 夜雨聆风
夜雨聆风第2篇|OpenClaw深度解析:一只"小龙虾"如何成为你的AI数字员工

2026年1月,一个开源项目在GitHub上以近乎垂直的曲线飙升,两周内突破18万星,成为AI Agent领域有史以来增长最快的开源项目之一。
它叫OpenClaw。
但大多数人对它的了解,还停留在"一个可以部署在本地的AI助手"这个层面。
这篇文章,我们要深入它的架构、能力和设计哲学,真正搞清楚:OpenClaw到底是什么,它能做什么,以及它为什么重要。
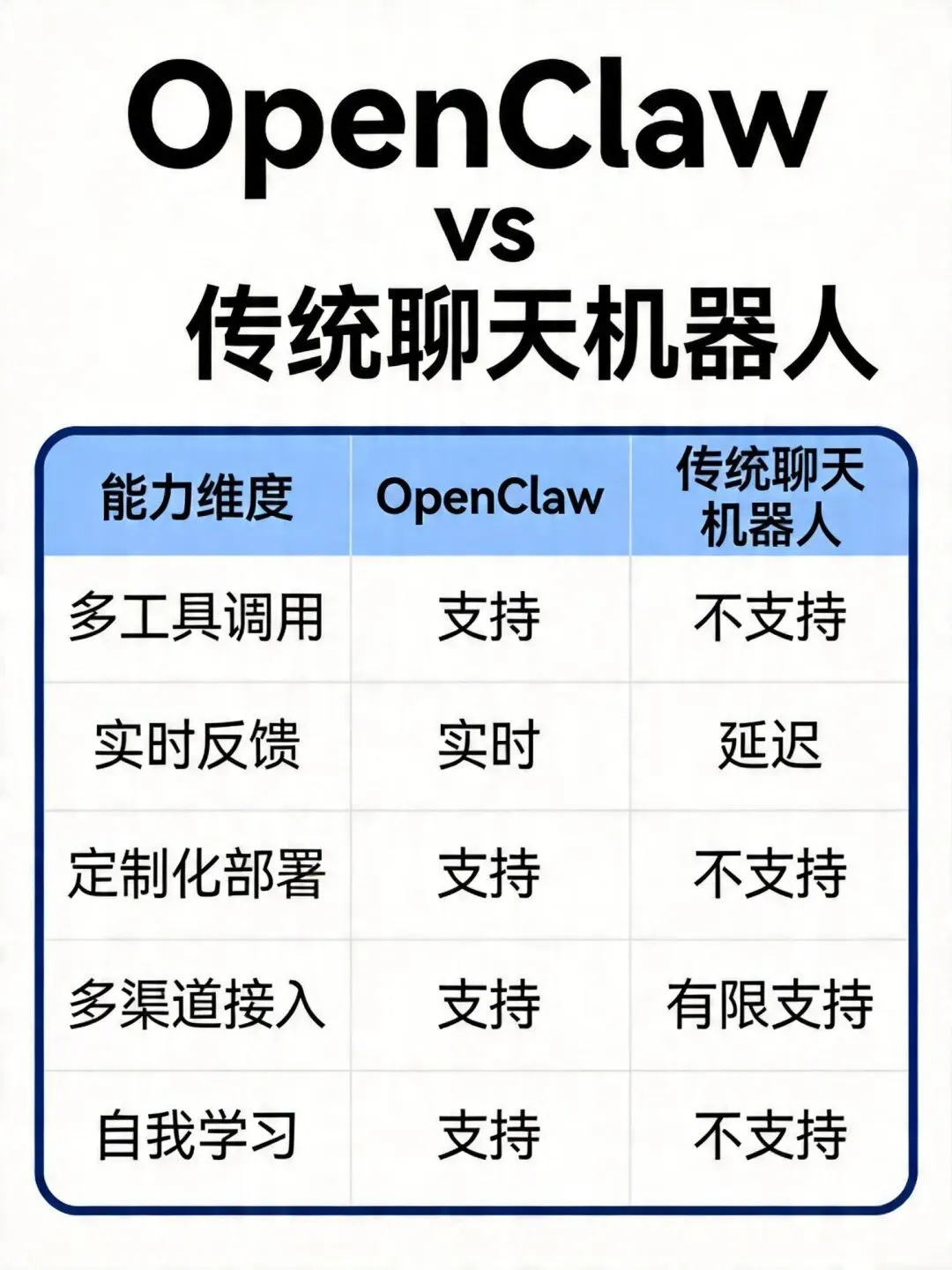
一、OpenClaw的本质:不是聊天机器人,是执行引擎
要理解OpenClaw,必须先打破一个认知定势:它不是ChatGPT的本地版本。
ChatGPT和大多数AI助手的工作模式是:输入→输出。你问,它答,交互在对话框里完成,不触碰任何外部系统。
OpenClaw的工作模式是:指令→执行→反馈。
它接收你的自然语言指令,调用真实的工具和系统,完成实际的任务,然后把结果告诉你。
这个区别,就是"聊天机器人"和"AI Agent"的本质差异。
用一个比喻:ChatGPT是一个博学的顾问,你问他问题,他给你建议。OpenClaw是一个能干的助理,你交代任务,他去执行,然后汇报结果。
二、核心架构:四层设计
OpenClaw的架构可以分为四个层次:
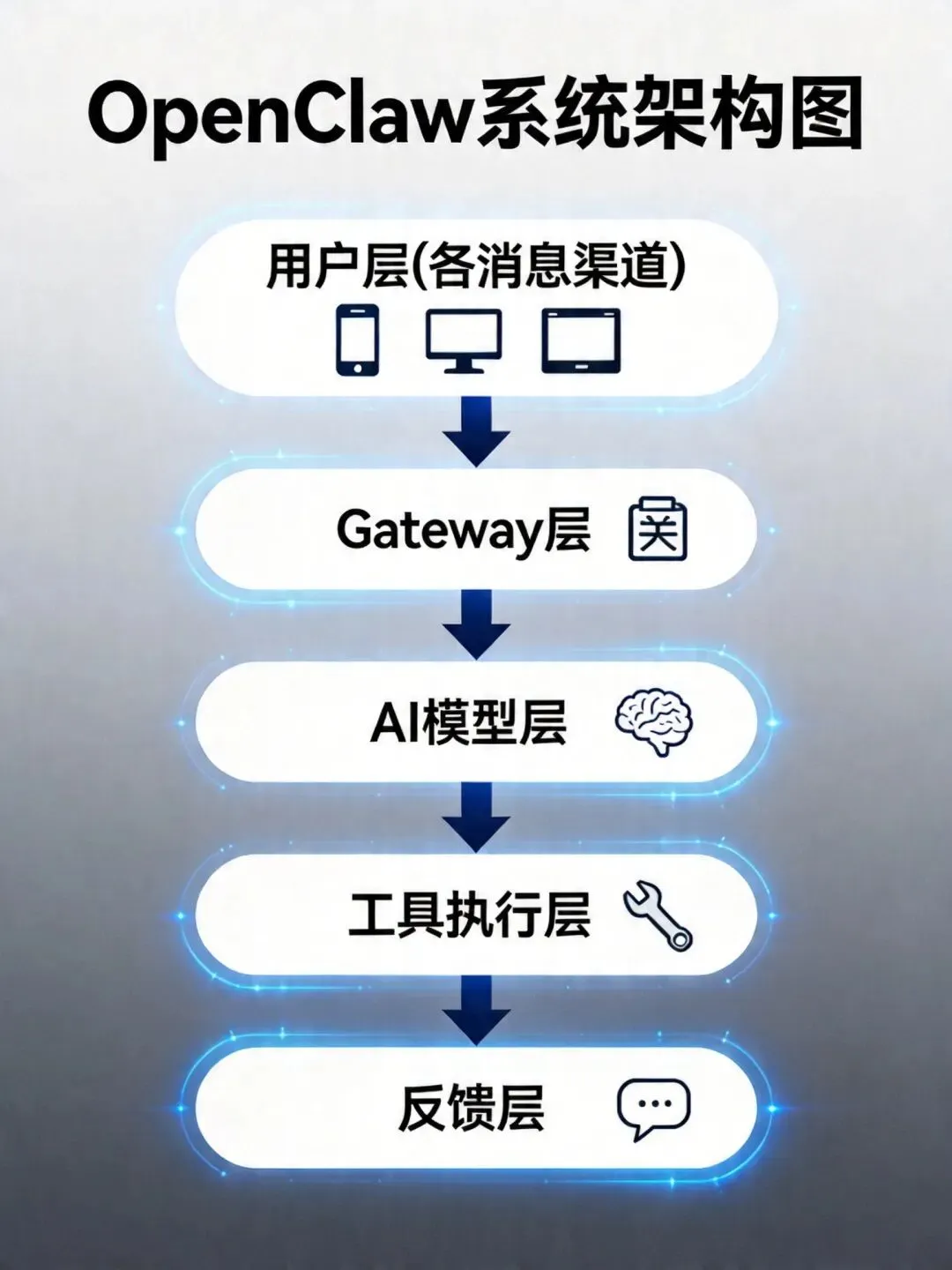
