 夜雨聆风
夜雨聆风一、背景
机器人智能系统分级:
system 1 :对应于快速、反应式模块,依赖习得先验产生即时响应; system 2 :更精细化的规划推理,支持结构化推理、长期规划、记忆管理以及跨长程任务的决策一致性
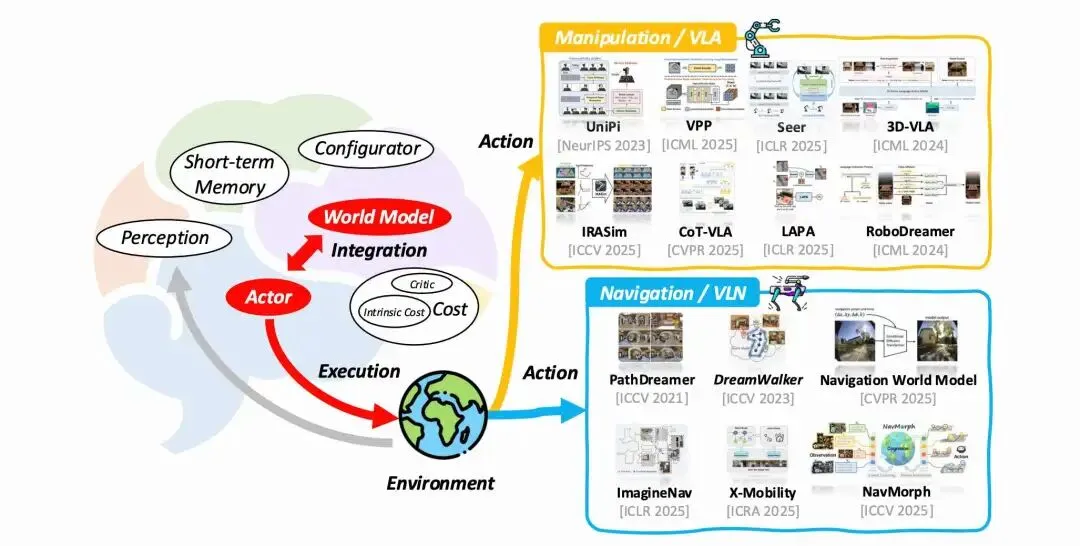
当前机器人智能系统普遍采用 Vision-Language-Action (VLA) 视觉语言执行、Vision-Language Navigation (VLN) 视觉语言导航 或 World Action Model (WAM) 世界模型+动作策略架构,这一类架构缺乏对任务状态、环境与长期记忆的显式建模,因而难以支持需要持续监控以及对于长程任务的上下文管理。
1.当前面临的问题
长时任务完成率低:VLA模型强感知但无长期记忆监控,长时任务容易崩溃。 sandbox隔离:多数Agent只在虚拟环境跑,依赖预先注册的工具包,只能调用静态预定义函数池中的功能,面对环境变化,无法自主生成解决方案,只能中止任务或请求人工干预 异构难协同:机械臂/人形/四足接口割裂,无法统一调度、任务接力。 操作权限不足:缺乏对操作系统的直接控制:无法读写文件、调用本地应用或维持持久进程,从而与物理环境脱节
