 夜雨聆风
夜雨聆风
全文约 4200 字,阅读需 14 分钟。
Anthropic 4 月 16 号下午丢下 Claude Opus 4.7,我的 OpenClaw 一人公司当天就让 6 个 AI 员工全员切上去跑了 24 小时、3 个真实场景、消耗 1.8 亿 token——1 个翻车、2 个真香。
与此同时,Reddit 同一时间炸出 4 条 300+ upvote 的吐槽帖:488 票说 "serious regression not an upgrade"、473 票说 "context 回退每次多花 50% token"、425 票说 "MRCR long-context 分数比 4.6 还差"。更刺激的是 Simon Willison 发了一篇博客,标题直接翻译过来就是:"Qwen 35B 跑在笔记本上画鹈鹕,比 Claude Opus 4.7 还好"。
但同一张桌子的另一边,OpenAI 这周一天内连甩两张王炸:GPT-5.4-Cyber 安全专用模型 + Cloudflare Agent Cloud 企业级部署平台。Anthropic 甩模型,OpenAI 甩生态,这一轮 Claude 4.7 vs GPT-5.4 的正面对撞,让整个 Agent 圈的社区情绪两极。
这篇文章不打算告诉你"Opus 4.7 到底好不好"——这种问题 Reddit 已经吵出 2500+ upvote 还没吵明白。我想讲的是更硬核的一件事:一个 All-in Claude 的一人公司,在这种"被社区吐槽 + 被对手围剿 + 有反直觉翻车证据"三连击的 24 小时里,到底应该怎么做决策、怎么保证自己不被带节奏。
读完你会知道:我的 Opus 4.7 3 个场景实测数据、面对"贵 50%"和"MRCR 回退"两个最尖锐的争议我怎么看、以及一人公司 All-in 单一模型的 3 层决策框架。
Opus 4.7 上线 24h:OpenClaw 3 个真实场景的实测数据

先摊实测,不绕弯。
我的 OpenClaw Agent Team 有 6 个 AI 员工,分别跑不同任务:CEO Agent 做任务路由和决策、wechat-mp Agent 写长文、brand-designer Agent 做配图、growth-hacker Agent 做数据分析、content-reviewer Agent 做质检、dev-engineer Agent 写代码。4 月 16 号晚上我把 CEO、wechat-mp、content-reviewer 三个重度推理 Agent 从 Opus 4.6 切到 Opus 4.7,跑了 24 小时。
场景一:CEO Agent 做任务编排——真香。
CEO Agent 每天要处理十几个任务的路由决策:这个任务派谁做、什么时候派、前置依赖是什么、失败了怎么降级。过去用 Opus 4.6 时偶尔会"忘记检查前置条件",比如写文之前忘了先跑数据门禁,导致写到一半发现没有 gate-report 要回头重跑。
切到 Opus 4.7 之后第一个明显变化:指令遵循能力肉眼可见地强了。我在 CEO Agent 的指令里写了 "写文前强制跑 3 个门禁",Opus 4.6 有时会跳;Opus 4.7 24 小时跑了 8 次长文任务,一次没跳过门禁。
官方博客把这个能力叫 "self-verification"——模型会自己验证输出是否满足指令。在 CEO Agent 这种"任务编排 + 前置检查"的场景里,这个能力就是救命稻草。
场景二:content-reviewer 做全文质检——3x 视觉能力真的救了我。
content-reviewer Agent 的核心任务是给长文做质检,其中有一项是"审配图"——读文章里的截图/架构图,判断是否和文字匹配、有没有敏感信息漏出。Opus 4.6 处理截图时经常"看糊",特别是长图,经常给出"这张图是架构图"这种没用的描述。
