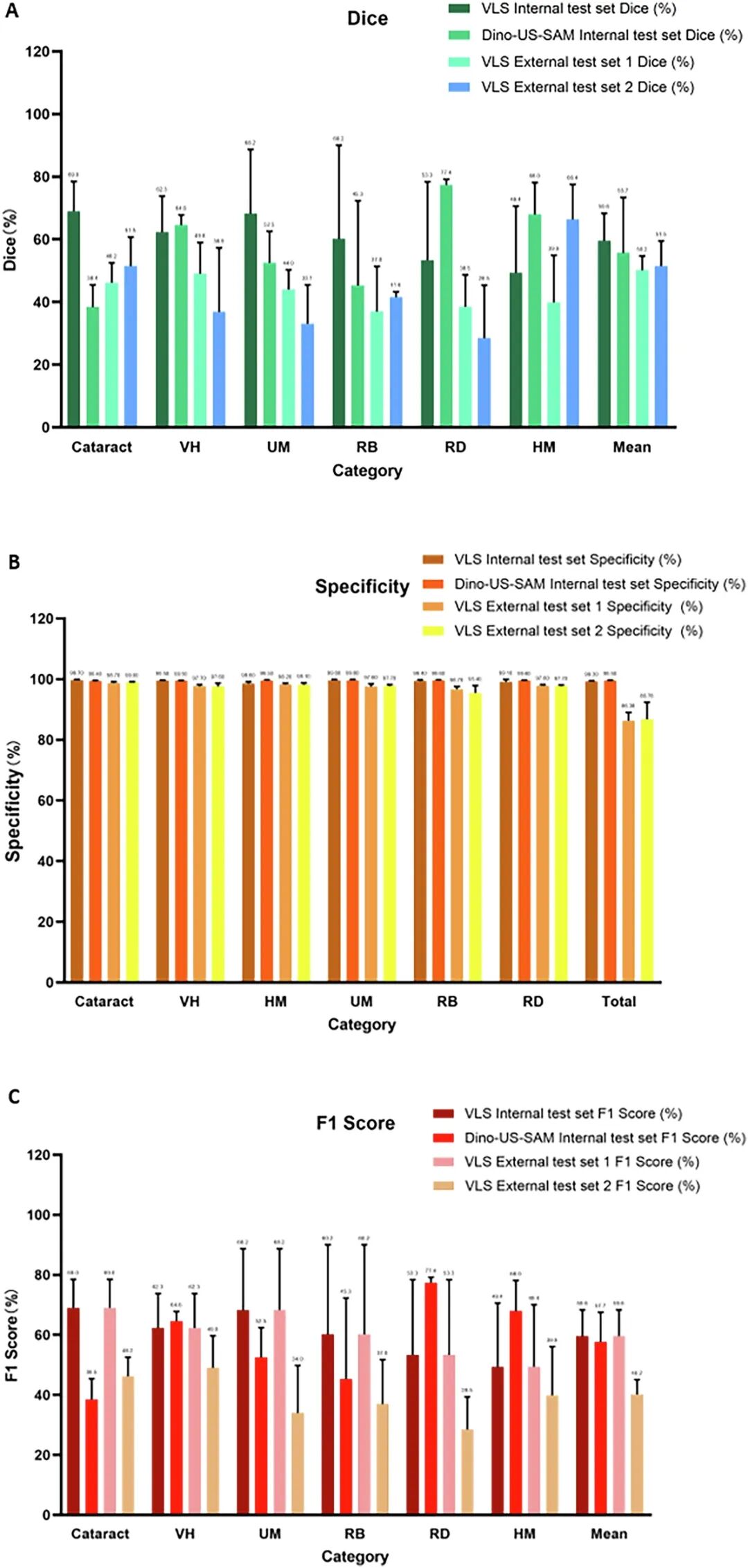
图4|病灶分割精度评估
图注:VLS模型与Dino-US-SAM模型的分割精度对比。采用Dice系数、特异性、F1分数三维度评估。VH=玻璃体积血,HM=高度近视,UM=葡萄膜黑色素瘤,RE=屈光不正,RB=视网膜母细胞瘤,RD=视网膜脱离。
解读:
整体表现:VLS内部测试集平均Dice系数59.6%,特异性99.3%;外部两中心分别为50.2%和51.5%,特异性始终维持97.7%以上,意味着“假阳性极低”
疾病差异:VLS在白内障(Dice 69.0%)和葡萄膜黑色素瘤(68.2%)上表现最优;Dino-US-SAM在视网膜脱离(77.4%)和高度近视(68.0%)上更胜一筹
临床意义:高特异性保证了AI不会“乱画”,这是进入临床的必要前提;但部分疾病Dice仍有提升空间,提示需针对性优化
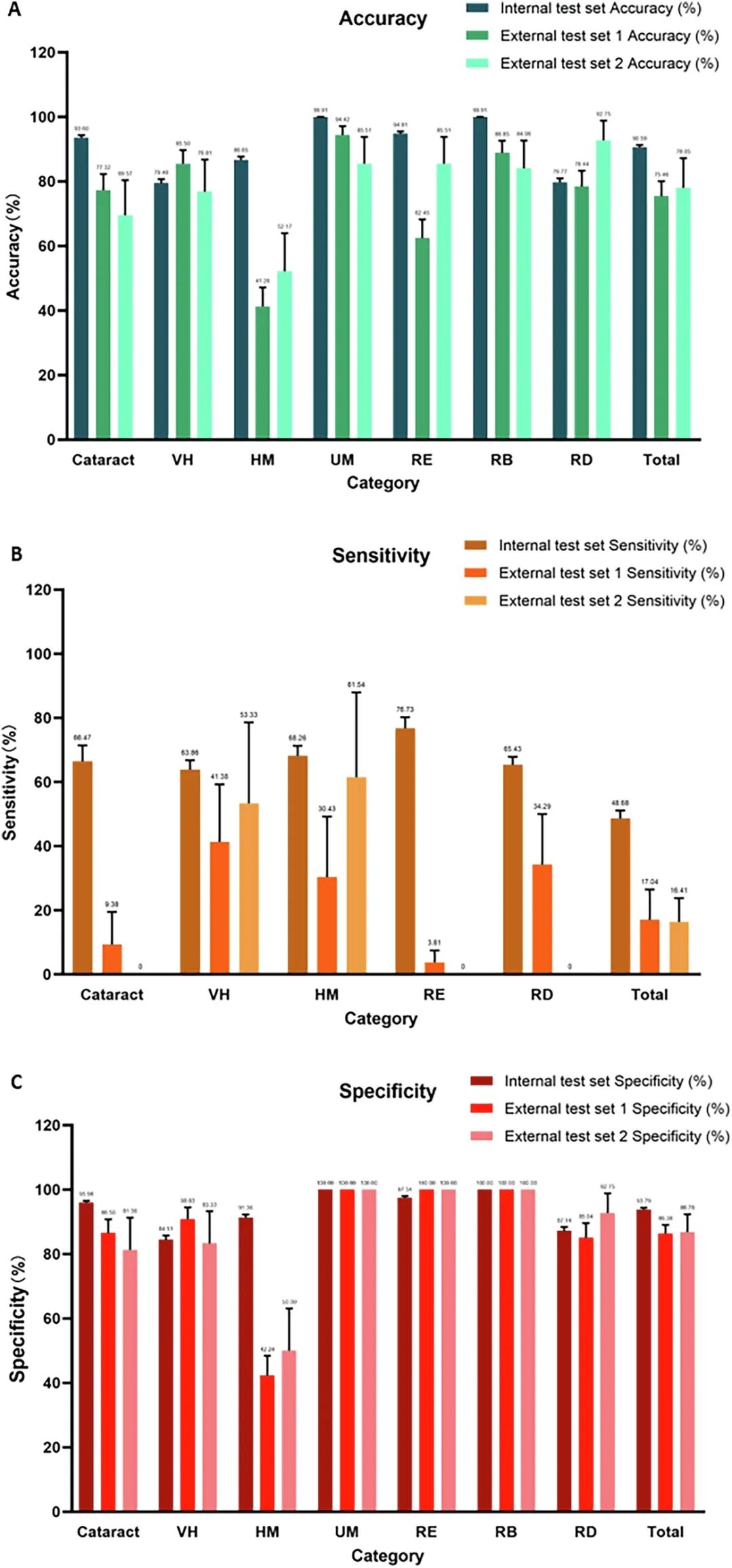
图5|VLS诊断性能全景评估
图注:VLS模型的诊断性能。A为准确率,B为灵敏度,C为特异度。涵盖三个测试集及七种眼部疾病。
解读:
整体准确率:内部测试集90.59%,外部两中心合并71.87%
“高特异低敏感”现象突出:以白内障为例,内部准确率93.6%,但灵敏度仅66.47%;葡萄膜黑色素瘤准确率近100%,灵敏度却为0%——说明模型“宁可不报,也不报错”