2. OpenClaw的短板
OpenClaw是本地全权限运行时,拥有完整系统权限,可执行 shell 命令、控制 GUI 应用、监听事件消息,并在 WhatsApp、Telegram、iMessage 等通信平台间实现统一集成。但缺具身控制架构、无System2规划、无多机协同、无闭环反馈、日志依赖于文本信息,对视觉信息和action状态缺乏关联性,撑不起复杂机器人任务。
二、ABot-Claw设计思想
1.OpenClaw扩展到具身场景的挑战
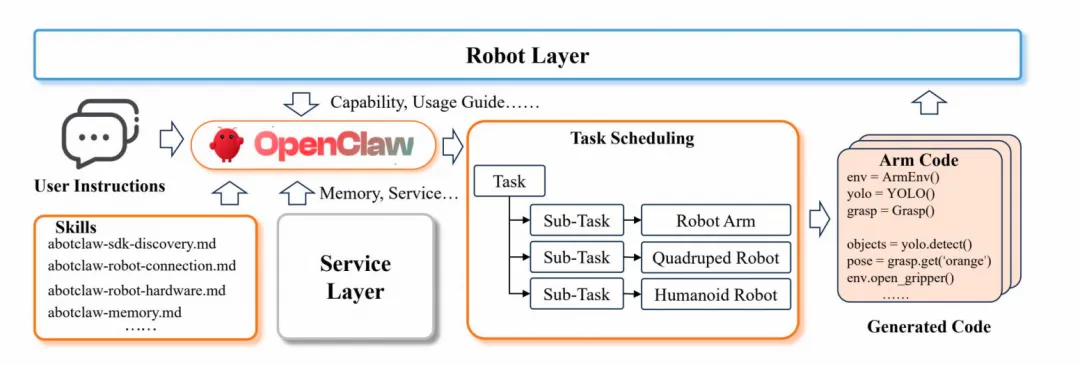
需要统一不同场景的机器人接口 必须维持持久的时空上下文,使智能体能够在长时程内定位、回忆并作用于所采集的观测信息 它必须在执行不确定性下保持鲁棒,其中open loop系统常因感知噪声、环境变化或控制漂移而失败
2、ABot-Claw架构
机器人智能系统通常集成多个异构组件,包括自然语言交互、任务规划、底层控制、感知模块、推理、记忆检索和模型服务部署。
但是当这些组件在单一运行时内紧密耦合时,会引入不清晰的模块边界,带来高昂的升级成本,限制系统可移植性,并增加单点故障风险。因此ABot-Claw采用OpenClaw层 + 共享服务层 + 机器人具身层分层解耦系统。
