夜雨聆风
夜雨聆风LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
- 1、[LG] Parcae: Scaling Laws For Stable Looped Language Models
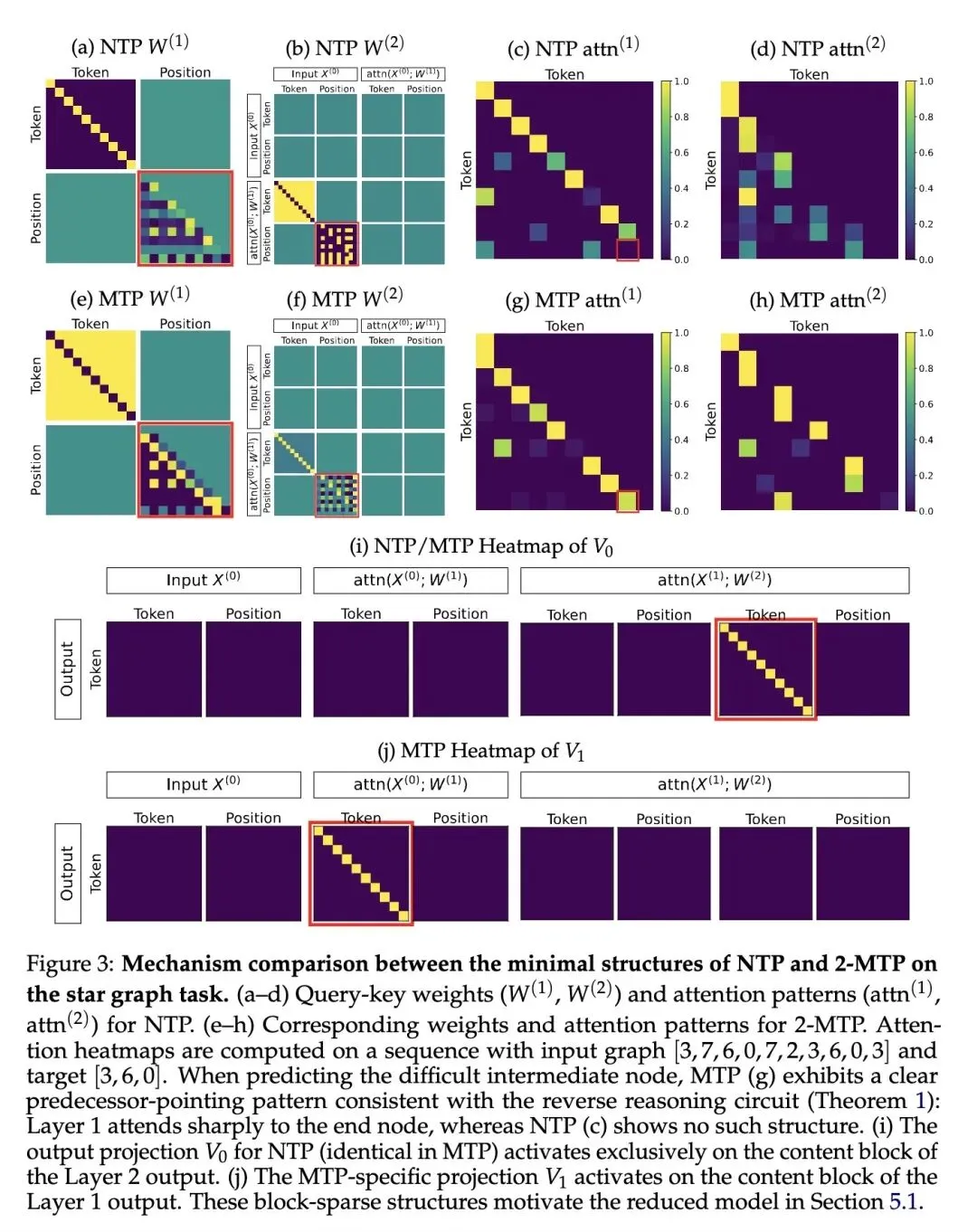
- 2、[LG] How Transformers Learn to Plan via Multi-Token Prediction
- 3、[LG] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
- 4、[CL] Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
- 5、[CL] Toward Autonomous Long-Horizon Engineering for ML Research
摘要:稳定循环语言模型的规模法则、Transformer如何通过多Token预测学习规划能力、长程思维链推理基准测试、通过自我修正将二元奖励转化为稠密监督、迈向机器学习研究的自主化长程工程
1、[LG] Parcae: Scaling Laws For Stable Looped Language Models
H Prairie, Z Novack, T Berg-Kirkpatrick, D Y. Fu
[University of California, San Diego]
Parcae:稳定循环语言模型的规模法则
要点:
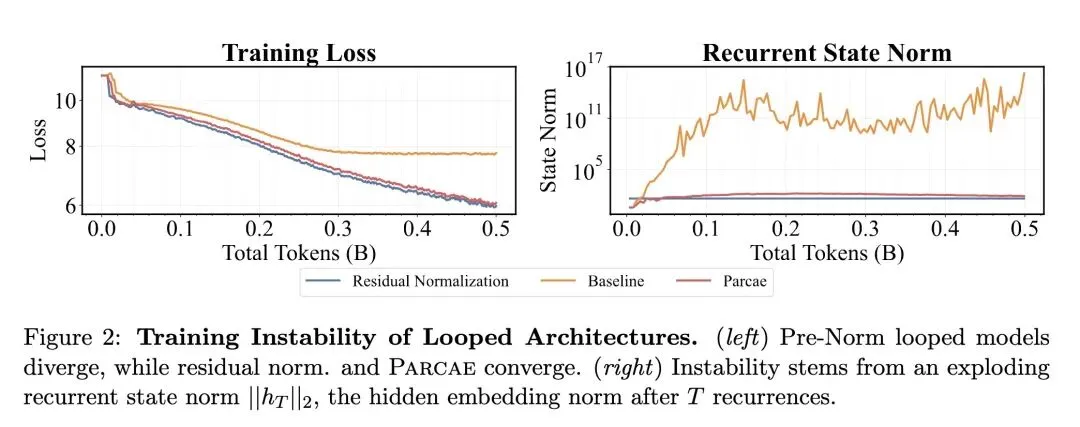
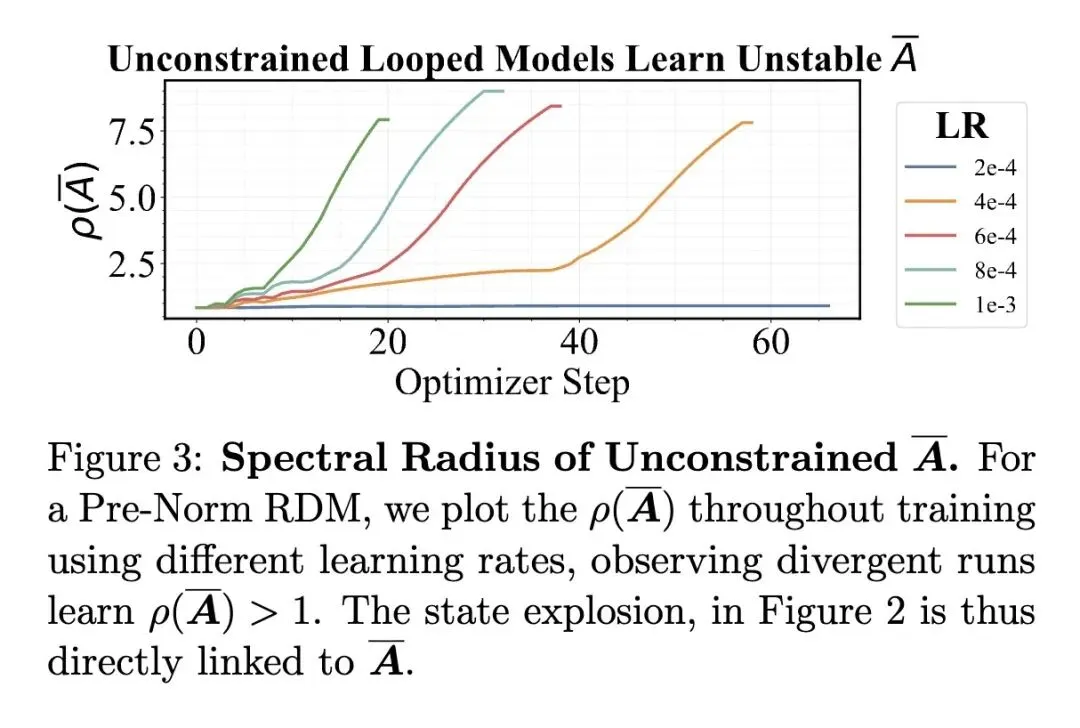
挑战了关于循环Transformer训练不稳定性(状态爆炸)源于复杂的非线性模块(注意力机制、MLP)的直觉假设;相反,它精确指出线性的输入注入参数才是罪魁祸首。 将循环架构重构为残差流上的离散线性时不变(LTI)动力系统,将经典的控制理论成功应用于神经网络分析。 发现先前的循环模型在隐式地学习不稳定的参数化,其转移矩阵的谱范数 ,从而导致了残差爆炸。 提出了Parcae模型,通过将转移矩阵参数化为负对角矩阵,强制其谱范数 ,从结构上保证了稳定性。 打破了循环模型具有“无限测试时计算扩展(Test-time Compute Scaling)”的迷思。它在数学上证明了,在推理时运行更多的循环会产生收益递减,遵循可预测的、逐渐饱和的指数衰减规律。 揭示了测试时的性能上限受到模型在预训练期间接触的循环深度()的严格限制。 确立了“循环(Looping)”与数据量、参数量一样,是一个一等、正交的扩展维度(Scaling Axis)。在固定FLOPs预算下的最优训练,需要根据精确的幂律同步扩展数据量和循环深度。 实证证明了1.3B参数的Parcae模型可以媲美2.6B参数的传统固定深度Transformer的下游任务质量,实际上将所需的内存占用减半。 解决训练损失尖峰的方法不是修改架构,而是将每个微批次(per-micro-batch)的深度采样改为每个序列(per-sequence)的深度采样,从而更好地逼近随机深度的期望值。
主旨: 这篇文章主要解决了循环语言模型(Looped LLMs,即通过重复使用同一层或块来增加深度的模型)在训练中存在的残差爆炸和损失尖峰等严重的不稳定问题,并探究了如何通过引入“循环”这一新维度,在训练和推理阶段建立可预测的计算扩展定律(Scaling Laws),从而在不增加内存占用的情况下提升模型质量。
创新:
引入了LTI(线性时不变)动力系统理论来解构Transformer的残差流,这是一种非常新的跨学科分析视角。 提出了一种基于负对角矩阵的连续参数离散化方法(Parcae架构),巧妙地从数学层面限制了转移矩阵的谱范数,彻底解决了残差爆炸问题。 在训练算法上,创新性地提出了“单序列深度采样(Per-sequence depth sampling)”机制,替代了以往的批次级采样,极大地平滑了训练早期的方差,消除了损失尖峰。 提出了一个“统一扩展定律(Unified Scaling Law)”,将训练时的幂律(Power Law)和测试时的指数衰减律(Exponential Decay)完美结合在一个数学公式中。
贡献:
理论贡献:解释了循环模型不稳定的根源,证明了不稳定性来源于注入参数的谱范数过大,而非复杂的注意力机制。 架构贡献:设计了稳定且高效的Parcae架构,并通过引入Prelude Normalization进一步提升了大参数规模下的训练稳定性。 规律发现:首次系统性地测定并证明了“循环深度”与“参数量”、“数据量”一样,是提升模型性能的独立正交维度。并推导出了对应的训练和推理Scaling Laws。 实践贡献:用一半的参数量(1.3B)达到了双倍参数量(2.6B)传统Transformer模型的同等水平,为端侧设备部署极低显存占用的大模型指明了方向。
提升:
相比于以往的循环模型(RDMs),Parcae在验证集困惑度(Perplexity)上降低了6.3%。 在同等参数量和数据预算下,扩展到1.3B参数的Parcae模型在Core和Core-Extended基准测试上,比强基线Transformer模型分别提升了2.99分和1.18分。 实现了极高的参数效率,其模型质量最高达到了尺寸是其两倍的Transformer模型的87.5%。
不足:
规模验证有限:目前该架构的实验最大规模仅验证到了1.3B参数,是否在百亿甚至千亿级别的更大FLOPs预算下依然保持最优扩展规律,仍有待验证。 推理延迟问题:随着预训练最优循环深度()的增加,测试时为了达到同等质量所需的推理步数也会增加,这可能会导致推理延迟(Latency)的上升。 设计空间的局限:该研究主要集中在中间层循环(Middle-looping),对于其他循环放置策略、复杂拓扑或极深层循环的探索仍然不够。