视网膜脱离改善明显:外部集2特异度达100%,体现出较强泛化能力
临床提示:VLS适合作为初筛辅助工具,可高效排除阴性病例,但对阳性病例仍需医生二次确认
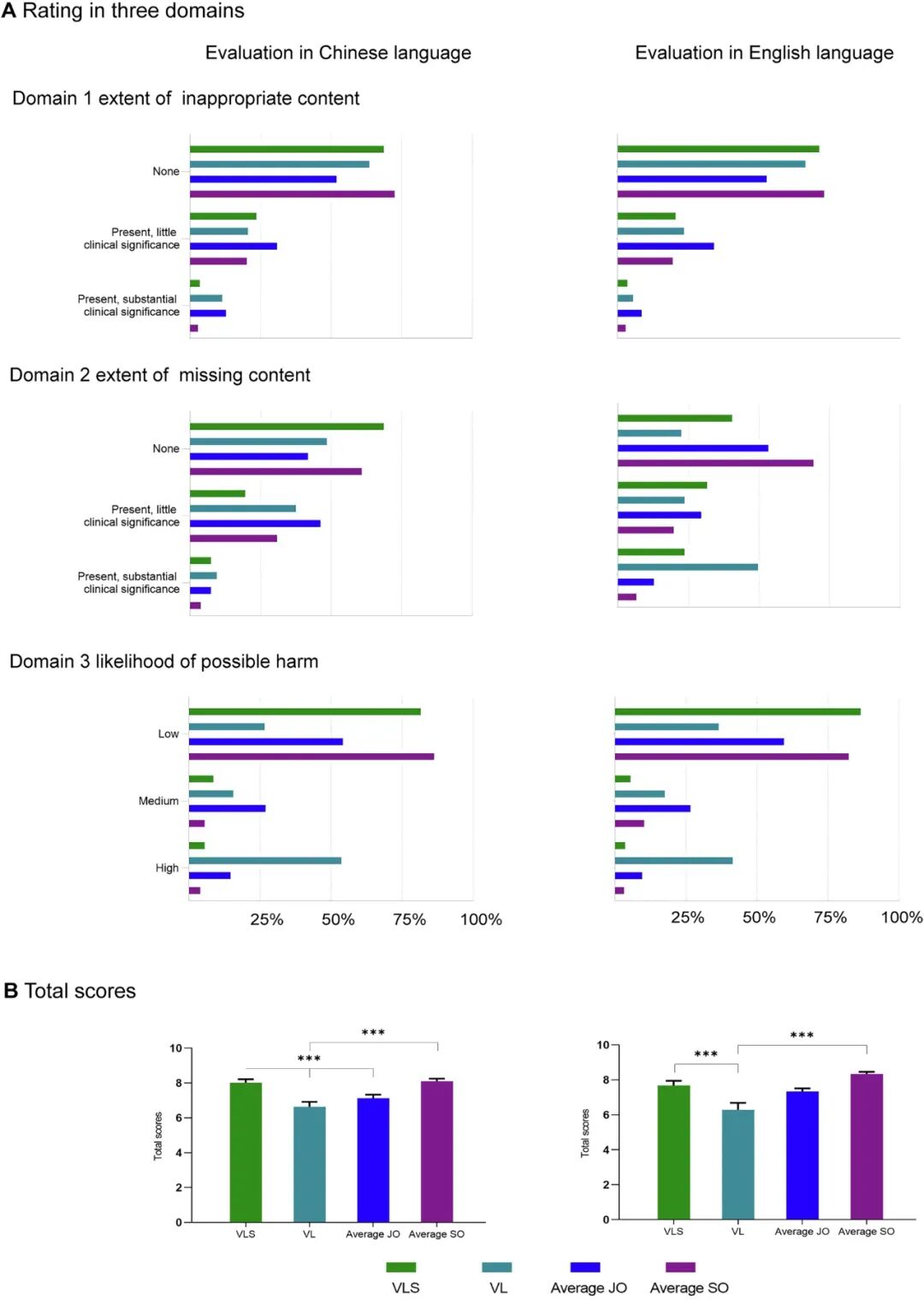
图6|眼科医生对报告质量的盲法评分
图注:VLS、VL、三名初级医生、三名资深医生在100例样本上的报告质量对比。A为三个维度评分(内容不当程度、内容缺失程度、潜在危害可能性);B为总分箱线图。采用Friedman检验和Wilcoxon符号秩检验,Bonferroni法校正p值。
解读:
VLS综合评分接近资深医生:中文报告总分VLS为8.02,资深医生8.09;英文报告VLS为7.68,资深医生8.12
VLS在“内容缺失”维度表现突出:70%中文报告无任何信息遗漏,优于初级医生(48%存在少量缺失)
纯VL模型安全性堪忧:VL总分最低(中文6.64,英文6.29),且在“潜在危害”维度得分垫底——说明没有SAM的视觉“校准”,纯语言模型更易产生幻觉和危险建议
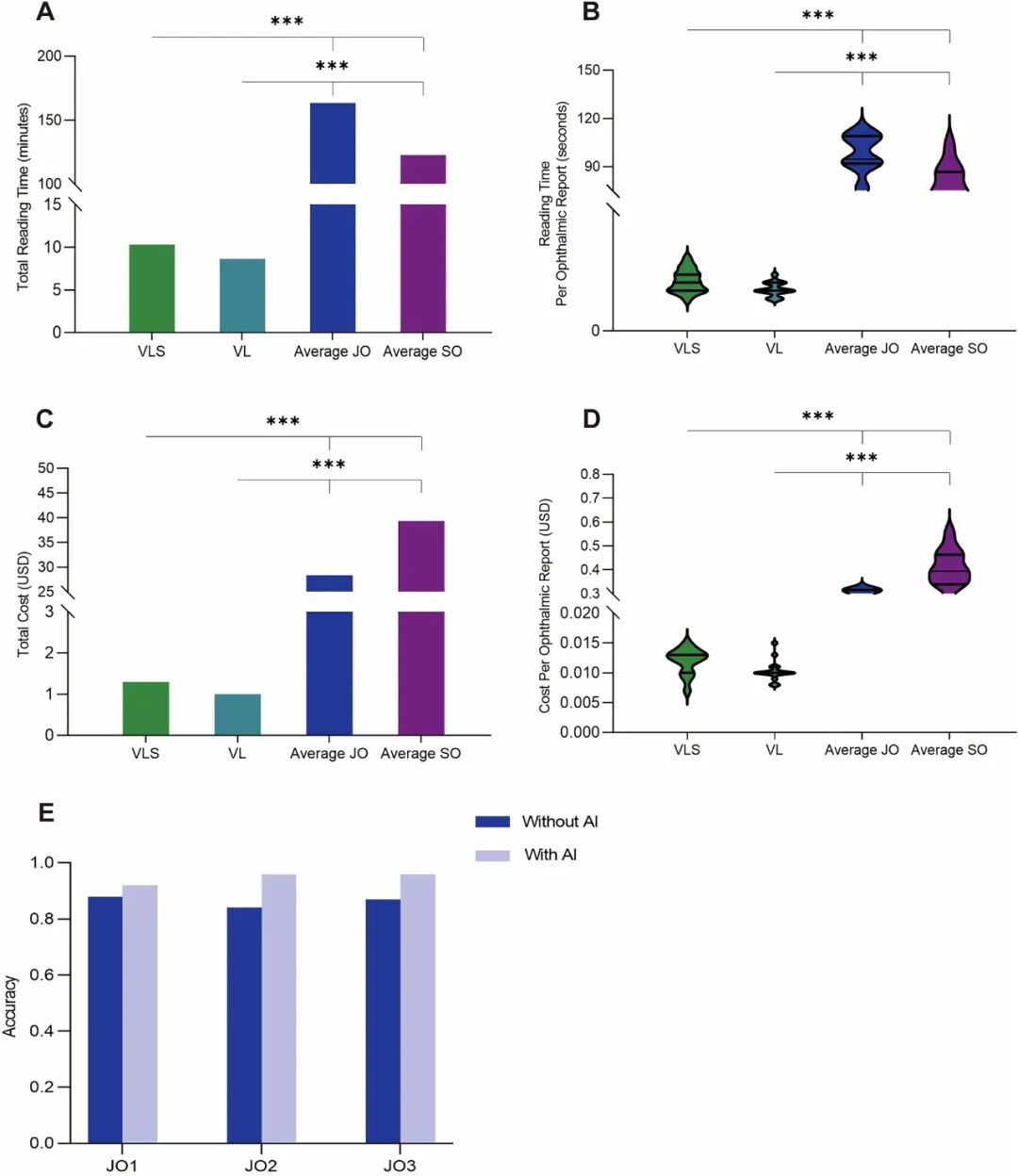
图7|效率、成本与诊断性能的综合对比
图注:AI辅助眼科超声解读的效率、成本及诊断性能。A为总阅读时间(秒);B为单份报告阅读时间小提琴图;C为总成本(美元);D为单份报告成本小提琴图;E为三名初级医生在有无AI辅助下对200例病例的诊断准确率。