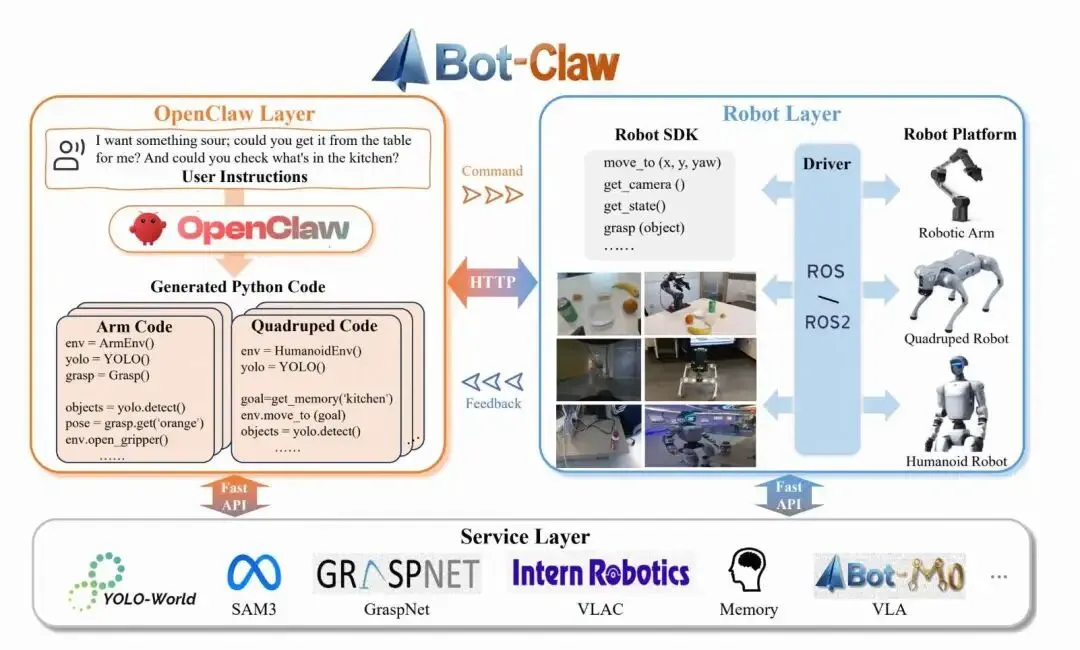
| OpenClaw层 | ||
| 共享服务层 | ||
| 机器人具身层 |
一句话总结:OpenClaw负责“任务调度路由”,服务层负责“感知和记忆”,机器人层负责“操作与执行”。
三、ABot-Claw核心模块以及协同控制过程
基于 OpenClaw 运行时,ABot-Claw 通过三大核心组件实现持久、协作且自我进化的机器人智能体
(1)异构具身集成(统一接口、能力调度、多机协作) (2)以视觉为中心的多模态记忆,实现长期、跨具身的上下文保持 (3)基于critic-based的闭环反馈机制,支持在线进度评估、局部优化与动态重规划。
三者协同,在开放、动态环境中将最上层的意图与下层的action执行闭环衔接。
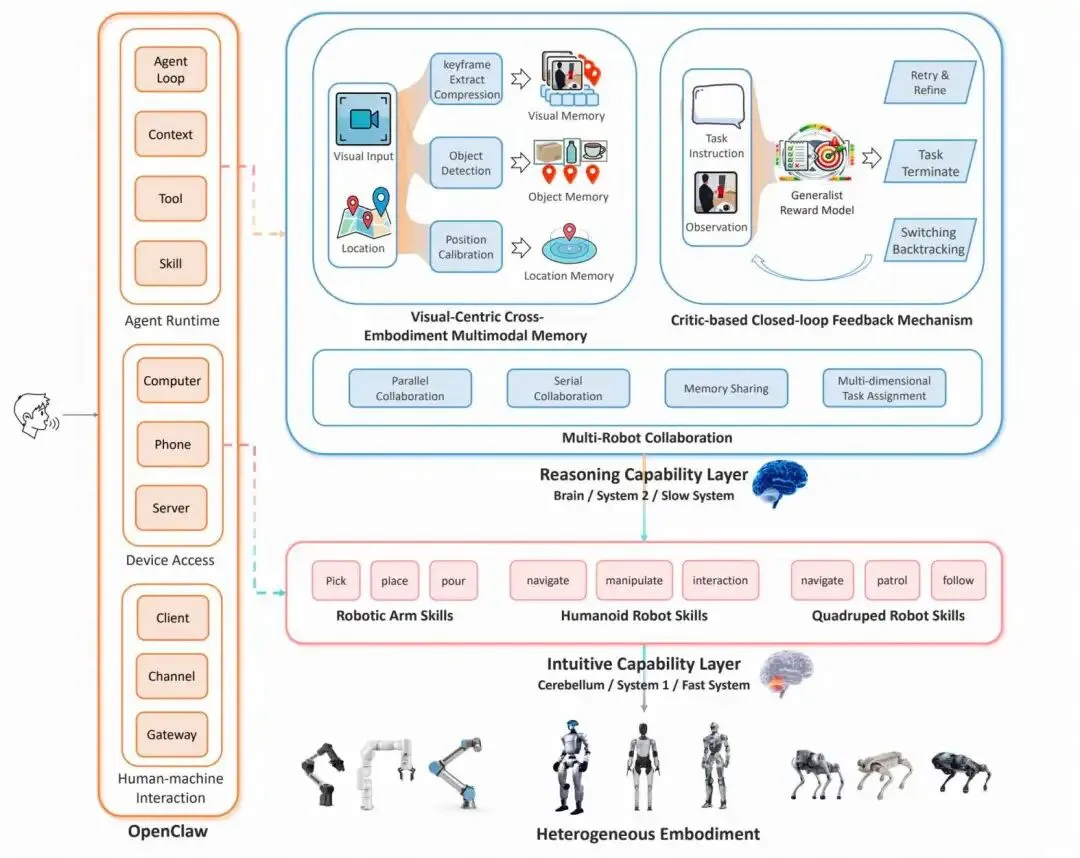
1. 统一具身接口
统一接口:用ROS适配器把不同机器人原生能力映射为导航(navigate)、观察(observe)、检查(inspect)、操作(manipulate)、交互(interact等意图级技能,上层 Agent 不感知硬件差异。 集中式运行时:维护设备池,跟踪状态、负载、位置、能力,支持并行执行、任务交接、故障转移。 智能路由:按能力匹配、位置优先、负载均衡、优先级四维度分配,实现“集中大脑、多身体接力”。
