 夜雨聆风
夜雨聆风引言
上一篇文章我们学会了反向传播——AI知道自己错了,也算出了每个权重该朝哪个方向调。但知道方向只是第一步,更关键的问题是:这一步该迈多大?
步子太小,走到天黑都到不了山脚;步子太大,可能直接跨过山谷冲到对面山坡上。在深度学习里,负责控制“步长”和“步法”的就是优化器(Optimizer)。
今天我们来认识两位优化器界的明星:一个是老实巴交的SGD(随机梯度下降),一个是聪明灵活的Adam(自适应矩估计)。我们会用Python模拟一个“下山”任务,让它们在同一个山谷里比赛,看看谁更快找到最低点。

什么是梯度下降?想象你在浓雾中下山
假设你被扔到一座不熟悉的山上,四周浓雾弥漫,只能看清脚下几米的范围。你的目标是走到海拔最低的山谷底部。你能做的只有一件事:每次抬脚前,先摸一摸周围哪个方向最陡峭,然后朝那个方向迈一小步。 重复这个过程,最终你就能下到谷底。
这就是梯度下降(Gradient Descent) 的核心思想:
当前位置 = 当前的权重参数
海拔高度 = 损失函数的值
最陡峭的方向 = 负梯度方向
迈步的大小 = 学习率(learning rate)
用数学语言写出来就是更新公式:
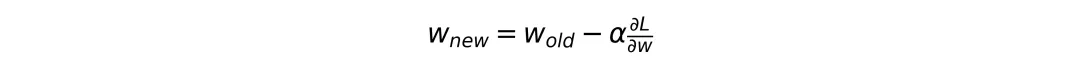
其中 alpha 是学习率,dL/dw 是损失函数对权重的梯度。
SGD:最朴素的“老实人”
SGD(Stochastic Gradient Descent,随机梯度下降)就是上面那种“每次只朝最陡方向迈一步”的纯种梯度下降。它从不耍花样,认准一个方向就直直往下走。
SGD的优点:简单可靠,数学上保证只要步长够小,最终一定能收敛到某个最小值附近。
SGD的缺点:
对学习率极度敏感。太大则震荡甚至发散,太小则蜗牛爬行。
在山谷里的“之字形”震荡——如果山谷是狭长的,SGD会在两侧山坡上来回弹跳,前进缓慢。
容易卡在“鞍点”(像马鞍一样中间平坦的地方),梯度接近0就走不动了。
为了直观感受,我们写一段代码模拟SGD下山的过程:
# 模拟一个简单的二次山谷地形:f(x,y) = x^2 + 10*y^2def valley(x, y):return x**2 + 10 * y**2def grad(x, y):return 2*x, 20*y# SGD下山x, y = 8.0, 8.0 # 起始点alpha = 0.02path_sgd = [(x, y)]for _ in range(50):gx, gy = grad(x, y)x = x - alpha * gxy = y - alpha * gypath_sgd.append((x, y))
稍后我们会把这条路径画出来。
Adam:自带“动量”和“自适应步长”的聪明人
SGD就像一个盲人,每次只能根据脚下的坡度迈步。Adam则像一个经验丰富的登山者,它做了两件聪明事:
动量(Momentum):记住上一次迈步的方向,这次迈步时把上次的惯性也考虑进去。就像推一个铁球下山,越滚越快。
自适应学习率:对于陡峭的维度,自动减小步长避免震荡;对于平坦的维度,自动增大步长加速前进。相当于给每个参数单独配了一个“步长调节器”。
Adam的更新规则稍复杂,但我们只需要知道效果:它几乎不需要手动调学习率,就能又快又稳地收敛。
用同样的山谷模拟Adam:
# Adam下山(简化版,真实Adam还有偏差修正)x, y = 8.0, 8.0alpha = 0.1beta1, beta2 = 0.9, 0.999m_x, m_y = 0.0, 0.0v_x, v_y = 0.0, 0.0eps = 1e-8path_adam = [(x, y)]for t in range(1, 51):gx, gy = grad(x, y)m_x = beta1 * m_x + (1 - beta1) * gxm_y = beta1 * m_y + (1 - beta1) * gyv_x = beta2 * v_x + (1 - beta2) * (gx**2)v_y = beta2 * v_y + (1 - beta2) * (gy**2)x = x - alpha * m_x / (np.sqrt(v_x) + eps)y = y - alpha * m_y / (np.sqrt(v_y) + eps)path_adam.append((x, y))
动手环节:画出SGD和Adam的“下山轨迹”
