夜雨聆风
夜雨聆风
Trae IDE + Stata MCP深度配置:让大模型真正读懂你的数据结构 自定义Skills构建:把重复性代码工作封装成"一键指令" Vibe Regging工作流:从数据清洗到结果输出,全程AI协同
sdfd


sdfd

sdfd
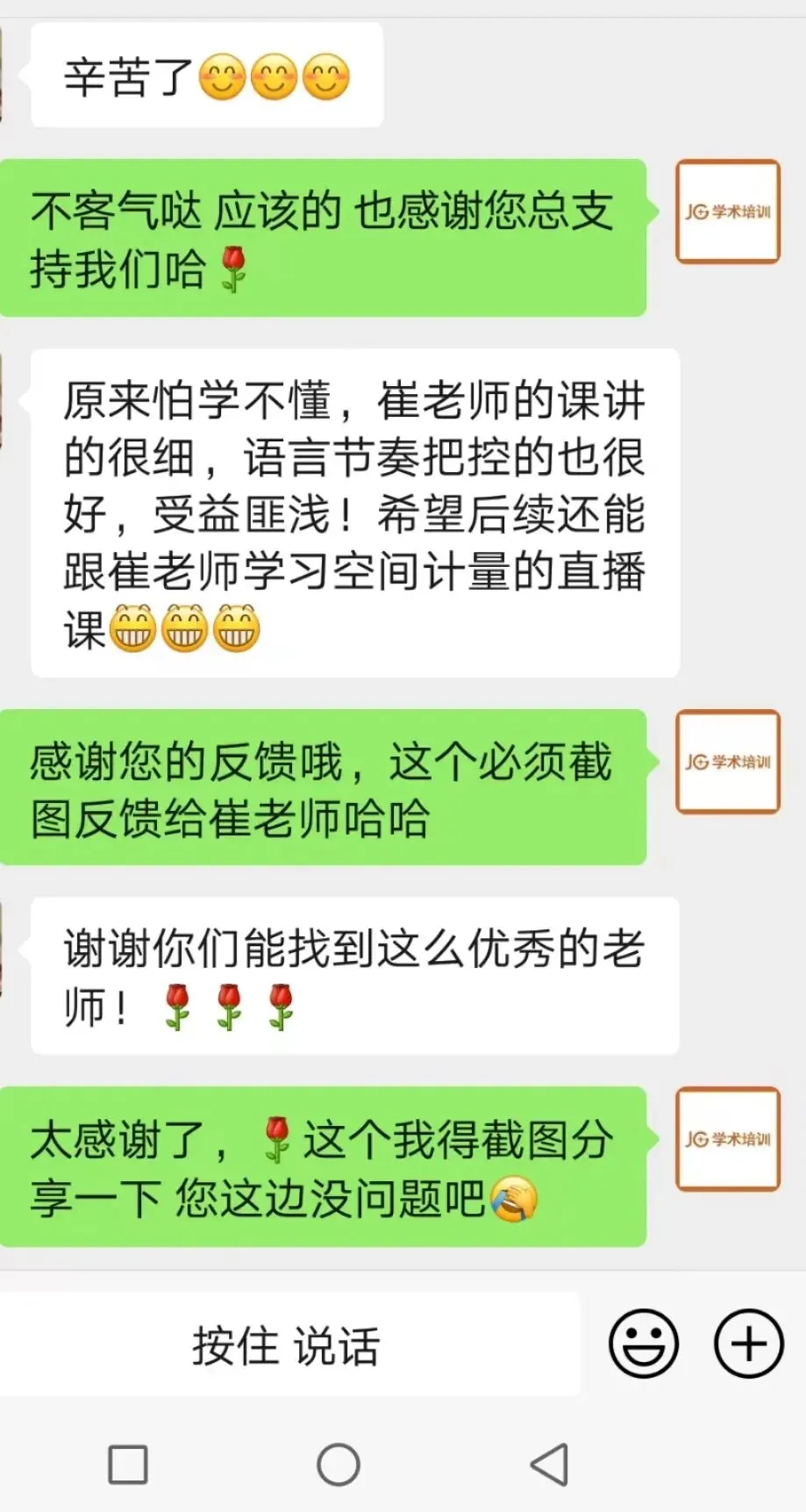
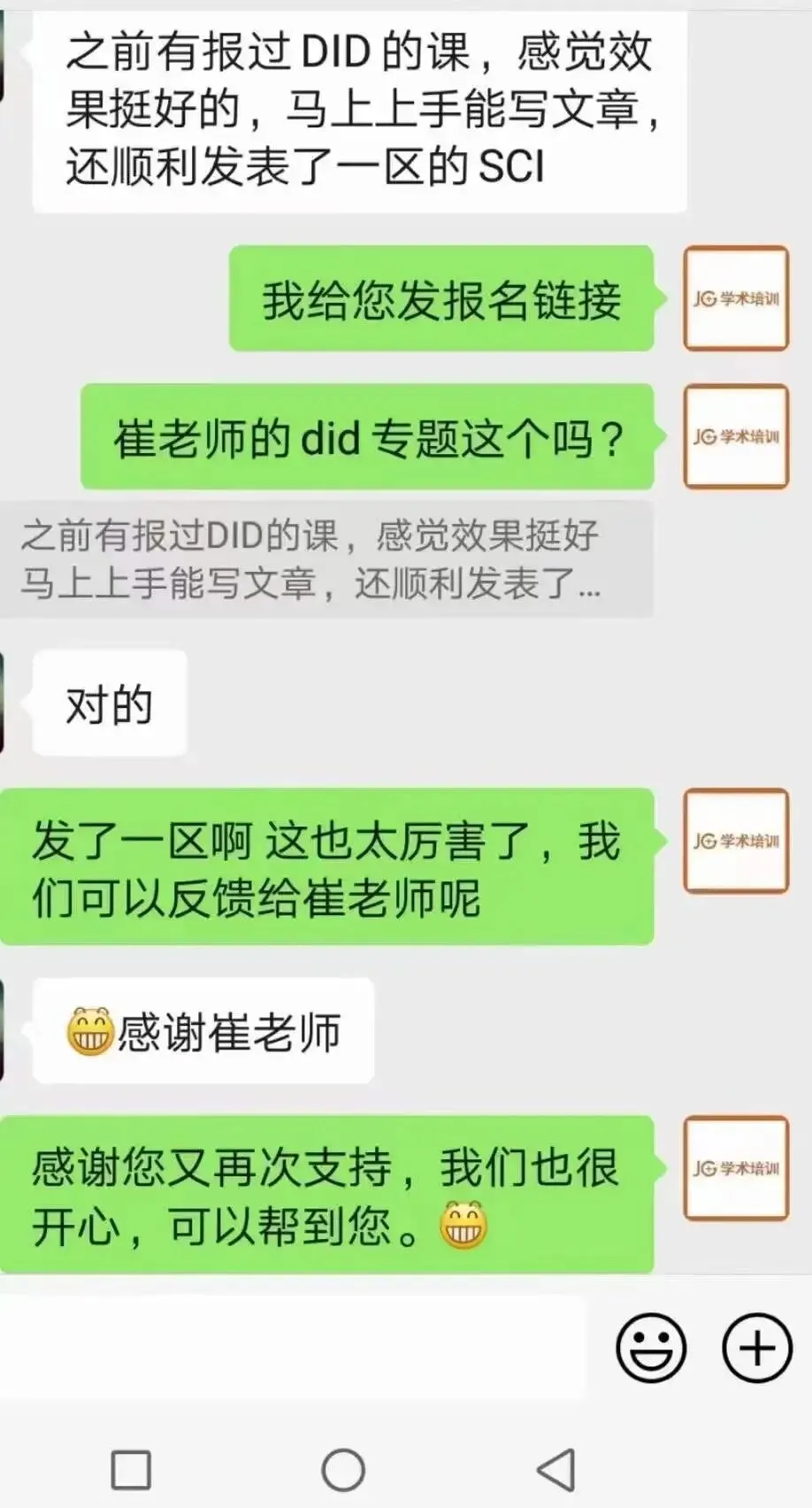
sdfd
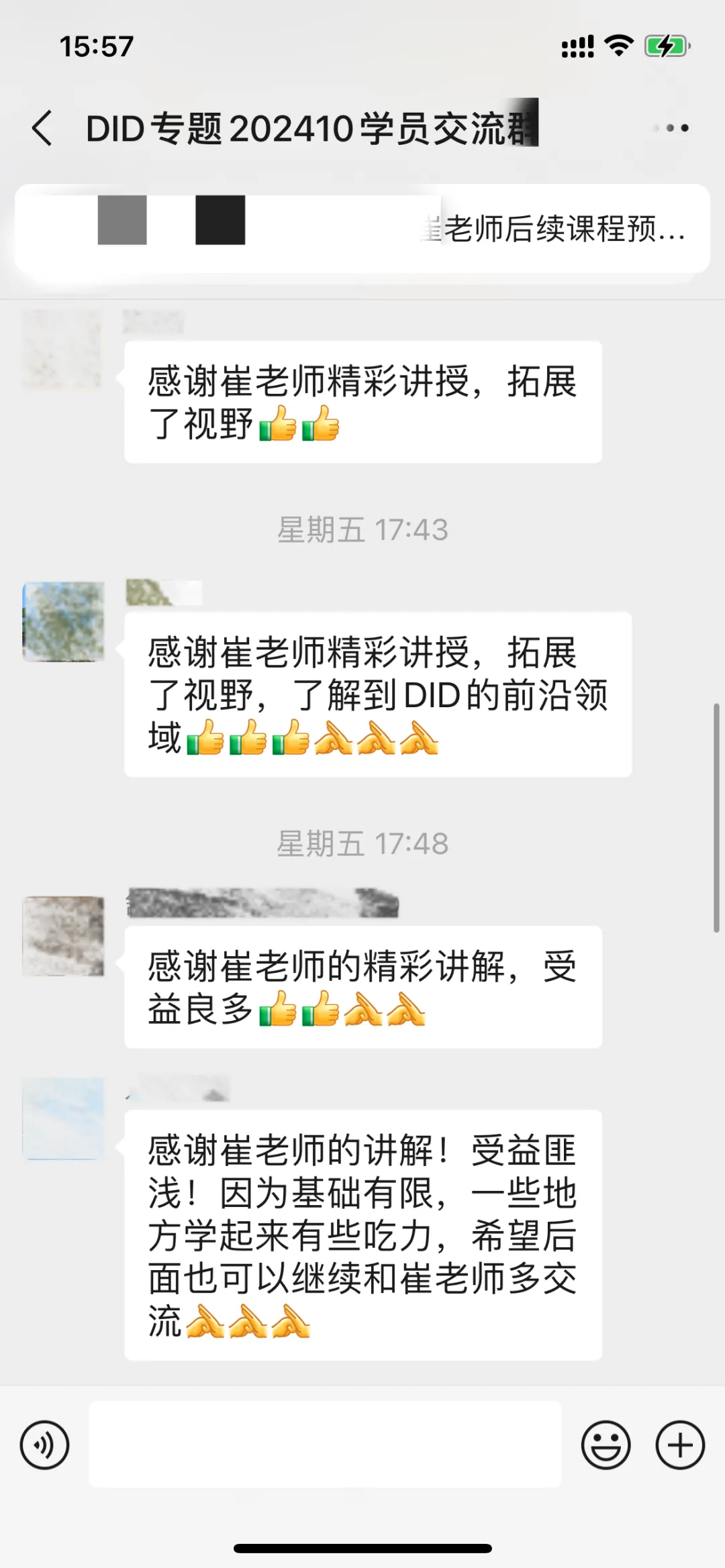
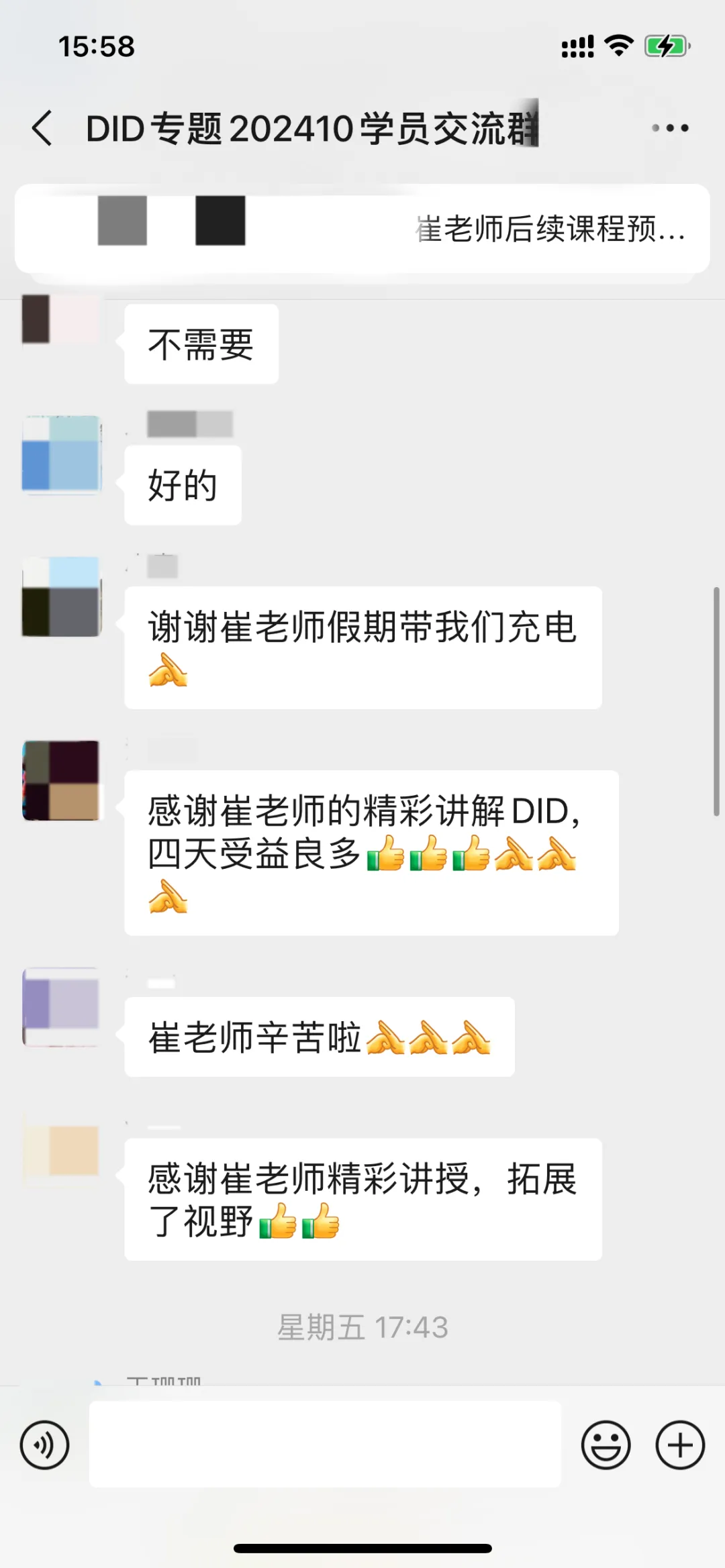
sdfd
