 夜雨聆风
夜雨聆风昨天有个朋友私信问我:"为什么你的OpenClaw自动化任务跑得那么顺?我自己搭的总是半途卡住,不知道哪里出了问题。"
我看了他的配置,发现了一个很典型的现象——他根本没用OpenClaw最核心的功能:子代理机制。
很多人跟我一样,最初接触OpenClaw的时候,看到对话框里弹出的「子代理启动」「子代理运行」这些提示,只会觉得这是普通的状态日志,点进去瞄一眼就划过去了。
说实话,我一开始也是这样。
直到有一次,我需要同时处理一个超复杂的任务——把某书长文自动拆解成可视化阅读卡片,涉及文章抓取、结构分析、数据入库、卡片渲染好几个环节。
我试着把所有逻辑塞进一个会话里,结果不仅容易出错,调试起来更是弯弯绕。
后来我才搞明白:OpenClaw的设计本身就是为多智能体协同准备的,「子代理启动」那四个字背后,藏着一整套主从架构。
今天这篇文章,我结合自己跑通的实战项目,把OpenClaw的子代理机制从概念到落地彻底讲透。看完你就明白,为什么说它是OpenClaw最核心的能力。
一、OpenClaw的「子代理」到底是什么?
先说清楚一个基本概念:在OpenClaw里,子代理不是独立存在的AI个体,而是相对于「主代理」而言的专项执行单元。
你可以把整个系统想象成一家公司。
主代理是老板,负责接单、分配任务、汇总结果、把控全局。
子代理是各个岗位上的专业员工,只做自己那一块事,做完汇报,老板再派下一个活儿。
员工不会擅自去干别人的工作,也不会跟其他员工抢资源——因为每个员工都在独立的工位上作业。
这个比喻对于理解OpenClaw的子代理机制特别重要。
核心角色是这样的:
主代理(总控层)是任务入口、调度大脑、结果汇总、最终交付。我在某书看板项目里实现的「某书看板总调度中心」,就是主代理。它负责接收用户的文章链接、新建飞书数据行、派生子代理、质检数据、触发渲染,最后把成品发给用户。
子代理(原子技能层)则是被临时创建、专注单一任务、执行完立即汇报的专项执行单元。我在同一个项目里实现的「某书标题拆解专家」「某书开头设计拆解专家」,都是子代理。每个子代理只做一件事,做完就向上汇报。
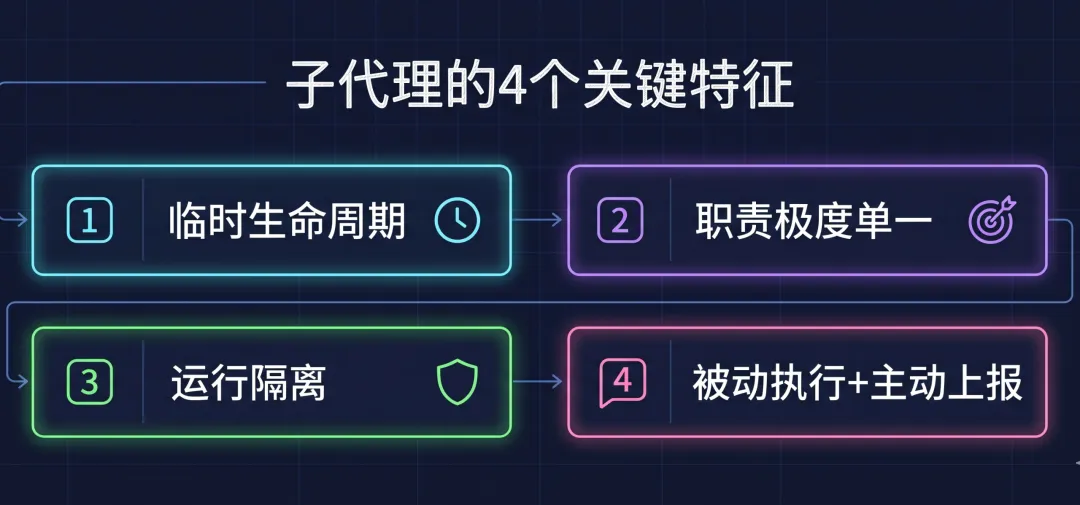
子代理有4个关键特征,理解了你就知道它为什么比「大包大揽」更稳:
第一,临时生命周期。 主代理用sessions_spawn创建子代理,任务结束子代理就销毁,不会占用资源,也不会留下脏数据。
第二,职责极度单一。 每个子代理只做一件事。标题拆解专家只管分析标题,不会去碰内容分析;开头设计专家只管拆解开头,不会去管标题。这种单一职责让执行更稳、更准。
第三,运行环境的隔离。 子代理在独立会话里运行,互相不干扰。一个子代理出错,不会把整个流程带崩。
第四,被动执行加主动上报。 子代理不主动行动,只听主代理指挥。干完活立刻汇报,让主代理知道进度、更新状态。
二、主代理和子代理,到底怎么通信?