心得:
重新认识非线性与线性系统:当深度神经网络(如Transformer)出现梯度爆炸或状态爆炸时,我们常常本能地怀疑是复杂的非线性模块(如自注意力或MLP)出了问题。这篇文章极具启发性地指出,问题的根源往往在于最简单的线性部分(如残差注入)。利用经典的控制理论来约束深度学习模型,是一条被严重低估的研究路径。 打破“无限思考时间”的错觉:近年来Test-time compute(测试时计算)非常火热,人们直觉上认为只要给模型更多的循环“思考”时间,效果就能不断提升。但本文的数据无情且清晰地揭示:测试时收益会呈现指数级衰减并触及“天花板”,而这个“天花板”的高度是在预训练阶段通过循环深度()被锁死的。这对于当下狂热的System 2 / Test-time scaling研究是一记绝佳的清醒剂。 开启多维扩展定律的新纪元:在此之前,算力(FLOPs)的最优分配主要在“数据量”和“参数量”之间进行权衡(如Chinchilla定律)。本文证明了“循环(递归)深度”是第三个正交维度。这意味着未来的小显存设备(如手机端)可以通过加载小参数模型,但运行深度的循环计算,来达到原本需要大显存才能实现的效果,这深刻改变了端侧AI的模型设计范式。
一句话总结:
本文通过将循环架构重构为经典控制理论中的线性时不变动力系统,精准解决了其训练不稳定的痛点,并提出了Parcae模型及统一的缩放定律(Scaling Laws),证明了“循环”是一个可预测的正交扩展维度,使1.3B的循环模型成功媲美2.6B的传统Transformer。
Traditional fixed-depth architectures scale quality by increasing training FLOPs, typically through increased parameterization, at the expense of a higher memory footprint, or data. A potential alternative is looped architectures, which instead increase FLOPs by sending activations through a block of layers in a loop. While promising, existing recipes for training looped architectures can be unstable, suffering from residual explosion and loss spikes. We address these challenges by recasting looping as a nonlinear time-variant dynamical system over the residual stream. Via a linear approximation to this system, we find that instability occurs in existing looped architectures as a result of large spectral norms in their injection parameters. To address these instability issues, we propose Parcae, a novel stable, looped architecture that constrains the spectral norm of the injection parameters via discretization of a negative diagonal parameterization. As a result, Parcae achieves up to 6.3% lower validation perplexity over prior large-scale looped models. Using our stable looped architecture, we investigate the scaling properties of looping as a medium to improve quality by increasing FLOPs in training and test-time. For training, we derive predictable power laws to scale FLOPs while keeping parameter count fixed. Our initial scaling laws suggest that looping and data should be increased in tandem, given a fixed FLOP budget. At test-time, we find that Parcae can use looping to scale compute, following a predictable, saturating exponential decay. When scaled up to 1.3B parameters, we find that Parcae improves CORE and Core-Extended quality by 2.99 and 1.18 points when compared to strong Transformer baselines under a fixed parameter and data budget, achieving a relative quality of up to 87.5% a Transformer twice the size.
