 夜雨聆风
夜雨聆风
在人工智能大模型(LLM)的狂飙突进中,技术创新与知识产权的跑马圈地同步进行。对于AI企业而言,了解底层技术的专利布局,不仅是技术研发的必修课,更是防范侵权风险、进行FTO(自由实施)尽职调查的法律前提。
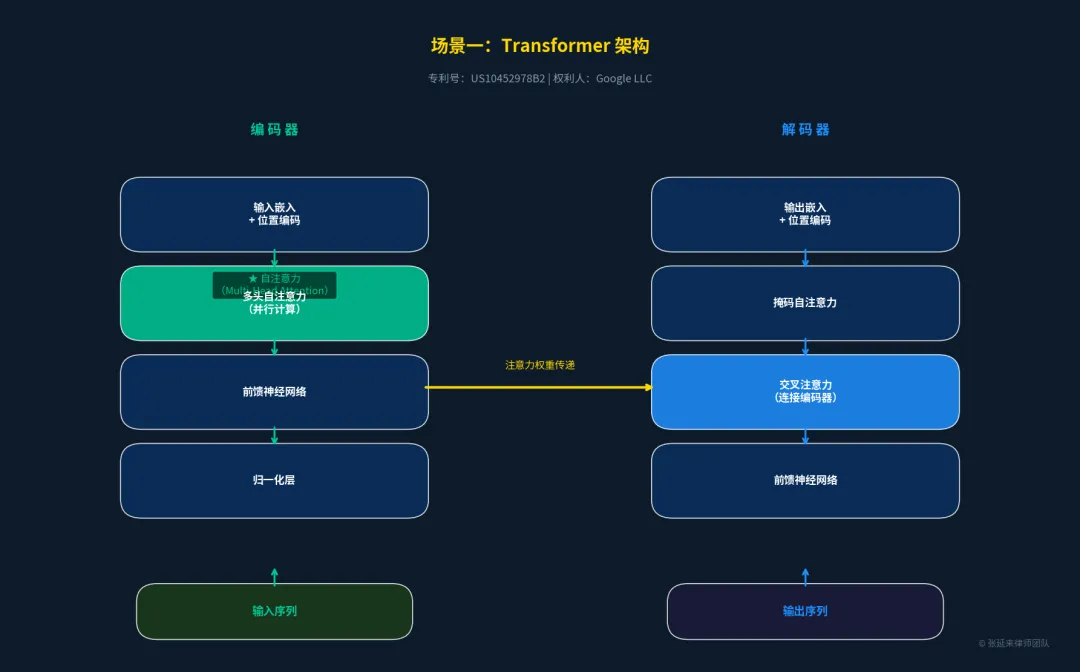
场景一:基础架构层 —— Transformer 自注意力机制
Transformer架构是现代大模型的绝对基石。它彻底抛弃了传统的RNN/CNN循环结构,引入了“自注意力机制”(Self-Attention),使得模型能够并行处理序列数据,极大地提升了训练效率和长文本理解能力。
权威出处与专利信息:
•专利号:US10452978B2 [1]
•专利名称:Attention-based sequence-to-sequence neural networks
•权利人:Google LLC
•核心保护点:基于多头自注意力机制的编码器-解码器网络结构,以及位置编码技术。
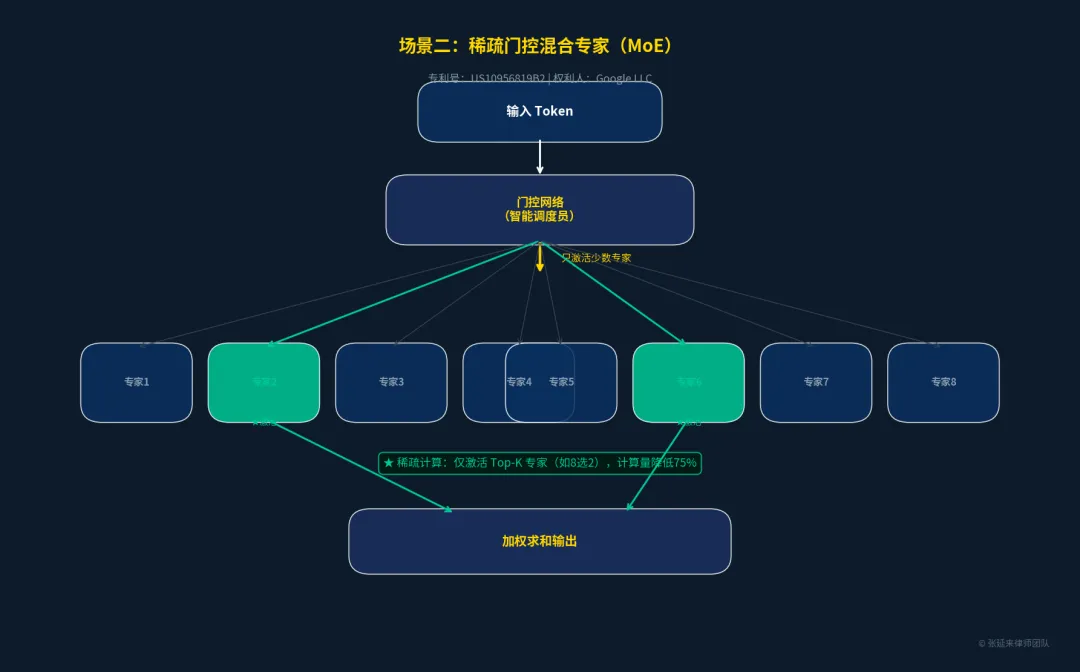
场景二:规模扩展层 —— 稀疏门控混合专家(MoE)
随着模型参数量向万亿级别迈进,计算成本成为巨大瓶颈。混合专家(Mixture of Experts, MoE)技术通过引入“门控网络”,在每次计算时只激活少数几个最相关的“专家”网络,实现了“参数量大增,但计算量不增”的稀疏计算奇迹。
权威出处与专利信息:
•专利号:US10956819B2 [2]
