 夜雨聆风
夜雨聆风上篇讲了 HBM 的整体格局和四家公司的不同战线。这一篇回到 HBM4 这一代的具体战场。
真正决定 2026-2027 年格局的变化,不在市占率数字的小数点后面,而是HBM4。因为HBM4 不只是 HBM3E 的下一代,是整个供应链权力结构被重新洗一遍的起点。
HBM4量产的三道坎
三家厂商过去一年在 HBM4 上的进度集体拉胯,不是哪家工艺不行,是这一代的门槛比上一代跳了一个台阶。
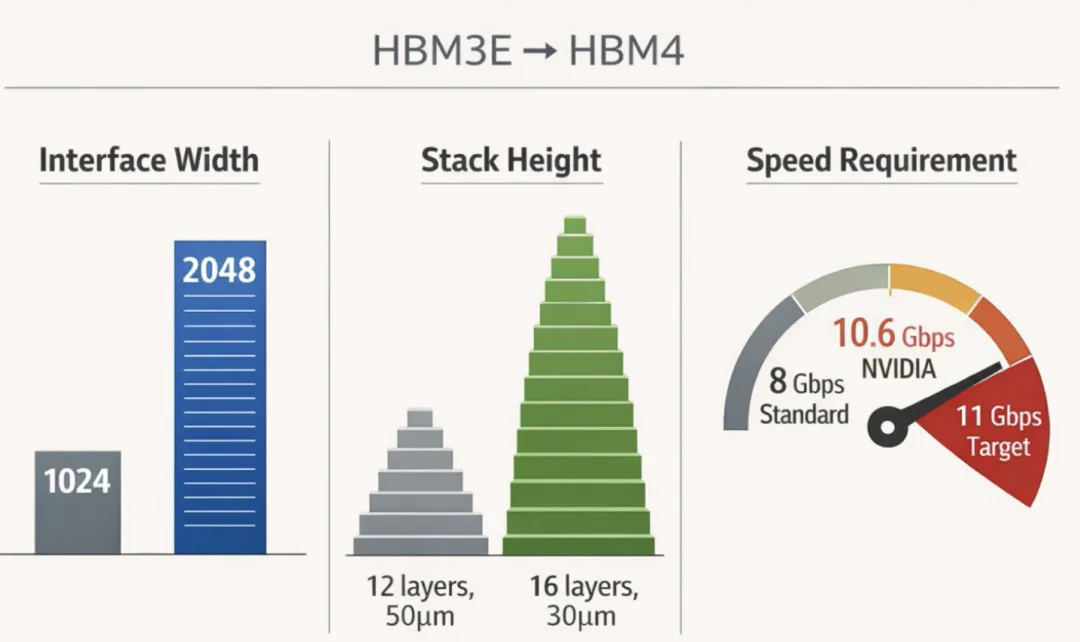
一:接口翻倍,底座必须换成逻辑芯片。
HBM3E 的数据接口是 1024-bit,HBM4 翻倍到 2048-bit。通道数量翻倍意味着 HBM 最底部那块 base die(基板)不能再用简单的信号转接板。2048 条通道的信号管理太复杂,base die 必须升级成一颗真正的逻辑芯片,而且要用台积电 4nm 这一级的先进制程来造。
这个变化有一个容易被忽略的后果:HBM 从一个”纯内存产品”变成了”内存 + 先进逻辑代工”的复合产品。成本结构、利润分配、供应链关系都跟着变。
二:堆叠从 12 层加到 16 层,硅片要磨得更薄。
行业标准把整颗 HBM 的总高度限死在 775 微米。层数加了 4 层,每一片内存芯片就得磨得更薄——从 50 微米压到 30 微米,大约是一根头发丝的三分之一。这个厚度的硅片极易碎裂,量产良率就是从这里崩的。
三:NVIDIA 要的速度超出了行业标准。
HBM4 的行业标准(JEDEC 定的)是每根数据引脚 8Gbps。NVIDIA 直接要到 11Gbps,最初甚至提过 11.7Gbps。比标准高出将近 50%。
16 层堆叠叠加这个速度,三家厂商初期良率都低于 20%——造 5 颗废 4 颗。量产根本走不下去。
这三道坎合在一起,意味着 HBM4 不是 HBM3E 的增强版,是一个新品类。过去”谁先搞定 HBM 谁吃肉”的逻辑,在 HBM4 上变成了”谁能先把良率爬到 50% 以上谁吃肉”。也许技术终点三家都能到,但是先后时间差决定谁拿大单、谁拿小单、谁只能转去做 DDR5。
NVIDIA HBM4降标准
上篇点到了 NVIDIA 把 HBM4 规格从 11Gbps 降到 10.6Gbps 这件事。表面上这只是一次技术妥协——标准太严做不出来,客户松口一档。但背后是 NVIDIA 对整个 HBM 供应链权力结构的一次主动调整。
如果维持 11Gbps,会发生什么?
