 夜雨聆风
夜雨聆风上个月,大模型领域的佼佼者 Anthropic 公司发布了一篇极具指导意义的技术文章《Common workflow patterns for AI agents—and when to use them》。这篇文章并没有堆砌高深的数学公式,而是从工程实践的角度,系统性地梳理了构建 Agent 工作流的几种核心模式。它告诉我们,构建一个成功的 Agent 系统,关键不在于追求极其玄学的自主性,而在于如何通过科学的工作流设计,让LLM在大模型能力的边界内发挥最大效用。
核心背景:从魔法回归工程
在Agent概念刚兴起时,很多人将其想象成一个能够独立思考、自动解决所有问题的黑盒。然而,现实中的工程落地往往充满了挫败感。Anthropic 在文章中开宗明义地指出,所谓的Agent系统,本质上是大型语言模型(LLM)与代码逻辑的结合。
文章要解决的核心问题是:如何平衡系统的灵活性与可靠性。一个完全由大模型自主控制的系统虽然看起来很酷,但在实际生产中往往因为不可预测性而难以大规模应用。相反,过度硬编码的逻辑又失去了AI的灵活性。因此,Anthropic 提出了一套基于构建块的思维方式,通过组合不同的工作流模式,来实现既强大又可控的 Agent 系统。
基础基石:增强型LLM
在深入探讨复杂模式之前,我们必须理解Agent系统的基本单元:增强型LLM。这并不是一个简单的模型调用,而是一个集成了搜索、计算、文件阅读等工具,并拥有记忆能力的综合体。
在这种基础模式下,模型不再是孤军奋战。我们可以为它配置一套工具集,让它根据用户的输入决定何时调用工具。这种模式的成功关键在于提示词的质量和工具接口的简洁性。它是所有复杂工作流的起点,也是最容易上手、见效最快的方式。
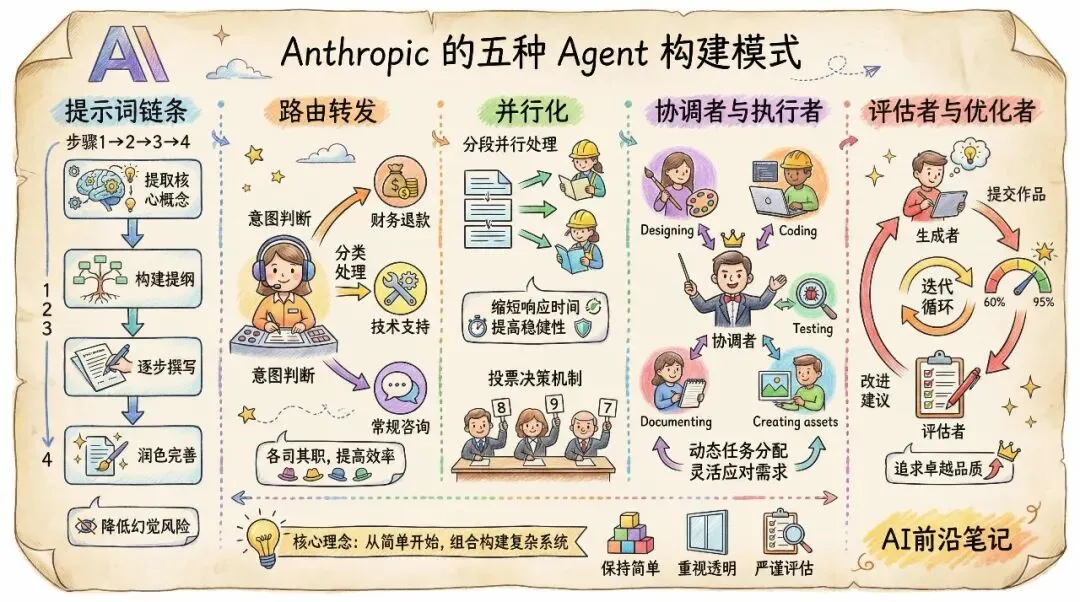
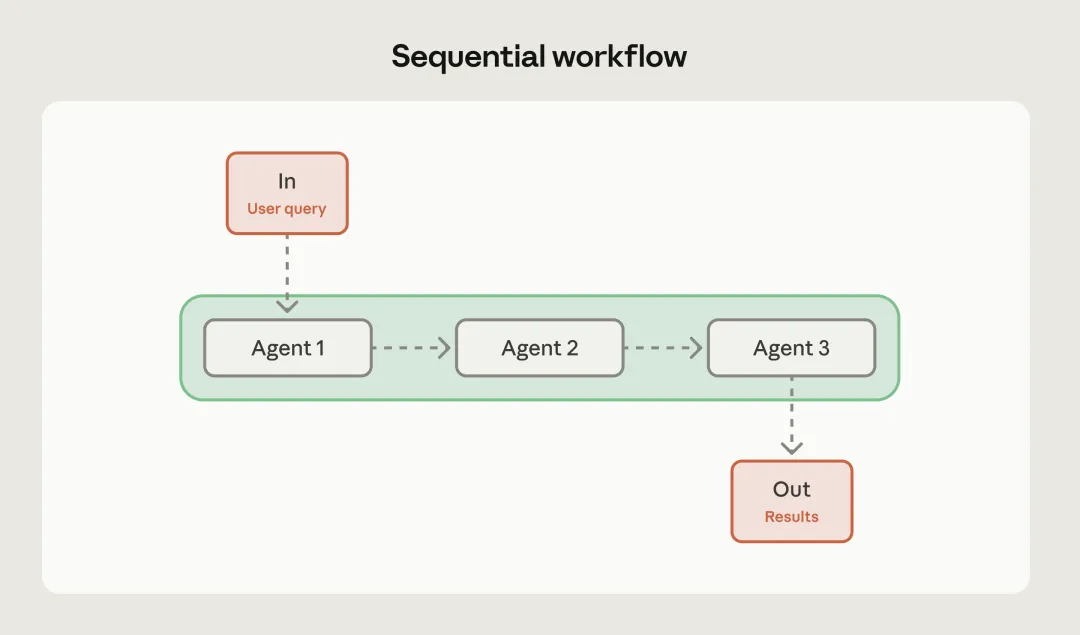
模式一:提示词链条(Prompt Chaining)