第一层:渠道层(Channel Layer)
这是用户与OpenClaw交互的入口。OpenClaw支持几乎所有主流的即时通讯平台:
• 微信(通过企业微信或个人微信接入)
• 飞书
• Telegram
• Discord
• Slack
• 以及Web界面
这意味着你不需要打开任何专门的应用,直接在你日常使用的聊天工具里发消息,就能控制OpenClaw。
第二层:Gateway层(网关层)
Gateway是OpenClaw的核心调度中枢。它负责:
• 接收来自各渠道的消息
• 解析用户意图
• 调度合适的AI模型
• 管理会话上下文
• 路由工具调用请求
Gateway运行在你的本地设备或服务器上,是整个系统的"大脑"。
第三层:模型层(Model Layer)
OpenClaw本身不绑定任何特定的AI模型,它是一个模型无关的平台。你可以接入:
• OpenAI(GPT系列)
• Anthropic(Claude系列)
• 通义千问(Qwen)
• KIMI
• 本地模型(通过Ollama等)
这种设计让你可以根据任务类型、成本预算、隐私需求灵活选择模型。
第四层:工具执行层(Tool Execution Layer)
这是OpenClaw最核心的差异化能力所在。工具执行层包含了所有让AI能够"真正干活"的能力:
• 文件系统工具:读取、写入、移动、删除文件,整理目录结构
