 夜雨聆风
夜雨聆风unsetunset基本信息unsetunset
论文标题:General scales unlock AI evaluation with explanatory and predictive power 期刊:Nature(IF≈64.8) 发表时间:2026年4月2日 DOI:10.1038/s41586-026-10303-2 通讯单位:普林斯顿大学、剑桥大学、微软研究院、西班牙瓦伦西亚理工大学等
unsetunset核心突破 🔥unsetunset
当前通用大语言模型(LLMs)发展日新月异,但AI评估一直是行业痛点:传统基准测试的平均准确率只能反映「模型在当前测试集上的表现」,既不能解释模型为什么成功/失败,也没法预测模型在未见过的新任务上的表现,而且随着AI快速迭代,旧评估方法很快就会过时。这项研究开创性地提出了一套基于通用能力标尺的AI评估新框架,将任务需求和AI能力放到同一套可比较的绝对标尺上,同时实现了出色的解释性和预测性:不仅澄清了领域内关于LLM推理能力的诸多矛盾结论,还能在分布外新任务上达到远高于传统黑盒方法的预测准确率,而且这套标尺不依赖现有AI种群,未来AI能力提升后也能平滑扩展,为AI评估的标准化奠定了基础,对AI研发、部署和监管都有重要价值。
unsetunset研究背景 📚unsetunset
随着通用大模型在各个领域落地,对AI能力的准确、可重复评估已经成为迫在眉睫的需求。传统AI评估以基准测试的聚合准确率为核心,本质上是模型能力和测试集难度分布共同作用的结果,既不是模型本身固有的能力,也没法跨基准比较,很容易出现「同一个模型在两个都号称测推理的基准上结果完全矛盾」的问题,更没法预测新任务上的表现。过往的改进方案,无论是心理测量学的因子分析、项目反应理论,还是黑盒预测模型,要么依赖评估时的AI/基准种群,结果很快随着AI迭代过时,要么不可解释、分布外泛化差。因此,领域亟需一套不依赖种群、可解释、能预测新任务性能的通用评估框架。
unsetunset技术创新 💡unsetunset
1. 18个通用独立的比率标尺
