 夜雨聆风
夜雨聆风大模型训练与推理对算力的需求正以指数级增长,而单芯片的性能提升已无法独立支撑这一需求。当一次大模型训练需要数万张GPU协同工作时,"互联"——即芯片之间、板卡之间、服务器之间、机架之间如何高效传输数据——已成为决定AI算力系统实际性能的关键瓶颈。
一个AI数据中心的互联体系是多层级的:最底层是芯片内部die与die之间的互联(UCIe),往上是同一节点内GPU之间的高速互联(NVLink),再往上是服务器通过PCIe总线与加速卡、存储和网络设备的连接,最外层则是机架与机架之间通过以太网或InfiniBand构建的集群网络。每一层级的带宽、延迟和功耗特性截然不同,所采用的技术路线也各有侧重。
本文将从底层芯片互联逐层向上,系统梳理当前服务器互联的技术体系、协议标准、关键产品形态以及未来演进方向,重点分析UCIe、NVLink、PCIe等核心协议,以及光模块、CPO、铜缆与SerDes等关键使能技术的发展脉络。同时,本文将深入分析国内互联产业链上下游中具备真实业绩和技术壁垒的核心企业,梳理其产品路线与竞争优势。
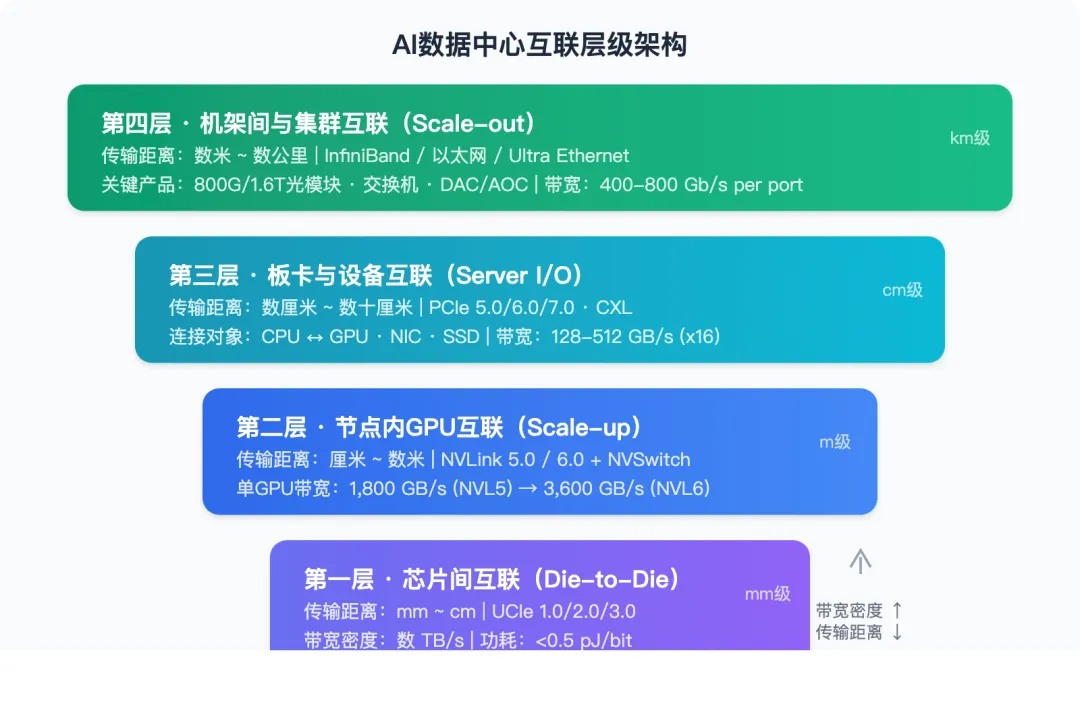
图1:AI数据中心四层互联架构——从芯片到集群,每一层级的带宽、距离和协议各不相同
一、互联层级总览:从芯片到数据中心
现代AI算力系统的互联可划分为四个层级,每一层级在带宽需求、传输距离和技术选择上存在本质差异:

第一层级:芯片间互联(Die-to-Die)。传输距离在毫米到厘米量级,发生在同一封装基板上的多个chiplet之间。核心协议为UCIe,带宽密度极高(可达数TB/s),功耗效率最优(低至0.5 pJ/bit以下)。这一层级的目标是让多个chiplet在逻辑上等效于单颗大芯片。
第二层级:节点内加速卡互联(Scale-up)。传输距离在厘米到数米范围,发生在同一服务器节点内的多张GPU或加速卡之间。NVIDIA的NVLink是该层级的代表性技术,当前Blackwell架构的NVLink 5.0可提供单GPU 1,800 GB/s的互联带宽。这一层级追求的是GPU间的高带宽、低延迟通信,以实现模型并行训练中的高效梯度同步。
第三层级:板卡与设备互联(Server I/O)。以PCIe总线为核心,连接CPU与GPU、网卡、SSD等各类设备。PCIe 5.0(32 GT/s)目前是主流部署标准,PCIe 6.0(64 GT/s)正在导入,PCIe 7.0规范已于2025年6月正式发布,将数据速率提升至128 GT/s。CXL(Compute Express Link)作为PCIe物理层之上的缓存一致性协议,正在开辟内存池化和异构计算的新场景。
第四层级:机架间与集群互联(Scale-out)。传输距离从数米到数公里不等,构建的是整个GPU集群的通信网络。InfiniBand和以太网是两条主要路线。NVIDIA的InfiniBand方案长期主导HPC和AI训练集群,而以太网阵营在Ultra Ethernet Consortium的推动下正快速追赶。这一层级的关键产品包括光模块(800G/1.6T)、交换机和铜缆/光缆。
二、芯片间互联:UCIe与Chiplet架构
2.1 Chiplet的崛起背景
随着先进制程节点的成本急剧上升,单片式(monolithic)SoC的经济性正面临严峻挑战。以台积电为例,N3工艺的每片晶圆成本较N5提升约50%以上,而良率随die面积增大而快速下降。Chiplet架构——将一颗大芯片拆分为多个功能化的小芯片(chiplet),再通过先进封装技术集成于同一基板——已成为业界共识。AMD的EPYC系列处理器、Intel的Ponte Vecchio GPU以及众多AI加速器均采用了这一路线。