• Shell执行工具:运行任意命令行指令,调用系统工具
• 浏览器控制工具:通过Playwright控制浏览器,实现网页自动化
• 网络请求工具:调用外部API,获取实时数据
• 定时任务工具:设置Cron任务,实现周期性自动化
• 记忆工具:读写持久化记忆文件,跨会话保持上下文
三、Skill机制:OpenClaw的"技能包"系统
如果说上面的工具层是OpenClaw的"手脚",那么Skill机制就是它的"专业技能"。
Skill是OpenClaw的插件系统,每个Skill是一个专门针对特定任务场景的执行流程包。
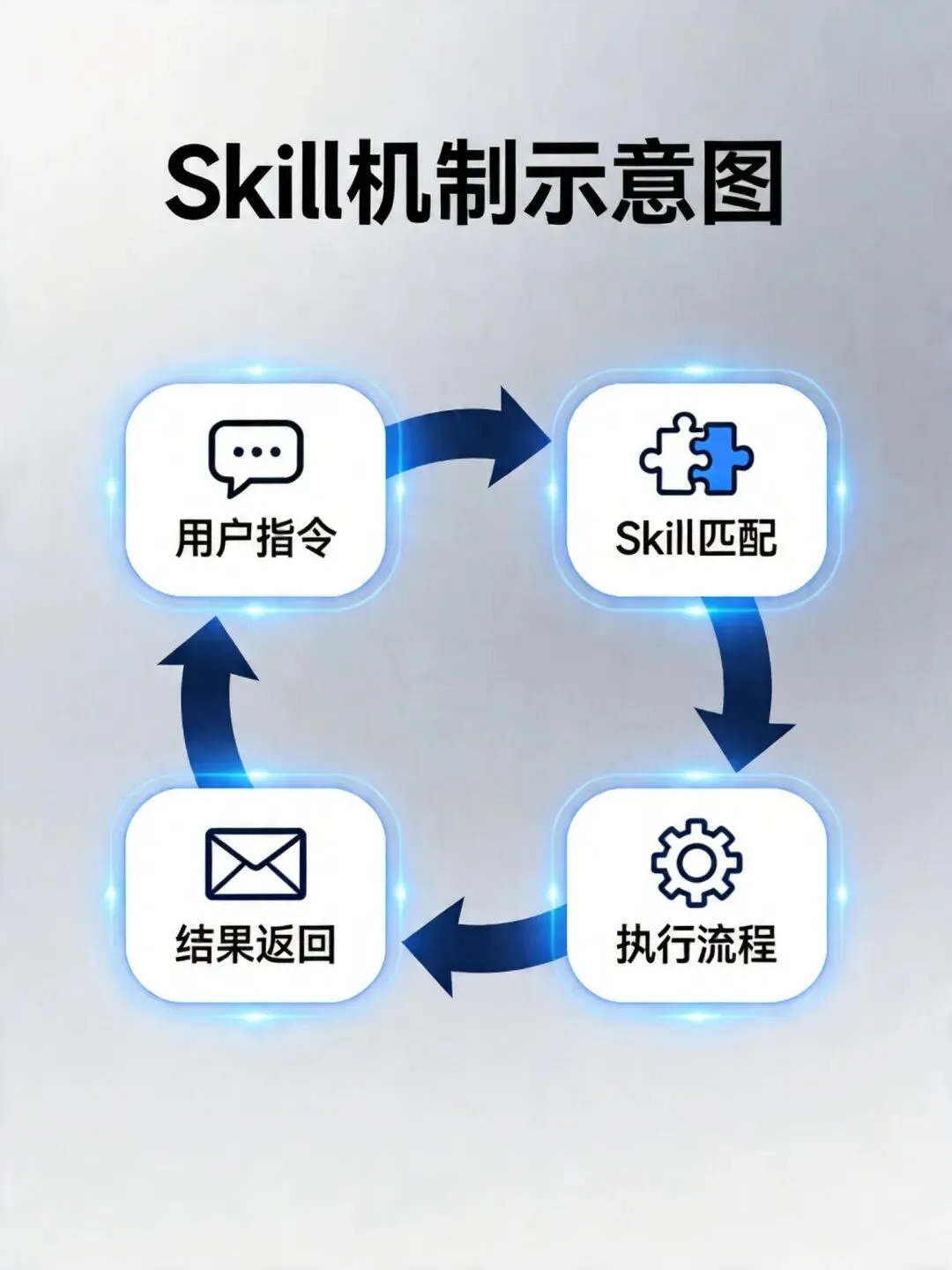
举几个例子:
• 天气查询Skill:当你问"今天北京天气怎么样",Skill会自动调用天气API,格式化返回结果,甚至给出穿衣建议。
• 邮件处理Skill:当你说"帮我看看有没有重要邮件",Skill会通过IMAP连接你的邮箱,筛选未读邮件,按重要程度排序后汇报给你。
• 文件整理Skill:当你说"帮我整理一下桌面",Skill会扫描桌面文件,按类型分类,移动到对应文件夹,并生成操作日志。
• Excel处理Skill:当你发来一个Excel文件说"帮我分析一下销售数据",Skill会读取文件,执行数据分析,生成图表,返回结论。
Skill机制的精妙之处在于:它把复杂的多步骤任务封装成一个可复用的流程,让AI不需要每次都从零开始"想"怎么做,而是直接走预定义的可靠路径。