•专利名称:Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
•权利人:Google LLC
•核心保护点:稀疏门控机制的实现方法,以及如何在分布式系统中高效路由Token到不同专家。
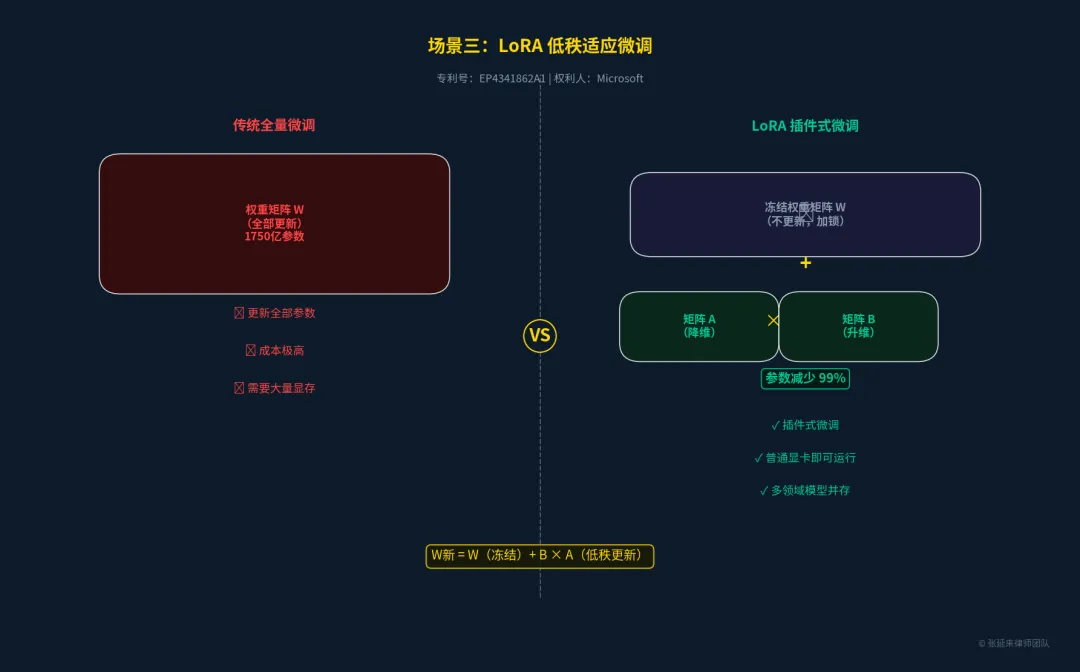
场景三:高效微调层 —— LoRA 低秩适应
面对千亿参数的大模型,全量微调(Full Fine-tuning)成本极高。LoRA(Low-Rank Adaptation)技术巧妙地冻结了预训练模型的原始权重,仅在旁路注入两个低秩矩阵进行训练。这使得微调参数量骤降99%以上,普通消费级显卡即可完成大模型微调。
权威出处与专利信息:
•专利号:EP4341862A1 [3]
•专利名称:Low-rank adaptation of large language models
•权利人:Microsoft Technology Licensing, LLC
•核心保护点:在冻结的预训练权重旁,并行添加可训练的低秩分解矩阵的微调架构。
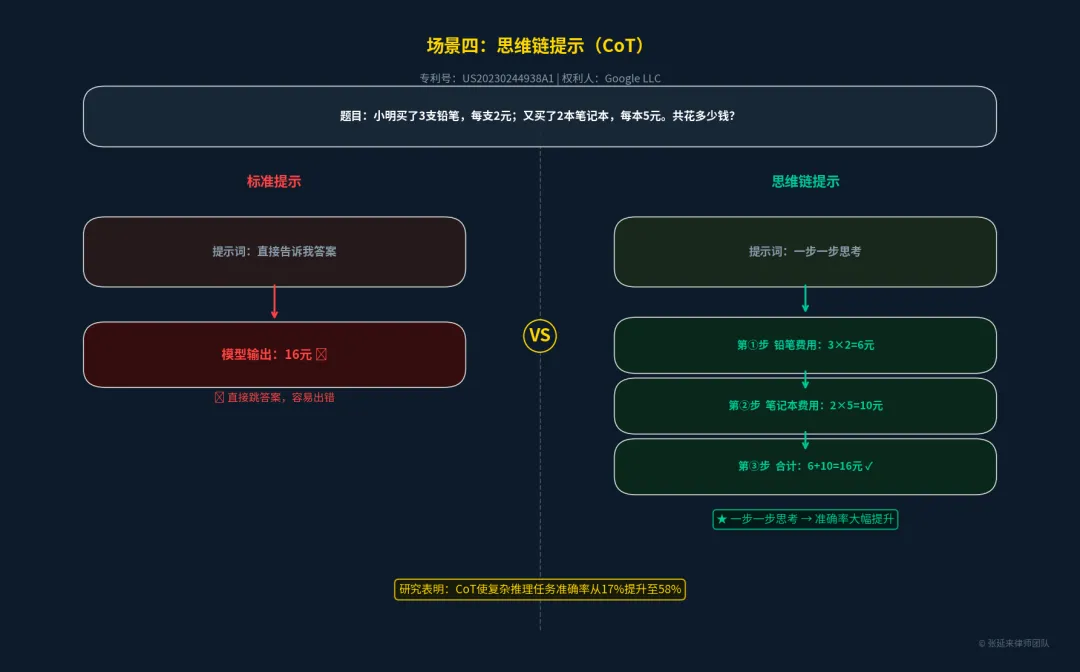
场景四:推理增强层 —— 思维链提示(CoT)
大模型在处理复杂数学或逻辑推理时容易出错。思维链(Chain of Thought, CoT)技术通过在提示词中加入“一步一步思考”(Let's think step by step)的引导,迫使模型展示中间推理过程,从而大幅提升了复杂任务的准确率。
权威出处与专利信息:
•专利号:US20230244938A1 [4]