Chiplet架构的核心挑战在于:多个来自不同供应商、不同工艺节点的chiplet如何实现高带宽、低延迟、低功耗的互联?这正是UCIe要解决的问题。
2.2 UCIe协议体系
UCIe(Universal Chiplet Interconnect Express)由Intel、AMD、ARM、台积电、三星、日月光等行业巨头于2022年联合发起,旨在建立开放的chiplet互联标准。
UCIe 协议代际演进
UCIe 1.0(2022年)4-32 GT/s · 2D/2.5D封装
UCIe 2.0(2024年8月)+3D封装 · +DFx · +UDA
UCIe 3.0(2025年8月)48-64 GT/s · 性能大幅提升
UCIe 1.0(2022年发布)定义了基础的物理层和协议层规范。物理层支持标准封装(bump pitch 100μm)和高级封装(bump pitch 25μm)两种模式。标准封装下单lane速率为4 GT/s至32 GT/s,高级封装下通过更密集的布线实现更高的带宽密度。协议层支持PCIe和CXL协议的映射,使chiplet可以复用成熟的软件生态。
UCIe 2.0(2024年8月发布)在1.0基础上增加了三项关键能力:第一,标准化的可管理性系统架构(UDA),为多chiplet系统提供统一的测试、遥测和调试框架;第二,支持3D封装,通过hybrid bonding等技术实现垂直方向的chiplet堆叠,带宽密度和功耗效率进一步提升;第三,完善了DFx(Design for Test/Debug/Manufacturing)架构,解决了多供应商chiplet在产品全生命周期中的可测试性问题。
UCIe 3.0(2025年8月发布)是最新版本,最重要的更新是将数据速率提升至48 GT/s和64 GT/s,显著增强了对高带宽AI加速器和高性能计算芯片的支持能力。
UCIe的战略意义在于:它试图在chiplet层面构建类似PCIe在板卡层面所建立的开放互联生态。如果这一生态成熟,芯片设计公司可以像搭积木一样组合来自不同供应商的计算、存储、I/O chiplet,大幅降低芯片设计门槛和成本。
三、节点内GPU互联:NVLink与NVSwitch
3.1 NVLink的代际演进
NVLink是NVIDIA为解决GPU间高速通信而自研的专有互联协议,自2014年首次发布以来已历经六代演进:
| NVLink 5.0 | Blackwell | 2024 | 100 GB/s | 18 | 1,800 GB/s |
| NVLink 6.0 | Rubin | 2026 | 200 GB/s | 18 | 3,600 GB/s |
NVLink 5.0(2024年,Blackwell架构)是当前正在大规模部署的最新一代。它将每条link的双向带宽从50 GB/s翻倍至100 GB/s,配合18条link,实现单GPU 1,800 GB/s的总互联带宽——是上一代Hopper的两倍。更关键的是,NVLink 5.0与NVSwitch芯片配合,在GB200 NVL72系统中构建了72颗GPU的全连接域,域内总带宽高达130 TB/s。
NVLink 6.0(预计2026年下半年,Rubin平台)将再次翻倍,单GPU带宽提升至3,600 GB/s。NVIDIA已披露Vera Rubin NVL72系统(72颗Rubin GPU + 36颗Vera CPU)的机架级总带宽将达到260 TB/s。
3.2 NVSwitch:从节点内到机架级
NVLink的带宽优势需要NVSwitch的配合才能在多GPU系统中充分发挥。NVSwitch本质上是一颗专用的高基数交换芯片,其作用是将节点内或机架内的所有GPU连接成一个全互联的通信域。