这是最基础也最实用的模式。它的核心思想是将一个复杂的任务拆解成一系列有序的步骤,每个步骤的结果作为下一个步骤的输入。
想象一下,如果你要写一篇关于量子物理的科普文章,如果你直接给LLM一个指令:写一篇量子物理科普。效果可能差强人意。但在提示词链条模式下,工作流可能是这样的:
第一步,由LLM提取量子物理的核心概念;
第二步,针对这些概念拟定一个由浅入深的提纲;
第三步,根据提纲逐节撰写内容;
第四步,对写好的内容进行通俗化润色。
这种模式的优势在于,每一步都有明确的目标,LLM不容易在复杂的长任务中迷失方向。同时,开发者可以在每一步之间加入逻辑检查,确保生成的质量。它极大程度降低了由于任务过重导致的模型幻觉风险。
模式二:路由转发(Routing)
如果说提示词链条是纵向的深入,那么路由模式就是横向的分类。在实际应用中,用户输入的需求往往是多样化的。一个全能的Agent如果用同一套逻辑处理所有请求,效率和精准度都会大打折扣。
路由转发模式就像是一个经验丰富的分拣员。它首先利用LLM判断用户意图,然后将任务分发给最适合的处理逻辑或专门的Agent分支。
例如,在一个客户支持系统中,路由节点会判断:这是一个关于退款的投诉吗?还是一个关于产品安装的技术咨询?如果是退款,它会路由到专门处理财务逻辑的分支;如果是技术咨询,它会调用技术文档数据库进行检索。这种模式确保了系统能够各司其职,避免了资源的浪费,也提高了处理速度。
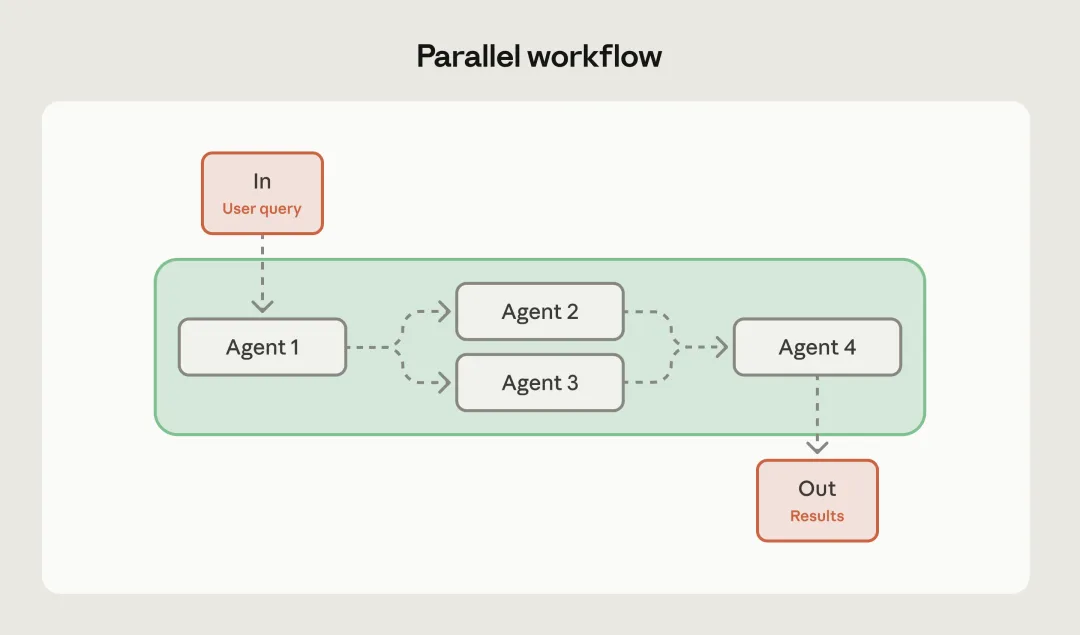
模式三:并行化(Parallelization)
在某些场景下,我们需要同时从多个维度处理同一个问题。并行化模式提供了两种主要的玩法:分段处理和投票决策。
分段处理就像是工业流水线上的多线并进。例如,在对一份长达百页的法律合同进行风险评估时,我们可以将合同切分成若干章节,让多个LLM并行阅读,最后汇总结果。这极大地缩短了响应时间。
