 夜雨聆风
夜雨聆风点击上方卡片关注我
上周 Karpathy 在 GitHub 上发了一个 gist,叫 llm-wiki,不是代码,不是项目,就是一个 idea file,一份关于怎么用 LLM 构建个人知识库的思路文档。
但这个东西发出来之后在 HN 上引发了不少讨论,因为它提出的思路跟目前主流的 RAG 方案完全不同。
仔细看了一遍,觉得这个想法确实值得分享给大家。
先说 RAG 的问题在哪
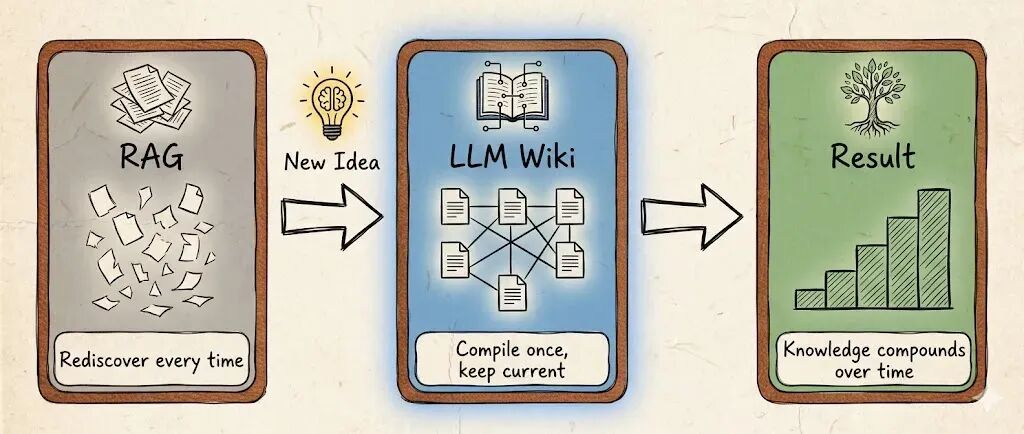
大多数人用 LLM 处理文档的方式是 RAG:把文件丢进去,LLM 查询时检索相关片段,拼起来生成回答,NotebookLM、ChatGPT 文件上传、各种知识库产品,底层都是这套。
RAG 能用,但有一个根本性的问题——它没有积累。
每次你问一个问题,LLM 都是从零开始找碎片、拼答案,你上周问过的、上个月研究过的,它全忘了,问一个需要综合五份文档才能回答的复杂问题,它每次都得重新把五份文档翻出来拼凑。
就像一个每天上班都失忆的同事,你给他交代过的事情第二天又要重新说一遍。
让 LLM 养一个 Wiki
Karpathy 的方案反过来了,不是查询时临时检索,而是让 LLM 增量构建并维护一个持久化的 Wiki。
每加入一份新资料,LLM 不是简单地存起来等着以后检索,它会读这份资料,提取关键信息,然后把新知识整合进已有的 Wiki 里,更新实体页面、修订主题摘要、标记新旧数据的矛盾、补充交叉引用。
知识是「编译一次,持续维护」的,不是「每次查询重新发现」的。
Karpathy 自己的用法是:一边开着 LLM Agent(Claude Code 或者 Codex),一边开着 Obsidian。LLM 在那边改 Wiki,他在 Obsidian 里实时看结果——点链接、看关系图、读更新后的页面,用他的原话说:Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。
三层架构,分工很清楚
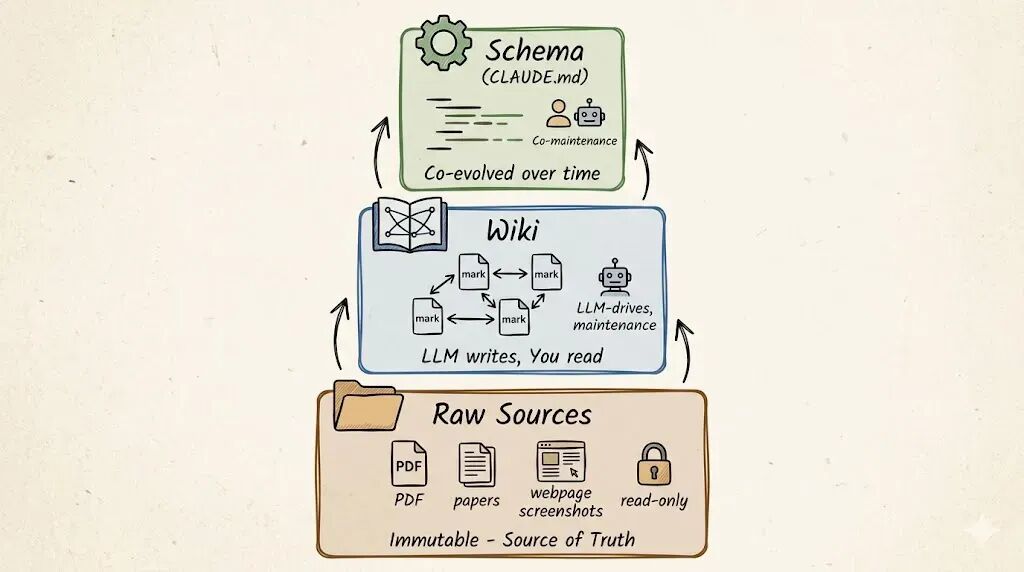