这套标尺整合三类维度:11个基础认知能力维度(如语言理解、逻辑推理、元认知等)、5个领域知识维度(自然科学、社会科学、形式科学等)、2个混杂因素维度(非典型性、输入长度,用来捕捉训练污染、任务拼接带来的难度变化)。每个维度从0(无需求)到5+(极高需求)分级,采用绝对比率尺度,不依赖现有AI种群,未来AI能力提升后可以直接扩展更高等级,保持向后兼容。
2. 双剖面可解释评估框架
框架通过两个核心剖面实现解释性:①任务需求剖面:用LLM自动按照标准rubric给每个任务实例标注各维度的需求等级,就能知道这个基准/任务真正需要哪些能力,判断是否满足它宣称的测量目标;②模型能力剖面:通过特征曲线拟合得到模型在每个维度的能力得分(定义为模型有50%概率成功的需求等级),同一个标尺下可以直接跨维度跨模型比较能力强弱。
3. 低成本高泛化的实例级性能预测
用任务的18维需求作为特征训练简单的随机森林评估器,就能预测模型在新实例上的成功概率,计算成本比端到端微调的黑盒模型低了整整6个数量级,预测性能却更好,尤其是在分布外(新任务、新基准)场景下,预测优势非常明显。
unsetunset实验结果unsetunset
Figure 1:能力-需求剖面匹配直接解释性能差异
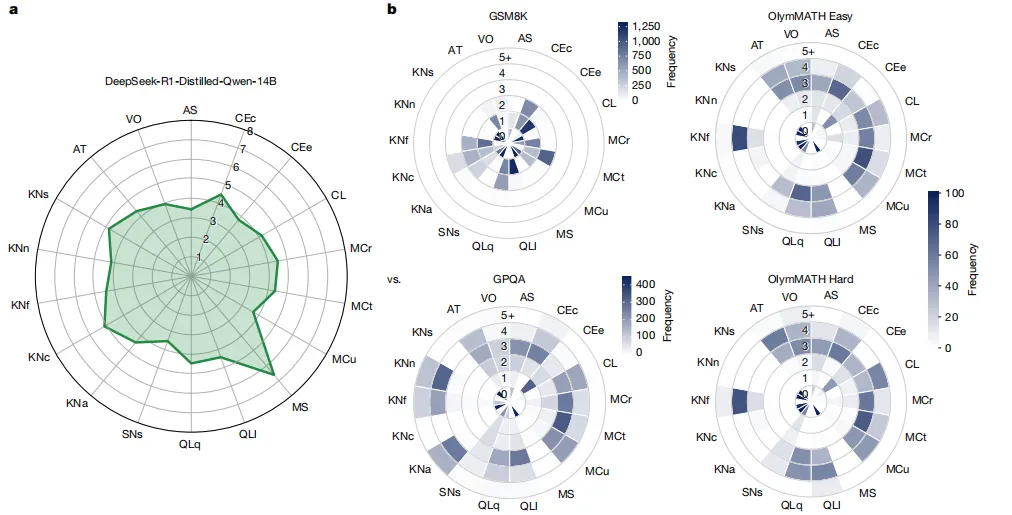
图表标题:可比的模型能力剖面和基准需求剖面可解释和预测性能 结果解读:左图展示了DeepSeek-R1-Distilled-Qwen-14B的18维能力得分,右图展示了四个都号称测量「数学推理」的基准的需求分布。从剖面匹配就能直接预测性能:GSM8K对定量推理、逻辑推理的需求很低,因此模型准确率高达90.5%;OlymMATH Hard对这两个维度的需求接近5,因此准确率只有13.3%;而GPQA虽然推理需求不高,但额外要求自然科学、应用科学等多个领域的知识,因此准确率也远低于OlymMATH Easy,直接解释了为什么同叫推理基准结果差异巨大,澄清了领域内的矛盾结论。
Figure 2:现有大部分基准都缺乏结构效度
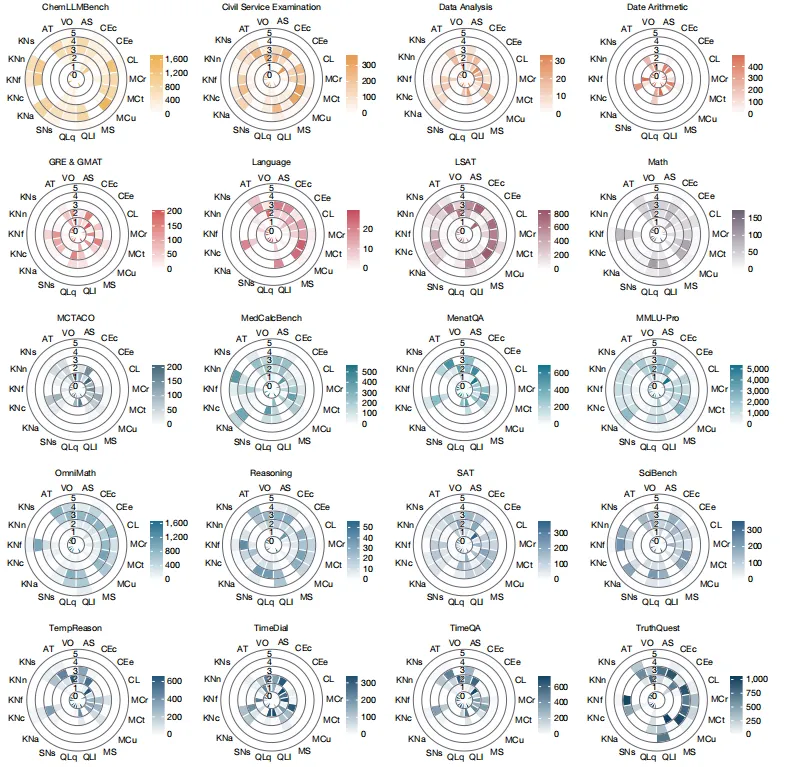