在DGX H100时代,每台8-GPU服务器内部通过4颗NVSwitch实现全连接。到了GB200 NVL72时代,NVSwitch的互联规模进一步扩展到机架级,72颗Blackwell GPU通过机架内的NVLink Switch System实现all-to-all通信,无需经过传统以太网或InfiniBand,大幅降低了集合通信(如AllReduce)的延迟。
架构意义:NVSwitch将"Scale-up"的边界从单个服务器节点扩展到了整个机架,使得一个72-GPU机架可以作为一个统一的计算节点来运行超大模型,减少了对Scale-out网络的依赖。
四、板卡与设备互联:PCIe与CXL
4.1 PCIe的持续演进
PCI Express自2003年面世以来,一直是服务器内部CPU与各类外设之间的标准总线。其核心演进路径是每一代将单lane速率翻倍:
PCIe 代际速率演进(x16双向总带宽)
PCIe 3.0(2010年)· NRZ8 GT/s · ~32 GB/s
PCIe 4.0(2017年)· NRZ16 GT/s · ~64 GB/s
PCIe 5.0(2019年)· NRZ32 GT/s · ~128 GB/s
PCIe 6.0(2022年)· PAM464 GT/s · ~256 GB/s
PCIe 7.0(2025年)· PAM4128 GT/s · ~512 GB/s
PCI-SIG已明确表示,PCIe 7.0的首要应用场景并非消费市场,而是云计算、800G以太网和AI。值得关注的是,PCI-SIG已于2025年8月宣布启动PCIe 8.0的开发工作,Marvell在2026年DesignCon上展示了PCIe 8.0 SerDes原型,业界的技术储备节奏正在加快。
4.2 CXL:内存池化与异构计算的关键
CXL(Compute Express Link)构建在PCIe物理层之上,提供了三种子协议:CXL.io(设备发现与配置)、CXL.cache(设备访问主机内存的缓存一致性通道)和CXL.mem(主机访问设备侧内存的通道)。
CXL的核心价值在于打破了传统服务器中内存与CPU的刚性绑定关系。通过CXL,多台服务器可以共享一个外置的内存池,按需动态分配内存资源。CXL 3.1(2024年发布)已支持多级交换和动态容量管理,正在进入实际部署阶段。
五、机架间与集群互联:InfiniBand、以太网与Ultra Ethernet
5.1 InfiniBand:AI训练集群的传统首选
InfiniBand由Mellanox(已被NVIDIA收购)主导发展,长期是高性能计算和大规模AI训练集群的首选互联网络。其核心优势包括:RDMA(远程直接内存访问)原生支持,绕过CPU直接在GPU间传输数据;极低的端到端延迟(亚微秒级);以及成熟的集合通信库(NCCL)优化。
NVIDIA当前的旗舰方案是基于ConnectX-7网卡和Quantum-2交换机的NDR InfiniBand(400 Gb/s)。下一代XDR InfiniBand(800 Gb/s)已经随Blackwell平台推出,配合ConnectX-8网卡和Quantum-3交换机使用。
5.2 以太网阵营的反击
尽管InfiniBand在技术指标上领先,但其封闭生态和较高成本促使超大规模云厂商探索以太网替代方案。根据Dell'Oro Group 2025年数据,以太网在AI后端网络中的份额已快速增长,2025年第四季度以太网交换机在AI集群数据中心的销售额已超过InfiniBand的两倍以上。Amazon、Microsoft、Meta、Oracle和xAI等头部云厂商均在大规模采用以太网方案。