•专利名称:Chain of thought prompting for language models
•权利人:Google LLC
•核心保护点:通过提供包含中间推理步骤的示例,引导语言模型生成结构化推理路径的方法。
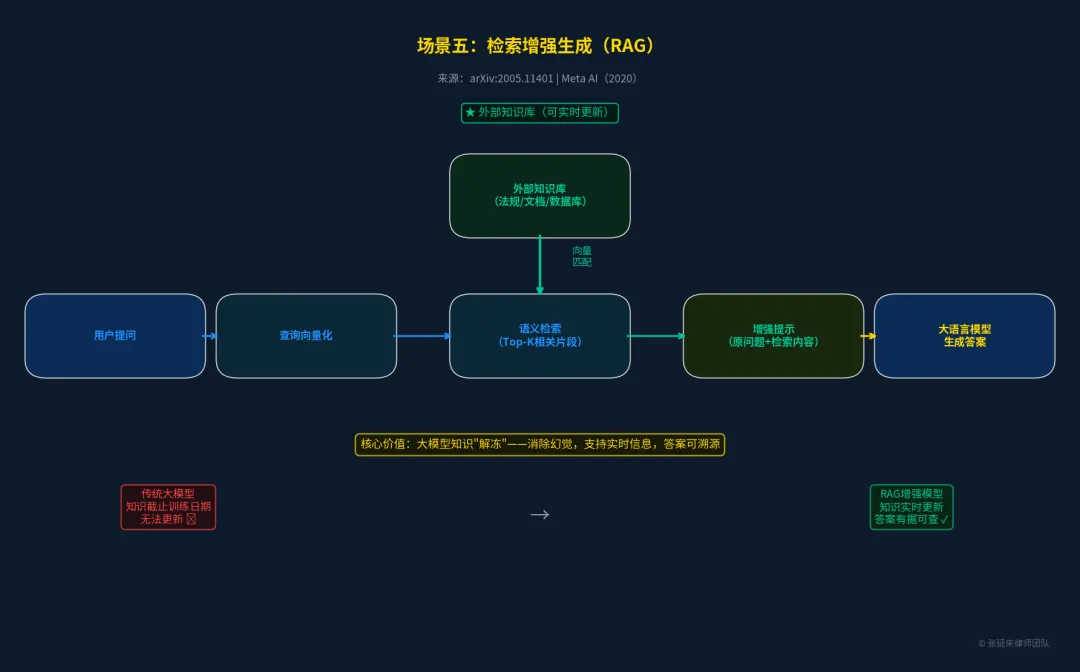
场景五:知识注入层 —— 检索增强生成(RAG)
大模型的知识受限于训练数据的截止日期,且容易产生“幻觉”。RAG(Retrieval-Augmented Generation)技术将外部知识库检索与大模型生成相结合。模型在回答前,先从知识库中检索相关片段作为上下文,从而实现知识的实时更新和答案的可溯源。
权威出处与专利信息:
•来源:学术论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 [5]
•发布机构:Meta AI (Facebook AI Research), 2020
•状态:作为开源学术成果广泛应用,是目前企业级AI落地的最核心架构。
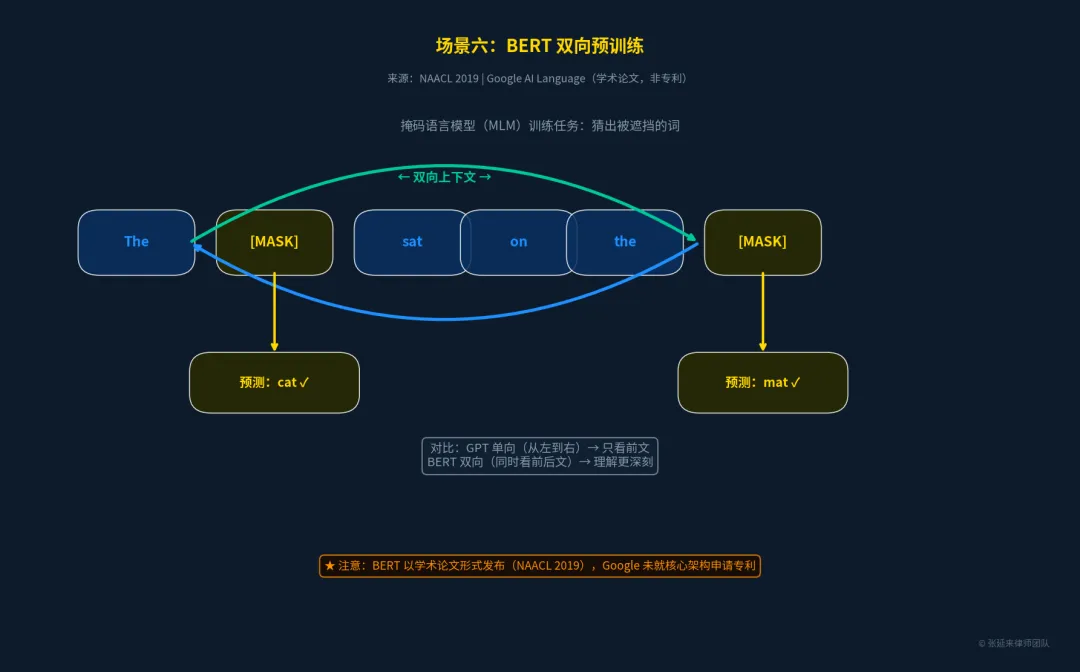
场景六:语言理解层 —— BERT 双向预训练
在生成式大模型(如GPT)爆发前,BERT统治了自然语言理解(NLU)领域。它首创了“掩码语言模型”(MLM)任务,通过随机遮挡句子中的词并让模型预测,迫使模型同时学习上下文的双向信息,实现了对语言的深刻理解。
权威出处与专利信息:
•来源:学术论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》 [6]
