 夜雨聆风
夜雨聆风研究AIOps已有数月,目前手里有不少可落地的方案了,接下来会把这些方案全部整理到我的大模型课程里。欢迎大家把你遇到的场景在评论区留言。我会在能力范围内给你提供思路和建议。
OpenClaw的热度已经过去了,很多搞自媒体的、搞技术的甚至我们运维圈里也有不少朋友都在用它给自己打工。效果到底怎么样,只有深度用过它的人才能说的清吧。对于我的需求场景来说,确实能帮我做不少事儿,也确实能提效,但远远没有预想的那么牛逼。
而最近呢又出来一个跟OpenClaw类似的竞品:Hermes Agent(下文简称Hermes),业界不少人叫它“爱马仕”。这玩意,最大的优势就是可以自我学习、自我进化,这个能力主要归功于它的“记忆”系统。
而咱们运维领域不就需要这种“自我进化”的超级Agent吗?所以,这两天我就在琢磨能不能把Hermes深度用于AIOps体系里。于是,今天这篇文章就产生了。
01|为什么Hermes适合做AIOps
真正的运维工作,从来不是一次性的。
它是连续的、上下文密集的、经验驱动的。它需要记住你们系统的历史问题,理解你们业务的依赖关系,知道某类告警在你们环境里意味着什么,知道哪个指标抖动是噪音,哪个日志模式其实是事故前兆。
说白了,运维最值钱的部分,不是“会查资料”,而是会积累经验,会复用经验,会把经验越滚越厚。
而这,恰恰是我觉得Hermes最有意思的地方。它不是只想做一个会调用工具、会跑任务的agent。它真正想做的是一个带学习闭环的agent:
会在交互中积累上下文
会保留长期记忆
会沉淀技能
会在后续任务里复用这些技能
甚至可以继续改进自己的技能和工作方式
这意味着它天然就非常适合那些不是一次性任务,而是长期演化型任务的场景。而AIOps,恰恰就是这种场景。
为什么说AIOps这个方向,Hermes天然合适?因为运维、排障、故障定位、根因分析,本质上都特别依赖三件事:
第一,经验。很多问题不是“有没有标准答案”,而是“你有没有见过”。
第二,上下文。一次故障从来不是孤立的,它背后往往挂着变更记录、依赖关系、历史告警、拓扑结构、机器状态、日志模式、链路异常。
第三,持续优化。真正厉害的运维体系,不是每次从头排障,而是同类问题下次再出现时,可以更快定位、更快处置、更少踩坑。
你会发现,这三件事,刚好都不是传统问答式 AI 最擅长的。但它们却非常符合 Hermes这种“会记、会学、会沉淀”的agent形态。
02|基于Hermes做AIOps平台的思路
我觉得运维这件事,最有价值的并不是你做出来多么牛逼的一个运维平台,而是平台背后越来越厚的经验。
比如:
你们系统里,哪个告警经常是虚报、假报
哪类错误日志通常意味着上游依赖超时
某个业务在大促前后,哪些波动其实是正常现象
某个服务抖动时,先查什么最有效
某个故障在你们组织内部,最靠谱的处理路径是什么
这些东西,不太像“固定规则”,更像“组织经验”。而组织经验最适合由什么来承载?
它不是一个死规则引擎,也不是一个一次性回答器,而是一个持续工作并且能持续进化的载体。Hermes不就是这样的载体吗?
所以我更看好的一种思路是:不要只想着把大模型接进运维平台。而是反过来:把Hermes这个智能体放到运维平台正中间。也就是说,把Hermes当成核心引擎,然后围绕这个引擎,再去补企业级平台能力。
如果按这个思路去设计,一个比较合理的架构会是这样:
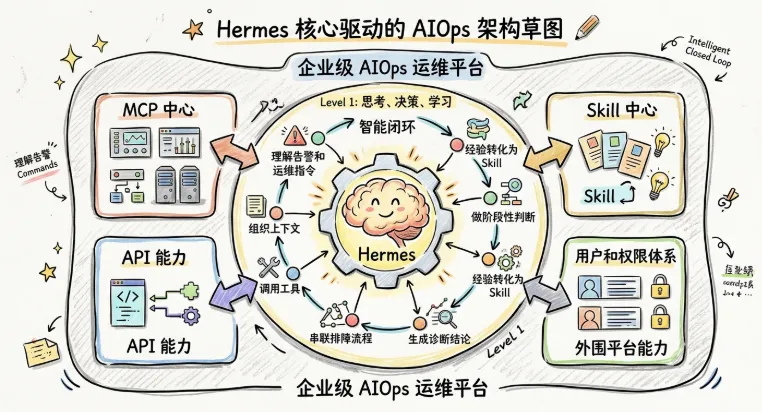
一层:Hermes负责“思考、决策、学习”
它是整个 AIOps 平台的大脑,主要负责:
理解告警和运维指令
组织上下文
调用工具
串联排障流程
做阶段性判断
生成诊断结论
从一次次故障处理中沉淀经验
把经验转化成可以复用的 skill
换句话说,它不只是“接问题”,而是接管整个智能闭环。
二层:在Hermes外围补齐平台能力
这个平台层,至少应该补四块:
MCP 中心
Skill 中心
用户和权限体系
API 能力
我觉得这四块,基本就是把Hermes产品化、平台化、企业化的关键。
03|AIOps平台的4个核心能力
1)MCP 中心:把所有运维系统都接到Hermes身上
如果Hermes是大脑,那MCP中心就是它的“神经系统”。因为运维现场最怕的不是“AI 不聪明”,而是“AI 什么都看不到”。
它如果拿不到监控数据、日志、链路、拓扑、变更记录、工单、发布信息、集群状态,它再聪明也只能猜。
所以第一件事,就是把企业现有的运维生态,统一接到Hermes上:
监控系统
日志系统
链路系统
CMDB
发布系统
工单系统
值班系统
Kubernetes / 云资源平台
数据库和中间件控制面
内部知识库 / Runbook / Wiki
