 夜雨聆风
夜雨聆风引言
前几篇文章,我们认识了感知机、Sigmoid和ReLU。它们像一个个独立的“神经元”,会接收信号、做加权求和、然后决定要不要“激活”。但单个神经元只能解决最简单的问题——比如判断“是不是两个输入都是1”。想要识别图片里有没有猫,我们需要把成千上万个神经元串联起来,组成一个多层网络。
那么问题来了:当一张图片进入这个庞大的神经元网络时,数据到底是怎么“流动”的?AI又是如何从像素点一步步“看”出“这是一只猫”的?
今天,我们就把这个过程画成一张“地铁线路图”,再用Python模拟一次完整的前向传播。读完这篇文章,你会明白:AI的“一眼看穿”,其实是一层一层的“流水线作业”。
前向传播,就像工厂的流水线。
想象一个汽车制造工厂:
第一道工序:把钢板冲压成车门。
第二道工序:把车门焊接到车架上。
第三道工序:给车身喷漆。
最后一道工序:装上轮胎,整车下线。
每一道工序都只负责自己的任务,然后把半成品交给下一道工序。神经网络的前向传播,就是这样一个层层传递、逐步加工的过程。
把“输入图片”想象成原材料钢板,把“最终分类结果”想象成成品汽车。中间的每一层神经元,就是一道道工序:
输入层:接收原始像素值(比如28×28=784个数字)。
隐藏层:对输入做加权求和、激活,提取特征。
输出层:给出最终判断(比如猫的概率0.82,狗的概率0.15)。
数据从输入层进入,经过隐藏层的一步步加工,最终从输出层流出——这个单向流动的过程,就叫前向传播(Forward Propagation)。
一个三层神经网络的“解剖图”
为了更直观,我们画一个最简单的三层网络:
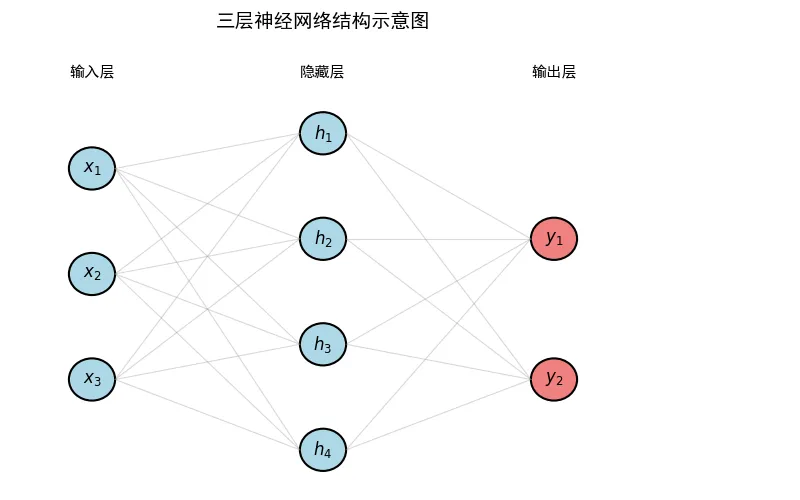
箭头代表权重(每条连接线都有一个数字,代表“影响力”)。
每个神经元内部做两件事:加权求和(把所有输入乘以权重相加,再加偏置),然后过激活函数(比如ReLU或Sigmoid)。
这个网络的结构用数学语言写出来就是:
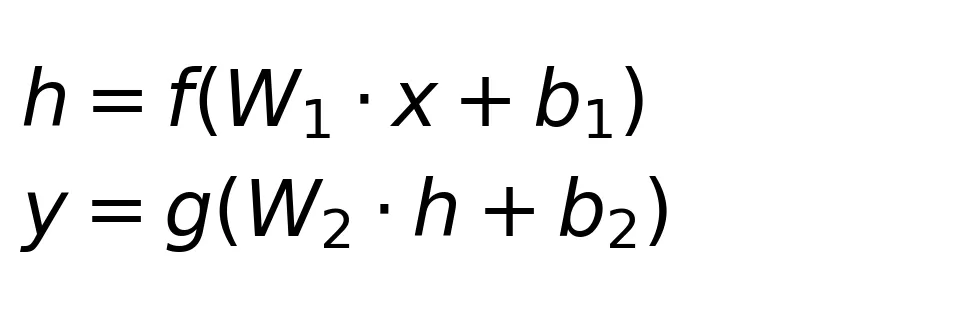
其中 W1 和 W2 是权重矩阵,b1 和 b2 是偏置向量。
动手环节:用Python模拟一次前向传播
光说不练假把式。下面我们用NumPy写一个三层网络,随机初始化权重,然后输入一张“假图片”(一个3维向量),看看数据是如何一层层流动的。
import numpy as np# 设置随机种子,让每次运行结果一致np.random.seed(42)# ---------- 网络结构定义 ----------# 输入层:3个神经元# 隐藏层:4个神经元# 输出层:2个神经元# 随机初始化权重和偏置(模拟训练好的网络)W1 = np.random.randn(3, 4) # 3x4 矩阵,连接输入层到隐藏层b1 = np.random.randn(4) # 隐藏层偏置(4个)W2 = np.random.randn(4, 2) # 4x2 矩阵,连接隐藏层到输出层b2 = np.random.randn(2) # 输出层偏置(2个)# 定义激活函数(这里隐藏层用ReLU,输出层用Sigmoid)def relu(x):return np.maximum(0, x)def sigmoid(x):return 1 / (1 + np.exp(-x))# ---------- 前向传播 ----------def forward(x):# 第一段:输入 → 隐藏层z1 = np.dot(x, W1) + b1 # 加权求和a1 = relu(z1) # ReLU激活print("隐藏层加权和 z1:", z1)print("隐藏层激活值 a1:", a1)# 第二段:隐藏层 → 输出层z2 = np.dot(a1, W2) + b2 # 加权求和a2 = sigmoid(z2) # Sigmoid激活,得到最终概率print("输出层加权和 z2:", z2)print("输出层概率 a2:", a2)return a2# 模拟一张“图片”(3个特征值)x_input = np.array([0.5, 0.2, 0.9]) # 比如三个像素点的亮度值print("输入向量 x:", x_input)print("="*40)output = forward(x_input)print("="*40)print("最终输出概率:", output)
运行结果示例(你的数值会略有不同):
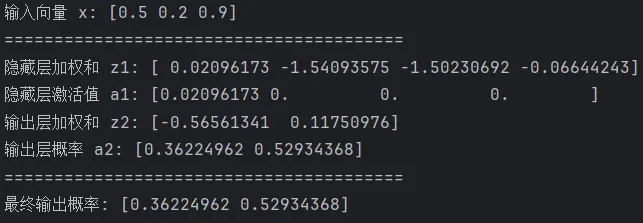
解读一下数据的“旅程”:
输入的3个像素值 [0.5, 0.2, 0.9] 乘以权重矩阵 W₁,加上偏置 b₁,得到隐藏层的“原始信号” z1:
z1 经过ReLU,负数被清零,得到激活值 a1。注意后三个神经元因为输入为负而被彻底“关闭”了,只有第一个神经元保留了一个微弱的正信号 0.02。这就是 ReLU 的稀疏激活性——每次只点亮极少数神经元。
接着,a1 再乘以权重矩阵 W₂,加上偏置 b₂,得到输出层的原始信号 z2。
z2 经过Sigmoid,被压缩成0到1之间的概率。
最终网络认为:第一类的概率是 36%,第二类的概率是 53%。如果这是一个二分类任务(比如猫/狗),网络会倾向于预测这张“图片”属于第二类——虽然信心不算特别强,但已经有了明确的偏向。
整个过程,从输入到输出,数据只向前流动,不回头——这就是“前向传播”的全部秘密。
前向传播在YOLO里是怎么跑的?
在我们熟悉的YOLO模型,前向传播的过程要复杂得多(几百层卷积),但核心逻辑完全一样。一张416×416×3的图片进入网络后:
Backbone:经过几十层卷积+BN+激活(通常是SiLU或ReLU),逐步提取边缘、纹理、语义特征。
Neck:对不同尺度的特征图进行融合。
Head:最后输出三个尺度的检测结果,每个网格预测边界框坐标、置信度和类别概率。
虽然YOLO有上千万个参数,但每一次推理(inference)都是一次标准的前向传播:数据单向流动,没有反向传播的梯度计算,所以速度极快。你在YOLO里运行 model.predict(),本质上就是让数据跑了一遍上面那个 forward() 函数的“超级加长版”。
一张图总结:前向传播的“流水线”
如果要用一句话记住前向传播,那就是:
输入 → 加权求和 → 激活 → 加权求和 → 激活 → ... → 输出
每一层都在做同样的事:接收上一层的输出,乘以自己的权重,加上偏置,过激活函数,然后传给下一层。
| 步骤 | 做什么 | 类比 |
|---|---|---|
| ① 加权求和 | z = W·x + b | 把各种意见按重要性综合起来 |
| ② 激活函数 | a = f(z) | 决定要不要把这个意见“传下去” |
| ③ 传递 | a 成为下一层的 x | 把半成品交给下一道工序 |
明天,我们会反过来走一遍:如果AI预测错了怎么办?它怎么知道自己错在哪,又怎么去修正权重?这就是反向传播的故事——也是神经网络“学习”的核心。