解读:
时间革命:初级医生阅片总耗时约163分钟,VLS仅需10.3分钟,效率提升15倍以上;单份报告从98秒压缩至6.2秒
成本断崖:资深医生总成本约$339,VLS仅$31;单份报告从$39降至$1.3——这是AI在真实医疗经济学中的有力佐证
人机协同最优:三名初级医生借助AI后,准确率分别从88%→92%、84%→96%、87%→96%,平均提升8.3个百分点——AI不是替代医生,而是让“普通医生”拥有“专家级”的诊断水平
课题申报指南
Step 1|找准临床痛点,锚定“流程闭环”缺口
思路提炼:本研究直击眼科超声两大痛点——①报告书写耗时(资深医生单份70秒);②AI输出“黑箱化”(只给结论,不给依据)。由此锁定“分割+报告”一体化需求。
申报启示:在申报书中明确陈述:“当前XX检查的报告生成高度依赖人工,且现有AI工具缺乏可解释性。本研究拟构建‘定位-诊断-报告’全链条模型,实现从图像到图文报告的无缝输出。”
Step 2|构建“图文配对”数据集,强化标注质控
思路提炼:研究者从PACS系统提取64,098张图像和21,355份真实报告,由3名5年以上经验医生标注,再由2名10年以上资深医生复核。
申报启示:
数据量不是唯一关键,标注质量才是——申报书中需详细说明质控流程(如“双人独立标注+第三人仲裁”)
预留外部验证集——至少2个独立中心数据,证明泛化能力
