 夜雨聆风
夜雨聆风透视AI 黑盒
大模型时代的冷思考与务实之路
——中美人工智能发展格局深度复盘
深度复盘报告安泰行研中心| 人工智能行研班2026年4月
─────────────────────────────────
核心论点
❝ AI训练走的是经验路线,但文明的跃迁需要理性。中美在人工智能领域的竞争,表面上是算力与资本的博弈,本质上是两种截然不同的控制哲学与战略选择。——安泰行研中心 · 讲座核心论断
本报告基于安泰行研中心AI 行研班第二课时讲座内容整理而成,旨在对当前中美人工智能发展格局进行系统性的冷静审视。报告涵盖四个核心议题:技术溯源与Scaling Law极限、中美AI发展的资本与算力鸿沟、DeepSeek的中国式破局,以及从感知让渡到心即理回归的哲学反思。最终落脚于"守住人类认知主体地位"的战略主张。
报告结构
章节 | 核心议题 |
第一章 | 技术溯源:大模型本质与Scaling Law极限 |
第二章 | 中美分野:猎豹的爆发vs 象群的势能 |
第三章 | 破局者:DeepSeek 与中国式"暴力降本" |
第四章 | 智能体与具身智能:从"聊天助手"到"推理器" |
第五章 | 哲学反思:心即理与认知主体性的守护 |
总结 | 守住人类认知的"主体地位" |
第一章 技术溯源:大模型本质与Scaling Law极限
理解AI,首先要理解大语言模型(LLM)的本质:**LLM是基于海量历史数据预测下一个词的概率模型。** 它与传统聊天机器人有着根本的区别:
维度 | 传统聊天机器人 | 大语言模型(LLM) |
技术基础 | 基于规则/模板,依赖预定义的流程匹配 | 基于深度学习的大型神经网络,海量文本训练 |
语言理解 | 回答机械式,局限于预设模板或关键词 | 能理解复杂自然语言、语义、上下文甚至情感 |
创造力 | 无法生成超出预设内容的回答 | 能够进行创意写作、代码生成等开放性任务 |
ChatGPT成功的核心秘密,在于引入了**基于人类反馈的强化学习(RLHF)**机制,使大模型从"能说话"升级为"会说人话"。
1.1 Scaling Law 的极限与哈布斯堡诅咒
OpenAI的核心信仰是**Scaling Law(规模定律)**:模型参数量越大、训练数据越多、算力越强,模型能力就越强。然而,这一定律的极限正在显现。
OpenAI前CTO曾公开表示,"世界上的数据已经被充分利用"。当高质量人类数据耗尽,模型只能用AI生成的数据来训练新的AI时,就会陷入"哈布斯堡诅咒"——如同近亲繁殖,导致模型能力的代际退化,最终走向"认知崩溃"。
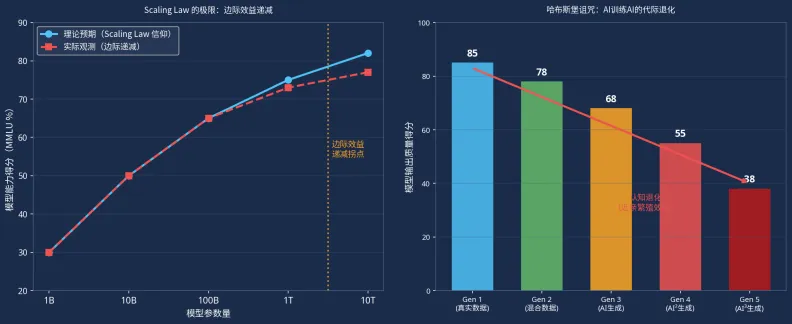
图1:Scaling Law 的极限与哈布斯堡诅咒(数据来源:讲座课件)
1.2 AI发展的五个级别