https://arxiv.org/abs/2604.12946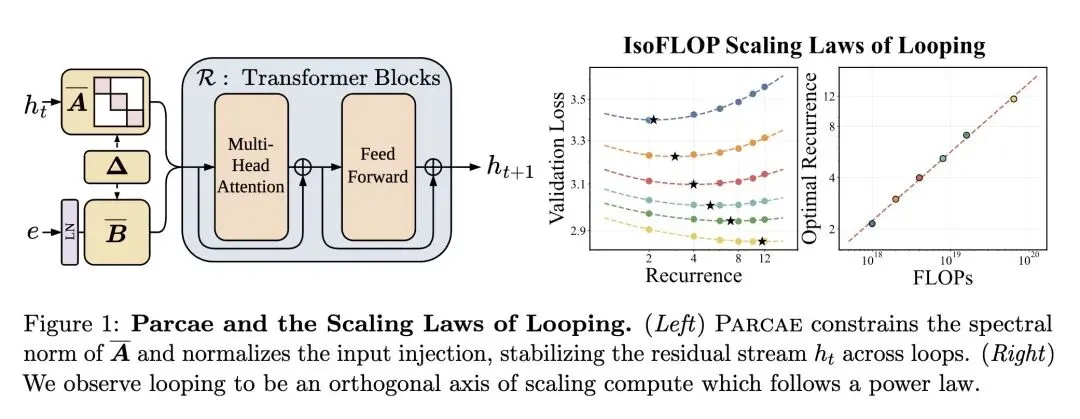
2、[LG] How Transformers Learn to Plan via Multi-Token Prediction
J Huang, Z Zhou, R Xia, B Mirzasoleiman…
[University of California, Los Angeles & Shanghai Jiao Tong University]
Transformer如何通过多Token预测学习规划能力
要点:
挑战了“多Token预测(MTP)仅仅是通过防止‘聪明汉斯作弊’(即模型盲目复制前缀模式)来提升推理能力”的传统假设,证明了MTP从本质上改变了优化动力学,从而形成稳健的规划回路。 揭示了MTP诱导出的一种反直觉的“反向推理(Reverse Reasoning)”过程:在解决路径寻找问题时,模型首先将注意力集中在目标(终点节点)上,然后向后回溯中间步骤,而不是从起点向前搜索。 确定了“梯度解耦(Gradient Decoupling)”是MTP成功的核心数学驱动力:浅层的MTP预测头将梯度专门路由至早期层,绕过了未初始化的深层网络,提供了干净、隔离的训练信号。 在数学上证明了,标准的下一个Token预测(NTP)在初始化阶段实际上会主动排斥早期层中最佳的“前驱指向(predecessor-pointing)”注意力模式,从结构上阻碍了模型学习全局规划算法。 证明了MTP有效地将一个复杂的多步前向组合搜索问题,转化为了一个干净、解耦的两阶段对比学习问题(第一阶段学习位置指针,第二阶段学习内容匹配)。
主旨: 本文旨在探索多Token预测(MTP)目标如何相较于传统的下一个Token预测(NTP)赋予大型语言模型更强的全局规划和推理能力。通过实证评估和严格的理论推导,研究揭示了MTP利用独特的“梯度解耦”属性,使Transformer在训练中自发学会了一种高效的“反向推理”算法机制。
创新:
首次从理论上严格分析了MTP的收敛动力学,并构建了其与传统NTP在训练动态上的数学对比框架。 采用双层解耦Transformer(Disentangled Transformer)架构作为理论分析工具,精确剖析了注意力机制在MTP下如何形成两阶段的内部算法回路。 创新性地提出了“梯度解耦”机制解释:从数学上证明了并行的MTP输出头如何切断不同层之间纠缠的梯度信号,为浅层特征提取和深层逻辑匹配提供了分阶段的完美优化路径。
贡献:
理论贡献:证明了MTP能诱导出“关注终点-- 实证贡献:在星形图(Star graph)和二叉树图任务中,通过控制变量证实了MTP不仅仅是消除了数据的捷径(聪明汉斯作弊),而且真正习得了更强的规划能力;同时在Countdown(算24点变体)和3-SAT等真实且复杂的NP-Complete推理任务上验证了MTP架构的明显优势。 机制解释:为目前工业界前沿大模型(如DeepSeek-V3等)广泛采用MTP架构提供了坚实的机理层面的理论背书。
提升:
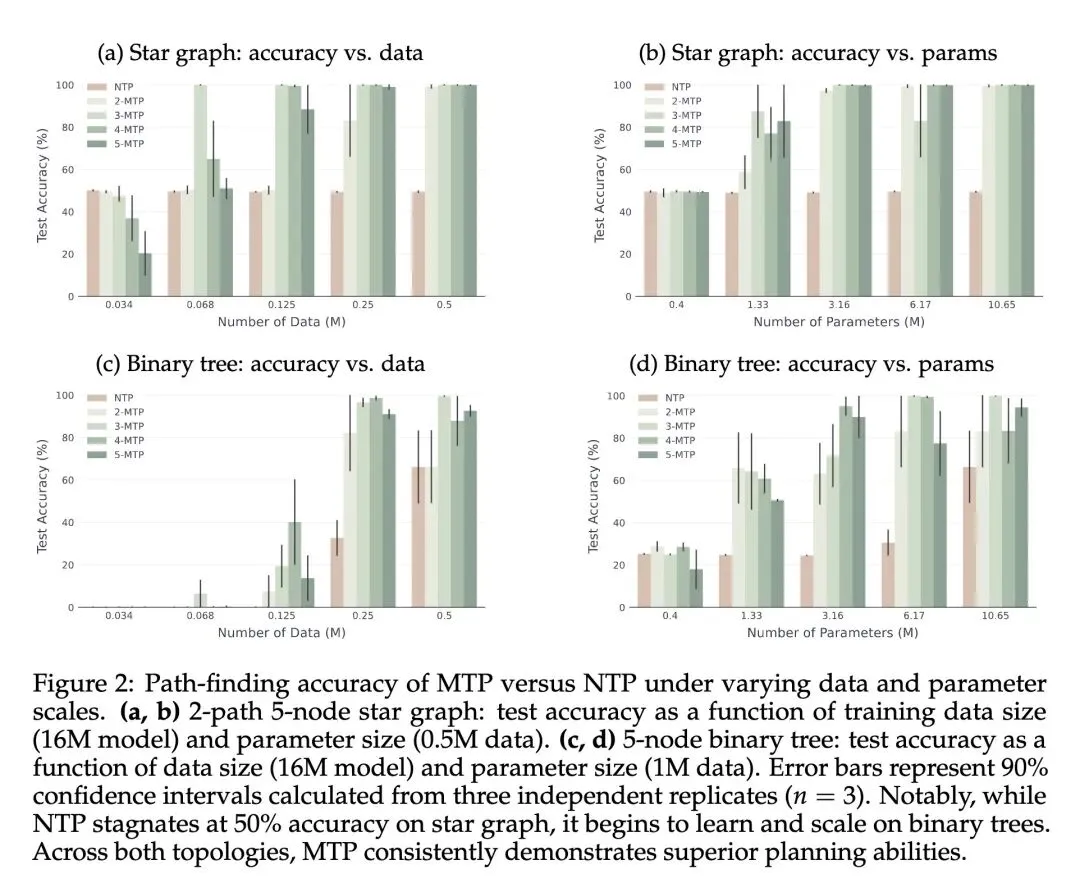
图规划任务准确率:在星形图任务上,MTP实现了100%的路径寻找准确率,而标准NTP在扩大数据和参数量时始终停滞在50%的随机猜测水平;在更难的二叉树任务中,MTP依然全面且显著地优于NTP。 复杂逻辑与计算:在Countdown(算术规划)和3-SAT(布尔可满足性问题)任务中,使用MTP训练的模型测试准确率均大幅超越NTP(例如在3-SAT任务中,7-MTP配置将准确率从NTP的10.40%极大幅提升至87.47%)。
不足:
理论模型假设的局限:目前的理论分析主要建立在简化的双层解耦Transformer模型和极简的2路径3节点星型图上,能否平滑推广至极深层架构、任意图拓扑以及非线性激活的MLP模块仍有待进一步证明。 缺失顺序MTP的分析:该研究聚焦于独立的并行MTP预测头(Independent-head),尚未分析工业界常用的顺序MTP变体(Sequential MTP,例如DeepSeek-V3的实现)在梯度动力学上的异同。 收敛率证明暂缺:文章对梯度流的分析更多是方向和驻点的性质证明,尚缺乏有限时间下收敛率(Finite-time convergence rates)的严谨刻画。
心得:
训练目标重塑模型思维模式:这篇文章带来最震撼的启发是,多Token预测绝不仅仅是为了“推理加速”或“给模型更强的数据监督”,它从根本上重塑了模型的认知回路。仅仅是增加未来的几个预测头,就能让模型从盲目的“走一步看一步(前向生成)”转变为类似人类的“以终为始(反向推理)”,这表明Loss函数的设计可以作为一种内隐的算法诱导器。 “梯度解耦”是复杂网络寻优的密钥:标准NTP失败的原因在于“梯度纠缠”——底层的注意力模式必须通过顶部随机初始化的权重层才能获得反馈,结果导致底层学不到真正的规律(甚至被推向错误方向)。MTP中较浅的预测头刚好起到了“短路”梯度的作用,让底层先学好位置指针,顶层再学内容匹配。这提示我们,在设计大模型训练范式时,为不同深度的网络提供直接、解耦的监督信号极其关键。 跳出“聪明汉斯”陷阱:过去我们常认为NTP做不好逻辑推理是因为数据集里有捷径可走。作者通过二叉树实验证明,即使完全切断捷径,NTP还是表现不佳,问题依然出在优化路径上。这告诫研究者在分析LLMs的推理缺陷时,不能只停留在数据层面,更要深入模型优化动力学的微观层面。
一句话总结:
本文从理论与实证双重维度揭示了多Token预测(MTP)相较于标准下一个Token预测(NTP)的本质优势,证明了MTP通过独有的“梯度解耦”机制,成功克服了NTP的梯度纠缠问题,诱导Transformer在训练中自发学会了从目标节点向后回溯的“反向推理”全局规划算法。
While next-token prediction (NTP) has been the standard objective for training language models, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.