这,正是Harness Engineering思想的直接体现。
四、持久化记忆:让AI真正"认识"你
OpenClaw最被低估的能力之一,是它的记忆系统。
大多数AI助手是无状态的——每次对话都是全新开始,它不记得你上次说了什么,不知道你的偏好,不了解你的工作背景。
OpenClaw通过文件系统实现了持久化记忆:
• MEMORY.md:长期记忆文件,存储你的偏好、重要决策、个人背景
• 每日日记文件:记录每天发生的事情,形成时间线
• SOUL.md / USER.md:定义AI的性格和对用户的了解
这套记忆系统让OpenClaw能够真正"认识"你——它知道你叫什么,知道你的工作习惯,知道你上次交代的任务进展到哪里了。
这不是噱头,这是AI从"工具"进化为"助理"的关键一步。
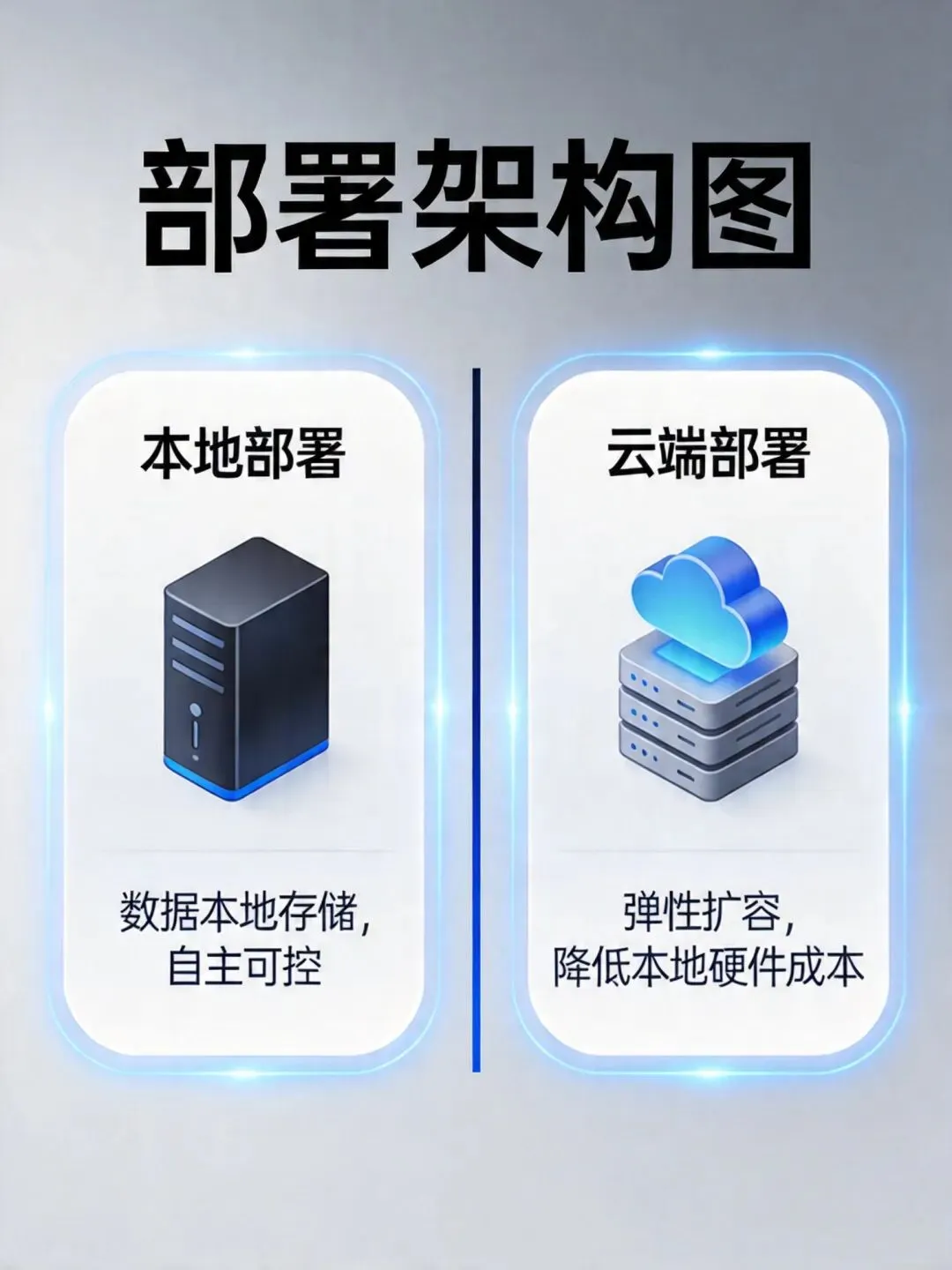
五、本地部署:数据主权的回归
OpenClaw的另一个核心价值主张是:你的数据,只在你的设备上。
在云端AI服务大行其道的今天,这个选择显得格外珍贵。
当你使用云端AI服务时,你的对话内容、文件内容、个人信息都会上传到服务商的服务器。你不知道这些数据被如何存储、如何使用、是否被用于训练模型。
OpenClaw的本地部署模式彻底解决了这个问题:
• Gateway运行在你的本地设备
• 文件操作在本地执行
• 记忆文件存储在本地