•发布机构:Google AI Language, NAACL 2019
•状态:BERT核心架构以学术论文形式开源发布,Google并未就此申请基础专利。 这使得BERT成为NLP领域最广泛使用的开源基座之一。
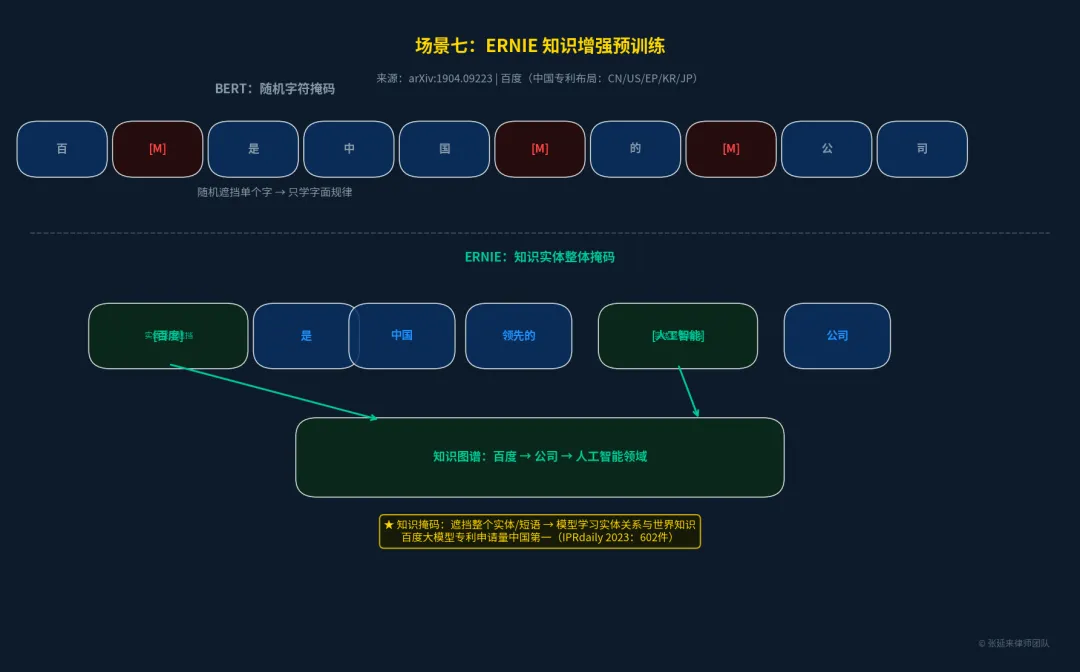
场景七:中文NLP层 —— ERNIE 知识增强预训练
针对BERT随机遮挡单个汉字导致模型无法学习完整实体概念的缺陷,百度提出了ERNIE(Enhanced Representation through Knowledge Integration)。ERNIE创新性地引入了“知识掩码”策略,将完整的实体(如人名、地名、机构名)或短语作为一个整体进行遮挡。这迫使模型在预训练阶段就学习到实体间的关系和世界知识,大幅提升了中文NLP任务的表现。
权威出处与专利信息:
•中国核心专利:CN111552821B、CN111914556B 等系列专利 [7]
•美国专利申请:US20210374334A1 [8]
•权利人:百度(Baidu)
•核心保护点:基于实体级和短语级知识掩码的预训练语言模型训练方法。
•行业地位:据IPRdaily统计,百度大模型专利申请量和授权量连续多年位居中国第一。
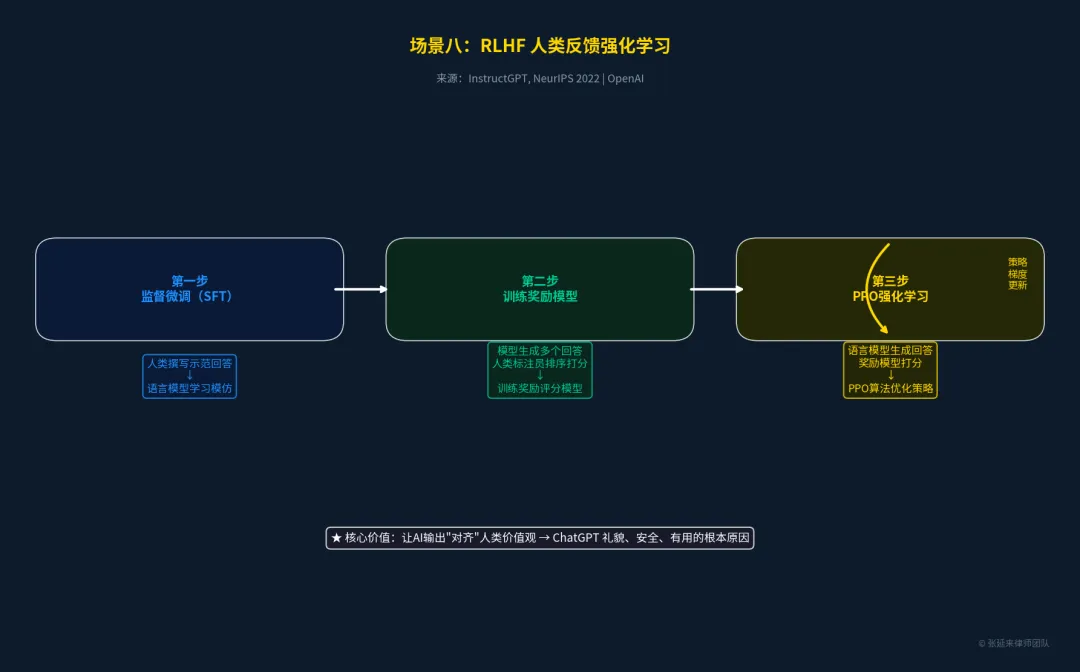
场景八:安全对齐层 —— RLHF 人类反馈强化学习