https://arxiv.org/abs/2604.11912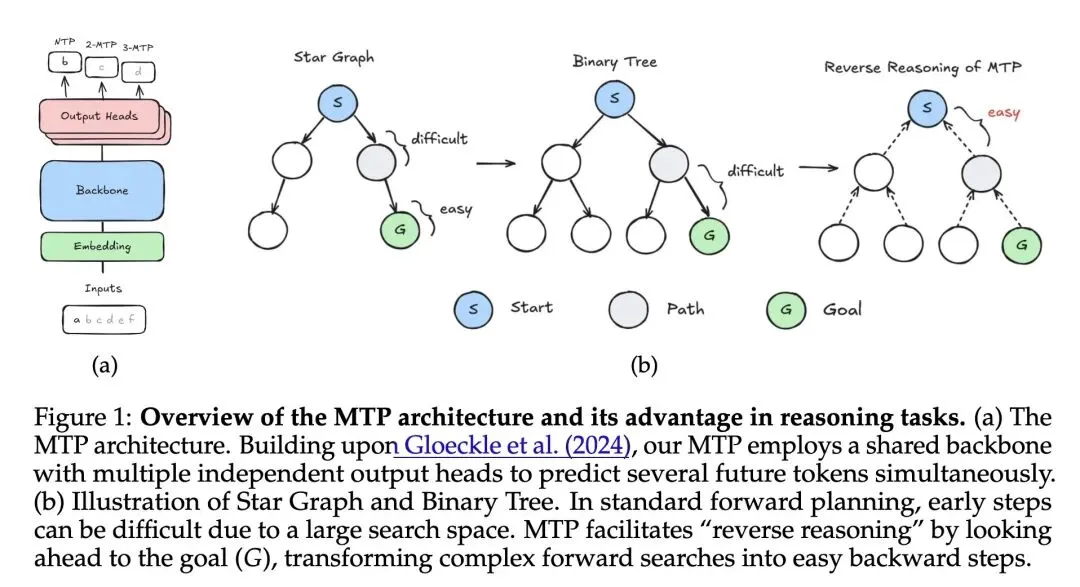
3、[LG] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
S R Motwani, D Nichols, C London, P Li…
[University of Oxford & Lawrence Livermore National Laboratory (LLNL)]
LongCoT:长程思维链推理基准测试
要点:
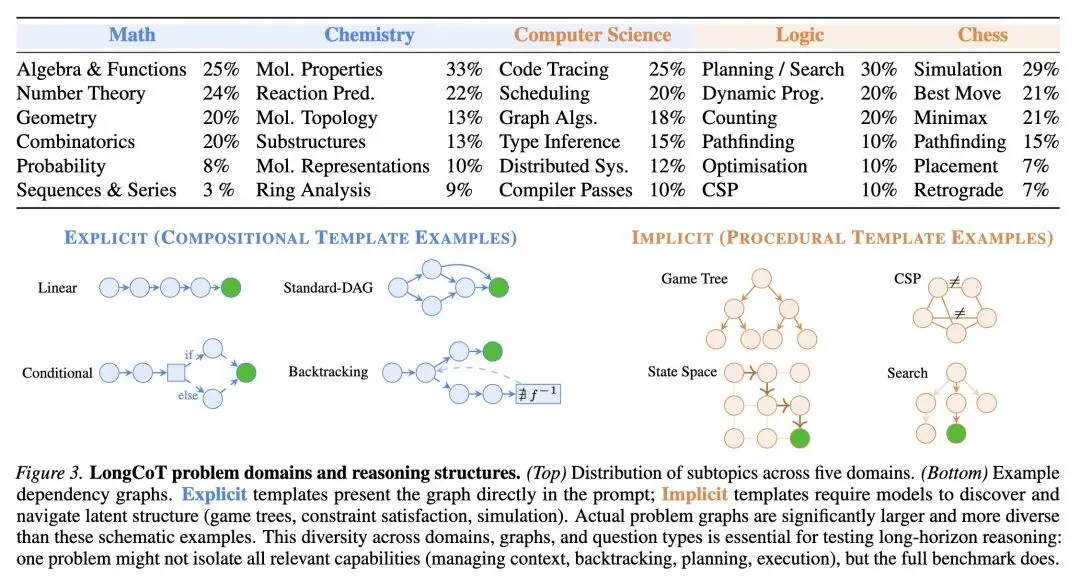
指出了当前大模型基准测试的一个关键盲区:现有的评估要么测试短链推理,要么测试Agent工作流(严重依赖工具使用和外部脚手架),未能衡量模型维持连贯的、长周期思维链(Long-Horizon CoT)的内在能力。 推出了 LongCoT,一个包含2500个可验证问题的严苛基准测试,涵盖5个截然不同的领域(化学、数学、计算机科学、国际象棋、逻辑)。 反直觉的设计: 题目的难度并不来自于冷门知识或极难的原子步骤。单个子问题对前沿模型来说很容易解决。极端的难度完全来自于复杂的图结构依赖(有向无环图、博弈树、循环约束),这需要模型生成数万到数十万个推理Token来导航。 严格在无工具环境(不允许执行代码)下运行,以剥离外部干扰,纯粹衡量基础推理能力:上下文管理、长期规划、约束传播和回溯纠错。 采用专家设计的参数化模板(显式/组合式 和 隐式/过程式),既能实现问题的大规模程序化生成,又能有效防止训练数据污染。 令人震惊的结果: 前沿模型在LongCoT上遭遇滑铁卢。最强的闭源模型 GPT 5.2 仅取得 9.83% 的准确率(尽管其每题平均输出高达6.2万个推理Token)。Gemini 3 Pro得分为6.08%,Claude 4.5 Sonnet仅为2.04%。开源模型得分几乎为零。 构建了 LongCoT-mini(500个较简单的问题),成功用于区分开源模型的能力(例如,DeepSeek V3.2在此子集上达到8.3%,Kimi K2达到7.5%)。 高信息熵发现: 随着问题长度增加,模型性能的下降幅度远大于独立误差累乘的数学期望。这证明了模型的失败是结构性的(状态丢失、无法回溯),而不仅仅是随机的局部错误。 证实了如递归语言模型(RLMs)等先进的Agent脚手架在纯长程推理任务上失效,因为图结构依赖无法被干净地分解或折叠,强行分解会导致关键状态丢失。
主旨: 本文旨在解决现有大模型评测体系的缺陷,提出了一个名为LongCoT的全新基准测试,旨在剥离外部工具和脚手架的干扰,通过引入极长输出(数万至十万级别Token)和高度图依赖的任务,纯粹且直接地衡量前沿大模型在长周期思维链中的规划、状态保持、错误检测和回溯推理能力。
创新:
能力剥离与极限施压: 首次明确区分了“Agent工具使用能力”与“模型内生长程推理能力”,通过禁止代码执行,迫使模型只能通过其内部的思维链(CoT)来承载巨大的依赖结构计算负担。 图依赖难度的参数化构造: 摒弃了依靠“单步超难”来难倒模型的传统做法,创新性地采用“原子步骤简单,全局图结构复杂”的范式。通过显式(如DAG组合)和隐式(如博弈树搜索)的专家参数化模板,实现了长程推理难度的精准和可扩展控制。 反解耦验证范式: 针对近期流行的上下文折叠和多Agent协作架构(如RLM),LongCoT通过高度交织的任务状态设计,专门击穿了这些试图走捷径的框架,确保测试的是真正的全局连贯推理。
贡献:
构建了迄今为止对大模型长程纯逻辑思维链考验最为严苛的基准测试集(覆盖五大学科,2500道高质量校验题)。 揭示了当前AI行业的一个冰冷现实:尽管大模型在各大榜单上屡创新高,但即便像GPT-5.2这样强大的模型,其真正的长程无辅助推理准确率也不到10%。 通过细粒度的错误归因和轨迹分析,为学术界和工业界指明了当前大模型在推理上的核心缺陷:早期规划能力差、多步状态遗忘、复合错误无法自我纠正以及缺乏沿着决策树回溯的能力。
提升:
这篇文章的“提升”主要体现在基准测试自身的区分度提升上。针对动辄刷榜到90%以上的现状,LongCoT成功将前沿大模型的性能压制在10%以下,创造了巨大的研究上升空间。 在子集LongCoT-mini中,成功实现了对开源模型能力的梯队划分(DeepSeek V3.2 - 证明了随着模型输出Token数量的增加(如GPT-5.2使用高达128k的推理预算),解决复杂图依赖问题的准确率确实有正向提升,为Test-Time Scaling(测试时计算扩展)提供了新的数据支撑。
不足:
评估成本极其昂贵: 由于每道题需要模型生成数万到十万以上的Token,单次API调用成本经常超过1美元,导致研究团队无法进行大规模的自洽性(Self-consistency)测试或Pass@k评估。 缺乏具体的训练解决方案: 本文是一篇纯Benchmark论文,虽然极为精准地诊断了“长程推理能力低下”的病因,但并未提出如何通过预训练或强化学习(RL)来治愈该问题的具体算法。 与现实脏数据的脱节: 为了确保答案的精确可验证性和逻辑链条的严密性,部分领域(如计算机科学的编译器Pass模拟、图算法)的问题构建得过于“干净”和理论化,可能与充满噪声的现实世界Agent任务存在一定差异。