典型场景:四足取物→递给机械臂精细操作;某机器人故障,自动派另一台接替巡检。
2. 以视觉为中心的跨具身多模态记忆
彻底抛弃纯文本日志,构建可检索、可行动、跨机器人共享的视觉空间记忆,是长时任务的核心支撑。
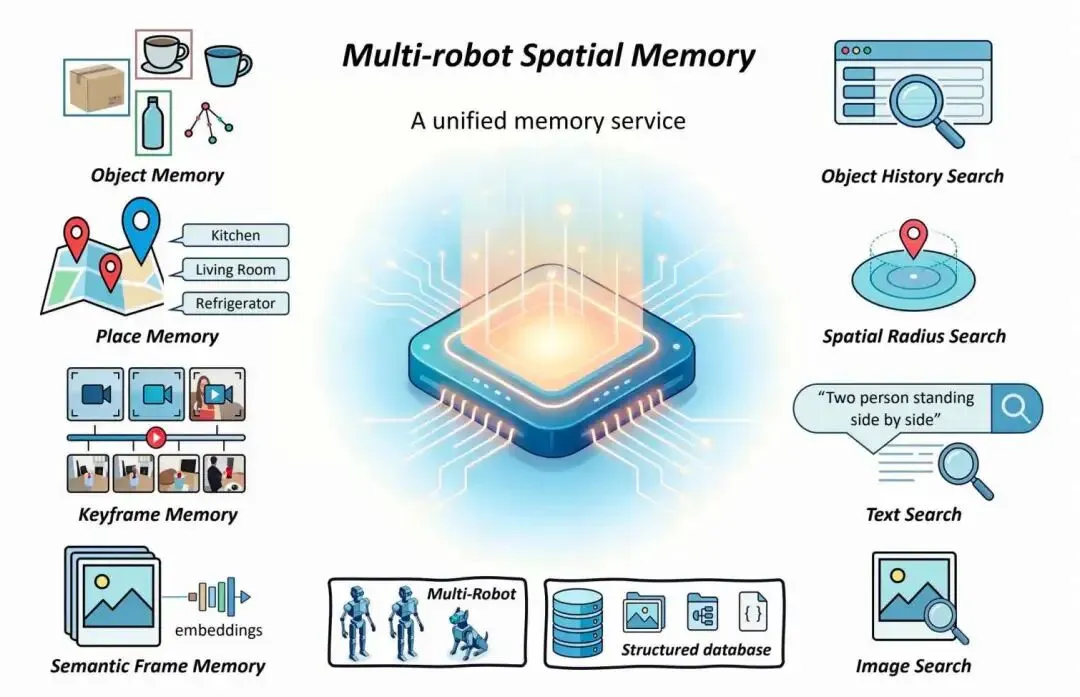
四类记忆实体
图像语义记忆:存储场景观测的高维视觉embedding,支持开放词汇跨模态检索。 关键帧记忆:稀疏但是信息量丰富的视觉快照来概括探索轨迹,用于回溯、重访、快速初始化环境。 物体记忆:锚定与后续交互相关的实体,包括类别、位姿、时间、机器人来源,支撑抓取/放置。 地点锚记忆:环境中具有语义意义的位置。通过自动注册或用户标注,语义位置(厨房/门口),离散化空间,便于语言规划。
检索机制
跨模态检索:文本+视觉embedding 结构化过滤:按物体、位置、时间、机器人筛选 混合检索:先语义匹配,再空间过滤
可导航返回协议
所有记忆输出统一格式:语义标签 + 置信度 + 视觉图 + 全局稳定 3D 位姿→ 直接喂给给导航 / 运动规划器,零解析成本
跨具身共享