ChatOps / IM / 邮件告警
这样,Hermes才不是一个“会说运维术语的聊天机器人”,而是一个真的能进现场、看数据、拉上下文、做动作的运维智能体。
但MCP中心不能只做“连接器市场”。它还必须承担平台治理角色,比如:
工具注册与发现
接入规范
版本管理
权限控制
调用审计
高风险操作审批
安全隔离
因为一旦agent真正开始接生产系统,你会发现最重要的已经不是“接没接上”,而是“接上之后怎么安全地用”。
2)Skill 中心:把运维经验变成平台资产
这是我觉得最有想象力的一层。很多公司做运维智能化,最后容易卡在一个地方:系统很强,但经验不沉淀。
今天某个专家处理了一个复杂故障,很精彩。明天另一个同学再遇到类似问题,还是得从头来一遍。这就很可惜。
而Hermes的skill机制,刚好给了一个很好的承载方式。我们完全可以把Skill中心做成“运维经验的产品化平台”,用来沉淀这些东西:
告警分级策略
服务排障 SOP
数据库诊断流程
中间件故障处置套路
发布失败回滚步骤
RCA 分析模板
事故复盘模式
各业务线特有的故障经验
更关键的是,它不应该只是人工录入的知识库。它应该是一个动态闭环:
一次真实故障处理完成后,Hermes从中抽取可复用步骤 → 生成skill草稿 → 专家审核 → 上线复用 → 后续继续优化。
这个闭环一旦跑起来,平台的价值就不只是“帮你处理故障”,而是:每处理一次故障,都在给平台增加能力。
这种模式就像是一个“会长大的运维系统”,这不正是我们想要的吗?
3)用户和权限体系:决定它能不能真的上生产
运维场景天然就是高权限、高风险场景。查日志和重启服务,根本不是一个风险等级。看监控和改流量,也不是一个风险等级。
所以如果Hermes要成为AIOps核心引擎,那它外面必须有完整的用户和权限体系:
用户身份管理
组织隔离
团队角色
环境隔离
工具级权限
数据级权限
动作审批
审计留痕
比如:
研发可以看指标、查日志,但不能执行生产动作
值班 SRE 可以执行低风险自动化
数据库动作必须走 DBA 权限
涉及生产变更、重启、流量切换的操作必须审批
Agent 每一次调用什么工具、拿了什么数据、做了什么判断,都必须能回溯
只有把这层补齐,Hermes才能从“聪明”变成“可用”。
4)API能力:让AIOps平台变成全公司都能调用的智能底座
这一层也非常关键。因为真正的平台,不能只停留在一个聊天框。
如果Hermes只是一个对话界面,那它最多是个助手。但如果它有标准API,它就能变成整个企业的智能运维底座。比如提供如下API:
告警接入API
智能诊断API
根因分析API
Runbook执行API
事故复盘API
Skill 查询/ 发布 API
MCP管理API
权限和审计API
这样它就可以接到各种系统里:
监控平台触发自动诊断
工单系统自动拉取RCA结果
ChatOps机器人查询排障建议
发布平台做变更风险分析
运营平台展示故障处理链路
领导驾驶舱读取事故总结和趋势
到这一步,它就不再是一个孤立的agent产品,而是企业运维系统里的“智能核心服务”。
04|先从简单场景落地开始
基于以上思路,我觉得最适合落地起步的,是下面三个场景。
场景一:告警智能助手
这个最容易切进去,也最容易体现价值。当告警来了以后,Hermes自动去拉:
指标变化
关联日志
最近变更
依赖服务状态
历史相似故障
责任团队信息
然后给出一个结构化结果:
告警摘要
影响范围
疑似根因
排查建议
推荐升级路径
建议通知人
这个场景的价值非常直接:把值班同学从“到处翻系统”变成“直接接收上下文完整的诊断入口”。
场景二:故障排查Copilot
这比告警助手更进一步。它不是只“告诉你发生了什么”,而是能按skill去引导整个排障过程。比如:
先查最近变更
再查上游依赖
再聚类错误日志
再看关键指标转折点
再检索历史相似案例
最后生成阶段性判断
这个时候,Hermes的优势就会特别明显。因为这已经不是单轮问答,而是真正的“连续故障处理”。
场景三:根因分析和复盘助手
这可能是长期价值最高的场景。因为它不仅帮助你在事故过程中动态分析,还能在事故结束后,把整个过程沉淀下来:
还原时间线
汇总关键信息
归纳疑似根因
生成复盘初稿
抽取可复用经验
形成skill候选
你会发现,一旦做到这一步,事故处理和经验沉淀就真正连起来了。这个能力可能是AIOps最稀缺的地方。
顺便介绍下我的大模型课:我的运维大模型课上线了,目前还在预售期,有很大优惠。AI越来越成熟了,大模型技术需求量也越来越多了,至少我觉得这个方向要比传统的后端开发、前端开发、测试、运维等方向的机会更大,而且一点都不卷!
扫码咨询优惠(粉丝优惠力度大)

