 夜雨聆风
夜雨聆风欢迎关注「几米宋」的个人微信公众号。我专注 AI 原生基础设施、GPU 虚拟化与异构算力治理的系统性研究与工程实践,同时推动云原生开源生态在 AI 场景下的深度应用

📄 文章摘要
很多团队一聊 AI 基础设施,第一反应就是"是不是该多买点 GPU"。到了 2026 年,这个问题已经过时了。真正成熟的 AI 系统,不是押注单一算力,而是运行在一套异构芯片组合之上——CPU 负责控制与编排,GPU 负责训练与高吞吐推理,TPU 负责垂直优化的张量计算,NPU 负责端侧低功耗 AI,DPU 负责网络、安全与基础设施卸载,APU 负责统一内存协同计算,LPU 负责低延迟语言生成。未
很多团队一聊 AI 基础设施,第一反应就是"是不是该多买点 GPU"。到了 2026 年,这个问题已经过时了。真正成熟的 AI 系统,不是押注单一算力,而是运行在一套异构芯片组合之上——CPU 负责控制与编排,GPU 负责训练与高吞吐推理,TPU 负责垂直优化的张量计算,NPU 负责端侧低功耗 AI,DPU 负责网络、安全与基础设施卸载,APU 负责统一内存协同计算,LPU 负责低延迟语言生成。未来的竞争,不是谁 GPU 最多,而是谁最会调度这些不同的芯片。
为什么会出现这么多“PU”
本质原因只有一个:计算需求的增长速度,已经超过了通用芯片单一路线能承载的效率边界。过去 CPU 可以解决大部分问题,后来深度学习来了,矩阵计算爆发,GPU 崛起。再后来,边缘 AI、低延迟推理、数据中心网络瓶颈、多租户隔离,又催生了新的专用处理器。所以这些芯片不是营销产物,而是系统压力层层递进的结果。
七类芯片速查表
| 缩写 | 全称 | 擅长什么 | 典型场景 | 最常见误用 |
|---|---|---|---|---|
| CPU | Central Processing Unit | 通用计算、复杂逻辑 | 控制面、预处理、调度 | 拿来硬扛大模型计算 |
| GPU | Graphics Processing Unit | 并行矩阵计算 | 训练、批量推理 | 用来做低并发强实时对话 |
| TPU | Tensor Processing Unit | 张量计算加速 | Google Cloud 训练/推理 | 当作通用 GPU 使用 |
| NPU | Neural Processing Unit | 低功耗推理 | AI PC、手机、边缘设备 | 拿来做训练 |
| DPU | Data Processing Unit | 网络/存储卸载 | 大规模 AI 集群 | 小规模场景过度建设 |
| APU | Accelerated Processing Unit | CPU+GPU 紧耦合 | 单机微调、HPC | 只看 FLOPS 忽略内存优势 |
| LPU | Language Processing Unit | 低延迟语言生成 | 实时 Agent、语音 AI | 当通用训练芯片 |
CPU:系统的大脑,不是主力算力
CPU 的强项一直没变——分支判断、多任务调度、I/O 管理、数据预处理、Tokenizer、Agent workflow orchestration。它擅长的是决定"下一步做什么",而不是"把同一个乘加动作重复几十亿次"。所以在 AI 系统里,CPU 更像控制平面,负责 Kubernetes 调度、推理前后处理、检索与数据库访问、工具调用编排这些事。很多人把 CPU 看轻了,但没有 CPU,GPU 集群往往也跑不顺。
GPU:AI 时代的主力发动机
GPU 赢在一件事情上:大规模并行矩阵计算。Transformer、CNN、Embedding,本质上都依赖矩阵乘法,GPU 用数千核心加上 HBM 和 Tensor Core 把这件事做到极致。今天 GPU 仍然是大模型训练的默认选择、云上 AI 的默认资源和通用推理的默认方案。但 GPU 也有现实问题。
利用率经常被高估。 很多企业买了一堆 GPU,真实利用率并不高,原因包括作业碎片化、多租户抢占、调度不合理、模型显存不匹配、空闲资源无法复用。