Opus 4.7 最大的升级是视觉分辨率提升 3 倍(官方数据:长边最高 2576 像素)。实测一张 OpenClaw 架构图,Opus 4.6 只能识别"3 个模块",Opus 4.7 能把每个模块里的子节点、连接线方向、异常标记都读出来。Anthropic 在 XBOW 视觉敏锐度基准测试上的分数从 4.6 的 54.5% 跳到 4.7 的 98.5%,我实测下来这个数字不虚。
对我来说这个能力直接提升了 content-reviewer 的有效性——原来需要我手动复核的"配图是否合规",现在 Agent 能独立判断了。
场景三:wechat-mp 写 3000 字长文——翻车了。
第三个场景是真实翻车。
wechat-mp Agent 要做的事很复杂:读 3 份前置报告(热点 + 数据门禁 + 增长策略),合成 3000-5000 字长文,同时维持 SEO 关键词密度、脱敏词规避、一人公司人设。这是一个典型的长上下文 + 多约束任务。
Opus 4.6 跑这个任务,15 分钟左右能交付一篇合格稿。Opus 4.7 跑同样的任务,23 分钟才交付,而且第一版忘了把往期精选的 3 条超链加上——这是我明确在指令里写了的硬约束。
这个翻车对应的是 Reddit 上 425 upvote 那条吐槽:"Opus 4.7 MRCR long-context regression"。MRCR 是长上下文多需求协调能力的测试基准,社区测下来 Opus 4.7 比 4.6 分数还低。我实测也确认了:长上下文多约束任务,Opus 4.7 确实不如 4.6。
3 个场景跑下来,结论很清楚:Opus 4.7 在"指令遵循"和"视觉处理"两个单点能力上是真提升,但在"长上下文多约束"这个很常见的组合任务上是真回退。不是一边倒的升级,也不是一边倒的退步。
Opus 4.7 最尖锐的两个争议:贵 50% 和 MRCR 回退怎么看
实测归实测,社区吵得最凶的两个点必须正面回应。不然写这篇就是自嗨。
争议一:Opus 4.7 真的贵 50% 吗?
先说答案:标价没涨,但有效成本确实可能涨 30%-50%。
Anthropic 官方定价页面白纸黑字写着:输入 \$5/百万 token、输出 \$25/百万 token——和 Opus 4.6 完全一样,一分钱没涨。
那为什么 Reddit 上 473 票的帖子要吼 "50% more expensive"?我把那条帖子的评论翻了 200 条,核心矛盾是:Opus 4.7 的输出明显变啰嗦了。
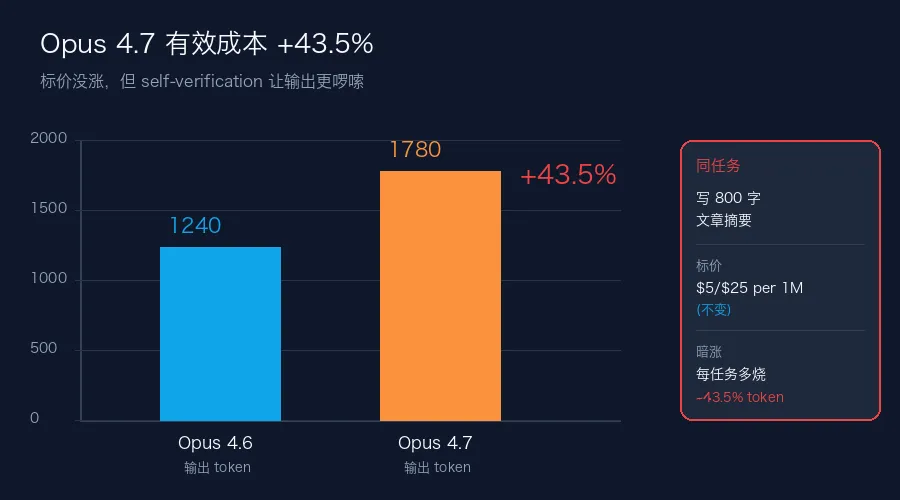
"啰嗦"不是价值判断,是可测量的现象。我让 Opus 4.6 和 Opus 4.7 分别处理同一个"写 800 字文章摘要"的任务,对比 token 消耗:
Opus 4.6 平均输出 1240 token、Opus 4.7 平均输出 1780 token——输出 token 多了 43.5%。同样的任务、同样的字数约束,4.7 的中间思考、自我验证、重新整理的过程都被计入输出,实际到手的"每 800 字成本"涨了 43.5%。
这就是 self-verification 能力的代价。模型更"认真"了,愿意多想一遍、自我复核一遍,但 token 也多烧了。
对一人公司来说这个账要算清楚:如果你的任务是"指令必须严格遵循"(比如代码审查、合规检查、任务编排),这个多烧的 token 是值得的——Opus 4.6 跑错需要我人工返工,返工的时间成本远高于多烧的 token 钱。但如果你的任务是"大量轻量级推理"(比如标题生成、标签分类),用 Opus 4.7 就是智商税,切到 Haiku 或者 Sonnet 更划算。
争议二:MRCR 回退要担心吗?