伦理前置——回顾性数据可申请豁免知情同意,但需伦理批件;前瞻性验证需签署知情同意
Step 3|采用“成熟模块+轻量适配”技术路线
思路提炼:研究者并未从头训练模型,而是选用Qwen2.5VL和LLaVA作为基座,通过LoRA技术进行低成本微调;SAM模型直接零样本使用,未做针对性训练。
申报启示:
技术路线描述模板:“采用预训练VLM作为视觉编码器-文本解码器基座,通过LoRA低秩适配实现领域迁移;引入SAM作为即插即用的分割模块,以VLM输出的边界框作为空间提示”
算力成本可控:2块V100 GPU即可完成训练,适合大多数三甲医院科研平台
Step 4|设计“技术+临床”双维度评估体系
思路提炼:本研究评估体系涵盖技术指标(BLEU、ROUGE、Dice、F1)、临床质量(三位初级+三位资深医生盲法评分)、经济学指标(时间成本、费用成本)、人机对比(200例前瞻性验证)。
申报启示:
技术指标:选NLP领域公认指标(BLEU/ROUGE)+ 分割领域Dice系数
临床指标:设计“内容完整性、不当内容占比、潜在危害度”三维Likert量表
经济学指标:计算单份报告时间/成本,这是打动医院管理层的“杀手锏”
人机协同验证:设置“医生独立诊断 vs 医生+AI辅助诊断”对照,量化AI的增量价值
Step 5|预留“多模态扩展”和“实时学习”接口
思路提炼:讨论部分明确指出未来方向——整合OCT、眼底照相等多模态数据,纳入病史和临床笔记,构建“眼科全流程AI助手”。