大概率只有 海力士 一家能通过验证。三星 工艺窗口够不到,美光 被 base die 设计卡住。NVIDIA 下一代旗舰 AI 芯片 Rubin 的 HBM 供应会绑死在 海力士 一家身上。
这是任何一个头部芯片公司都不敢接受的结果。单点供应意味着只要 海力士 产线出任何意外——地震、停电、设备故障、甚至良率波动——Rubin 的整个量产计划就停摆。NVIDIA 过去几年对供应链单点风险的警觉性非常高,H100 时代已经吃过台积电 CoWoS 产能不够的亏。
为啥降到 10.6Gbps:给三星开门。
这一档规格正好落在 三星 工艺的及格线上。NVIDIA 用 0.4Gbps 的速度让步,换来了第二家合格供应商。量产安全性上去了,单点风险解除了。
付出的代价:总带宽从目标的 1.5TB/s 降到 1.35TB/s,少了 10%。但仍然比上一代 Blackwell 的 1.2TB/s 高出 12.5%,代际进步还在。
这就解释了上篇留的一个疑问——三星 为什么能在 2 月 12 日抢在 海力士 前面宣布 HBM4 量产?不是 三星 技术反超。是 NVIDIA 从另一边把门槛降了一档,三星 的工艺窗口正好够得着。两边各走一步,中间碰上了。
这个动作传递的信号,超出 HBM 本身。
过去两年 AI 硬件叙事的主线是”技术最强者通吃”——谁的芯片性能最好、良率最高、规格最激进,谁就拿单子。HBM4 这次降规格事件告诉市场:当技术难度超过供应链极限的时候,头部客户会主动降规格换供应商冗余。竞争叙事从”技术最强”转变成”按时交货”。良率、产能确定性、多供应商认证这些偏制造业的指标,权重在上升。
海力士 的 70% 和 三星 涨价:一个硬币的两面
上篇提到 海力士 拿下 Rubin HBM4 约 70% 的分配,同时主动砍了 20-30% 的产能。也提到 三星 HBM4 logic die 年内涨价 40-50%。这正从侧面反映出,HBM4 市场一个新特征——份额的含金量正在下降,定价权的含金量正在上升。
海力士 拿到 70% 份额,按老逻辑应该是大利好。但这 70% 是在”Rubin 推迟、总盘子缩水”的前提下拿到的,实际出货量可能还不如原来 50% 份额对应的量。更关键的是,海力士 作为绝对主力,要承担的是 Rubin 推迟的全部风险——NVIDIA 平台一天不放量,海力士 这些 HBM4 产能就一天变不成收入。所以它主动砍 20-30%,把产能转去做 HBM3E 和 DDR5,对冲平台风险。这是一个”拿着大单却不敢all-in”的姿态。
三星 那边的逻辑相反。份额只有 30%,但作为 NVIDIA 的第二供应商,定价上有底气。HBM4 logic die 年内涨价 40-50%,不是被动的供不应求涨价,是”我是少数能供应的厂商之一”的主动定价。而且因为份额小、出货压力小,Rubin 即使推迟,对 三星 的财务冲击也有限。
HBM 相关公司过去几年的定价逻辑,是跟着”NVIDIA 份额 × HBM 总需求”走的。HBM4 这一代开始,这个公式要加两个修正项。第一,份额要打”平台风险折扣”——拿大单的那家对客户出货节奏的依赖更深。第二,定价权要单独估值——少数供应商身份带来的涨价能力,在 HBM4 时代第一次变成一个明显的变量。