Raw Sources(原始资料)。 收集的文章、论文、图片、数据文件。这些是只读的,LLM 只能读不能改,这是信息源头。
Wiki(知识库)。 一个由 LLM 生成和维护的 markdown 文件目录,里面有摘要页、实体页、概念页、对比分析、综述,这一层完全由 LLM 负责,它创建页面、更新页面、维护交叉引用、保持一致性。你只管读,它负责写。
Schema(配置文件)。 一份告诉 LLM 这个 Wiki 怎么组织、有什么规范、各种操作该怎么做的文档,就是 CLAUDE.md 或者 AGENTS.md,和 LLM 一起慢慢迭代这份配置,找到最适合你领域的工作流。
这个分层设计很聪明,原始资料保真不动、Wiki 由 AI 全权维护、配置文件控制行为规范,职责划分清晰,不容易搞乱。
三种核心操作
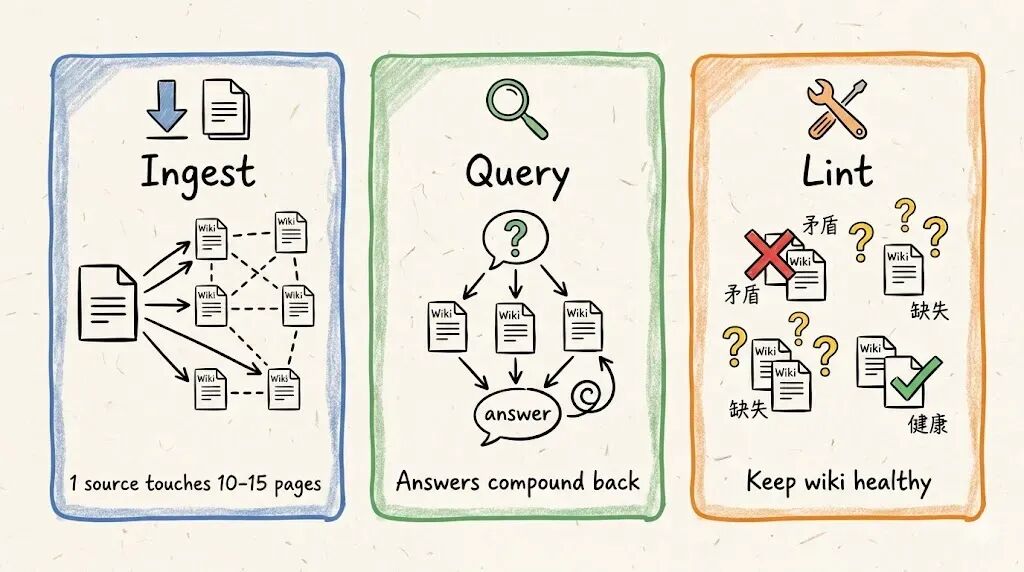
Ingest(摄入)。 往原始资料里丢一份新文档,让 LLM 去处理,LLM 读完之后讨论要点,然后写摘要页,更新索引,更新所有相关的实体页和概念页,一份资料可能会触发十几个 Wiki 页面的更新。
Query(查询)。 向 Wiki 提问。LLM 搜索相关页面,读完综合回答,带引用,关键在于:好的回答可以反向存回 Wiki,你做过的分析、发现的关联、对比的结论,这些不该消失在聊天记录里,应该沉淀到知识库中。
Lint(审查)。 定期让 LLM 对 Wiki 做健康检查,找矛盾、找过期信息、找孤儿页面、找缺失页面,这个操作让 Wiki 在不断生长的同时保持健康。
能用在什么场景
个人成长:把日记、播客笔记、文章摘要都喂进去,LLM 帮你建一个结构化的自我认知图谱。
深度研究:花几周甚至几个月研究一个课题,每篇论文读完就摄入,Wiki 自动更新综述和交叉引用。到最后你手里有一个完整的知识体系,不是一堆散落的笔记。
读书:每读完一章就摄入,LLM 自动建角色页、主题页、情节线索页。等你读完整本书,手里就有一个类似 Tolkien Gateway 那样的个人 Wiki。
团队知识库:Slack 讨论、会议纪要、项目文档、客户通话都可以喂进去,LLM 帮你维护一个永远最新的内部 Wiki。没有人愿意做的知识库维护工作,交给 LLM。
这个思路好在哪?