图表标题:ADeLe基准库中20个基准的需求剖面 结果解读:这张图系统分析了20个常用AI基准的需求分布,研究用两个标准衡量基准质量:灵敏度(覆盖目标能力的全难度范围)和特异性(不混杂无关能力的需求)。结果发现,只有不到一半的基准能满足自己宣称的测量目标,很多基准存在明显缺陷:比如MedCalcBench宣称测医学计算能力,实际最大需求是注意力扫描能力;SAT这类常用基准因为大量题目存在训练污染,非典型性得分远低于正常水平,会高估模型能力。这个结果直接点出了当前AI基准领域的普遍问题。
Figure 3:需求-成功率特征曲线区分不同模型能力
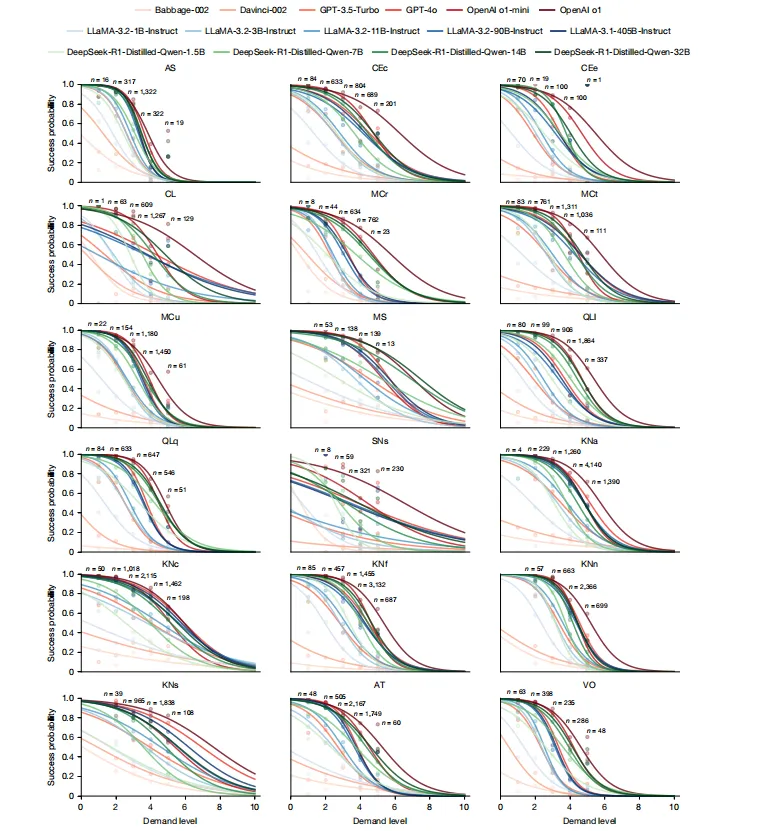
图表标题:15个LLM在18个需求维度的特征曲线 结果解读:x轴是需求等级,y轴是模型在该需求等级下的平均成功率,曲线展示了模型成功率随需求升高的变化趋势。研究发现不同维度的曲线特征差异明显:注意力扫描等维度曲线非常陡峭,低需求容易成功,高需求几乎全败;而社会科学知识维度的区分度很低,曲线平缓。推理优化模型(如OpenAI o1、DeepSeek-R1)的曲线在逻辑推理、元认知、心智建模等维度明显优于同尺寸普通大模型,直接证明了推理训练确实提升了这些维度的能力。通过logistic拟合就能从曲线得到模型在该维度的能力得分。
Figure 4:不同家族LLM的能力剖面直观展示强弱
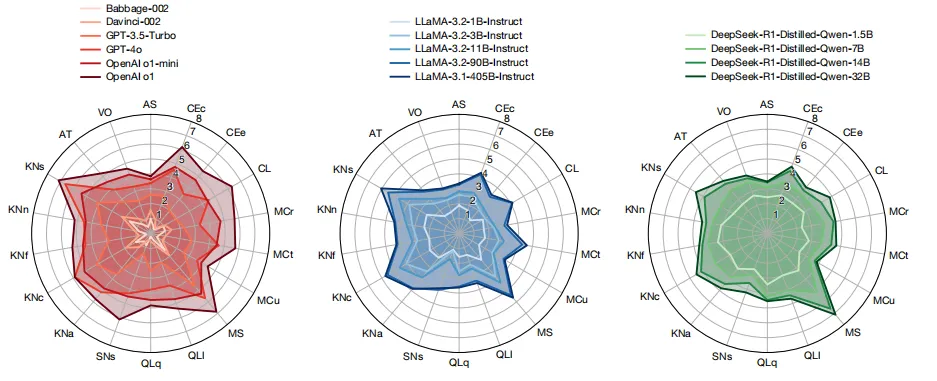
图表标题:15个LLM的能力剖面 结果解读:这张图整理了15个不同家族、不同尺寸LLM的18维能力得分,得到了多个有启发的结论:知识类维度的能力得分基本随模型参数增大而升高;推理优化模型哪怕参数较小,在定量推理、逻辑推理、心智建模等维度的得分也远高于同尺寸普通大模型;更重要的是,在绝对标尺下能清晰观察到,当模型参数增加到一定程度后,多数能力的提升出现明显的边际效益递减,这是第一次在非饱和尺度上观察到这个规律,传统的准确率缩放法因为容易饱和,很难发现这个趋势。
unsetunset应用前景与展望unsetunset