心得:
“工具使用”掩盖了“内生推理”的虚弱: 这篇论文给我最大的震撼是它无情地撕下了当前Agent繁荣的“遮羞布”。很多时候我们以为大模型变聪明了,其实只是它学会了写Python代码把计算推给CPU,或者调用搜索引擎。一旦剥离这些外挂,让模型单纯在“大脑”(上下文)里推演一个深度的逻辑图,最强如GPT-5.2也会迅速崩溃(准确率跌破10%)。这说明追求真正的AGI,必须回归模型内生逻辑连贯性的提升。 长程错误的非线性坍塌与“状态重置”难题: 论文中有一处极高信息熵的发现:在组合任务中,大模型的准确率下降曲线远比“各步独立误差相乘”要陡峭得多。这意味着大模型在长上下文中不是“偶尔算错一步”,而是发生了灾难性的“状态遗忘”或“目标漂移”。它无法像人类一样在遇到死胡同时执行“状态弹栈(Backtracking)”。长程推理的瓶颈根本不在于Context Window的长度,而在于注意力机制对历史逻辑锚点的精准召回能力。 分治法(Divide & Conquer)在复杂图依赖前的失效: 目前业界很流行用递归Agent(如RLM框架)把长任务切碎交由不同子Agent处理。但LongCoT证明了,当任务具有高度耦合的有向无环图(DAG)属性或隐式状态机属性时,这种机械的上下文拆分会切断逻辑的血脉,导致子Agent因缺乏全局视野而在死循环中打转。这给未来的大模型系统架构提出了新的挑战:我们需要一种能够无损传递“隐式逻辑图结构”的全新上下文压缩和交互机制。
一句话总结:
本文提出了首个通过禁止外部工具调用来极限施压大模型纯粹长周期思维链(Long-Horizon CoT)能力的基准测试LongCoT,利用极其复杂的图依赖逻辑,揭示了即使是最顶级的GPT-5.2大模型在面对跨度数万Token的内生推理时,也会因规划失效和无法回溯而导致准确率跌破10%的残酷现实。
As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
https://arxiv.org/abs/2604.14140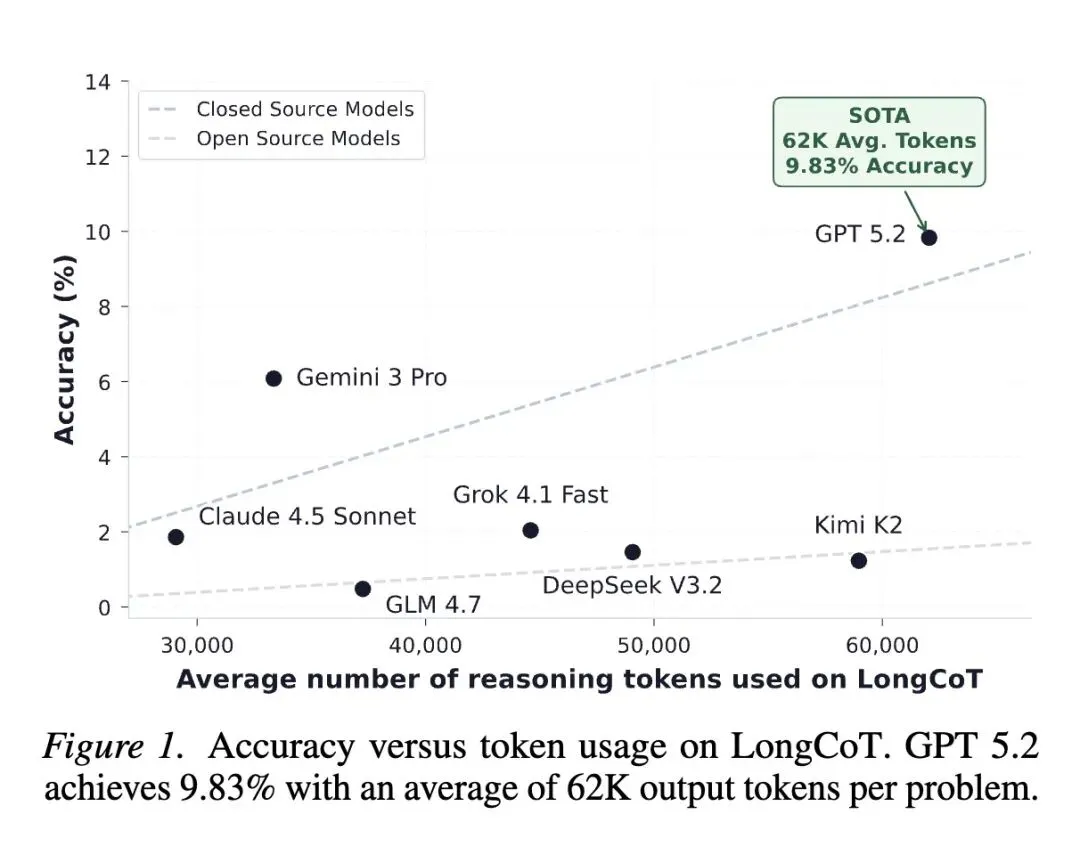

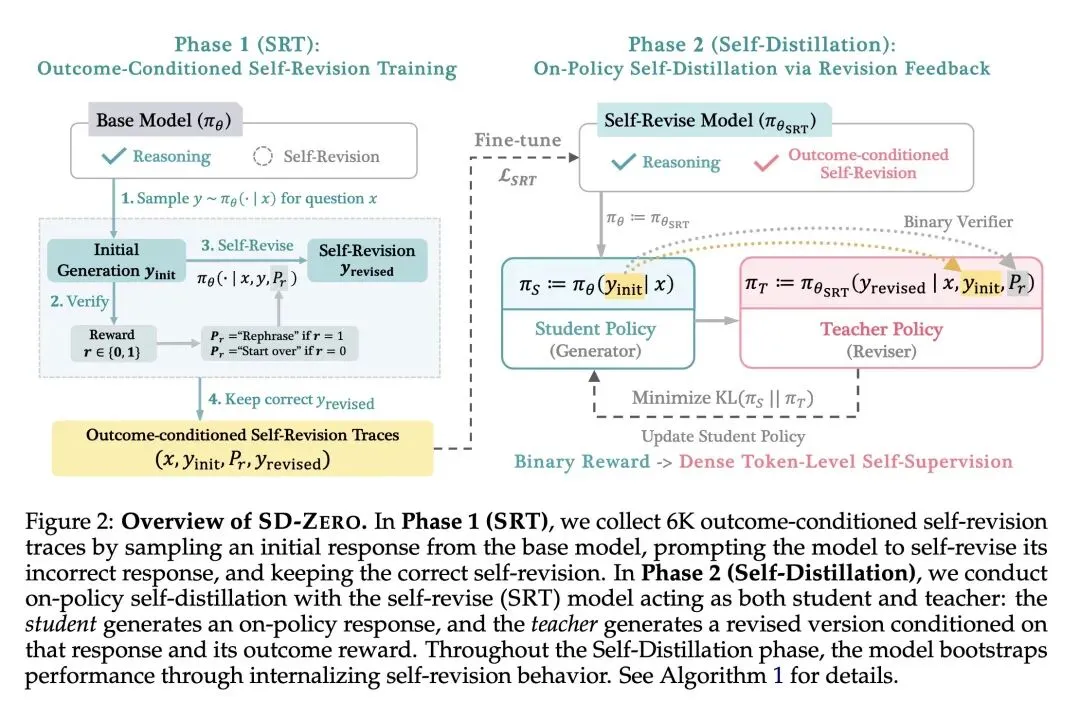
4、[CL] Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Y He, S Kaur, A Bhaskar, Y Yang…
[Princeton University]
Self-Distillation Zero:通过自我修正将二元奖励转化为稠密监督
要点:
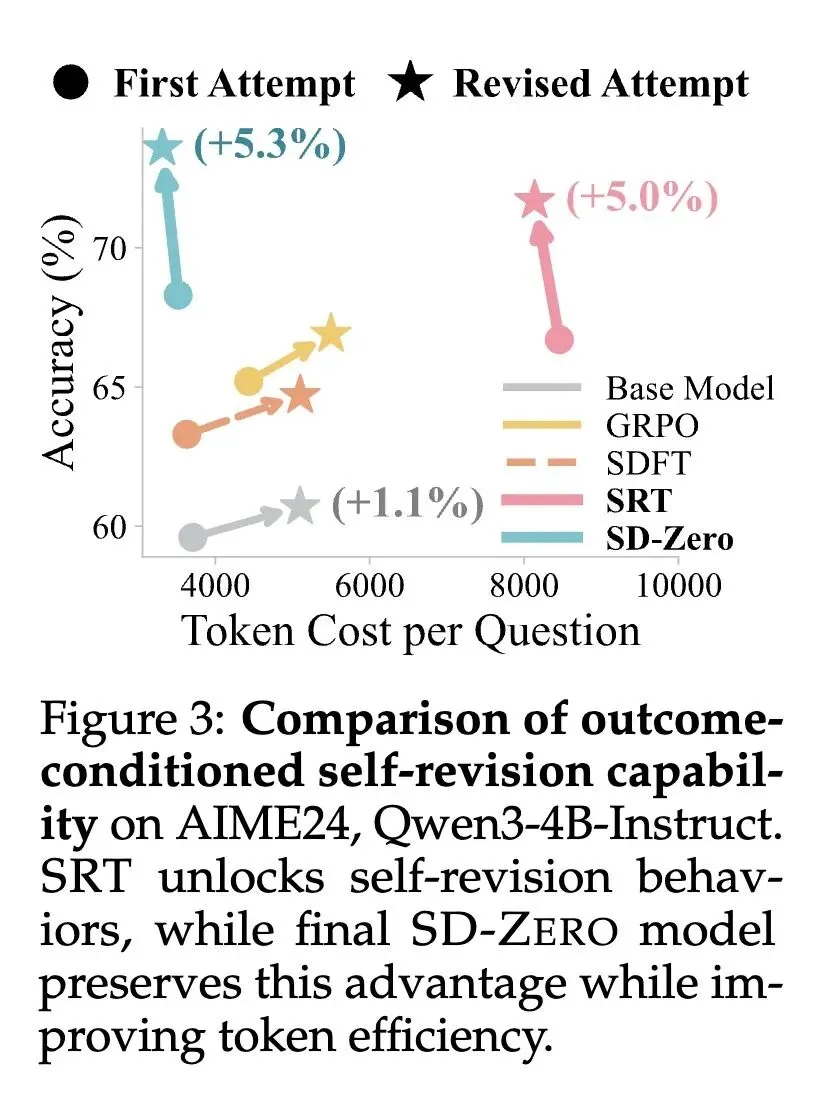
解决了LLM后训练中的两难困境:强化学习(如GRPO)由于二元奖励的稀疏性导致样本效率低,而知识蒸馏需要昂贵的外部教师或黄金演示数据。SD-ZERO仅利用二元奖励和模型自身,就实现了密集的Token级监督。 反直觉地让教师以学生的“错误”为条件:传统蒸馏只从完美轨迹中学习,而SD-ZERO的教师(Reviser)将学生不正确的尝试和二元奖励作为输入,提供有针对性的、纠错性的Token分布。 发现了“Token级自我定位(Token-level Self-localization)”现象:模型神奇地将标量0/1结果奖励转化为了密集的Token级信号。分析表明,对于错误答案,KL散度奖励会精确地在推理出现缺陷的Token处出现剧烈峰值。 揭示了从“显式纠错”到“内化引导”的转变:第一阶段(自我修订训练)使模型准确率提高,但变得冗长且犹豫(例如显式输出“等等,让我重新开始”)。第二阶段(自我蒸馏)迫使模型将此能力内化,在一开始就主动避开陷阱,将回复长度缩减了50%。 实现了迭代自我进化(Iterative Self-Evolution):由于蒸馏阶段同时也提升了模型底层的修订能力,更新后的学生在后续轮次中可以成为新的教师,使得性能可以持续扩展而不会过早遇到瓶颈。 揭示了在“思考型(Thinking)”模型上的关键局限:令人惊讶的是,将此方法应用于具有长且探索性思维链的模型时,反而会导致性能下降。因为现有的数学框架会将“富有成效的试错(富有探索性的废稿)”误判为错误并加以惩罚。
主旨: 本文提出了一种名为Self-Distillation Zero (SD-ZERO) 的后训练框架。它通过让单一模型同时扮演“生成器”和“修订器”两个角色,巧妙地将稀疏的二元奖励(对或错)转化为密集的Token级别自我监督信号,从而在不需要外部强大教师模型或高质量黄金轨迹的情况下,高效地提升语言模型的逻辑推理能力。
创新:
教师以“错误尝试”为条件的生成范式:打破了蒸馏只能“模仿正确”的常规,让冻结的教师模型接收学生生成的“错误草稿”及“错误奖励”,生成纠错的Token分布,引导学生学会“如何从当前错误中走出来”。 标量奖励到Token级密集反馈的转化机制:利用生成器和修订器在同一个错误Token处的概率分布差异(KL散度),自然地实现了错误节点的精准定位(Token-level self-localization)。 两阶段分离的训练架构:第一阶段(SRT)专门激发模型显式的反思和修订能力;第二阶段(Self-Distillation)通过策略同轨(on-policy)蒸馏,将这种纠错能力内化为第一直觉的生成能力,大幅压缩了推理长度。