机器人 A 探索 → 写入共享记忆 机器人 B 直接复用,不用重复探路
3. 基于通用奖励模型的 Critic based闭环反馈
解决“开环执行一错到底”,实现感知‑执行‑评估‑修正闭环。
通用Critic
输入指令+当前观测,输出连续进度分数,不是成功 / 失败,而是过程信号。
三层自适应决策
分数达标:子任务完成,进入下一步 分数上升但未达标:局部微调(姿态 / 视角 / 重试) 分数停滞 / 下降:重规划、查记忆、换机器人
自我进化闭环
执行轨迹 + critic得分 → 存入经验库 →反向优化后续规划与策略
4.端到端执行流程
指令落地:OpenClaw解析意图,查记忆、选机器人、拆分子任务。 记忆辅助action生成:调用技能/模型服务,用记忆定位目标,减少盲搜。 执行与评估:机器人执行,评论器实时打分,监控进度。 更新/修正/重规划:成功写回记忆;失败触发重规划或换具身。
实验结果
论文在Unitree G1人形、Unitree Go2四足、Agilex Piper机械臂上实测,覆盖四类核心任务,全自然语言指令、无预设模板。
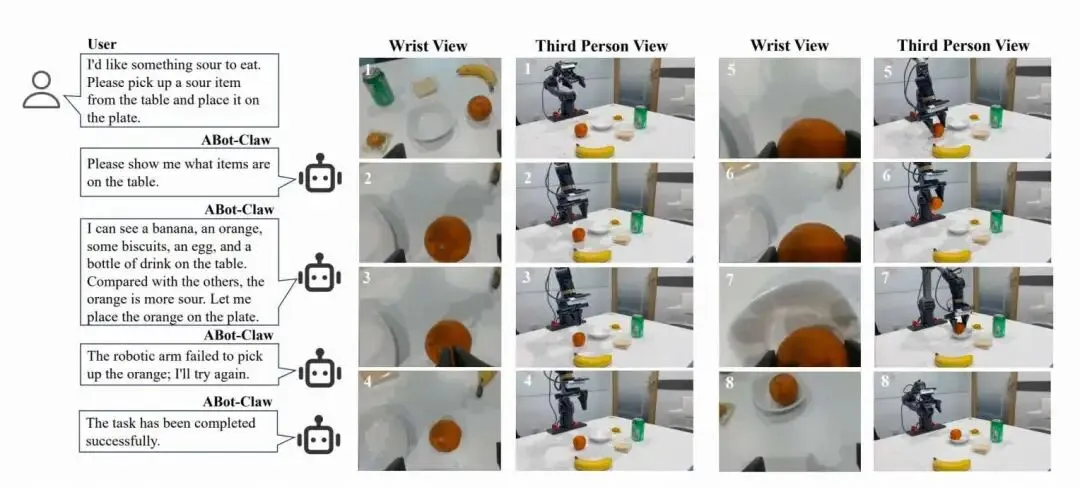
1. 机械臂:部分可观测搜索 + 模糊语义操作
桌面瓶子不在初始视野:主动询问用户→规划搜索→找到并抓取。