这套通用标尺框架为AI评估开辟了全新的方向,应用场景非常广泛:对AI研究者来说,可以用这套框架设计更有结构效度的新基准,整合不同来源的基准实例做跨基准能力比较,还能给模型做精细的能力诊断,解释失败原因、做反事实分析;对落地部署来说,可以自动给新任务标注需求,路由给能力最匹配的大模型,也能提前拒绝超过模型能力范围的请求,提升AI应用的安全性;对AI监管和红队测试来说,统一的标尺让大模型能力评估有了可比较的标准,还能针对性靶向测试模型的薄弱能力。目前这套框架仅针对文本LLM,未来还可以扩展到多模态、具身智能、机器人等其他AI类型,也可以加入安全性、公平性等新的维度,适应AI技术的快速发展。
项目代码和数据已经完全开源:👉 https://kinds-of-intelligence-cfi.github.io/ADELE/
unsetunset生信视角解读unsetunset
其实这套评估思路对当前生信领域的大模型研发非常有启发。现在生信领域已经涌现出大量蛋白大模型、基因组大模型、多组学大模型,但评估其实和通用AI遇到了一模一样的问题:很多研究还是按任务算平均准确率,不同任务的基准没法直接比较,经常出现「模型A在基准1上比模型B好,在基准2上反过来」的矛盾情况;很多基准还存在和文中提到的类似问题:训练集泄露(对应文中的污染问题)、任务混杂了无关能力(比如蛋白结合预测基准其实更容易被序列长度影响,不是真的结合能力),导致评估结果不能反映模型的真实能力。
这篇工作给我们的启示是:生信领域也可以参考这个思路,建立一套适合生信大模型的通用能力需求标尺,比如区分序列模式识别、结构预测、功能理解、药物设计能力等不同维度,然后给每个任务做需求标注,给每个模型做能力剖面,就能得到更可靠、更可比较的评估结果。当然这个方法也有局限:当前v1.0只覆盖了通用文本能力,需要生信研究者扩展适合组学任务的特有维度;另外高难度实例的不足也需要更多数据积累。如果你正在设计生信大模型的评估基准,不妨试试这个思路,提前排查基准的灵敏度和特异性问题,让你的评估结果更可靠。
你在做大模型评估或者生信基准设计的时候,遇到过不同基准结果矛盾的问题吗?欢迎在留言区交流你的看法~
