 夜雨聆风
夜雨聆风谁懂啊家人们!😭终于不用再为AI模型的TOKEN花钱了! 作为一个经常需要用AI做简单推理、日常问答、轻量创作的普通人,之前要么用在线版AI,动辄就提示“TOKEN不足”“付费升级”,要么找各种开源模型,不是配置不够跑不起来,就是操作复杂到劝退,折腾了大半个月,终于迎来了胜利的曙光——
在我的Win11普通电脑上,成功跑起了Gemma4:e4b! 没有高端配置,没有复杂的服务器,就是一台日常办公、偶尔玩游戏的普通台式机,亲测能跑、能用,虽然稍稍有点卡,但完全在可接受范围内,从此实现AI模型本地自由,再也不用看TOKEN的脸色,也不用花一分钱充值!原来一天好几十元的烧钱,真心是舍不得用呀。都是去豆包上选问清楚了,再回来做,感觉很憋闷,现在爽了。

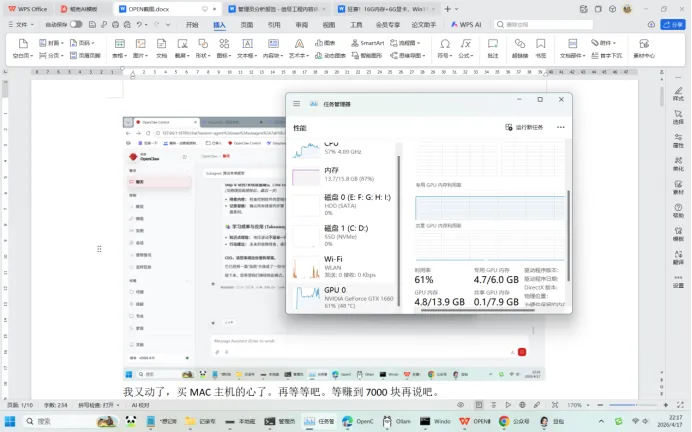
先跟大家报一下我的“配置”,避免大家觉得我是用了什么高端设备: ✅ 系统:Windows 11(普通家庭版,没做任何特殊优化) ✅ 内存:16G(日常办公足够,跑模型时会占满,但不影响基础操作) ✅ 显卡:6G显存(不是什么高端卡,就是普通NVIDA的RTX1660系列,之前还担心显存不够,没想到完全hold住) ✅ 模型:Gemma4:e4b(谷歌出品的开源大模型,轻量又能打,日常使用完全够用)
其实最开始我也没抱太大希望,毕竟看很多教程都说,跑大模型至少要8G显存、32G内存,我这配置只能说是“勉强达标”,甚至还略低于推荐配置。 从找模型、配置环境,到调试参数、解决各种报错,前前后后折腾了好多天,中间也遇到过显存溢出、模型加载失败、运行卡顿到崩溃的问题,一度想放弃,毕竟“免费的东西果然难搞”。我已经反复试验好多天了,其它前期我已经研究2周了始终没有成功,这次成功的关键是Gemma4:e4b可以加载,终于成功了。兴奋!
但好在没半途而废,一点点调整参数,关闭不必要的后台程序,优化显存调度,终于!当看到模型成功加载、打出第一句回复的时候,那种成就感真的拉满了!🥳

跟大家说一下实际使用感受,不吹不黑,客观分享: ✨ 可用性:完全在线!日常问答、简单推理、文案润色、代码辅助,都能轻松应对,不用联网(加载模型后),断网也能正常使用,再也不用担心网络卡顿或TOKEN不够。复杂的事可以直接换网上的大模型。 ✨ 流畅度:稍稍有点卡,但可接受。加载模型需要1-2分钟,生成回复时,短句子(10-20字)基本秒出,长句子(50字以上)会卡顿几秒,毕竟配置有限,这个表现已经超出我的预期了。 ✨ 优势:最大的亮点就是「免费」+「本地部署」,不用花钱买TOKEN,不用依赖第三方平台,数据都存在自己电脑里,隐私更安全,日常使用完全够用,性价比直接拉满。

可能有人会问:6G显卡+16G内存,真的能跑Gemma4:e4b吗?会不会是噱头? 我可以很肯定地说:真的可以!亲测可行! GPU基本是满载,内存80%左右。

核心秘诀就是「合理优化」,不用追求极致性能,只要适配自己的配置,关闭冗余功能,调整量化参数,普通配置也能跑起来。比如我就用了INT4量化,最大程度节省显存,同时关闭了后台所有不必要的程序,让电脑资源全部集中在模型运行上。
之前一直羡慕那些能本地跑大模型的大佬,总觉得“门槛很高”,直到自己实操才发现,原来普通人也能做到——不用高端配置,不用专业技术,只要愿意花点时间调试,就能摆脱TOKEN的束缚,实现AI自由。
对于和我一样,预算有限、配置普通,又经常需要用AI的朋友来说,Gemma4:e4b真的是福音,16G内存+6G显卡的Win11电脑就能跑,稍稍有点卡,但完全不影响使用,再也不用花钱买TOKEN,再也不用被在线AI的限制绑住手脚。前几天我还想MAC-MINI-M4得1万多块。这下不用了。
现在每天用它辅助办公、写文案、查资料,不用再担心“TOKEN不够用”,也不用再纠结“要不要充值”,这种自由感真的太爽了!
最后想说:普通人的AI自由,从来都不是靠高端配置堆出来的,而是靠一点点尝试和坚持。如果你也有一台普通配置的电脑,也想摆脱TOKEN的困扰,不妨试试Gemma4:e4b,亲测可行,赶紧冲!
后续我也会把自己的配置教程、调试技巧整理出来,分享给大家,帮大家少走弯路,一起实现本地AI自由~
评论区聊聊:你的电脑配置是多少?有没有尝试过本地跑大模型?

