 夜雨聆风
夜雨聆风《GPT到底是啥?——大语言模型原理白话版》
嘿,我是你们的AI科普搭子!
前四天咱们从机器学习刷到神经网络,从CNN、RNN刷到Transformer一统江湖。今天终于轮到当代AI顶流——GPT登场了!
ChatGPT、GPT-4、文心一言、Claude……这些天天上热搜的大模型,到底是啥玩意儿?它们怎么就能跟你聊天、写诗、写代码、解数学题?
坐稳了,今天咱们把GPT的底裤扒干净!🩲
🎲 一、GPT的本质:高级版"词语接龙"
先说结论,别被吓到:
> GPT其实就是一个"词语接龙"的高级玩家。
你玩过成语接龙吗?"一心一意"→"意气风发"→"发愤图强"……GPT干的事差不多,只不过它接的是下一个token(词片段)。
核心机制:自回归生成
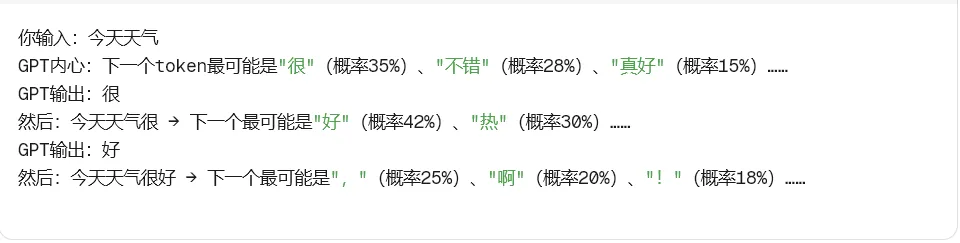
循环往复,直到生成完整个回答。
所以GPT不是"理解"了你的问题,而是基于海量文本训练,学会了语言的概率分布——什么词后面最可能跟什么词。
打个比方: 就像你手机输入法的联想功能,只不过GPT的"词库"是整个互联网,"联想能力"强了一亿倍。
📚 二、GPT是怎么练成的?三阶段"修仙"
GPT不是天生这么牛,它要经历三个阶段的残酷训练:
第一阶段:预训练(Pre-training)——读遍天下书
任务: 让GPT海量阅读互联网文本(网页、书籍、论文、代码……)
目标: 学会语言的统计规律,建立"世界知识"
数据量: GPT-3读了3000亿个token,相当于读了整个图书馆几百遍
这个过程: 就像让一个小婴儿在图书馆长大,不说话,只看书。看了几年后,他虽然不会思考,但知道"太阳"后面常跟"升起","爱情"后面常跟"甜蜜"或"痛苦"。
第二阶段:监督微调(SFT)——拜师学艺
问题: 只读书的GPT,回答可能乱七八糟,甚至有害
解决: 找人类标注师,写几万个"优质问答对",让GPT模仿学习

这个过程: 就像拜师学艺,老师手把手教"这样回答才是对的"。
第三阶段:RLHF(人类反馈强化学习)——对齐人类价值观
问题: 标注师教不完所有情况,而且什么是"好回答"很主观
解决: 让GPT生成多个答案,人类打分排序,训练一个"奖励模型",再用强化学习优化GPT

这个过程: 就像训狗,做对了给零食,做错了无视,慢慢就知道什么行为能讨主人欢心。
RLHF的关键作用: 让GPT学会"说人话、说好话、不说坏话"——这就是AI对齐(Alignment)。
🧮 三、涌现能力:量变引起质变
GPT有个神奇现象:模型大到一定程度,突然会了一些没教过的技能。
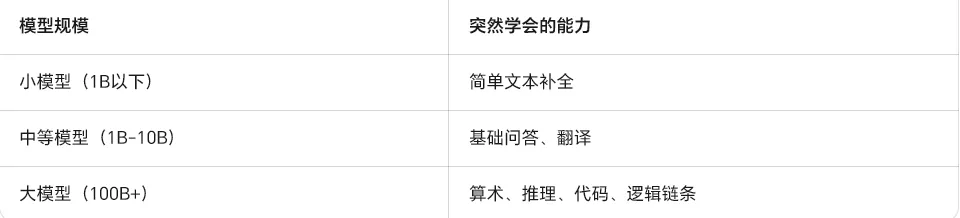
这叫"涌现能力"(Emergent Abilities)。
就像水分子多了突然有"湿润"的特性,单个水分子没有——GPT参数多了,突然表现出"推理"的特性,虽然它本质上还是词语接龙。
但注意: 涌现能力不可预测,也不知道上限在哪。这就是为什么大家都在疯狂堆参数、搞更大的模型。
😵 四、GPT的"幻觉":一本正经地胡说八道
GPT有个致命bug,业内叫"幻觉"(Hallucination):
> 它会编造不存在的事实,而且语气非常肯定。
典型案例:
- 律师用ChatGPT写诉状,引用了6个假案例,被法官罚款
- GPT说"爱因斯坦获得过诺贝尔文学奖",还给你编颁奖词
- 问它"你知道张三吗",它可能编出张三的生平事迹
为什么会这样?
因为GPT的目标是"生成流畅合理的文本",不是"说真话"。如果训练数据里没有答案,它就会根据概率瞎编,凑出一个看起来像真的回答。
应对方法:
- 重要事实必须人工核实
- 要求GPT给出信息来源(虽然它可能编来源)
- 用RAG(检索增强生成),让GPT先查资料再回答
🔔 明日预告
今天咱们搞懂了GPT的"词语接龙"本质,但怎么跟GPT对话才能让它发挥最大威力?
明天Day 6:《Prompt工程——与AI对话的"话术秘籍"》,教你从"小白提问"进化到"Prompt工程师"!
关注不迷路,咱们明天见! 👋