如何让大模型不仅“聪明”,而且“听话”、“安全”?RLHF(Reinforcement Learning from Human Feedback)是ChatGPT取得巨大成功的关键。它通过收集人类对模型回答的偏好排序,训练一个奖励模型(Reward Model),再利用PPO强化学习算法不断优化大模型的输出策略,使其对齐人类价值观。
权威出处与专利信息:
•来源:学术论文《Training language models to follow instructions with human feedback》 [9]
•发布机构:OpenAI, NeurIPS 2022
•状态:OpenAI在RLHF及相关对齐技术上进行了密集的专利布局。
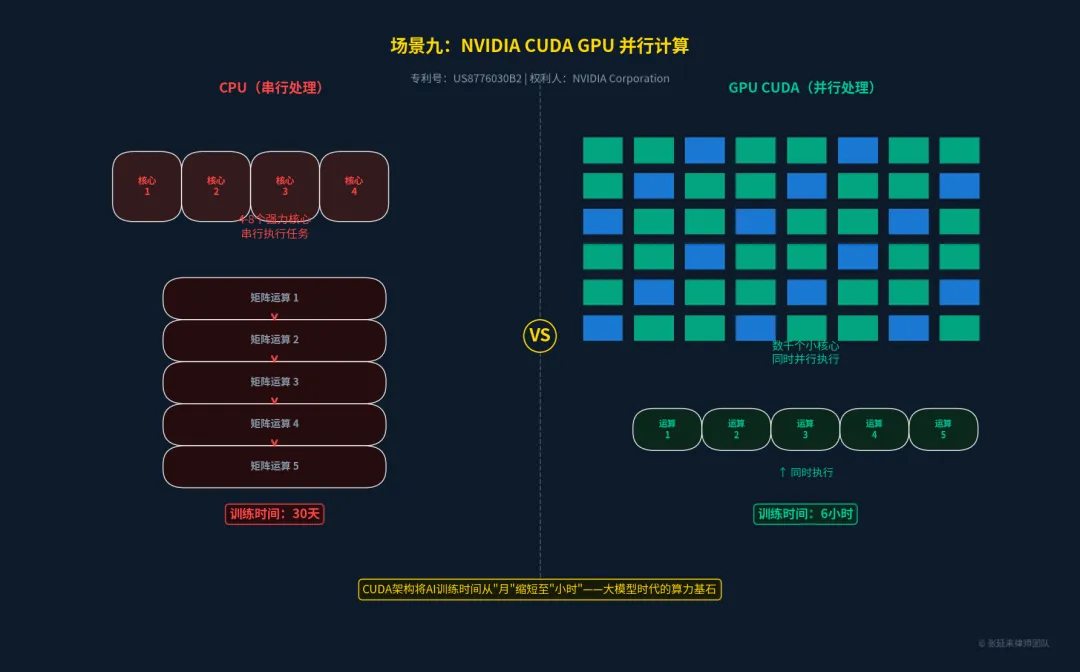
场景九:硬件基础层 —— NVIDIA CUDA 并行计算
大模型的训练离不开海量算力。NVIDIA的CUDA架构彻底改变了计算范式,它允许开发者直接调用GPU中数以千计的小核心,进行极其高效的矩阵并行运算。没有CUDA,大模型的训练时间将从现在的“周/月”级别退化到“年/世纪”级别。
权威出处与专利信息:
•专利号:US8776030B2 [10]
•专利名称:Parallel processing architecture
•权利人:NVIDIA Corporation
•核心保护点:GPU流式多处理器(SM)架构及线程块调度机制。
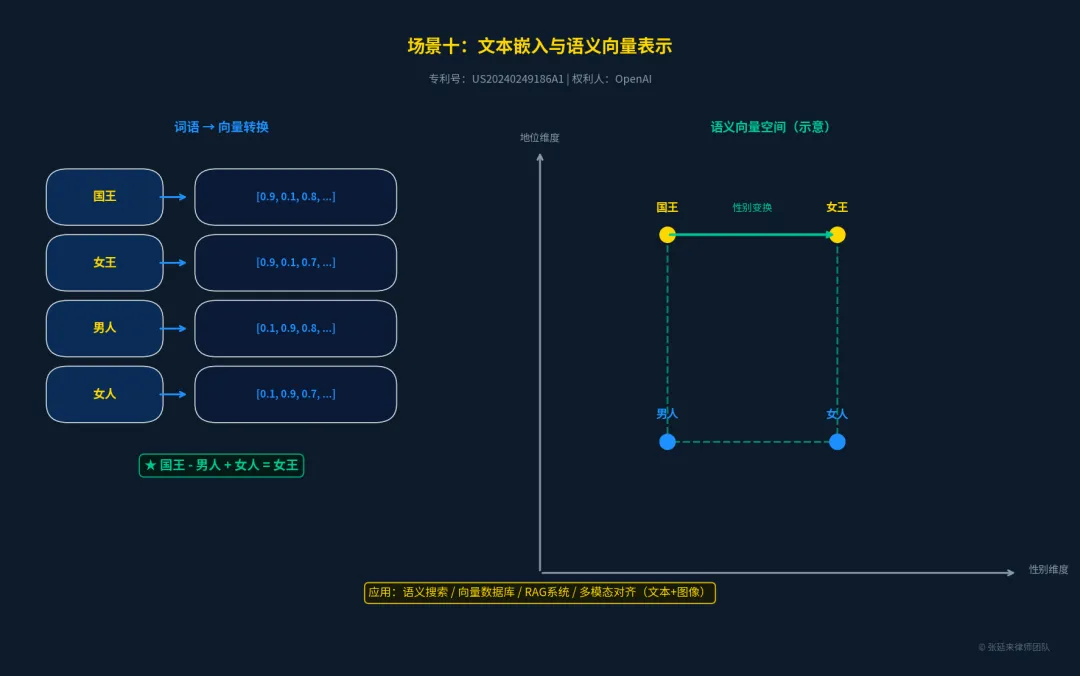
场景十:语义表示层 —— 文本嵌入向量化
