 夜雨聆风
夜雨聆风Claude/Codex/OpenClaw 记忆横评
Claude Code vs Codex CLI vs OpenClaw调研日期:2026-04-10
1. 设计哲学对比

Claude Code 的哲学最独特:不构建复杂的记忆管理程序,而是通过精心设计的 system prompt 指令让 LLM 自己决定何时、何地创建和使用记忆。记忆操作本质上是 LLM 的 tool use(Read/Write/Edit)。Codex 走工业化路线:用专门的模型做提取(Phase 1: gpt-5.4-mini),再用更强的模型做整合(Phase 2: gpt-5.3-codex),形成"原始信号 → 结构化知识"的流水线。OpenClaw 最工程化:引入 embedding 向量化、混合检索、MMR 多样性重排、时间衰减等 IR(信息检索)领域的经典技术,把记忆检索当作搜索引擎来构建。
2. 存储架构对比
2.1 存储技术
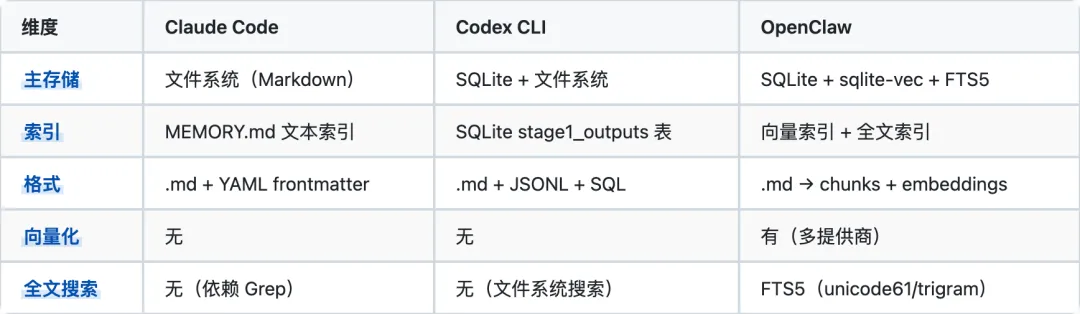
2.2 作用域层级
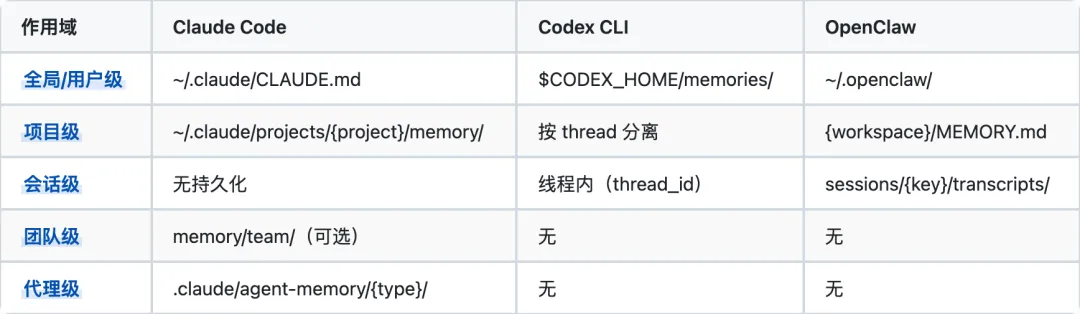
Claude Code 的层级最丰富:五层作用域(全局、项目、会话、团队、代理),设计了精细的隔离。Codex 最扁平:所有记忆在 $CODEX_HOME/memories/ 下统一管理,通过 SQLite 的 thread_id 做逻辑隔离。OpenClaw 居中:workspace 级别 + session 级别 + 额外路径扩展。
3. 记忆类型对比
