 夜雨聆风
夜雨聆风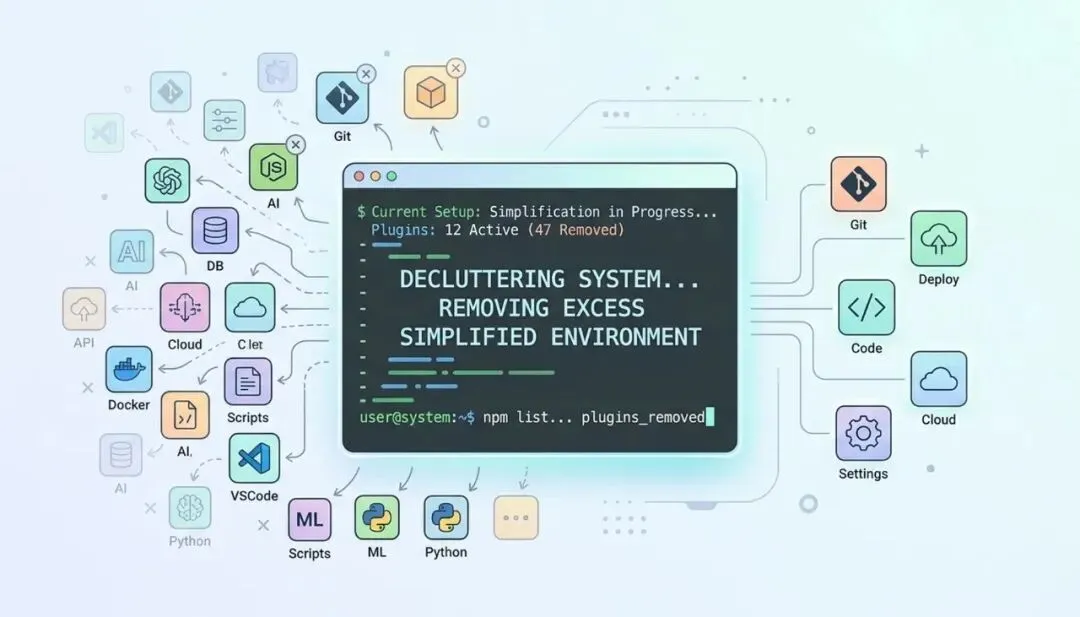
大家好,我是飞飞。
gstack 我用了几周,今天卸了。
不是因为它不好——恰恰相反,它太强了,强到把我的 Claude Code 拖慢了。
装上 gstack 的第一天
Garry Tan,YC 的 CEO,把自己用 Claude Code 写了 60 万行代码的工作流开源了。
23 个 slash commands,每个对应一个角色——CEO、设计师、工程经理、QA、安全官、发布经理。
你装上 gstack,相当于在终端里养了一个虚拟团队。
GitHub 68,000 多个 star。社区里到处在讨论。我看了一圈文档,觉得这个思路很对——让 AI 不只是写代码,而是从产品决策开始介入。
装完之后我跑了第一个任务:用 /office-hours 讨论一个新功能的需求。
体验确实好。
它会从 CEO 视角问你"这个功能的用户价值是什么",然后切到工程视角问"技术上有什么约束",最后从 QA 视角问"上线后怎么验证"。
一套下来,需求比我自己想的清楚多了。
问题是后来出现的。
我的 Claude Code 开始变慢了
装 gstack 之前,我已经有 superpowers 的 14 个 skill,加上自己写的十几个 content 类 skill。
加上 gstack 的 23 个,总数直接到了 50+。
第一个信号是 /context 命令。跑了一下,Skills 那一行从 1k tokens 变成了 4.2k。
加上 System tools、Memory files、Custom agents,开局就吃掉了 30k tokens。200k 的 context 窗口,还没开始干活就去了 15%。
第二个信号是响应速度。以前一个简单任务——改个 CSS、加个字段——Claude 直接动手,两三秒给方案。装了 gstack 之后,它开始犹豫了。
终端里经常看到它在"思考"该调用哪个 skill。
一个改按钮颜色的需求,它先跑了 /office-hours 的判断流程,然后考虑要不要跑 /design-consultation,最后才开始写代码。
三十秒的活变成了三分钟。
第三个信号是 skill 冲突。superpowers 有一个 brainstorming skill,gstack 有一个 /office-hours。两个都想在任务开始时介入。
Claude 有时候先跑 brainstorming 再跑 /office-hours,有时候反过来,有时候两个都跑一遍。结果是同样的问题被问了两次。
Claude Code 的文档里有一句话:Skills and subagents override by name: when the same name exists at multiple levels, one definition wins based on priority. 名字不同的 skill 不会被优先级覆盖——它们会同时生效,然后打架。
一个研究者的 GitHub Issue 让我彻底想明白了
GitHub Issue #39686,标题是:claude.ai Skills and Cowork plugins silently injected into Claude Code context — no opt-out, ~6k tokens wasted per session。
发帖人是一个 AI 意识研究者,他有 80 多个 custom skills。
他发现 claude.ai 上的 skills 和 Cowork 插件被静默注入到了 Claude Code 的 context 里。
他没装、没选、没同意,每个 session 凭空多了 69 个 skill 定义,6000 个 tokens 就这么没了。
他说了一句话让我印象很深:
"Every token of context matters. Losing 6,000 tokens per session to uninvited duplicates is not a minor annoyance — it's a material impact on my ability to work."