而投票决策则更像是一个评审团。对于一些逻辑极其复杂或者没有唯一标准答案的任务(如代码审查或创意写作评估),我们可以让多个模型独立生成答案,再通过另一个模型进行汇总和择优。这种少数服从多数或多方博弈的机制,能显著提高输出结果的稳健性。
模式四:协调者与执行者(Orchestrator-Workers)
这是处理不可预测任务的高级模式。在这种模式下,有一个中心化的协调者(Orchestrator),它负责拆解任务、分发给执行者(Workers),并最后收集汇总结果。
与简单的提示词链条不同,协调者不需要预先知道所有的执行步骤。它会根据当前的任务进展,动态地决定下一步该做什么。这种模式非常适合复杂的软件开发任务或深度的学术调研。
比如,当用户要求开发一个小型网页时,协调者会先让一个Worker生成设计方案,根据方案再让另一个Worker写代码,如果写代码的过程中发现需要特定的图标,协调者会临时增加一个生成图标的任务。这种灵活性使得系统能够应对高度不确定的需求,但也对协调者的逻辑拆解能力提出了极高要求。
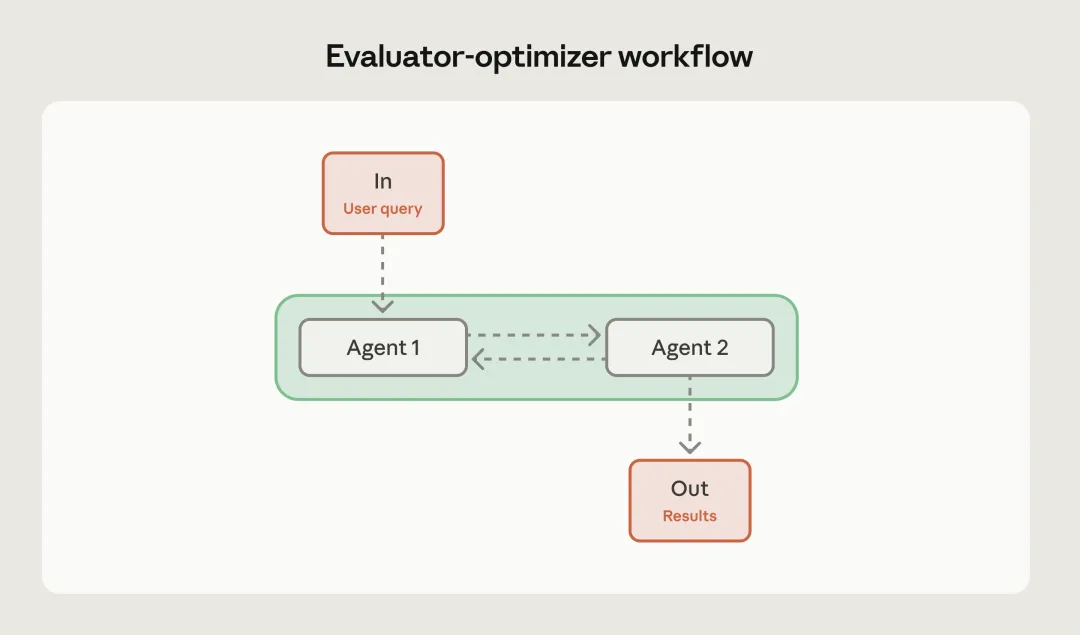
模式五:评估者与优化者(Evaluator-Optimizer)
这是追求卓越品质的终极利器。这种模式建立在一种有趣的观察之上:LLM在评价和修改他人作品时,往往比直接一次性写出完美作品表现得更好。
在这个工作流中,包含一个生成者和一个评估者。生成者产生初步结果,评估者根据预设的标准进行批判性审查并提出改进意见。生成者根据意见进行迭代,直到评估者给出及格甚至满意的分数。
这种循环迭代的模式在文学创作、高精尖代码编写和法律文书校对中表现惊人。它不仅能提升结果的质量,还能在迭代过程中自动修正那些细微的逻辑错误。Anthropic在文章中强调,这种闭环系统是实现高质量Agent的关键所在。
核心中的核心:自主型Agent(Autonomous Agent)
在文章的后半部分,Anthropic终于谈到了最迷人也最复杂的自主型Agent。这种Agent通常在一个持续的循环中运行,它拥有自己的目标、环境感知能力和行动能力。它不断地执行操作、观察环境变化、根据反馈调整策略,直到达成最终目标。