3.1 类型分类

Claude Code 的类型系统最明确和实用:每种类型都有清晰的定义、保存时机、使用指南和团队作用域建议。特别是 feedback 类型要求包含 Why 和 How to apply,让 LLM 理解规则背后的原因。Codex 不做显式分类,而是让模型在 Phase 1 提取时自然产生结构化输出(任务分类、偏好信号、失败防护),Phase 2 整合时再组织为可导航的文件结构。OpenClaw 的分类最粗糙,基于正则规则的关键词匹配(如 "is/are" → fact),准确率受限。
3.2 排除规则

4. 记忆创建机制对比
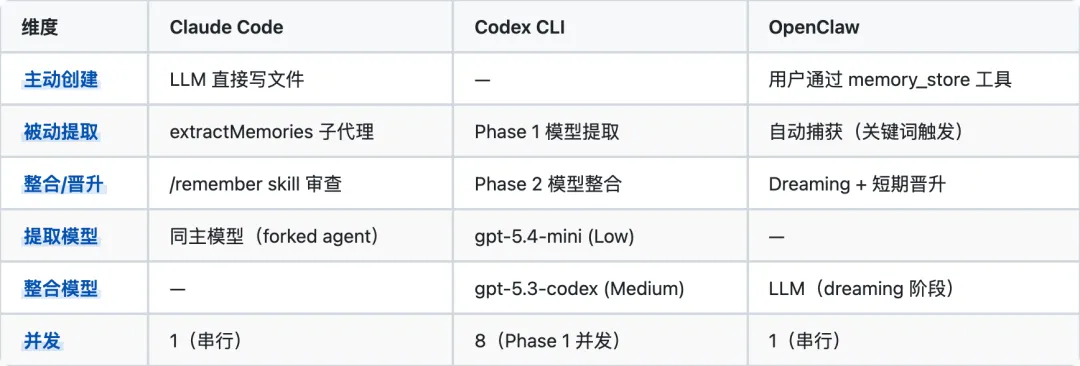
Claude Code 的创建最"轻量":主 Agent 直接写,或 forked agent 后台提取,不需要独立的模型调用。互斥守卫确保不重复。Codex 的创建最"工业化":Phase 1 并发 8 个任务处理最多 16 个 rollout,Phase 2 全局锁整合最多 256 条原始记忆。批量化管道设计。OpenClaw 的创建最"分散":手动工具 + 自动捕获 + Dreaming 晋升三条路径,各自独立。
5. 记忆检索机制对比
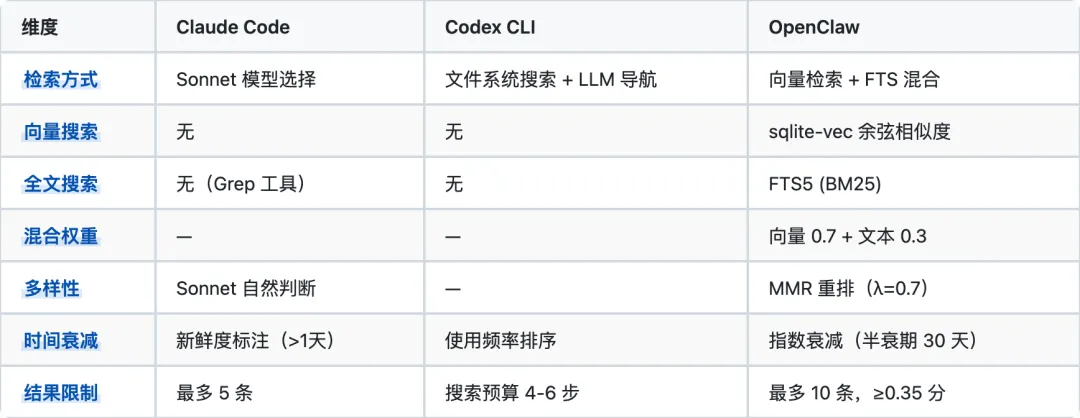
Claude Code 的检索最依赖 LLM:用 Sonnet 做相关性排序侧查询,本质上是"用 AI 选记忆给 AI"。优点是无需向量化基础设施,缺点是每次查询增加一次 API 调用。