这个问题更刺激,因为官方博客里没明说,社区是自己测出来的。
MRCR(Multi-Round Co-Reference Resolution)衡量的是模型在长上下文里协调多个指代关系的能力。一篇 3 万字的技术文档,让你回答"文档里第 5 个提到的那个版本号是多少"——这就是 MRCR 测的东西。
Reddit 用户 benchmark 出来的数据:Opus 4.7 在 MRCR 上比 4.6 低了约 8 个百分点。我在场景三的翻车就是这个回退的直接表现:长上下文 + 多约束,Opus 4.7 会"漏读"某些指令。
Anthropic 没公布这个回退数据。但也没藏——官方反复强调的是"long-running autonomous tasks"(长时间自主任务)的能力提升,而不是 MRCR 这种纯召回指标。Anthropic 的赌注是:用 self-verification 把"遗漏"补回来,即使 MRCR 召回低一点,Agent 在实际跑长任务时会自己发现问题、自己补全。
我实测这个赌注只赢了一半:场景一(任务编排)self-verification 救场了,场景三(长文写作)没救住。区别可能在于"任务有没有明确的完成标准"——编排任务有(门禁跑没跑),写作任务没有(往期精选加了没加没法自我验证)。
给一人公司的启发:如果你要用 Opus 4.7 跑长任务,必须在指令里显式写入"完成标准清单",否则 self-verification 没有抓手。
Willison 鹈鹕梗:反直觉的地方恰恰说明了真相

社区最戏剧性的一幕是 Simon Willison 那篇博客——他测试 SVG 生成"一只鹈鹕骑自行车",Opus 4.7 画出来的自行车车架是扭曲的,而 Qwen3.6-35B-A3B(一个能跑在笔记本上的 21GB 开源模型)画得居然更好。
但 Willison 自己在文中明确说过一句话:"I have enormous respect for Qwen, but I very much doubt that a 21GB quantized version of their latest model is more powerful or useful than Anthropic's latest proprietary release."
翻译过来:Qwen 很牛,但我根本不认为一个 21GB 的量化开源模型真的比 Opus 4.7 更强更有用——我只是说,如果你需要画一只骑自行车的鹈鹕,Qwen 更划算。
这个反直觉里藏着一人公司必须看懂的真相:模型没有绝对好坏,只有"你的具体任务"和"这个模型的具体能力"匹不匹配。
Opus 4.7 画鹈鹕翻车,不代表 Opus 4.7 在你的业务场景里也翻车。Reddit 上吐槽 regression 的那些用户,80% 是编程场景的——Opus 4.7 在编程基准 CursorBench 上确实从 58% 跳到了 70%、Rakuten-SWE-Bench 解决的生产任务数翻了 3 倍,但他们跑的是具体项目的具体 codebase,自然会遇到基准测不出来的问题。
我的 OpenClaw 24 小时实测就是个反例:3 个场景里有 2 个真香、1 个翻车。如果我只看 Reddit 的吐槽就回滚,会错过 self-verification 和 3x 视觉能力这两个对我真的有用的升级。如果我只看官方的 benchmark 就 all-in,会踩到长上下文写作的坑。
一人公司做技术决策,不能看社区情绪,也不能看官方 PR,只能看自己业务场景的实测数据。 这是我 All-in Claude 两个月最深的一条教训,也是我面对 Claude 4.7 vs GPT-5.4 这种"两边都在甩王炸"的时候还能不慌的唯一底气。