环境搭建与深度整合:我们将从零开始,详细演示如何配置Trae IDE与Stata MCP,实现大语言模型与Stata统计软件的深度、无缝连接。这为后续所有自动化分析奠定技术基础。 从“用工具”到“建智能”:紧接着,课程将引导学员超越基础操作,学习如何设计与构建专门服务于DID研究的AI智能体(Agent)。这个智能体将能理解您的研究设计意图。 定制化技能(Skills)开发:我们将重点讲授如何为您的AI智能体构建并赋予专用的Stata skills。这些Skills如同智能体的“武器库”,使其能够自动完成从基础DID模型估计、平行趋势检验图形(如coefplot)生成、安慰剂检验(包括时间前置、组别随机化等),到前沿的Bacon分解、交叠DID多种稳健估计量(如dcdH, CS, SA, Imputation, 堆叠估计量等)的实现与结果提取等一系列复杂任务。课程资料中提及的“Vibe Regging:全自动DID实证”愿景,将在此变为可操作的实践。
基础与拓展:扎实的传统DID、多期DID、PSM-DID、空间DID。 前沿与焦点:用整整两天时间深度剖析交叠DID,包括问题来源、诊断检验(Bacon分解、负权重检验、新事件研究法)及各种稳健估计量的原理与应用(dcdH, SA, CS, Plug-in, 堆叠法、局部投影法、合成DID等)。 AI深度融合:在每一个关键环节(图形自动化、安慰剂检验、PSM匹配、交叠DID估计量实现等)均设计“AI赋能”部分,演示如何通过Trae+智能体+Skills的组合实现自动化或半自动化分析。
掌握 AI 实证工具核心操作:独立完成 Trae+Stata 软件配置,能设计 DID 研究专属 AI 智能体,实现代码自动生成、实证分析自动化,大幅提升研究效率; 构建完整的 DID 方法体系:精通传统 DID、多期 DID、空间 DID、PSM-DID 等经典模型的理论与 Stata 实现,能识别研究中的反事实错误,完成稳健性检验与异质性分析; 落地交叠 DID 前沿方法:破解 TWFE 估计偏误难题,掌握 Bacon 分解、负权重检验、非平行趋势检验等核心技巧,能熟练运用 dcdH、SA、CS 等前沿估计量,对接顶刊最新研究范式; 具备实证研究全流程能力:从研究设计、数据处理到模型选择、结果解读,能独立完成一篇高质量的 DID 实证论文,解决实际研究中的各类计量难题。