大模型如何“理解”文字?答案是将其转化为高维空间中的向量(Embeddings)。在这个空间中,语义相近的词距离更近,甚至可以进行数学运算(如著名的“国王 - 男人 + 女人 = 女王”)。高质量的嵌入模型是RAG检索、语义搜索和多模态对齐的基础。
权威出处与专利信息:
•专利号:US20240249186A1 [11]
•专利名称:Systems and methods for generating text embeddings
•权利人:OpenAI OpCo, LLC
•核心保护点:生成和优化大规模文本嵌入向量的系统架构与对比学习方法。
结语:AI企业的知识产权合规启示
全球AI大模型的基础技术版图已基本确立。从上述十大场景可以看出,Google、OpenAI、Microsoft等美国巨头在底层架构(Transformer)、训练范式(MoE、CoT)和硬件生态(CUDA)上占据了绝对的专利优势。
与此同时,中国企业在知识增强(ERNIE)、中文特色预训练及应用层创新上,也构建了坚实的专利护城河。
对于广大AI创业公司和应用层企业而言,在调用开源模型或开发商业化AI产品时,必须高度重视FTO(自由实施)尽职调查。开源协议(如Apache 2.0、MIT)通常只解决版权问题,并不天然豁免专利侵权风险。深入理解这些绕不开的基础专利,是企业在AI浪潮中安全航行、避免重大诉讼风险的必修课。

参考文献
[1] Google LLC. Attention-based sequence-to-sequence neural networks. US Patent 10,452,978 B2. https://patents.google.com/patent/US10452978B2/en [2] Google LLC. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. US Patent 10,956,819 B2. https://patents.google.com/patent/US10956819B2/en [3] Microsoft Technology Licensing, LLC. Low-rank adaptation of large language models. EP Patent 4,341,862 A1. https://patents.google.com/patent/EP4341862A1/en [4] Google LLC. Chain of thought prompting for language models. US Patent App. 2023/0244938 A1. https://patents.google.com/patent/US20230244938A1/en [5] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401. https://arxiv.org/abs/2005.11401 [6] Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019. https://arxiv.org/abs/1810.04805 [7] 百度网讯科技有限公司. 法律意图搜索方法、法律意图搜索装置和电子设备. CN Patent 111552821 B. https://patents.google.com/patent/CN111552821B/zh [8] Baidu Netcom Science and Technology Co Ltd. Method for training language model, electronic device and readable storage medium. US Patent App. 2021/0374334 A1. https://patents.google.com/patent/US20210374334A1/en [9] Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022. https://arxiv.org/abs/2203.02155 [10] NVIDIA Corporation. Parallel processing architecture. US Patent 8,776,030 B2. https://patents.google.com/patent/US8776030B2/en [11] OpenAI OpCo, LLC. Systems and methods for generating text embeddings. US Patent App. 2024/0249186 A1. https://patents.google.com/patent/US20240249186A1/en