搞清楚了子代理是什么,接下来最关键的问题:主代理和子代理之间怎么传递消息?
很多人以为这就是简单的「主代理喊一嗓子,子代理就去干活」。不是的。OpenClaw的通信是一套标准化、可监控、可回溯的流程。
我用某书文章转可视化卡片这个实战项目举例说明。
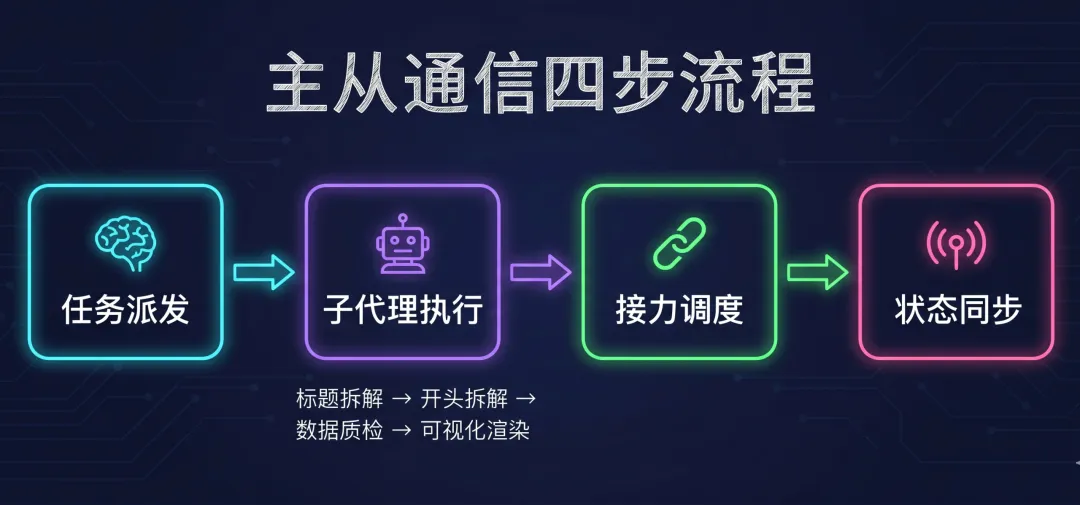
第一步:任务派发。
当用户把文章链接扔给主代理,主代理会做几件事:新建一条飞书记录、拿到Record ID、解析出App Token和Table ID这些参数。然后,它用sessions_spawn唤醒子代理,把参数传过去。
这时候,主代理进入静默等待状态,不输出多余的内容,只等子代理回报结果。对话框里会触发提示:「子代理启动」。
第二步:子代理执行。
以「标题拆解专家」为例,它被唤醒后只做4件事:
接收主代理传来的参数——文章链接、Record ID、Table ID。抓取文章标题,然后进行结构化拆解,分析出构成公式、元素拆解、策略定性、吸睛钩子。把拆解结果回写到飞书表格的指定字段里,不碰其他数据。执行完向主代理汇报:「✅ 标题拆解已完成」。
第三步:接力调度。
这是整个协同模式最精彩的地方:上一个子代理没完成,绝对不启动下一个。
主代理严格遵守串联接力模式:总控初始化 → 标题拆解子代理 → 开头拆解子代理 → 数据质检 → 可视化渲染。
每一步都等上一步交棒,才开始跑下一棒。这种设计保证了数据的一致性和流程的可控性。
第四步:状态同步。
子代理的启动、运行、完成、异常,这些状态都会通过全局事件总线同步给主代理和用户。你在对话框里看到的「子代理启动」「子代理运行」「子代理完成」这些提示,不是简单的日志,而是实时状态推送。
三、实战落地:一条完整的多智能体自动化流水线
理论讲完了,来看看实际怎么落地。
我基于OpenClaw子代理机制,跑通了一条某书长文转可视化阅读卡片的自动化流水线。整个流程从输入链接到输出卡片,全程不用人工插手。
系统架构分三层:
第一层是主代理:某书看板总调度中心。
这是整个流水线的大脑。它负责接收文章链接后新建飞书数据行、拿到Record ID、然后按顺序派发所有子代理任务。等所有子代理跑完,它要做数据质检——检查字段是否为空、有没有异常。最后,它还要调用渲染技能,生成HTML可视化卡片,把最终文件发给用户。
第二层是子代理:某书标题拆解专家和某书开头设计拆解专家。
每个子代理只做一个专项任务。以标题拆解专家为例,它只干4件事:接收参数、抓取标题、结构化拆解、回写数据。子代理之间不通信,只跟主代理汇报。
第三层是渲染子代理:frontend-slides-skill。
这个子代理负责把结构化数据变成可直接打开的HTML卡片。它按照「深空毛玻璃阅读卡片」的设计规范,把标题、拆解内容、原文链接整合成一张高颜值、可移动端适配的卡片。