OpenAI将AI的发展分为五个层级。当前我们正处于从Level 2(推理器)向Level 3(智能体)过渡的关键阶段。
层级 | 名称 | 特征描述 | 现状 |
Level 1 | 聊天助手(Chatbots) | 具备自然对话能力 | ✅ 已实现 |
Level 2 | 推理器(Reasoners) | 达到人类水平的问题解决能力 | ⚡ 部分实现(o1/o3) |
Level 3 | 智能体(Agents) | 能够自主执行复杂任务 | ��当前阶段 |
Level 4 | 创新者(Innovators) | 能够辅助发明创造 | ��未来目标 |
Level 5 | 组织者(Organizations) | 能够完成组织级别的工作 | ��远期愿景 |
─────────────────────────────────
第二章 中美分野:猎豹的爆发vs 象群的势能
美国如同猎豹,爆发力强,追求极致速度与颠覆性创新,执着于突破参数极限以实现通用人工智能(AGI)。中国则如象群,转身稍慢,但步步为营,势能不可挡,目标是将AI融入全球最完整的硬件供应链,实现产业赋能。
维度 | 美国 | 中国 |
战略目标 | 实现AGI,追求从0到1的颠覆性创新 | 产业赋能,追求从1到100的规模化效能 |
驱动力 | 市场导向+ 风险投资(VC) | 政策引导+ 国家基金 |
监管哲学 | "事后追责"与"行业自律",保护创新活力 | "事前审批"与"强监管",大模型需经"备案" |
模型策略 | 闭源为主(GPT-4、Claude、Gemini) | 开源为主(DeepSeek、通义千问) |
核心优势 | 原创算法+ 高端芯片 + 顶尖人才 | 数据规模+ 工程落地 + 供应链完整 |
2.1 资本鸿沟:12倍的私人投资差距
在资本层面,中美展现出截然不同的驱动模式。美国由私人资本驱动,拥有47家AI独角兽,Google和Meta等头部公司单季AI投入高达250亿美元。相比之下,中国私人资本投入仅为美国的十二分之一——**美国私人投资总额1091亿美元 vs 中国93亿美元**。
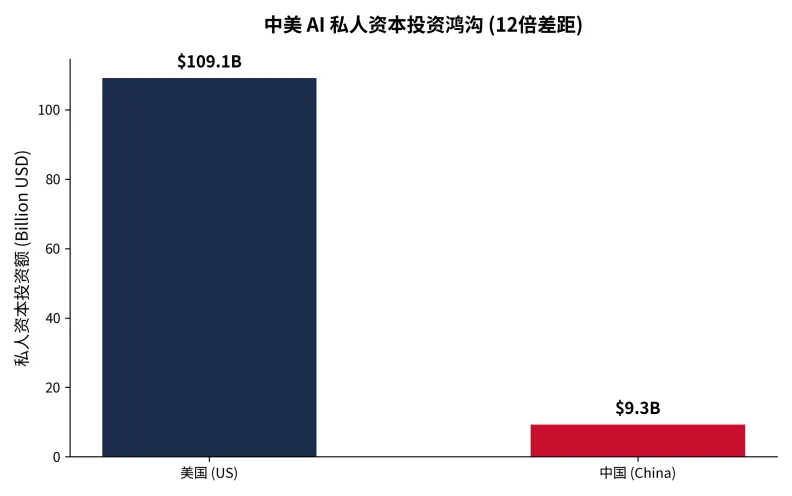
图2:中美 AI 私人资本投资鸿沟(数据来源:2024 中期记分卡)
面对巨大的私人资本鸿沟,中国必须走"举国体制",依赖国家大基金三期(475亿美元)来弥补私人资本的不足。美国的风险投资文化允许大量失败,从失败中迭代出颠覆性创新;而中国的国家引导资金则更注重确定性和产业落地。
2.2 算力困境:戴着镣铐跳舞
在硬件算力方面,美国占据了全球74%的高端算力,而中国仅占14%。出口管制切断了高端芯片供应,使得中国在算力基础设施上面临严峻挑战。