贡献:
提出了一种极具样本效率的后训练方法SD-ZERO,在同等数据预算下,大幅超越了RFT、GRPO和传统SDFT等主流方法。 证明了LLM具备内在的“Token级自我定位”能力,即仅凭最终结果的对错,模型就能在分布层面上准确定位到推理链条断裂的具体词元。 验证了“迭代自我进化”的可行性:证明了通过不断同步教师模型权重(Teacher Synchronization),无需外部数据即可实现多轮次的自我提升。
提升:
准确率大幅提升:在Qwen3-4B-Instruct和Olmo-3-7B-Instruct上,在数学和代码基准测试中平均准确率分别提升了10.5%和10.4%。 训练样本效率极高:相比于需要大量Rollout的GRPO,SD-ZERO的蒸馏阶段对每个问题只需采样一次响应,总计算成本极低。 推理效率的优化:经过第二阶段蒸馏后,模型在不损失准确率(甚至更高)的前提下,将输出Token的长度缩减了约50%,生成变得极其简练和主动。
不足:
严重依赖可验证领域:目前的方法仍然需要环境能提供明确的二元奖励(如数学答案的对错、代码是否通过测试用例),难以直接推广到开放域问答或缺乏明确奖励规则的领域。 难以兼容长思维链(System 2 Thinking):作者在消融实验中发现,在开启“Thinking(长思考)”模式的模型上应用此方法会导致性能严重下降,因为模型无法在漫长的探索性思维链中区分“合理的试错探索”和“真正的逻辑致命错误”。
心得:
“名师纠错”远胜于“死记标准答案”:传统的SFT或蒸馏就像是让学生背诵标准答案,而SD-ZERO的设计极其巧妙,它让教师拿着学生做错的卷子,手把手教学生“在这一步你该怎么改”。这种基于错误轨迹的对比学习,能提供比纯粹的正向模仿丰富得多的梯度信息。 学习的最高境界是将“反思”内化为“直觉”:论文中最有趣的发现之一是两阶段行为的对比。第一阶段模型像个新手,动不动就输出“等等,我算错了,重来”;第二阶段蒸馏后,模型在潜意识里绕过了那个坑,直接输出了正确的路径,连废话都没有了。这完美契合了人类从“显式纠错(System 2)”到“直觉避坑(System 1)”的认知进化过程。 探索性思维与错误惩罚的哲学困境:论文指出该方法在“Thinking”模型上碰壁,这揭示了当前AI对齐领域的一个深刻痛点——如何定义“错”。在长思维链中,走弯路是发现真理的必经过程。如果我们用刚性的Token级别KL散度去惩罚偏离最优路径的探索,就会扼杀模型的创造力。如何数学化地包容“富有成效的废话”,是未来大模型推理研究的一座大山。
一句话总结:
SD-ZERO通过让模型自我修订其错误尝试,巧妙地将稀疏的二元对错奖励转化为极其密集的Token级纠错信号,在无需任何外部金牌数据的情况下,以极高的样本和推理效率实现了模型推理能力的大幅跨越。
Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-ZERO), a method that is substantially more training sampleefficient than RL and doesn’t require an external teacher or high-quality demonstrations. SD-ZERO trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser’s token distributions conditioned on the generator’s response and its reward as supervision. In effect, SD-ZERO trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-ZERO improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator’s response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization. SampleInefficient Sparse Supervision Dense Self-Supervision From (Incorrect) Attempts RLVR: Sparse Learning Signal SD-Zero (Ours): Sparse Reward -> Dense Learning Signal High-Quality Demonstrations Dense Supervision From High-Quality Demonstrations On-Policy Self-Distillation: Dense Learning Signal Generator Reviser Model’s Own (Incorrect) Attempt Figure 1: We introduce SD-ZERO, an on-policy self-distillation paradigm where the teacher (reviser) can condition on incorrect student (generator) attempts.