Ultra Ethernet Consortium(UEC)于2023年由AMD、Broadcom、Cisco、Intel、Meta、Microsoft等公司联合成立,UEC 1.0规范已于2025年年中发布。其核心创新包括:无序(unordered)、无连接(connectionless)的传输架构;专为集合通信优化的传输语义;以及从物理层到软件栈的全新设计。UEC硬件预计在2025年秋季进入市场。
六、关键使能技术深度分析
6.1 SerDes:高速互联的物理层基石
SerDes(Serializer/Deserializer,串行器/解串器)是所有高速有线互联的物理层核心。无论是PCIe、以太网、InfiniBand还是NVLink,其底层都依赖SerDes IP将并行数据转换为高速串行信号进行传输,并在接收端恢复为并行数据。
核心命题:SerDes的代际演进与铜缆/光模块的技术路线之争,是理解整个互联产业发展方向的关键。
当前业界的SerDes速率正从112G(112 Gbps per lane)向224G(224 Gbps per lane)过渡。这一跃迁带来了多层面的技术挑战:
信号完整性恶化。224G要求的奈奎斯特频率是112G的两倍(56 GHz vs 28 GHz)。在如此高的频率下,PCB走线的插入损耗急剧增加,铜缆的高频衰减特性也更加恶劣。以112G为例,无源铜缆(DAC)的传输距离一般不超过2-2.5米;到了224G时代,这一距离可能进一步缩短至1米甚至更短。
PAM4调制的深化。从PCIe 6.0和112G以太网开始,业界从NRZ(2电平)编码全面转向PAM4(4电平)编码,在相同波特率下实现双倍数据速率。但PAM4的信噪比要求比NRZ高约9.5 dB,对SerDes的均衡器设计、时钟恢复精度和前向纠错(FEC)提出了更苛刻的要求。224G SerDes延续PAM4编码,但需要在每比特功耗方面较112G降低至少三分之一,这要求更先进的工艺节点(如台积电N3)和更精细的电路设计。
铜缆路线的应对策略。面对224G带来的信号完整性压力,铜缆阵营发展出了多种形态:无源铜缆(DAC)成本最低、功耗最低,但224G时代传输距离极为有限;有源铜缆(ACC)在缆线两端集成模拟均衡器,可将传输距离延伸至2-2.5米,功耗约2.5W(1.6T级别);有源电缆(AEC)嵌入DSP或retimer芯片,可支持更长距离(3-5米),但功耗和成本显著高于ACC。
需要特别注意的是,当前主流的DAC、ACC和AEC产品均基于100G/lane(即112G SerDes速率)设计。当系统向200G/lane(对应1.6T端口速率)演进时,铜缆方案面临全面换代——这不是简单的"线换粗",而是涉及多个技术维度的系统性重构:
200G/lane铜缆换代的四大技术要点:1. 连接器体系重新定义。112G时代的主流连接器(如OSFP、QSFP-DD)的触点间距、阻抗匹配和串扰隔离均针对28 GHz奈奎斯特频率设计。200G/lane将奈奎斯特频率推升至56 GHz,对连接器的介质损耗角正切值(Df)、差分对间串扰隔离度和回波损耗提出了全面升级的要求,现有连接器无法直接沿用。2. 导体和绝缘材料升级。56 GHz频率下,铜导体的集肤效应和表面粗糙度导致的附加损耗急剧增加,需要采用更高纯度的铜合金(如OFC无氧铜)和更低表面粗糙度的导体加工工艺。绝缘层需从传统的聚乙烯基材料升级为更低介电常数(Dk)和更低损耗因子(Df)的氟聚合物材料,成本将大幅上升。3. DAC可用距离骤缩。在112G时代,无源铜缆(DAC)可支持2-2.5米传输距离。到200G/lane时代,无源DAC的有效传输距离将缩短至不足1米,实际应用场景被压缩到机架内相邻设备间的直连——这意味着DAC的应用范围将从"机架内通用"退化为"邻位专用"。4. 有源方案功耗和成本跳增。ACC和AEC中的均衡器和retimer芯片也需要从112G升级到224G版本,目前224G retimer芯片尚处于早期量产阶段,成本和功耗均显著高于成熟的112G方案。1.6T AEC的功耗预计将从当前800G AEC的5-7W跃升至10W以上。