更令人担忧的是"效率惩罚"问题。由于性能折损、互联瓶颈与生态系统成熟度差异,中国在达到同等算力时,需要投入约**3倍的硬件资源**。具体而言,美国使用10万片NVIDIA B200芯片即可达到的算力,中国需要约30万片国产等效芯片。
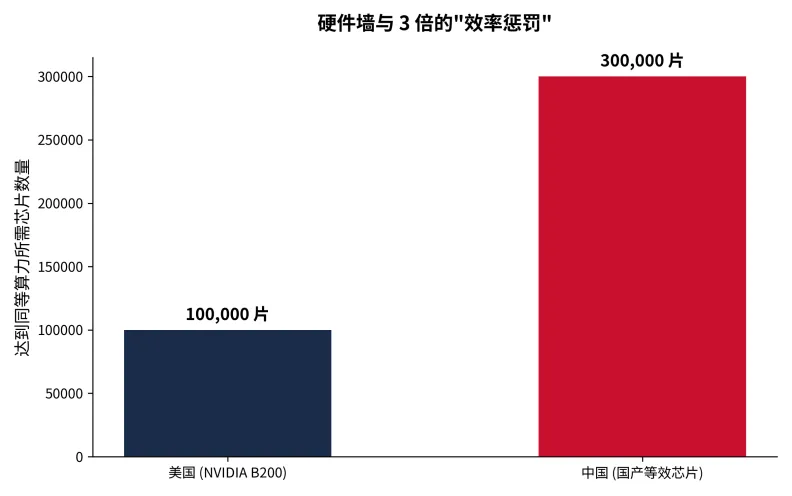
图3:硬件效率惩罚——3倍的算力代价(数据来源:讲座关键指标)
2.3 能源瓶颈:AI发展的终极制约
除了算力,电力正在成为AI发展的另一道"天花板"。单次AI搜索查询耗能约为2.9 Wh,是传统Google搜索(0.3 Wh)的**10倍**。讲座预判:2024-2025年为"算力瓶颈"期,预计2028年左右,全球将全面进入"能源瓶颈"期。届时,能源效率将成为AI竞争的核心变量。
────────────────────────────────
第三章 破局者:DeepSeek 与中国式"暴力降本"
❝ 如果ChatGPT刷新了我们对AI的认知,那么DeepSeek在某种程度上颠覆了美国人对中国AI水平的认知。当前大模型研发成本骤降:不一定需要10万卡和上亿美元的投入。——课件原文
3.1 技术路线:算法巧劲绕过"大力出奇迹"
DeepSeek的核心技术创新体现在三个层面:
【混合专家架构(MoE)】DeepSeek V3采用671B参数的MoE架构,但每次推理只激活其中约37B的参数。这种"按需激活"的机制,大幅降低了推理成本。
【多头潜在注意力(MLA)】通过创新的注意力机制,DeepSeek显著降低了推理时的KV Cache内存占用,使得在有限硬件上运行大模型成为可能。
【强化学习(RL)推理优化】DeepSeek R1通过纯强化学习训练推理能力,无需大量人工标注数据,模型自主学会了"慢思考"——在回答复杂问题时,通过链式思维(Chain-of-Thought)逐步推理。
3.2 成本革命:数字说话
DeepSeek的成本数据,是对"大力出奇迹"信仰的一次有力冲击:
指标 | DeepSeek V3 | GPT-4o | Claude-3.5-Sonnet | 倍数差距 |
参数量 | 671B | 175B(估算) | 175B(估算) | — |
训练成本 | <$600万 | ~$1亿 | ~$5亿 | GPT-4o的1/20 |
推理价格(/百万Token) | $0.48 | $18 | $18 | GPT-4o的1/40 |
质量指数(MMLU) | 80 | 82 | 75 | 接近持平 |
**训练成本不到600万美元,是GPT-4o的1/20;推理价格降至GPT-4o的1/40。** 这组数字不仅打破了"训练大模型必须烧钱"的神话,更引发了全球AI产业的深刻反思:Scaling Law的边际效益是否正在递减?算法优化是否可以部分替代算力堆砌?