https://arxiv.org/abs/2604.12002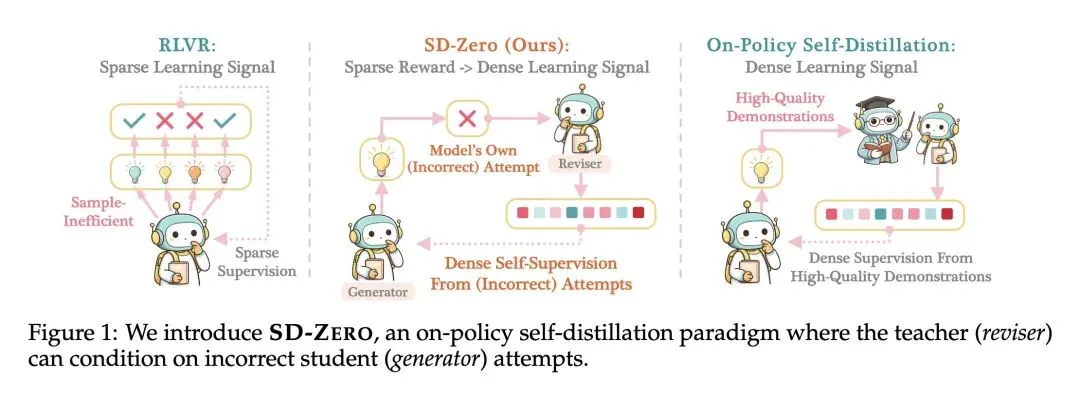
5、[CL] Toward Autonomous Long-Horizon Engineering for ML Research
G Chen, J Chen, L Chen, J Zhao…
[Renmin University of China]
迈向机器学习研究的自主化长程工程
要点:
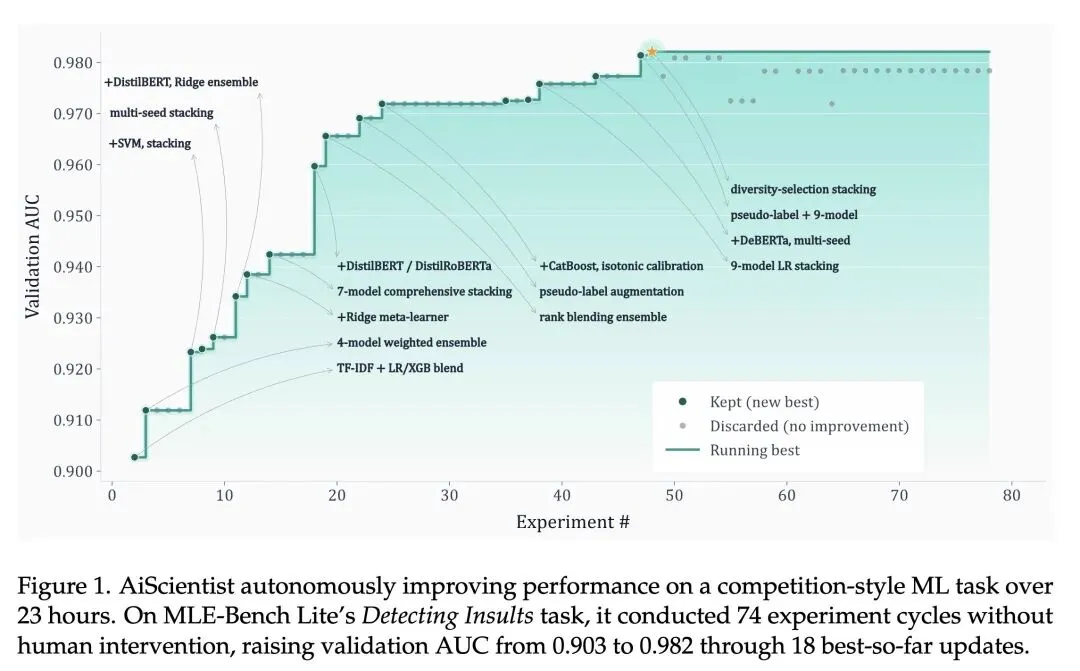
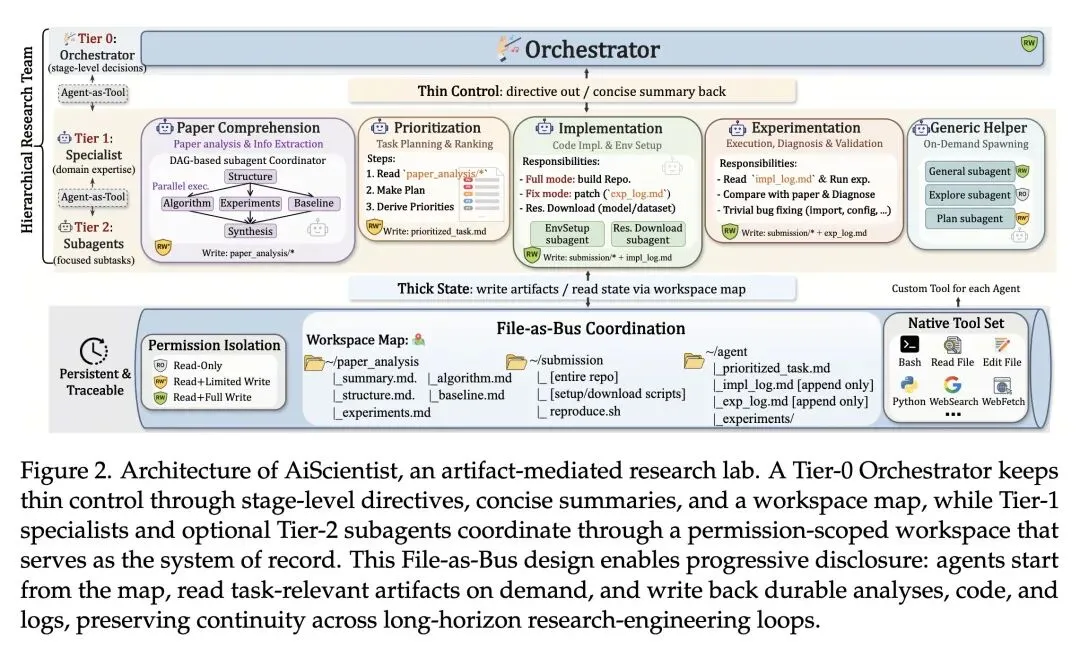
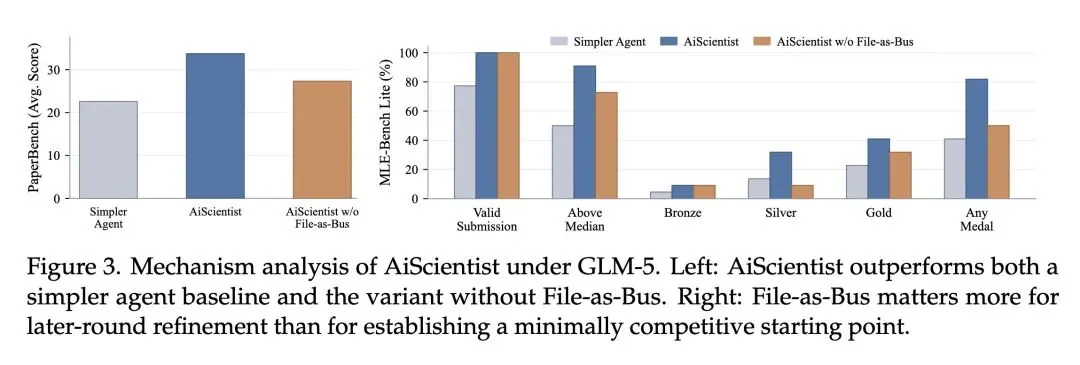
挑战了多智能体系统中“增加对话交互和推理就能带来更好结果”的普遍假设。文章证明,在长周期任务中,依赖对话式交接会导致灾难性的上下文丢失和幻觉。 提出了极其反直觉但高效的“厚状态上的薄控制(Thin Control over Thick State)”设计范式。顶层编排器(Orchestrator)不再将繁杂的项目历史塞满上下文窗口,而是仅保留紧凑的“工作区地图”和简明摘要(薄控制),实际数据则持久化在文件系统中(厚状态)。 提出了“文件即总线(File-as-Bus)”协调协议。智能体之间不通过聊天进行通信和状态保持,而是在权限隔离的共享工作区中读写持久化制品(如日志、代码、数据),将文件系统作为“单一事实来源(System of Record)”。 使用“智能体即工具(Agent-as-Tool)”机制重构了多智能体委派。专家智能体(Tier-1)被视为标准工具(如同Python执行或网页搜索),由编排器按需调用,使得任务委派变得灵活可选,而非僵化的流水线。 高信息熵发现:消融实验揭示,“文件即总线”协议对于后期的迭代优化(调试和指标提升)比对于构建初始可运行代码更加至关重要。移除该机制会导致在MLE-Bench Lite上的“任意奖牌率”暴跌31.82个百分点。 展现了巨大的效率提升:AiScientist在PaperBench上大幅击败了重度交互的基线(如IterativeAgent),同时将推理成本降低了高达77%(例如在GLM-5下,单任务成本从12.20)。 得出一个根本性结论:自主长周期机器学习研究本质上是一个系统工程问题(在持久状态上协调专业工作),而不仅仅是一个大模型局部推理问题。
主旨: 本文旨在解决机器学习研究中“自主长周期工程(Autonomous Long-Horizon Engineering)”的难题。现有的AI智能体在面对需要耗时数小时甚至数天、跨越文献理解、环境配置、代码实现、实验运行和Debug的复杂研究任务时,往往会因为上下文丢失和延迟反馈而崩溃。为此,文章提出了AiScientist系统,通过将系统控制(编排器)与项目状态(持久化文件系统)解耦,确立了“文件即总线”和“分层编排”的核心机制,从而确保智能体在漫长的研究周期中保持连贯的推进能力。
创新:
“文件即总线(File-as-Bus)”协议:摒弃了传统多智能体依赖对话历史传递上下文的脆弱方式,转而使用物理文件系统(按权限划分的目录如分析、代码、日志)作为信息总线,确保状态的持久化和可追溯。 渐进式上下文披露与薄控制(Progressive Disclosure & Thin Control):顶层编排器仅维护一个轻量级的“工作区地图(Workspace Map)”和任务摘要进行决策,避免了上下文窗口爆炸;底层专家智能体按需读取所需文件,实现了控制与状态的分离。 智能体即工具(Agent-as-Tool)集成:将复杂的专家智能体(如文献理解专家、实验专家)封装为可供编排器直接调用的工具API,实现了灵活、非强制的分层调度。
贡献:
构建了首个专注于长周期ML研究工程的端到端自主AI系统AiScientist。 从经验上证明了长周期AI任务的瓶颈不在于模型的局部推理能力,而在于系统级的“持久状态连续性(Durable State Continuity)”。 在极其困难的PaperBench(从零复现顶会论文)和MLE-Bench Lite(Kaggle式竞赛打榜)基准测试上刷新了SOTA,大幅缩小了AI智能体与人类ML博士之间的差距,同时显著降低了推理成本。
提升:
PaperBench复现能力:平均得分达到33.73分,比最强的匹配基线高出11.15分,大幅缩小了与人类博士专家(41%成功率)的差距;同时单任务成本从12.20。 MLE-Bench Lite竞赛能力:实现了81.82%的“任意奖牌获得率(Any Medal%)”,比最强的对比系统高出11.37到18.18个百分点,且在“高于中位数(Above Median)”指标上一致提升9.09个百分点。
不足:
高昂的评估成本限制了规模化测试:按照当前设定,在PaperBench上运行一次完整的20任务评估需要花费约832美元,这极大地限制了进行大规模消融实验和超参数调优的可能。 人类基准的差距依然存在:尽管取得了巨大进步,AiScientist在PaperBench上仍未完全达到人类ML专家的水平(41%),说明在处理极端模糊的规范或极具创新性的架构时,系统仍有局限。 依赖预定义的层级与角色:系统目前依赖人为定义的Tier-1专家角色(理解、规划、实现、实验)。对于某些非常规的、跨学科的研究范式,这种固化的组织结构可能缺乏足够的自适应弹性。