• 只有发送给AI模型的请求会经过网络(而且你可以选择本地模型完全断网运行)
对于处理敏感信息的个人用户和企业用户来说,这是一个不可忽视的优势。
六、OpenClaw的局限性:它不是万能的
诚实地说,OpenClaw也有它的局限:
• 学习曲线:相比直接使用ChatGPT,OpenClaw的部署和配置需要一定的技术基础。虽然已经有了很多一键部署方案,但对完全不懂技术的用户来说仍有门槛。
• 模型依赖:OpenClaw本身不包含AI模型,你需要自己配置API Key或本地模型。模型的能力上限决定了OpenClaw的能力上限。
• 高权限的双刃剑:OpenClaw拥有执行Shell命令、读写文件的高权限,这意味着如果AI判断出错,可能造成不可逆的操作。这也是为什么Harness Engineering如此重要——你需要给这匹"快马"套上合适的缰绳。
七、小结:OpenClaw代表的方向
OpenClaw的爆红,不只是一个开源项目的成功,它代表的是一种新的AI使用范式的崛起:
• 从"问答式AI"到"执行式AI"
• 从"云端托管"到"本地自主"
• 从"无状态对话"到"持久化记忆"
• 从"单一模型"到"工具+模型的系统"
这个方向,正是Harness Engineering所描述的未来:AI不再是一个你去"访问"的服务,而是一个在你的环境里持续运行、替你干活的智能体。
下一篇,我们深入Harness Engineering的核心理念和五大要素。