我们将两种优化器的路径画在同一张等高线图上,红色代表SGD,绿色代表Adam,看谁先到达谷底(中心点0,0)。
import numpy as npimport matplotlib.pyplot as pltimport matplotlib.font_manager as fm# ========== 中文字体配置 ==========def set_chinese_font():font_candidates = ['SimHei', 'Microsoft YaHei', 'PingFang SC','Arial Unicode MS', 'WenQuanYi Micro Hei', 'Noto Sans CJK SC']available_fonts = [f.name for f in fm.fontManager.ttflist]for font in font_candidates:if font in available_fonts:plt.rcParams['font.sans-serif'] = [font]plt.rcParams['axes.unicode_minus'] = Falsereturn Trueplt.rcParams['font.family'] = 'sans-serif'return Falseset_chinese_font()# 定义地形和梯度def valley(x, y):return x**2 + 10 * y**2def grad(x, y):return 2*x, 20*y# SGD路径x_sgd, y_sgd = 8.0, 8.0alpha_sgd = 0.02path_sgd = [(x_sgd, y_sgd)]for _ in range(50):gx, gy = grad(x_sgd, y_sgd)x_sgd -= alpha_sgd * gxy_sgd -= alpha_sgd * gypath_sgd.append((x_sgd, y_sgd))path_sgd = np.array(path_sgd)# Adam路径x_adam, y_adam = 8.0, 8.0alpha_adam = 0.1beta1, beta2 = 0.9, 0.999m_x, m_y = 0.0, 0.0v_x, v_y = 0.0, 0.0eps = 1e-8path_adam = [(x_adam, y_adam)]for t in range(1, 51):gx, gy = grad(x_adam, y_adam)m_x = beta1 * m_x + (1 - beta1) * gxm_y = beta1 * m_y + (1 - beta1) * gyv_x = beta2 * v_x + (1 - beta2) * (gx**2)v_y = beta2 * v_y + (1 - beta2) * (gy**2)x_adam -= alpha_adam * m_x / (np.sqrt(v_x) + eps)y_adam -= alpha_adam * m_y / (np.sqrt(v_y) + eps)path_adam.append((x_adam, y_adam))path_adam = np.array(path_adam)# 绘制等高线x = np.linspace(-9, 9, 200)y = np.linspace(-9, 9, 200)X, Y = np.meshgrid(x, y)Z = valley(X, Y)plt.figure(figsize=(8, 