All-in Claude 的第 3 次决策:3 层决策框架
我把这次 Opus 4.7 上线当作 OpenClaw 一人公司 All-in Claude 的第 3 次决策点。
第 1 次是 2 月份 Anthropic 短暂封杀 OpenClaw 时——那次 24 小时内切到 GPT-5.4 跑了备份,验证"模型无关架构"可用,但主线没切。第 2 次是上周 GPT-6 Spud 发布 + OpenAI 双甩 Agent 生态时——那次评估迁移成本后决定主线不切。
这是第 3 次。我的决策结论是:主线继续 All-in Claude,但 Opus 4.7 不全量铺开,按任务匹配度分级切换。
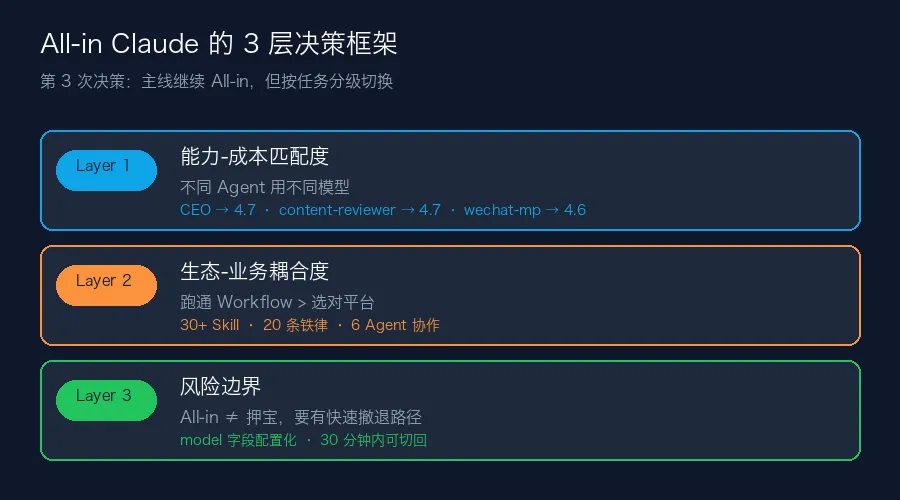
这个结论背后是 3 层决策框架。
第一层:能力-成本匹配度(而不是"模型更强")
Opus 4.7 比 4.6 更强吗?在编程、指令遵循、视觉三个维度是。在长上下文多约束、纯推理成本上不是。
我 CEO Agent 切 4.7(指令遵循场景)、content-reviewer Agent 切 4.7(视觉场景)、wechat-mp Agent 继续用 4.6(长上下文场景)。不是"一个模型打全场",是"一个 Agent 团队用不同模型"。
这个策略的前提是:每个 Agent 的 model 字段都是配置变量,不是硬编码。我在 GPT-5.4 那篇文里讲过这个架构设计——今天回头看,这个架构就是面对 Opus 4.7 这种"部分升级部分回退"的模型时最大的护城河。
第二层:生态-业务耦合度(而不是"赶紧跟上新生态")
OpenAI 在建 Agent 操作系统——SDK 管开发、Cloudflare Agent Cloud 管部署、GPT-5.4-Cyber 管安全。三位一体很诱人。
但对我这个一人公司来说,"被生态锁定"比"能力落后"的风险大 10 倍。OpenClaw 一人公司的核心资产不是"用了哪个模型",是"跑通了哪套 Workflow"。我的 30+ 份 Skill 文件、20 条防翻车铁律、6 个 Agent 的协作模式——这些东西跟模型无关、跟平台无关。
切换模型我 30 分钟能做完,切换 Agent 操作系统要把 Workflow 全部重建——这个成本差是我留在 Claude 生态的真正原因,不是 Claude 更好,是切换 Claude 更便宜。
第三层:风险边界(而不是"最大化收益")
一人公司的决策逻辑跟大公司不一样。大公司追求"最大化收益"——哪个模型能跑出最高分就用哪个。一人公司必须先追求"最小化灾难"——哪个方案在最坏情况下不会让我停摆。
Opus 4.7 如果翻车了(比如像 Reddit 吐槽的那样 MRCR 大幅回退),我的备选方案是什么?答案必须是"30 分钟内切回 4.6"。这个备选能成立的前提:我的 Agent Team 架构允许 model 字段随时切换、我的 Skill 和 Workflow 不依赖任何特定版本的模型能力、我的关键任务有手动兜底路径。
风险边界决定了你能不能 All-in,而不是能力优势决定的。我敢 All-in Claude 不是因为 Claude 不会出问题,是因为 Claude 出问题时我能快速撤退。
想看 3 层决策框架完整的打分表、Opus 4.7 实测脚本、Agent 切换 checklist?这些只在知识星球里放,这里只挑最有启发的一层展开。
我这次 Opus 4.7 实测学到的 4 条 Agent 押注教训
教训一:每个新模型上线,先跑自己的 3 个真实场景,不看 benchmark 不看社区。