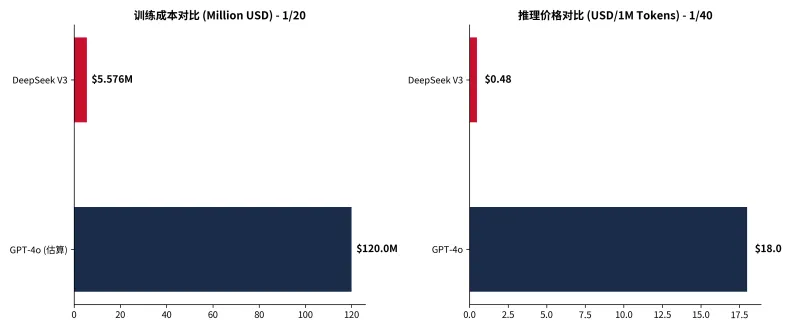
图4:DeepSeek V3 vs GPT-4o 成本对比(数据来源:DeepSeek官方技术报告)
3.3 开源涟漪:解构"闭源算力霸权"
DeepSeek最具战略意义的决策,是将所有模型全部开源。这一举措产生了四重涟漪效应:
【效应一:刺穿溢价壁垒】迫使全球算力军备竞赛从"堆砌算力"转向"优化算法提升效率",Meta、XAI等公司被迫加速开源布局。
【效应二:打破闭源垄断】开源也有好模型的事实得到证明,迫使OpenAI、谷歌等闭源公司重新审视其商业策略,ChatGPT已宣布部分降价。
【效应三:赋能云厂商】DeepSeek提供API服务,使云厂商可以自行部署,利好国内各云服务、芯片厂商,加速国产AI生态的形成。
【效应四:全球南方布局】借助"一带一路",中国正在向中东、东南亚和非洲出口基于DeepSeek的本地化AI解决方案,打破西方市场的绝对统辖。
─────────────────────────────────
第四章 智能体与具身智能:从"聊天助手"到"推理器"
4.1 智能体(Agent):AI的"手脚"
如果说大语言模型是AI的"大脑",那么智能体(Agent)就是赋予AI"手脚"的关键技术。智能体能够自主执行复杂任务,调用外部工具(如搜索、代码执行、文件操作),并根据反馈动态调整行动策略。
目前最成功的代码智能体是Anthropic的Claude Code(Claw Code),它凝结了数千名工程师的编程经验,在软件开发任务上展现出令人印象深刻的能力。华人背景的智能体公司Manus,上线仅10个月ARR(年度经常性收入)即达到1亿美元,随后被Meta收购,成为中国AI应用层能力的有力佐证。
4.2 具身智能:从虚拟到实体的最后一跳
具身智能(Embodied AI)是指将AI的感知、推理和决策能力与物理实体(机器人)相结合,使其能够在真实世界中自主行动。从基座模型到智能体,再到具身智能,是迈向通用人工智能(AGI)的关键路径。
目前,全球七八成人形机器人公司在中国,这与中国完整的制造业供应链密切相关。然而,讲座也指出,具身机器人离真正的"自主做事"还相当遥远。讲座团队的目标是今年年底前推出自己的机器人,设计思路是"先做大脑,再做小脑"——先解决感知与决策问题,再解决运动控制问题。
4.3 快思考 vs 慢思考:两种模型范式的对决
CoT链式思维的出现,将大模型分为两类:
维度 | 概率预测(快速反应,如ChatGPT 4o) | 链式推理(慢速思考,如OpenAI o1) |
性能表现 | 响应迅速,算力成本低 | 慢速思考,算力成本高 |
运算原理 | 基于概率预测,通过大量数据给出快速预测可能的答案 | 基于链式思维(CoT),逐步推理问题的每个步骤来到达答案 |
决策能力 | 依赖预设算法和规则进行决策 | 能够自主分析情况,实时做出决策 |
创造力 | 局限于模式识别和优化,缺乏真正的创新能力 | 能够生成新的创意和解决方案,具身创新能力 |
─────────────────────────────────
第五章 哲学反思:心即理与认知主体性的守护
❝ 从哲学角度看,目前基于经验训练AI模型的范式很难达到AGI,因为机器缺乏理性,对世界的认识是片面和有限的。——讲座金句
5.1 认知的让渡:MIT实验的警示
MIT的神经科学实验为我们提供了一个令人警醒的数据点:过度依赖AI辅助思考会导致前额叶连接度降低,**83%的学生甚至无法引用自己"写"的内容**。这种"外包思考"不仅是技能的退化,更是认知主权的实质性让渡。
这一现象在教育领域尤为突出。浙江K12已开设AI课程,但如何教学、以及高中和大学应提供何种教育,仍是悬而未决的问题。更令人担忧的是,很多AI公司已经开始直接从高中招人,跳过了大学教育体系。长远来看,仅有工程能力是不够的——缺乏创新能力,在范式变迁时必然掉队。
5.2 西方哲学的镜鉴:理性 vs 经验的千年之争
理解当前AI的局限,需要回溯18世纪欧洲哲学的核心争论:
【莱布尼茨(理性主义)】认为真正的知识来自理性,通过逻辑推演可以认识世界的本质。这对应于AI中的"符号主义"路线——用逻辑规则和知识图谱来表达智能。