三层各司其职,通过主代理统一调度,形成了完整的自动化闭环。
四、全流程跑通:从链接输入到卡片输出
我把整个流水线拆成7个步骤,每一步谁在干什么,看得清清楚楚:
第一步,用户输入某书文章链接。
第二步,主代理新建飞书记录,拿到Record ID。
第三步,子代理1(标题拆解专家)开工:抓取标题 → 结构化拆解 → 回写表格 → 汇报完成。
第四步,子代理2(开头拆解专家)开工:抓取开头 → 结构化拆解 → 回写表格 → 汇报完成。
第五步,主代理质检数据,检查标题和开头两个字段是否都填写完整。
第六步,渲染代理启动,把结构化数据变成HTML可视化卡片。
第七步,主代理把最终卡片文件发给用户,流程结束。
整个闭环从头到尾,用户只需要做一件事:扔一个链接进去。等几分钟,一张完整的可视化阅读卡片就出来了。
五、常见疑问:为什么技能树看不到调用关系?
讲到这里,可能有同学会问:我在OpenClaw的技能树里,怎么看不到主代理和子代理之间的调用关系?
这个问题非常好,也是很多人踩过的坑。
答案很简单:OpenClaw的技能树展示的是物理文件目录结构,而子代理的调度逻辑是写在SKILL.md里的执行工作流。两者不是一回事,所以技能树不显示调用关系,但流程依然正常运行。
就像你公司的组织架构图和组织流程图是两套东西一样。组织架构图告诉你谁在哪个部门,组织流程图告诉你一件事要经过哪些环节。技能树相当于组织架构图,展示文件在哪;调度逻辑写在SKILL.md里,相当于组织流程图,展示任务怎么跑。
搞明白这个区别,你就不会在技能树里傻傻找调用关系了。
六、子代理机制的真正价值
用了这么久的OpenClaw子代理机制,我总结出它的4个核心价值:
第一,复杂任务简单化。 一条超长的流程拆成多个小任务,每个子代理只负责一小块。你不需要在一个会话里塞进所有逻辑,调试的时候也容易定位问题。
第二,系统更稳定。 子代理之间完全隔离,一个子代理出错不会把整条流水线带崩。主代理可以捕获异常、记录日志、决定要不要重试或者跳过。
第三,全自动无人干预。 从输入到输出,全程AI自己调度、自己执行、自己汇总。用户只需要在最开头给一个指令,在最结尾拿一个结果。
第四,可无限扩展。 想加能力就加子代理。标题拆解、开头设计、内容结构、插图、排版、引流、IP分析……想加什么就加什么,主代理统一调度,不用改原有逻辑。
结尾
对话框里一句简单的「子代理启动」,背后是OpenClaw一整套主从架构加消息通信加生命周期管理的底层机制。
在多智能体时代,OpenClaw用「总控加专家」的模式,让普通人也能搭建出专业级的AI自动化系统。你可以用同样的思路做内容创作、视频剪辑、数据报表、账号运营,任何复杂任务都能被拆成一组听话的子代理。
流水线搭好之后,你只需要做一件事:下命令,等结果。
你在使用OpenClaw的时候,遇到过哪些子代理相关的问题?
欢迎在评论区留言交流,我们一起探讨 🚀