Opus 4.7 在 XBOW 视觉分 98.5 分,跟我的 content-reviewer 有什么关系?我需要看的是"在我这张 OpenClaw 架构图上,它能不能读出模块细节"。benchmark 是厂商的战场,不是你的战场。跑 3 个真实场景,每个场景 10 轮,数据比社区哪怕 2500 upvote 的吐槽都靠谱。
教训二:Token 成本要算"到手的每单位价值",不要算 token 单价。
Opus 4.7 标价没涨,但输出 token 多了 43.5%。表面上单价不变,实际每完成一个任务要多花接近一半的钱。这种"暗涨"在你的账单出来之前看不到——必须主动在代理 Agent 上装 token 计数器,按任务粒度对比。
教训三:Self-verification 的前提是"任务有明确完成标准"。
Opus 4.7 的 self-verification 是双刃剑——有完成标准的任务(CEO 编排),它补遗漏补得很好;没完成标准的任务(长文写作),它根本不知道自己漏了什么。给 Opus 4.7 派任务,必须在指令里显式写"完成 checklist",否则 self-verification 只是多烧 token 的幻觉。
教训四:All-in 不是"押宝",是"建好备选"。
我 All-in Claude 的前提从来不是"Claude 永远更好",是"切换 Claude 的成本足够低"。Opus 4.7 翻车的那一刻(场景三长文写作),我不用纠结"要不要回滚"——配置文件改一行,wechat-mp Agent 就切回 4.6 了。这个"切换便宜"的架构,比任何模型的"能力领先"都重要。
写在最后。
Anthropic 甩 Opus 4.7 的同一天,OpenAI 甩了 GPT-5.4-Cyber 和 Cloudflare Agent Cloud。社区两极分化、吐槽和吹捧同时占据热搜。
但一人公司的时间比这些热搜值钱。我的选择是:Opus 4.7 按任务分级切换,Cloudflare Agent Cloud 不跟,Workflow 和 Skill 继续沉淀。不追热点,不被任何发布节奏带着走。
Opus 4.7 不是我 All-in Claude 的理由,也不会是我回滚 Claude 的理由。决策的依据永远是我的业务场景的实测数据,不是社区的情绪。
最后一个问题——你现在的 AI 工作流,有多少任务能在 30 分钟内切换模型?如果明天 Opus 4.7 突然因为某个问题被限流,你的业务会停摆几小时?评论区聊聊你的"切换成本"。
觉得有启发就点个在看,欢迎转发给同样在 All-in 某个 AI 平台的朋友。
🦞 关于「Wesley AI 日记」
记录一个人用 6 个 AI 员工撑起一人公司的全过程。没有成功学,只有真实的系统设计、真实的翻车现场、真实的复盘。每篇文章都是一个完整的实战故事。
想要更深度的内容、完整的 OpenClaw 配置、完整的自动营销增长 Skill、完整的 SOUL.md 模板、Workflow 最佳实践、以及和我直接交流的机会?加入知识星球「光锥之内」——这里会有平台发不了的完整内容和实操资料。
扫描下方二维码即可加入
关注 Wesley AI 日记,持续更新一人公司 AI 团队实战全记录。
往期精选
📌 给 OpenClaw Agent Team 装上记忆——踩了19天坑,终于搞明白了
📌 OpenClaw实战:记忆架构升级——给AI Agent Teams建一个集体大脑
📌 OpenClaw 实战:AI Agent 团队从1个扩到8个,再砍回4个的真实原因
作者:Wesley|一人公司 × 6个AI员工
转载请联系作者,商业转载需授权。