光模块路线的演进。随着SerDes速率提升,电信号在铜缆中的传输距离越来越短,光互联的经济性拐点正在前移。传统光模块在模块内部集成完整的DSP(数字信号处理器),用于对电信号进行时钟恢复和信号整形。一个典型的、基于DSP架构的800G光模块,其整体功耗高达12-15W。
LPO(线性可插拔光学)应运而生。LPO的核心思路是移除光模块内部的DSP,仅保留驱动器、激光器、光电二极管和TIA等线性模拟组件,将数字信号处理任务交由主机端ASIC完成。这一架构变革可将800G光模块功耗降低40-50%(从约14W降至8W以下),延迟也可降低数纳秒。业界预测,到2026-2027年,超过三分之一的数据中心内部800G部署将采用LPO方案。
6.2 光模块:从800G到1.6T
光模块速率演进与市场数据
800G(2025年主力)出货量YoY +60%
1.6T(2026年放量)OSFP-XD · 92%合约
3.2T(实验室阶段)预计2028年后
2025年全球出货量约3,450万支
2025年市场收入超160亿美元
800G光模块是2025年的绝对主力。根据Cignal AI数据,2025年800G光模块出货量同比增长约60%。其主流形态为OSFP和QSFP-DD800封装,内部采用8通道100G/lane(基于112G SerDes)的架构。
1.6T光模块正处于导入前夜。2025年已有小批量商用样品出货(主要面向NVIDIA等特定客户),但大规模上量预计在2026年。1.6T的主流技术路线为OSFP-XD封装(已获得92%超大规模客户合约),内部采用8通道200G/lane或16通道100G/lane。200G/lane路线要求224G SerDes配合,是推动224G SerDes商用的核心驱动力。
6.3 CPO:光电共封装的终极形态
当SerDes速率达到224G甚至更高时,即使是LPO也面临一个根本性问题:电信号从交换机/网卡ASIC芯片出发,经过PCB(印刷电路板)上的铜走线传输到面板前端的光模块插槽,这段10-30厘米的电气路径在56 GHz奈奎斯特频率下损耗过大。CPO(Co-Packaged Optics,光电共封装)的思路是将光引擎直接集成在交换芯片或计算芯片的封装基板上,将电光转换点从传统的面板前端拉近到芯片旁边,从而将电信号传输距离缩短至毫米级,彻底解决高速电信号的损耗和功耗问题。
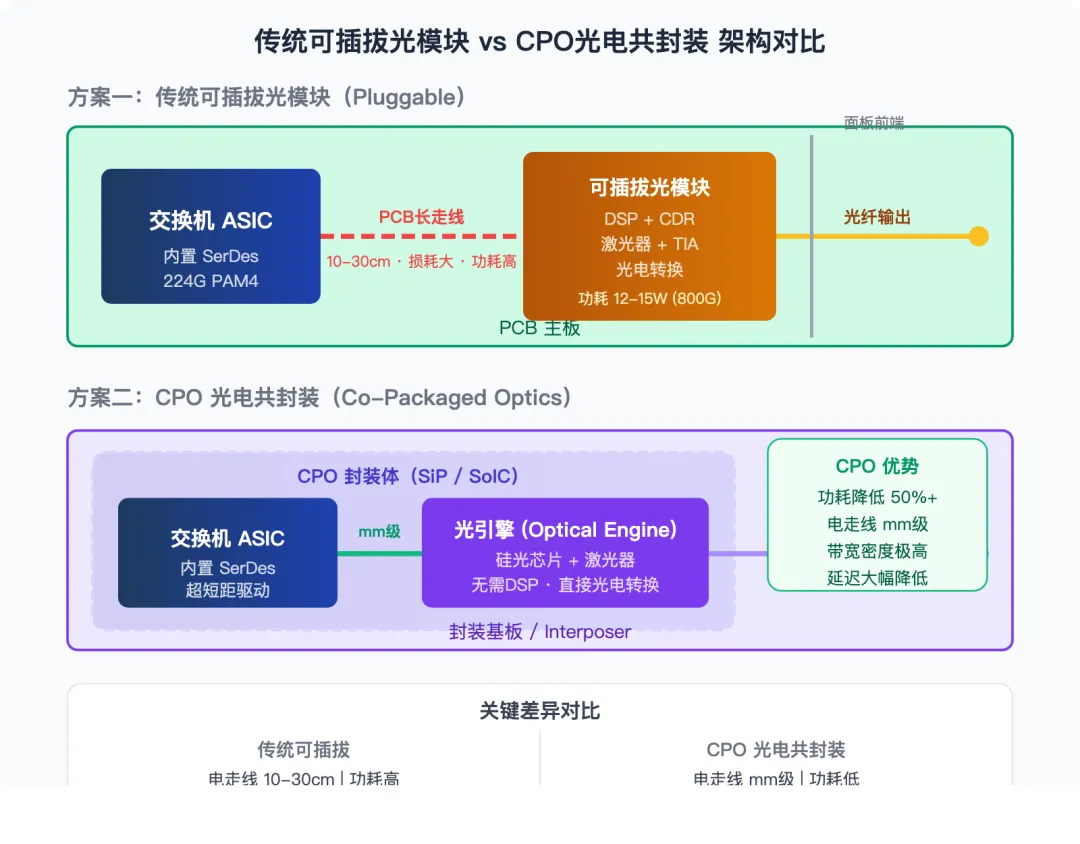
图2:传统可插拔光模块 vs CPO光电共封装架构对比——CPO将光电转换点从面板前端拉近至芯片旁边
产业进展方面:Broadcom是CPO商用化的领跑者。截至2025年底,Broadcom已累计出货超过5万颗Tomahawk 5-Bailly CPO交换机,并宣布其第三代200G/lane CPO平台即将推出。Meta在实验室环境中对Broadcom CPO方案进行了超过100万链路小时的高温测试,未出现一次链路中断。NVIDIA在GTC 2025上发布了基于硅光技术的Spectrum-X和Quantum-X交换机,采用台积电SoIC 3D混合键合技术实现了极高的集成密度。Marvell展示了将定制XPU计算芯片、HBM和3D硅光引擎集成在同一基板上的方案。
CPO 市场与部署时间线
2025年市场规模~20亿美元
复合增长率(CAGR)37-40%
2033-2036年预测200-250亿美元
大规模部署预计2028-2030年