三星 在 HBM3E 代被踢出供应链的时候,市场给它的估值压到很低。现在它以”第二供应商”的身份回到牌桌,有涨价能力、没有 Rubin 风险全量敞口。这是一个结构上被低估的位置。

美光 的缺席和81% 毛利率
美光 没进入 Vera Rubin 旗舰供应商名单,只能供中端推理用的 Rubin CPX。上篇讲过它腾出来的产能做 DDR5,毛利率 81%。
这里要补一个上篇没讲透的判断:美光 的”缺席”不是战略失败,是一次有意识的选择。
三家厂商在 2025 年都面临同一道选择题——HBM4 良率还没爬上去,DDR5 涨价周期正热。把产能往哪放?
海力士 选 HBM4 为主、兼顾 DDR5。三星 选 HBM4 为主、用涨价换利润。美光 选完全倒向 DDR5。
美光 这个选择背后有一个很实际的判断:HBM4 的旗舰订单拿不下来,与其在中端 HBM 市场做低毛利的供应商,不如把产能换到正在涨价的 DDR5 上。结果是三家里财报最好看的那一家,反而是 HBM 市占率最低的那一家。
这件事对 HBM 投资叙事的冲击比很多人意识到的大:HBM 市占率和财务回报,在 HBM4 这一代第一次出现了脱钩。
按老逻辑,拿到 HBM 份额就是拿到 AI 算力红利。按 美光 这一季财报揭示的新逻辑,DRAM 公司的利润来源不止 HBM 一条线,当常规 DRAM 涨价的时候,HBM 份额甚至是劣后选项。这改变了投资者评估存储公司的框架——不能再用”HBM 份额”一个指标看全部。
美光 的 HBM4E 要到 2026 Q2 看良率爬坡。如果那一轮能挤回旗舰供应商名单,它就有了”HBM + DDR5 双轮驱动”的结构。挤不进,就继续做 DDR5 的专业户。这是一个二选一的分叉点,时间表比份额变化更重要。

HBM 价值链上移
正如上篇结尾提到”真正的分叉点在 2028 年的 HBM4E 和 hybrid bonding 量产”,HBM4 的故事里,最容易被忽略的产业机会在上游。
前面讲过 HBM4 的 base die 不再是简单转接板,必须是一颗台积电 4nm 的逻辑芯片。这个变化的直接后果是:单颗 HBM 的成本结构里,台积电的代工费占比在上升。HBM3E 时代,base die 成本占单颗 HBM 的 5-8%。HBM4 时代,这个比例上升到 15-20%。三家内存厂每卖出一颗 HBM4,都要给台积电交一份代工费。
台积电对应的产能类别是”CoWoS 先进封装 + 4nm 逻辑代工”。这两块产能原本就是紧缺的,HBM4 放量会加剧紧缺。对台积电来说,HBM4 不是拿一个新客户,是在一个现有产能瓶颈上再叠加一层需求。这部分业务的定价权会比整体晶圆代工更高。
再往上游:16 层堆叠在 HBM4 代还能用传统的 TC-NCF(热压非导电胶膜)工艺勉强做,但 HBM4E(2028 年左右)开始,堆叠可能上到 20 层以上,必须用 hybrid bonding(混合键合)工艺。这是一个全新的封装技术路线,设备需要重新采购。
Hybrid bonding 设备市场目前只有两三家玩家能做。荷兰的 BESI 是目前的领头羊,技术成熟度最高。应用材料(Applied Materials)通过收购切入。日本的 Disco 在 wafer 磨薄设备环节占主导——HBM4 把硅片从 50 微米磨到 30 微米,再往下到 HBM4E 的 20 微米以下,这个磨薄环节的设备需求在非线性上升。
