 夜雨聆风
夜雨聆风一、 前情提要
由于原有的 Coding Plan 套餐用尽,我转而使用注册智谱时赠送的资源包。
初始阶段:先使用了 GLM-4.5-air 资源包(共 1,200 万 Token),直到昨天正式用完。 切换过程:昨天 18:18,我切换至 GLM-4.6V 资源包,随后并未进行操作。 异常情况:今早使用时发现,资源包已经用尽(共600 万 Token )。 
二、 消耗原因排查
这种消耗速度实在令人心惊,我甚至一度怀疑是权限控制没做好,被他人刷了。
为了查明真相,我进行了原因排查:
账单明细分析
通过查看账单明细,发现token于凌晨1点50分彻底用完。 并请求呈现出极其规律的特征:约每 30 分钟就会发送八九条请求。 据此推测,这极有可能是 OpenClaw 的心跳机制在后台运行。 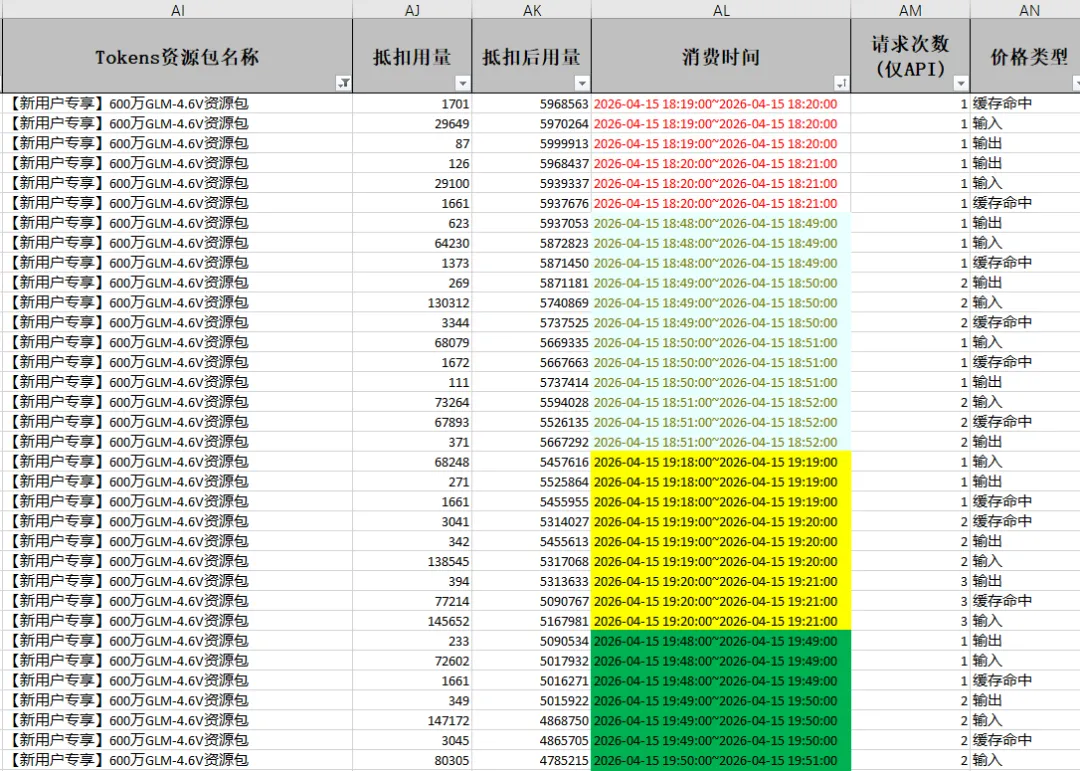
openclaw控制台确认
检查控制台后确认,确实每隔 30 分钟会有一次心跳交互,且单次消耗很大。
参数详情:图中单次交互的 Input Token 为 25.2w,而 Output Token 为 240。 计算结论:这意味着单次心跳就吞掉了 25 万 Token。按此速度计算,600 万 Token 确实撑不了多久。 性能影响:此时 ctx(上下文)占用率已达 100%,意味着触及了模型的最大上下文长度限制。当达到满额 ctx 时,模型不仅会变笨、丢失部分远端上下文,响应速度也会明显变慢。 当前版本:OpenClaw 版本为 v2026.4.9,引入了 REM Backfilling(梦境回填) 机制,Agent 会尝试在心跳期间处理更多的“历史上下文”来构建记忆。
三、 原因分析
OpenClaw 的工作机制
基于 OpenClaw 的全量上下文工作机制,对话历史记录是无损携带的。
模型会将之前的聊天内容、系统指令以及当前项目文件全部打包发送。
当这些内容堆叠到上限且没有及时重置时,每次简单的交互(包括心跳)都会传送海量数据。
为什么使用 GLM-4.5-air 时没有出现该问题?
首先来看配置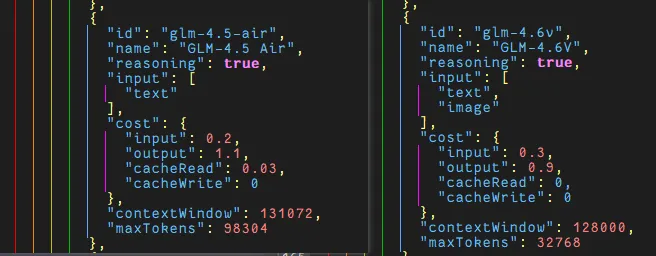
cacheRead:模型提供商把计算结果暂时存起来。当你再次发送相同内容时,模型直接“读取”缓存,而不需要重新计算。 glm-4.5-air 配置的cacheRead为0.03,而GLM-4.6v 配置的cacheRead为0,代表此功能费用为0,或者不支持缓存 而经过后续查证:GLM-4.6v 拥有“自动缓存识别”功能,只要你发送的内容重合度高,系统会自动触发缓存。 理论上,cacheRead不会额外消耗token费用
模型策略差异
OpenClaw 的 Agent 策略适配主要通过一套内置的规则引擎(Strategy Router),来决定对模型是进行“精简摘要(Summarization)”还是“全量投喂(Raw Feed)”。
GLM-4.5-air 版本:其设计初衷是追求高性价比与低延迟,上下文窗口相对较小,系统会自动进行截断或丢弃。因此,OpenClaw 会对这种“小容量”模型强制执行滑动窗口策略,将 Token 消耗维持在一个动态平衡的水平,不会无限上涨,并配合使用精简版指令。 GLM-4.6V 版本:该版本支持超长上下文,系统默认不会主动裁剪,而是倾向于将所有资料全量喂给模型。由于它被识别为“大容量/推理”模型,OpenClaw 会将所有历史记录堆叠在一起,并注入极长的 Chain-of-Thought (CoT) 提示词以确保准确度。
四、 总结
虽然 “大容量/推理”模型(如GLM-4.6V) 的能力更强、准确度更高,但在全量上下文机制下,这种“不裁剪”的特性配合高频心跳,直接导致了 Token 的爆炸式消耗。若在按量计费模式下运行,这种消耗速度堪称‘成本黑洞’。”