CPO面临的挑战包括:可插拔光模块的可维护性优势难以完全替代(坏了可以单独更换),良率管控难度更高(光引擎与电芯片共封装意味着任一部分失效都会报废整个封装体),以及供应链的成熟度仍需时间积累。因此,业界普遍预期CPO将与可插拔光模块长期共存,CPO首先在带宽密度和功耗要求最极端的场景(如AI训练集群的交换机侧)率先落地。
七、铜缆与光模块技术路线对SerDes发展的影响
铜缆与光模块并非简单的替代关系,它们的技术路线选择深刻影响着SerDes IP的设计方向和整个互联产业链的演进节奏。
对SerDes功耗目标的影响。铜缆链路(尤其是DAC和ACC)要求SerDes在发送端和接收端承担几乎全部的信号补偿工作,包括发送端预加重(Tx FFE)、接收端连续时间线性均衡器(CTLE)和判决反馈均衡器(DFE)等,功耗通常较高。相反,光模块路线——尤其是LPO——可以利用光纤信道近乎无损的传输特性,简化SerDes的均衡器需求,从而降低每比特功耗。OIF定义的CEI-224G框架中,专门为光模块短距场景和铜缆中距场景设定了不同的SerDes性能指标。
对SerDes设计架构的影响。传统DSP光模块内部集成了独立的SerDes和CDR,形成"两跳"架构。LPO和CPO的推进正在打破这一架构:LPO模式下形成"单跳"架构;CPO模式下,SerDes的设计重心从"驱动长距离电信道"转变为"直接驱动光电器件"。
这些变化正在推动SerDes IP供应商(如Synopsys、Cadence、Alphawave Semi、Credo等)分化出面向不同应用场景的产品线:面向铜缆的长距高功率SerDes、面向LPO的线性驱动SerDes、以及面向CPO的超短距低功耗SerDes。
对产业链节奏的影响。由于224G SerDes在铜缆信道上的距离极限已接近可插拔模块的物理要求,这一物理约束正在加速光互联的导入节奏。到448G(下一代SerDes速率,对应PCIe 8.0量级)时代,纯铜缆可插拔方案的可行性将进一步收窄,CPO可能从"可选"变为"必选"。
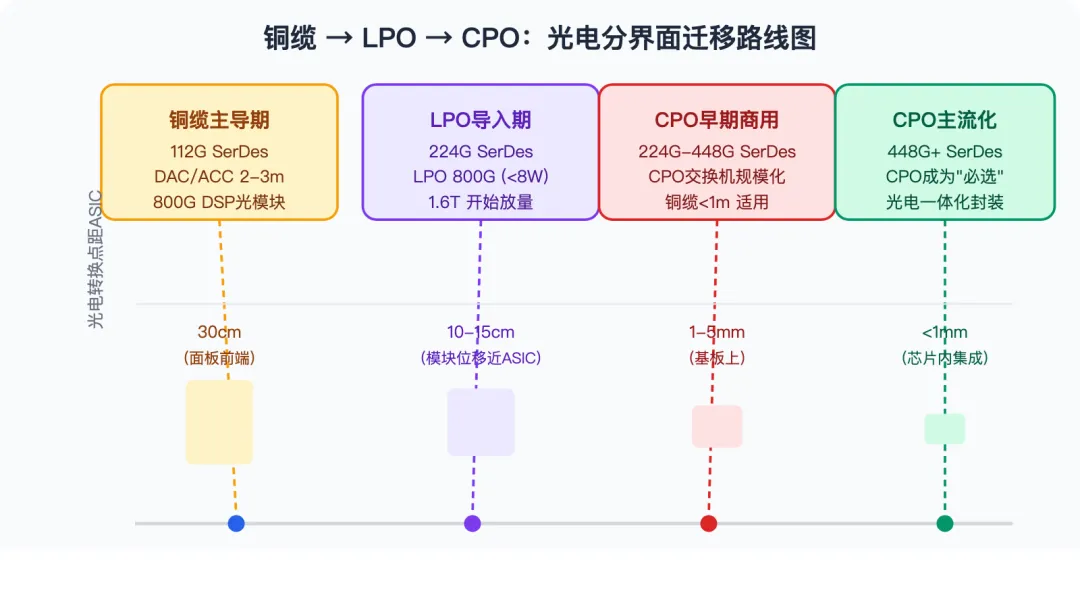
图3:从铜缆到CPO——光电转换点逐步向芯片迁移的技术演进路线
八、国内互联产业链:核心企业与技术壁垒
AI算力基础设施的爆发为国内互联产业链带来了历史性机遇。从光模块到光芯片、从高速铜缆到连接器、从光器件到交换机芯片,国内企业在多个环节已建立起全球竞争力。以下按产业链位置逐一分析具备真实业绩和技术壁垒的代表性企业。
8.1 光模块:中际旭创与新易盛


两家企业的竞争格局值得关注:中际旭创在综合规模和800G存量市场上领先,新易盛则在LPO新技术路线和增速上占优。随着1.6T时代到来,两家企业在200G/lane硅光方案上的竞争将成为下一阶段焦点。
8.2 光器件与光引擎:天孚通信

8.3 光芯片:源杰科技与光迅科技
光芯片是光模块产业链中技术壁垒最高的环节,也是国产替代进程最受关注的领域。光模块中最核心的有源芯片——激光器芯片(如DFB、EML)和探测器芯片——长期由Lumentum、Coherent、住友电工等海外厂商主导。
源杰科技是国内为数不多具备InP(磷化铟)激光器芯片完整自主工艺能力的企业。公司拥有从外延生长、光栅制作、芯片制造到封装测试的全流程IDM能力,这在国内同行中极为稀缺。100G EML芯片在2025年进入量产爬坡阶段。更具前瞻性的是,源杰科技在硅光CW(连续波)光源芯片上率先实现了大功率、高耦合效率的量产突破——硅本身不发光,必须由外部InP激光器提供光源,这使CW光源成为硅光方案中不可或缺的有源组件。公司2024年芯片年产能约96万颗,2026年规划产能将扩展至2000万颗。
光迅科技作为国资背景企业,优势在于从芯片到模块的全产业链布局,已实现25G DFB和EML芯片的自研量产,年芯片产能约1.2亿颗。