6))plt.contour(X, Y, Z, levels=20, cmap='viridis', alpha=0.6)plt.plot(path_sgd[:,0], path_sgd[:,1], 'r-o', markersize=4, linewidth=1.5, label='SGD (α=0.02)')plt.plot(path_adam[:,0], path_adam[:,1], 'g-o', markersize=4, linewidth=1.5, label='Adam (α=0.1)')plt.plot(0, 0, 'k*', markersize=15, label='最低点 (谷底)')plt.plot(8, 8, 'ko', markersize=8, label='起点')plt.xlabel('x', fontsize=12)plt.ylabel('y', fontsize=12)plt.title('SGD vs Adam:谁下山更快?', fontsize=14)plt.legend()plt.grid(alpha=0.3)plt.tight_layout()plt.savefig('optimizer_compare.png', dpi=150)plt.show()print(f"SGD 最终位置: ({path_sgd[-1,0]:.3f}, {path_sgd[-1,1]:.3f}), 损失: {valley(*path_sgd[-1]):.3f}")print(f"Adam 最终位置: ({path_adam[-1,0]:.3f}, {path_adam[-1,1]:.3f}), 损失: {valley(*path_adam[-1]):.3f}")
运行后你会看到一张等高线图:
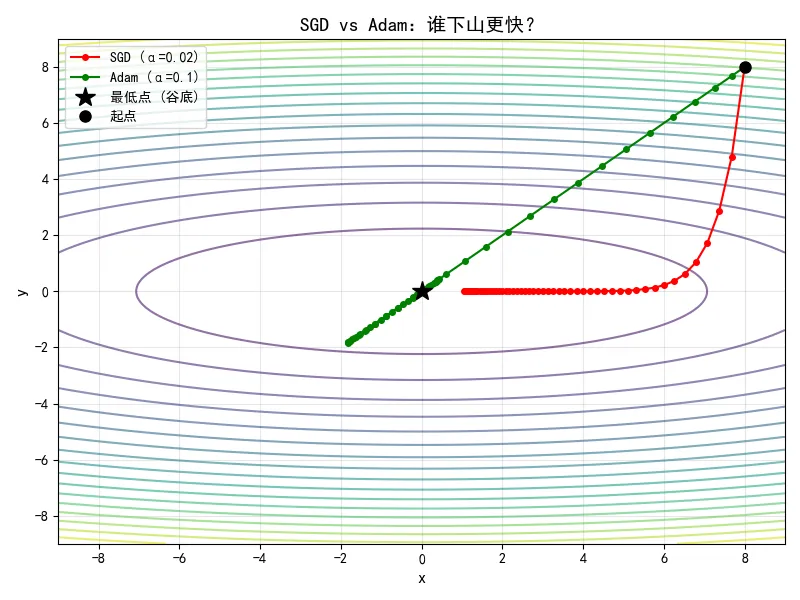

红色路径(SGD):在y方向上剧烈震荡(因为y方向梯度大,固定步长导致反复弹跳),向中心前进缓慢。50步后离谷底还有一段距离。
绿色路径(Adam):几乎没有震荡,一条平滑的弧线直奔谷底。50步后已经非常接近中心。
💡 关键观察:Adam的“自适应步长”让它在陡峭的y方向自动减小步伐,避免震荡;在平坦的x方向自动增大步伐,加速前进。这就是它比SGD快得多的原因。
为什么Adam成了深度学习的“默认选项”?
| 对比项 | SGD | Adam |
|---|---|---|
| 学习率 | 需要精细调参 | 默认值(0.001)几乎通用 |
| 收敛速度 | 慢,尤其在山谷地形 | 快,动量+自适应 |
| 震荡 | 严重,尤其在狭长山谷 | 轻微,自适应步长抑制震荡 |
| 鞍点表现 | 容易卡住 | 动量帮助冲过去 |
| 最终精度 | 调参得当后可能略高于Adam | 大多数任务足够好 |
在实际训练中,Adam几乎成了CNN(包括YOLO)的默认优化器。你在YOLO训练命令里看到的 optimizer=Adam,背后就是上面这段代码的逻辑在运行。不过SGD并没有退役。在一些对精度要求极高的任务(比如ImageNet打榜)中,先用Adam快速找到大致区域,再换SGD精雕细琢,是一种常见策略。
在YOLO里怎么选优化器?
YOLO的训练配置文件里有一行 optimizer,你可以填 SGD、Adam、AdamW 等。
新手/快速原型:直接上Adam,省心省力。
追求极致精度:SGD + 精心调参的学习率 + 更长的训练轮数。
另外,AdamW是Adam的一个改进版,把权重衰减(Weight Decay)从自适应学习率中解耦出来,现在很多SOTA模型都偏好AdamW。YOLOv8就默认使用了AdamW。
优化器决定了AI“下山”的步法。SGD像一个盲人,每次只根据脚下坡度迈步;Adam像一个经验丰富的登山者,带着惯性和自适应步长,又快又稳。虽然SGD在某些场景下精度上限更高,但Adam凭借省心、快速的特点,成了绝大多数深度学习任务的默认选择。