指令“拿酸的东西”:识别橙子→抓取放置;抓取失败自动重试。
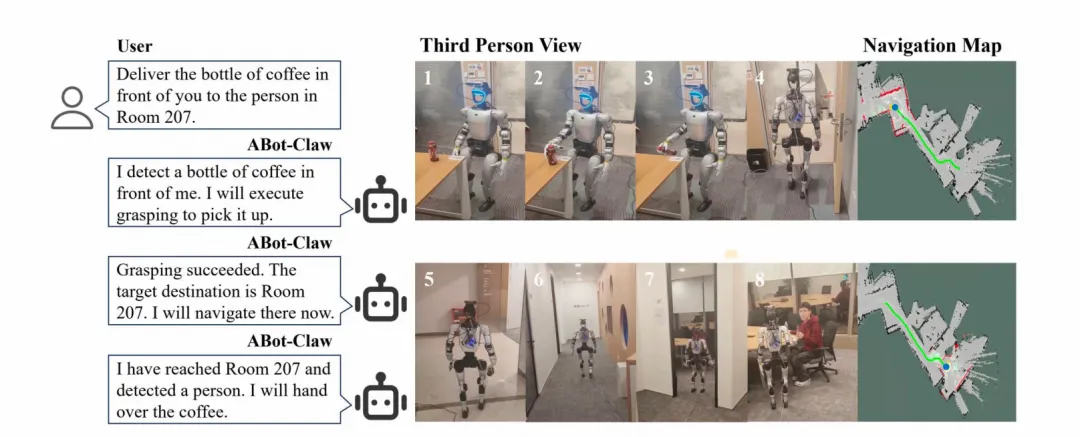
2. 人形机器人在模糊指令下的操控:移动操作递送 + 跨本体故障接替
咖啡瓶递送:抓取→导航207房间→递交给人,长链路闭环。
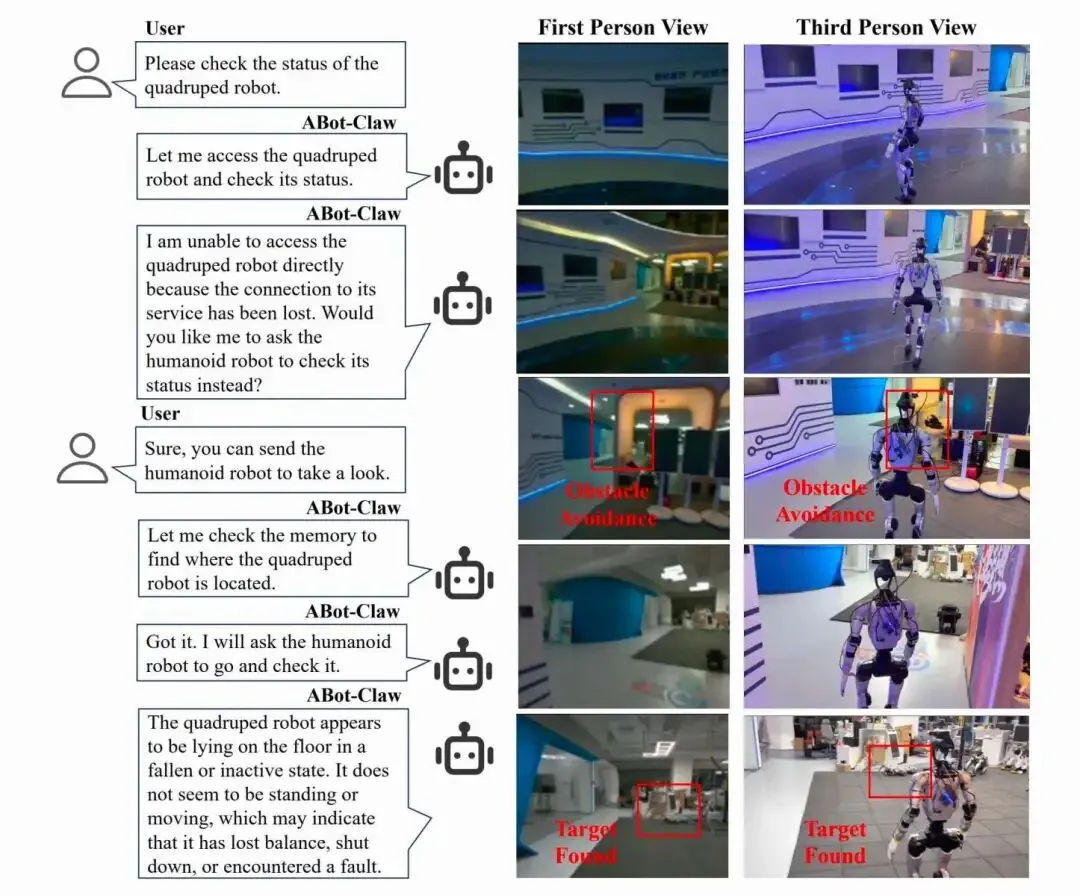
人性机器人巡检四足机器人,跨本体任务重分配
系统首先尝试直接访问该四足机器人,但服务不可用,直接通信失败。ABot-Claw 并未终止,而是查询共享内存以获取四足机器人最后已知的位置,并利用该信息重新分配任务。随后,该人形机器人被选为替代具身,被派往目标区域进行实地检查。它在环境中导航,观察四足机器人,并汇报最终状态
3. 四足机器人:访客引导接待
电梯口迎接→沿路线护送至会议室,强移动性场景验证具身选择能力。

实验证明:ABot-Claw能在动态、部分可观测、模糊指令下稳定执行,支持多机协作与故障恢复。
与传统方案对比
参考
https://arxiv.org/pdf/2604.10096 https://www.techrxiv.org/doi/pdf/10.36227/techrxiv.176531987.77979037/v1