Codex 采用渐进式披露:memory_summary(总是可用)→ MEMORY.md(可搜索)→ rollout_summaries(按需深入),由 LLM 自主导航。搜索预算限制在 4-6 步避免过度搜索。OpenClaw 的检索最先进:标准的 IR 管道,支持语义检索和精确匹配的混合,配合 MMR 去重和时间衰减。是三个项目中唯一能做到"理解查询意图"的检索。
6. 上下文注入对比

7. 过期与清理对比
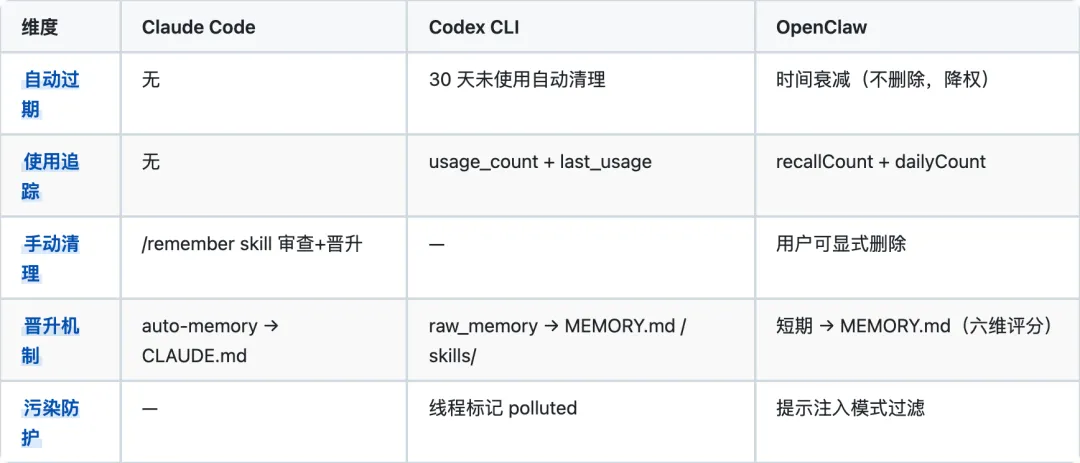
Codex 的过期最自动化:基于使用频率的自然淘汰,30 天未用则清理。Phase 2 选择时优先保留高频使用的记忆。OpenClaw 最精细:六维评分的晋升公式(频率 0.24 + 相关性 0.30 + 多样性 0.15 + 最近度 0.15 + 整合度 0.10 + 概念覆盖 0.06)。Claude Code 最"手动":无自动过期,依赖用户通过 /remember 审查。
8. 安全设计对比
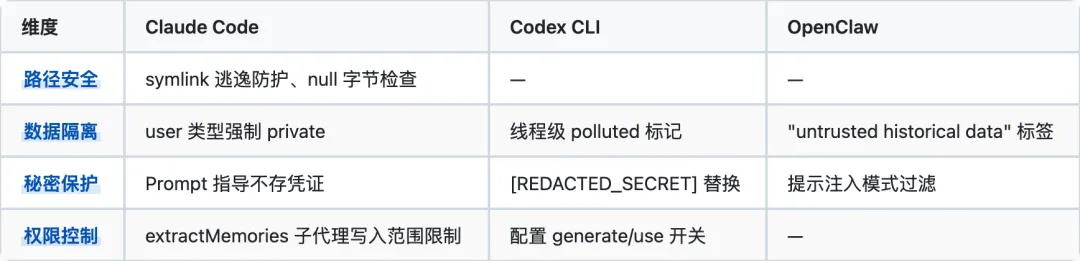
Claude Code 在团队记忆场景做了最多安全工作:symlink 防护、路径验证、Unicode 规范化攻击防护。Codex 的污染追踪最独特:MCP 工具和 web 搜索调用会标记线程为 polluted,防止不可信信息进入记忆库。OpenClaw 的安全设计集中在注入防护:检测提示注入模式,注入时标记为不可信数据。
9. 可扩展性对比
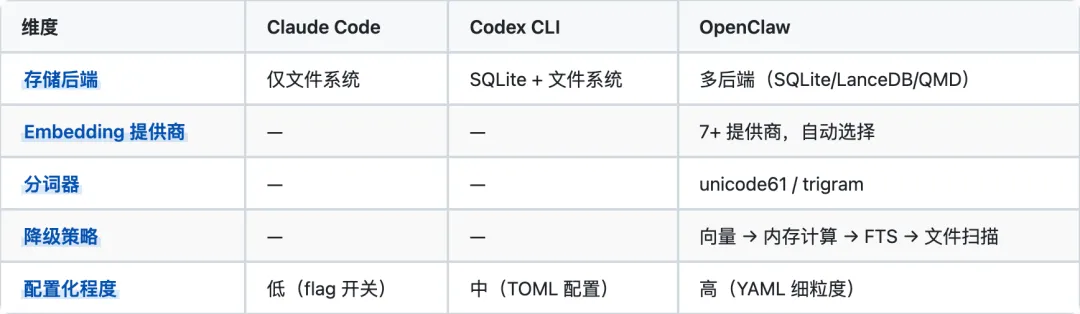