这种模式的典型应用是环境交互,比如自动操作网页浏览器或在本地环境中进行代码调试。然而,Anthropic给开发者打了一剂预防针:虽然自主型Agent非常强大,但在构建它们时,必须保持高度的透明度和可控性。
在自主循环中,最容易出现的问题是逻辑陷入死循环或者行动失控。因此,开发者需要设定严格的终止条件,并且在关键步骤引入人工确认机制。
总结与工程建议
通读全篇,我们可以感受到Anthropic对AI开发者的殷切建议。他们并不鼓励一上来就构建最复杂的自主Agent,而是提倡一种循序渐进的工程美学。
首先,保持简单。如果一个简单的提示词能解决问题,就不要用复杂的Agent工作流。简单的系统更容易维护,延迟更低,也更易于理解。
其次,重视透明度。在设计工作流时,要让每一个步骤的输入和输出都清晰可见。这样在系统出错时,你才能迅速定位是哪个环节出了问题。
最后,严谨的评估。不要被偶尔一次成功的惊艳表现所迷惑,要通过大量的自动化测试和基准测试来评估Agent系统的稳定性。
总而言之,Anthropic这篇文章为我们揭示了Agent开发的真相:它不是一种黑魔法,而是一门关于如何精巧组合LLM能力的工程艺术。通过理解和运用提示词链条、路由、并行化、协调者以及评估优化这五大模式,开发者能够构建出既具备AI灵活性,又具备工业级可靠性的Agent系统。
这场AI变革的竞赛,胜者往往不是那些拥有最复杂想法的人,而是那些能够通过稳健的工作流设计,将模型能力最大化转化为用户价值的人。
结语
Agent系统的构建正在从艺术走向科学。Anthropic通过对工作流模式的系统梳理,为开发者指明了方向:不要迷信单一的超级Agent,而要相信组合的力量。通过简单的构建块,我们终将搭建出改变世界的复杂智能系统。
感兴趣的可以阅读文章:https://claude.com/blog/common-workflow-patterns-for-ai-agents-and-when-to-use-them