内存厂商的竞争格局会变化——海力士 今天领先,三星 明天追上,美光 后天翻身都有可能。但上游的设备商和先进封装代工,供给侧更集中、新玩家进入门槛更高。三家内存厂竞争越激烈,上游越是旱涝保收。
过去三年 HBM 主题的投资几乎全部集中在三家内存厂。HBM4 这一代开始,这个结构会被迫调整——上游的台积电先进封装产能、BESI 的 hybrid bonding 设备、Disco 的磨薄设备,在 HBM 涨价中的受益比例会上升。

HBM4:缺席但受益
HBM4 的竞争发生在 NVIDIA 旗舰 AI 芯片的供应链上。长鑫的客户是华为昇腾、寒武纪这些国产 AI 芯片,做的是内循环市场。HBM4 的技术门槛(2048-bit 接口、16 层堆叠、台积电 4nm base die)长鑫现阶段达不到,也不需要达到——它的目标客户现在连 HBM3 都还没用上。
HBM4 三家集体延期、产能往 DDR5 倾斜这两件事,会给长鑫留出意想不到的时间窗口。海力士 把 HBM4 产能砍 20-30% 转去做 DDR5 这个动作,意味着它在 HBM3E 代的产能压力会持续更久。三星 把定价权往上拉意味着 HBM3E 的价格也会被抬高。对华为、寒武纪这些国产 AI 芯片厂商来说,哪怕美国出口管制松一点、能买到 HBM3E,价格也会越来越贵。这反而给长鑫的 HBM3 商业化留出了一个成本窗口——只要长鑫 HBM3 的良率能爬上去,价格上对国产客户就有吸引力。
HBM4 三家打仗的副作用,是 HBM3 这一代的性价比曲线被抬高了。长鑫是这个副作用的受益者,虽然它根本没参与这场仗。
HBM4产业值得跟踪的变量
变量一:良率。HBM4 三家厂商的 10.6Gbps 良率什么时候稳过 50%。这个数字决定 Rubin 什么时候真正放量,也决定 海力士 那 70% 的份额什么时候能变成真金白银的收入。第一个信号在下一个财报季。
变量二:DRAM 价格曲线和 HBM 价格曲线的关系。过去 HBM 相对常规 DRAM 的溢价是一个稳定的乘数。现在 DDR5 涨价压缩了这个溢价空间,三家厂商的产能分配选择会跟着变。跟踪 HBM4 需求节奏,必须同时跟踪 DDR5 的合约价走势。
变量三:Rubin 的放量时间表。Rubin 每推迟一个季度,HBM3E 需求就多强一个季度,海力士 的 70% 份额就多一份风险。这个时间表要看 NVIDIA 自己的披露,也要看 CX9 网络互联、液冷方案这些 Rubin 平台的配套进度。
变量四:上游的产能分配。台积电 CoWoS 产能里分给 HBM4 base die 的比例、BESI 和 Disco 的订单节奏、hybrid bonding 量产的时间表。这些数据披露频率比内存厂低,但更领先。能看懂这些指标,就能比市场早半年看到 HBM4E 的格局。
变量五:长鑫的良率和 IPO 节奏。长鑫科技科创板 IPO 预计 2026 Q1 上市,之后会开始披露详细的财务和产能数据。HBM3 良率、产能转换比例、华为订单规模,这些信息会在招股书和季报里陆续出来。国产 HBM 投资能不能落地,看这些数字。
总之,HBM4目前开局局面不再是海力士一家通吃。HBM4 这场新战役,比上HBM3热闹得多。