OpenClaw 的可扩展性最强:多存储后端、多 Embedding 提供商、可配置的检索参数、优雅的多级降级。Claude Code 最简单但也最受限:纯文件系统,200 文件上限,无向量化。
10. 性能特征对比
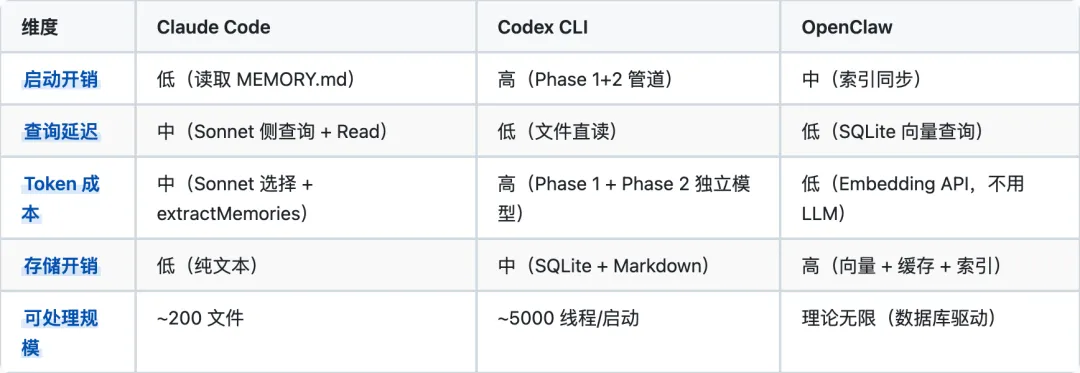
11. 总结:各自适用场景
Claude Code — "优雅的简约"
最适合:个人开发者、小团队、项目级知识管理优势: - 实现简单,无外部依赖 - LLM 驱动的记忆管理天然理解语义 - 类型系统设计精良(特别是 feedback 类型的 Why + How to apply) - 团队记忆支持完善局限: - 无向量检索,记忆规模受限(200 文件) - 无自动过期 - Sonnet 侧查询增加成本
Codex CLI — "工业级管道"
最适合:重度使用者、长期项目、需要自动化知识整理优势: - 两阶段管道自动从对话中提炼知识 - 使用频率驱动的优先级,自然淘汰无用记忆 - 污染追踪防止不可信信息污染 - Skills 自动提取可复用知识局限: - 启动延迟高 - 依赖 OpenAI 模型(两个独立模型) - 非实时(批处理模式)
OpenClaw — "搜索引擎式记忆"
最适合:大规模知识库、多用户平台、需要精确语义检索优势: - 真正的向量语义检索 - 混合检索(向量 + 关键词)+ MMR + 时间衰减 - 多后端、多 Embedding 提供商 - 优雅降级策略局限: - 复杂度高,调试困难 - 依赖外部 Embedding 服务 - 分类系统粗糙 - 记忆类型语义不如 Claude Code 明确