国产替代进度:在25G及以下速率芯片上,国内厂商已具备大规模替代能力;在50G-100G EML芯片上正在追赶;200G及以上速率光芯片仍高度依赖海外。差距核心在于InP外延材料的一致性控制和高速调制器设计。
8.4 高速铜缆:沃尔核材
沃尔核材已成为全球第二大、中国第一大高速铜缆制造商,全球市占率约24.9%。2025年公司实现营业收入84.51亿元,其中高速通信线营收10.17亿元,同比大增237.99%。GB300服务器的单机铜缆用量较上一代增幅达50%,全球高速铜缆市场规模从2024年的约12亿美元增长至2025年预计的19亿美元。
沃尔核材的壁垒主要体现在材料技术积累(起家于热缩材料和辐照交联技术)和产能扩张力度(投资25亿元全球扩产)。需要注意的是,铜缆行业整体技术门槛低于光模块和光芯片,护城河更多来自规模和客户认证壁垒。
8.5 高速连接器:立讯精密
立讯精密是国内连接器行业营收规模最大的企业,也是唯一进入全球连接器行业前五的中国企业。2025年连接器及相关业务营收预计超过600亿元,2026年全球市场份额预计约13.9%。公司凭借为NVIDIA供应800G高速铜缆组件和连接器,已深度嵌入全球AI服务器供应链核心。壁垒在于精密制造能力、垂直整合能力和客户认证壁垒(后来者需要12-18个月认证周期)。
8.6 交换机芯片:盛科通信
盛科通信是国内商用以太网交换芯片的龙头企业,自研芯片已进入新华三、锐捷网络、迈普等主流国产网络设备厂商的供应链。但需要客观指出的是,盛科通信目前的产品主要覆盖园区网和中低端数据中心场景,与Broadcom在高端数据中心交换芯片(如51.2T Tomahawk系列)之间仍存在明显的代际差距。
8.7 产业链全景判断
国内竞争力最强的环节是光模块和光器件。中际旭创全球市占率第一、新易盛在LPO路线上领先、天孚通信在光引擎领域占据关键位置——这三家企业2025年业绩均实现了50%以上的增长。技术壁垒最高、国产替代空间最大的环节是光芯片和交换机芯片。源杰科技在InP激光器和硅光CW光源上的突破具有战略意义,但高速光芯片的国产替代尚处于中早期。增速最快但壁垒相对较低的环节是高速铜缆和连接器。沃尔核材和立讯精密受益于AI服务器出货量增长,但长期面临竞争加剧和毛利率下行的压力。
附录一:核心术语释义
光通信关键术语
硅光技术(Silicon Photonics)利用标准CMOS半导体工艺在硅基衬底上制造光学器件(波导、调制器、探测器等)的技术。核心优势是借助成熟的半导体产线实现光器件的大规模、低成本制造,并可将光学功能与电子芯片集成在同一封装内。硅光技术在800G/1.6T光模块中的渗透率正快速提升,预计2026年硅光模块出货量将占全球光模块总量的50%以上。
光模块(Optical Transceiver)实现电信号与光信号之间相互转换的封装模块,是数据中心网络中连接交换机、服务器和存储设备的核心硬件。发送端将电信号转换为激光信号注入光纤传输,接收端将光信号还原为电信号。当前主流为800G可插拔光模块(OSFP/QSFP-DD800封装),1.6T正在进入导入期。
光引擎(Optical Engine)将激光器、调制器、光电探测器和光耦合结构集成在一个小型化封装体内的核心光电转换单元。光引擎是光模块和CPO方案中的"心脏"——在可插拔光模块中,光引擎被封装在模块壳体内;在CPO方案中,光引擎则直接贴装在交换芯片的封装基板上。天孚通信是目前全球1.6T光引擎的核心供应商。
CW激光器(Continuous Wave Laser)持续输出恒定光功率的激光器,在硅光方案中作为外部光源使用。因为硅材料本身不具备发光能力,硅光模块必须依赖外挂的CW激光器(通常采用InP磷化铟材料制造)提供连续激光,再由硅光芯片上的调制器对光信号进行高速调制。随着硅光模块渗透率快速提升,CW激光器需求同步放大,供应紧张预计持续至2027年。