申报启示:
短期目标:完成单一模态(如超声)的“分割+报告”模型
中期目标:拓展至OCT、眼底彩照,建立统一的多模态表征空间
长期愿景:接入电子病历系统,实现“影像+文本+结构化数据”联合推理
申报话术:“本研究为构建眼科多模态大模型奠定基础,所提出的‘定位-描述’耦合框架可迁移至放射、病理等领域”
附|可直接引用的“创新点”表述
方法学创新:“首次将VLM的开放词汇理解能力与SAM的零样本分割能力在眼科超声领域耦合,实现病灶定位与报告生成的端到端闭环”
验证体系创新:“构建‘内部测试+双中心外部验证+前瞻性人机对比’三级证据链,覆盖技术指标、临床评分、经济学评价三个维度”
可解释性创新:“以SAM输出的高分辨率掩码作为视觉证据,将VLM生成的文本描述锚定于图像空间,有效抑制语言模型的幻觉现象”
关于我们
清璟AI由国内TOP2高校医工交叉博士联合创立,专注于医疗大模型科研、影像组学、病理组学、深度学习、AI智能体、生信分析、多组学、多模态和各类人工智能算法。致力打造一站式Al+医学科研生态圈,提供专业的AI智能体、高端科研资源及一对一定制化服务。我们的服务涵盖从科研方案设计、数据处理到AI模型训练及系统开发等各个领域,旨在为医学研究者和临床医生提供全方位的支持与创新解决方案。携手清璟AI,让科研更智能,让医学更精准。

科研合作请联系
长按二维码加微信