GPU 越多,调度越难。 从单机到多节点再到异构卡池,复杂度指数级上升。这也是为什么 GPU 时代的真正价值层开始从硬件转向调度系统。
GPU 不是天然适合低延迟交互。 单用户实时对话、语音 Agent、低 batch 请求,并不是 GPU 最舒服的工作模式。
TPU:Google 的垂直算力路线
Google TPU 的逻辑非常明确:放弃通用性,换取特定任务的极致效率。它针对 Transformer、JAX/TensorFlow 和 Google Cloud 内部生态做了深度优化。TPU 更像一整套平台能力,而不是单独一块卡,适合大规模训练、高密度 serving 以及深度绑定 Google Cloud 的团队。不适合任意框架迁移、本地部署或者需要高自由度的实验环境。TPU 强,但它的边界也很清晰。
NPU:端侧 AI 的真正主角
很多人谈 AI 只看数据中心,但未来调用次数最多的 AI 很可能发生在手机、PC、耳机、眼镜和汽车这些设备上。这些设备最重要的约束不是算力,而是电池、发热、响应速度和本地隐私,NPU 正是为这些约束而生的。它负责实时字幕、背景虚化、本地 Copilot、语音助手和图像增强这些功能。所谓 AI PC,本质不是 PC 加 AI,而是 NPU 进入个人计算设备。
DPU:被低估的数据中心关键角色
很多 GPU 集群的问题不在 GPU,而在网络瓶颈、RDMA 管理、存储 I/O、安全隔离、East-West 流量和加密开销。DPU 的意义就是把基础设施负担从 CPU 身上剥离出去。NVIDIA BlueField 系列是典型代表。几十卡以下的规模感受不明显,但到了几百卡以上,这会变成真实成本问题。
APU:统一内存的另一条路线
很多人看芯片只看 FLOPS,这是旧时代思维。现实中大量性能浪费在数据搬运上——CPU 内存一份、GPU 显存一份,PCIe 来回复制、同步等待。APU 的价值在于 CPU 和 GPU 紧耦合、共享地址空间、减少数据复制,更适合单机训练与微调。AMD MI300A 和 Apple Silicon Unified Memory 是代表路线,很多本地 AI 工作站未来会越来越重视这条方向。
LPU:语言模型专用芯片的实验方向
Groq 提出的 LPU,本质是在赌一条假设:LLM 推理是一条可被高度流水线化的固定路径。它强调 token generation latency、deterministic execution、极低 jitter 和实时语音交互。如果你做的是实时 AI assistant、Voice agent 或高频文本生成,这类芯片路线值得关注。但它仍然是推理特化路线,不是 GPU 替代品。
按工作负载选芯片
选择芯片其实很直接:做训练优先 GPU;做低成本大规模云训练评估 TPU;做端侧产品优先 NPU;做超大规模 AI 集群必须考虑 DPU;做单机微调或本地 AI 看统一内存 APU;做低延迟对话系统评估 LPU;做系统编排,CPU 永远在场。
调度异构芯片是云原生的下一阶段
过去 Kubernetes 调度的是 CPU 和 Memory,后来加上了 GPU,未来会扩展到 GPU memory、topology、NUMA、tokens/sec、latency SLA、NPU slots、heterogeneous accelerators 和 power budget。这意味着 Kubernetes 正在从容器编排器进化为 AI Control Plane,而异构芯片时代,资源调度层会越来越重要。
别再迷信单卡性能榜
很多人还在纠结 H100 强还是 B200 强、TPU 值不值、NPU TOPS 高不高。这些问题当然有价值,但都不是核心问题。真正的问题是:你的系统是否让正确的任务跑在正确的芯片上。未来赢家不是买最多卡的人,而是最会组织算力的人。
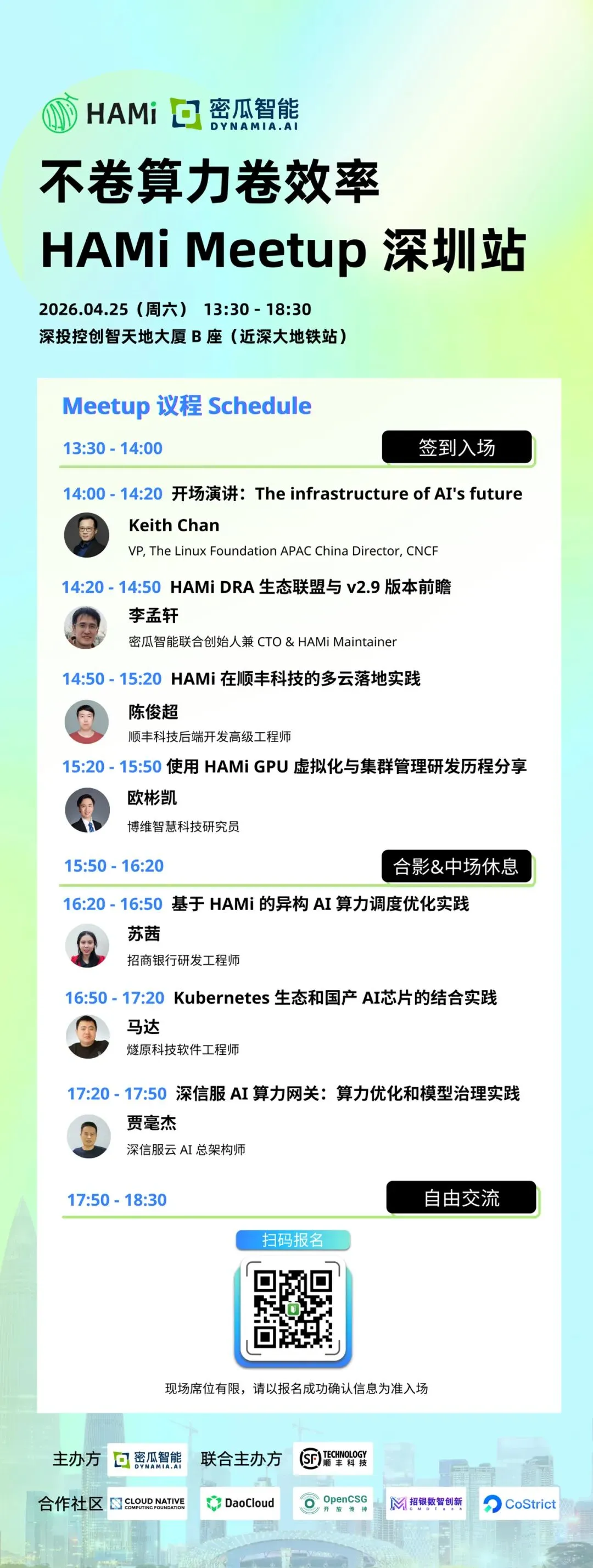
同时推荐一下笔者组织的本周六的深圳一个活动,欢迎报名。
更多精彩内容
🌐 个人网站:jimmysong.io
🎥 Bilibili:space.bilibili.com/31004924
如果这篇文章对你有帮助,欢迎点赞、分享给更多朋友!