【休谟(经验主义)】认为知识来自经验和感官,人类的认识是对感官印象的归纳和总结。这对应于AI中的"连接主义"路线——用神经网络从海量数据中学习模式。
【康德(批判哲学)】试图调和理性与经验,认为"认识始于经验,但知识来自理性"。
当前的大语言模型,走的是彻底的"休谟路线"——基于海量数据的经验归纳,通过概率预测生成输出。它们所做的是概率模式匹配,是模拟而非思考,并非真正的智能。从哲学角度看,这种范式很难达到AGI,因为机器缺乏理性,对世界的认识是片面和有限的。
5.3 东方哲学的智慧:心即理的回归
东方哲学同样对这一问题有深刻的洞察:
【儒家】"内圣外王"——内在的道德修养是外在事功的根本,强调人的主体性与内在价值。
【佛家】《金刚经》中"应无所住而生其心",禅宗认为世界是内心的投影,强调心的主体地位。
【道家】"道法自然",强调人对世界理解的重要性,人是认识世界的主体。
【王阳明心学】"良知乃是天理照明灵觉处,故良知即是天理,心即理"——世界的规律和真相,取决于人的内心的理解与体悟。
东西方哲学在这一点上高度一致:**人有区别于自然的灵性,这是机器所不具备的。** 当前的机器仍在做概率匹配,Claude Code之所以效果不错,是因为它凝结了几千名工程师的经验——但这是人类智慧的结晶,而非机器自主的创造。
5.4 感知让渡的边界:哪些可以,哪些不能
基于上述分析,我们可以划定一条清晰的"让渡边界":
能力类型 | 可让渡给AI(工具) | 必须由人类守护(主权) |
感知层 | 数据采集、图像识别、语音转写、信息检索 | — |
认知层 | — | 价值判断、战略决策、创意生成、道德推理 |
执行层 | 重复性任务、标准化流程、7×24运营 | — |
创新层 | — | 范式突破、跨界融合、人文关怀 |
引入AI的终极价值,并非简单的降本增效或替代人力,而是"**数字化资产的沉淀**"。AI能够提供7×24小时的绝对运营稳定性,无需情绪管理,且边际成本不断递减。未来的智能化软件范式,必将是"规则驱动(符号主义)+ 概率模型(连接主义)"的深度融合。
─────────────────────────────────
总结与战略建议:在时代洪流中做清醒的掌舵者
石器、青铜、铁器、蒸汽、电力、互联网、AI——每次技术革新都给社会带来巨大的冲击和机遇。当下成功出圈的案例,如黑神话悟空、DeepSeek、哪吒,成功的路径各不相同且不具备可复制性,但有两个共性:**志存高远、坚信不疑**。
从AGI角度看,我们距离真正登顶还有很长的路(Level 2/5),需要有长远的战略眼光,提前布局。DeepSeek/Qwen等开源模型为中国AI的崛起吹起号角,围绕其构建全球范围内人工智能生态正在逐渐形成规模效应。
对安泰校友的三项战略建议
【建议一:拥抱工具,守护认知】积极将AI融入业务流程,提升感知层和执行层的效率;但在战略决策、价值判断和创意生成等核心认知活动中,坚持人类的主导地位。警惕"认知让渡"的陷阱,培养团队的批判性思维和创新能力。
【建议二:关注应用,而非模型】对于大多数企业而言,自研基础模型既不必要也不现实。真正的机会在于将AI能力与行业深度结合,尤其是中国制造业在供应链、产业数据和产品上的独特优势。AI + 制造,是中国企业最具竞争力的赛道之一。
【建议三:坚持长期主义,警惕泡沫】AI是一个需要20-30年发展的长期行业,虽处于早期,但发展可能存在泡沫且会破裂。投资部门需关注AI是否为泡沫以及泡沫何时破裂等问题,企业应坚持长期主义,避免追风口式的短期投机,在泡沫破裂后仍能保持核心竞争力。
────────────────────────────────
结语:致安泰校友
❝ 智能时代下,创新意识和能力是人才培养重中之重,了解、掌握、熟练使用当下最前沿的AI工具是每个人的"必修课"。需要研究大语言模型吗?需要。但是我们更应该持续探索崭新的真正的AI范式。——讲座结语
在这个充满不确定性的时代,愿安泰校友们既能拥抱技术的变革,又能坚守理性的底线。让我们共同探索AI与产业深度融合的务实之路,在时代的洪流中,做清醒的掌舵者。
目前团队正在努力推出自己的机器人,目标是今年年底前完成,设计先做大脑,再做小脑。这是一个将学术探索与产业落地相结合的实践,也是对"守住认知主体性"这一理念的身体力行。
安泰行研中心2026年4月