Claude Code 创始人 Boris Cherny 也公开承认了这个问题的一个维度:性能退化的原因之一是
"People pulling in a large number of skills, or running many agents or background automations, which sometimes happens when using a large number of plugins."
Reddit 上有人更直接:
"I just wonder how many users with these problems use these 600 skill 463 custom slash command 74 custom Agent framework plugins."
600 个 skill。这不是夸张,是真的有人装到了这个数字。
Skill 是怎么吃 token 的
理解这个问题需要知道 Claude Code 的 skill 加载机制。
每个 skill 有两部分。第一部分是 description。
一行描述,大约 10 个 tokens,每次你发消息都会被包含在 context 里。
50 个 skill 的 description 就是 500 tokens,每条消息都在。
第二部分是 skill 正文。当 Claude 判断需要使用某个 skill 时,会读取完整内容。一个 skill 正文通常 500 到 2000 tokens。
gstack 的某些角色 skill 内容更长,因为它要注入完整的角色 prompt 和决策框架。
一个执行层 skill 消耗 10K+ tokens 的情况在 gstack 里不少见。
MindStudio 有一篇文章专门讲了 Context Rot——上下文腐烂。
核心观点是:即使你没超过 200K token 的窗口限制,skill 文件的膨胀也会导致注意力稀释。
研究表明,模型处理 context 中间位置的信息不如边缘位置可靠。
你塞进去的 skill 越多,每个 skill 被正确理解和执行的概率就越低。
这就解释了为什么我装了 50+ skill 之后,Claude 经常在两个功能相近的 skill 之间犹豫。它的注意力被稀释了。
我的 30 skill 原则
卸载 gstack 之后,我重新整理了自己的 skill 列表。
superpowers 的 14 个 skill 保留了——brainstorming、planning、TDD、debugging、code review 这些都是执行层的刚需。
我自己写的 content 类 skill 保留了 7 个——researcher、writer、polisher、training、artist、distributor、director。
这是我的博客流水线,每个 skill 都在频繁使用。
gstack 的 23 个 skill 全部卸载。
总数从 50+ 降到了 28 个。
效果立竿见影。/context 显示 Skills 回到了 1.2k tokens。响应速度恢复了。
Claude 不再在多个决策 skill 之间犹豫了。一个改按钮颜色的需求,它直接改,不绕弯。
我不是说 gstack 不好。gstack 的 /office-hours 和 /plan-ceo-review 确实能帮你在动手前想清楚。
但对我来说,superpowers 的 brainstorming 已经覆盖了这个需求。两套决策框架叠在一起,结果不是 1+1=2,是 1+1=0.5。
什么时候该装,什么时候该拆
如果你是独立开发者或者小团队创始人,需要 AI 帮你从产品决策层面思考,gstack 确实值得试。/office-hours 一个人就够用。
但如果你已经有了自己的工作流——已经有了 brainstorming skill、有了 planning skill、有了 code review skill——再装 gstack 大概率是减分。
因为你引入了 23 个新的决策点,每个都在争夺 Claude 的注意力和你的 token 预算。
我的建议是这样:
把你所有 skill 的数量控制在 30 个以下。打开 /context 看一眼 Skills 占了多少 tokens。如果超过 2k,你该开始做减法了。
每个 skill 问自己一个问题:过去一周我用过它吗?如果没有,卸载。
如果两个 skill 功能相近——比如都是在任务开始时做需求澄清——只留一个。
Claude 在两个相似 skill 之间做选择的成本,比你自己选一个然后坚持用它的成本高得多。
skill 的价值在于"教 AI 一个工作流"。但教得太多,AI 反而不知道该先听谁的。
就像一个实习生,你给他三页纸的操作手册他能记住,给他三十页他就开始翻来翻去了。
gstack 很强。但我的 Claude Code 只需要一支精锐小队,不需要一个完整的虚拟公司。
你装了多少个 skill?跑过 /context 看过 token 占用吗?评论区聊聊你的 skill 管理经验。