心得:
大模型系统设计正在向经典计算机体系结构回归:长久以来,提示工程(Prompt Engineering)试图把所有东西塞进LLM的“内存(Context Window)”里。这篇文章极具启发性地指出,AI Agent也需要“硬盘(File System)”。将临时推理(CPU/RAM)与持久化记录(Disk)剥离,是构建真正通用人工智能操作系统(AGI OS)的必由之路。 “废话少说,看代码”的极简协作哲学:传统多智能体框架(如ChatDev)喜欢让Agent互相聊天来推进任务,但这在长周期任务中会引发严重的幻觉和信息衰减。AiScientist的成功证明,“基于制品的协作(Artifact-Mediated Coordination)”远优于基于对话的协作。这与人类顶尖工程师团队的协作模式如出一辙——少开会,多通过Git Commit和文档交流。 系统工程思维 > 模型单点推理:一个70分的模型加上一个90分的系统架构,能够击败一个90分的模型加上70分的架构。这篇论文深刻表明,目前限制AI解决复杂现实问题(如持续数天的科研实验)的,不再是LLM做不出某道数学题,而是我们还没有为LLM搭建好能够“稳健承载数十次试错与回溯”的工程脚手架。
一句话总结:
AiScientist系统通过抛弃脆弱的对话式交接,独创了“文件即总线(File-as-Bus)”协议与“厚状态薄控制”的架构,证明了实现长周期自主AI科学研究的核心不在于增强大模型的单点推理,而在于如何通过优秀的系统工程维持数十次实验试错间的持久状态连续性。
Autonomous AI research has advanced rapidly, but long-horizon ML research engineering remains difficult: agents must sustain coherent progress across task comprehension, environment setup, implementation, experimentation, and debugging over hours or days. We introduce AiScientist, a system for autonomous long-horizon engineering for ML research built on a simple principle: strong long-horizon performance requires both structured orchestration and durable state continuity. To this end, AiScientist combines hierarchical orchestration with a permission-scoped File-as-Bus workspace: a top-level Orchestrator maintains stage-level control through concise summaries and a workspace map, while specialized agents repeatedly re-ground on durable artifacts such as analyses, plans, code, and experimental evidence rather than relying primarily on conversational handoffs, yielding thin control over thick state. Across two complementary benchmarks, AiScientist improves PaperBench score by 10.54 points on average over the best matched baseline and achieves 81.82 Any Medal% on MLE-Bench Lite. Ablation studies further show that File-as-Bus protocol is a key driver of performance, reducing PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points when removed. These results suggest that long-horizon ML research engineering is a systems problem of coordinating specialized work over durable project state, rather than a purely local reasoning problem.
https://arxiv.org/abs/2604.13018