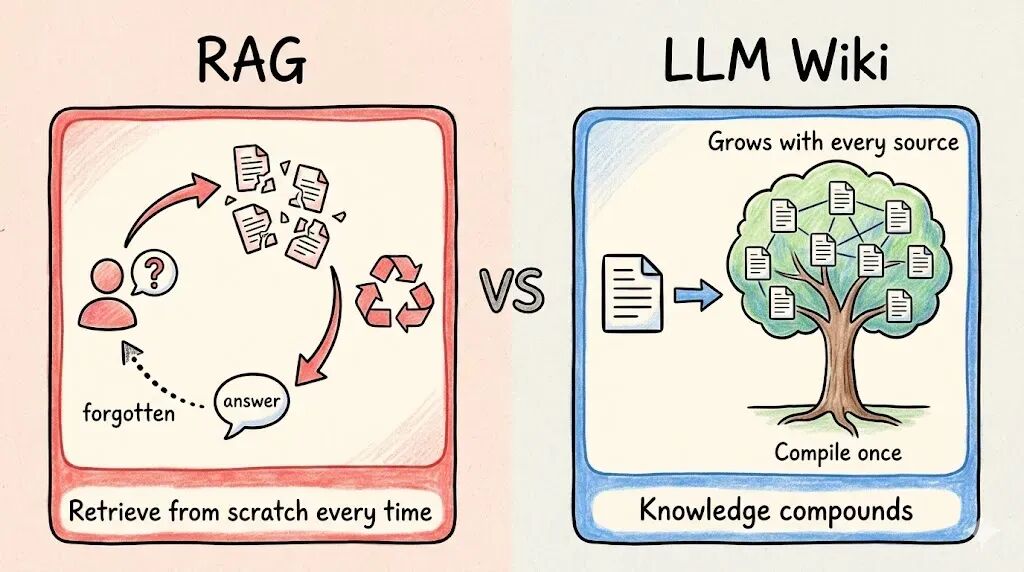
RAG 是「被动检索」——你问了才找,Karpathy 的 LLM Wiki 是「主动编译」,你加了资料它就处理,知识在不断积累和关联。
这个差别在使用初期不明显,但随着资料量增大,差距会越来越大。RAG 的回答质量取决于检索质量,检索找不到的信息就像不存在。而 Wiki 里的交叉引用早就建好了,矛盾早就标记了,综合分析早就写好了。
另一个好处是这个方案几乎不需要额外基础设施,不用部署向量数据库,不用搞 embedding pipeline,就是 markdown 文件加一个 LLM Agent 加一个 Obsidian。Wiki 规模小的时候靠 index.md 就够了,大了可以上 qmd,一个本地搜索工具,混合 BM25 和向量搜索,全部跑在本地,有 CLI 也有 MCP server。
但也得说一句:这个方案不是开箱即用的产品,是一个 idea file,需要自己配置 Agent、设计 Schema、跑通工作流,适合有动手能力、愿意花时间调教 LLM 的人。
怎么使用?
把这份 gist 直接复制到你的 LLM Agent 的 CLAUDE.md 或 AGENTS.md 里,然后跟 Agent 一起把 Wiki 搭起来。
具体步骤大概是:
建一个目录结构(raw/ 放原始资料,wiki/ 放 Wiki 页面) 写一份初始 Schema(定义页面类型、命名规范、摄入流程) 丢几份你感兴趣的资料进去,让 LLM 开始摄入 边用边调,把你发现好用的规则写回 Schema
如果用 Obsidian 的话,装一个 Web Clipper 浏览器插件可以快速把网页转成 markdown 存到原始资料里。图片建议下载到本地,避免外链失效。
这不是一个能一次配好的系统,更像是养一棵树,你持续喂养,它持续生长,关键是坚持用起来,知识库的价值是靠时间积累出来的。
欢迎关注,这个账号还会持续分享更多AI编程、出海工具、实战经验、踩坑记录。

出海赚钱案例:一个人做了个开源UI库,不融资不投广告,45天30万美元
出海赚钱案例:一个人用 PHP 做到月入 17 万美金,利润率 99%!
(2026年最新)Codex CLI 国内使用全攻略:终端 + VSCode + Cursor + Opencode 四种姿势全搞定