EML激光器(Electro-absorption Modulated Laser)将激光器和电吸收调制器单片集成在同一InP芯片上的器件,可直接输出高速调制光信号。EML是传统(非硅光)高速光模块中最核心、最昂贵的有源芯片,技术壁垒极高。相比CW激光器+硅光调制器的"两芯片方案",EML属于"单芯片方案",在器件复杂度和工艺难度上更高。100G EML芯片目前正处于国产化关键突破期。
PCB / CCL(印刷电路板 / 覆铜板)PCB(Printed Circuit Board,印刷电路板)是服务器和交换机中承载芯片、连接器等元器件并提供电气互联的基板。CCL(Copper Clad Laminate,覆铜板)是PCB的核心原材料,由绝缘基材两面覆盖铜箔制成。在224G及更高速率下,PCB走线的高频信号损耗成为瓶颈,对CCL的介电常数(Dk)和损耗因子(Df)提出了极苛刻的要求,超低损耗CCL(如PTFE基和碳氢基材料)正成为高速交换机设计的必选项。
附录二:光通信市场前景与供应链风险
光通信TAM:从百亿到千亿美元
AI算力需求正驱动光通信市场经历前所未有的扩张。根据多家机构预测,AI光通信的总潜在市场(TAM)将从2025年的约180亿美元增长至2030年的900亿美元左右,年复合增长率高达40%。其中,69%的增量来自Scale-up(节点内/机架内互联)市场——这正是NVLink、CPO和高速光引擎的核心战场。
更值得关注的是计算单元价值密度的跃升:在Scale-out网络中,每个计算单元(如单台GPU服务器)对应的光模块和网络设备美元价值量提升了约16倍;在Scale-up网络中,这一数字更是高达45倍。与此同时,光模块/光引擎市场规模扩大约13倍,可插拔光模块的单位价值市场增长约10倍。这些倍增效应的根本驱动力在于:AI训练集群对GPU间通信带宽的需求增长速度远超GPU算力本身的增速,互联成为整个系统中价值占比持续提升的环节。
硅光技术:渗透率从6%到50%的跃迁
硅光技术是本轮光通信升级中最重要的技术路线变迁。2022年,硅光模块在全球数据中心光模块出货中的占比仅约6%。到2026年,这一比例预计将突破50%,2029年硅光模块市场规模预计达到103亿美元。
硅光技术的快速渗透带来了两个结构性变化:第一,CW激光器需求爆发——每一颗硅光模块都需要配套外挂CW激光器作为光源,这使CW激光器芯片成为供应链中最紧缺的环节之一;第二,EML激光器作为传统非硅光高速模块的核心器件,其需求并未因硅光崛起而消失,反而在100G EML和200G EML等高速品类上面临供不应求。2024年,EML与CW激光器合计市场规模约9.7亿美元,预计到2030年将飙升至208亿美元(CAGR约66.6%)。激光器芯片供应紧张预计持续至2027年。
"光铜并举"还是"光进铜退":铜缆需求拐点辩证分析
市场上对铜缆前景存在两种截然对立的叙事:一种认为光互联将全面替代铜缆("光进铜退"),另一种认为AI服务器铜缆用量持续增长。真实情况比任何一种简单叙事都更复杂。
短期(2025-2027年):铜缆需求仍在上行。NVIDIA CEO黄仁勋在GTC 2026上明确为铜缆"正名",展示GB200 NVL72机架内超过2英里(约3.2公里)的高速铜缆时表示:"我们需要更多的铜缆产能。"他明确纠正了市场此前的"光进铜退"预期,将互联架构定调为"铜缆纵向Scale-up,光纤横向Scale-out"的双轨并行结构。在当前的Blackwell架构中,机架内GPU通过NVLink铜缆互联(零功耗、低延迟、高可靠),机架间通过光纤和交换机互联——铜缆在机架内的地位短期内不可替代。GB300服务器单机铜缆用量较前代增长50%,这使得2025-2027年全球高速铜缆需求处于上行通道。
中期(2028年前后):技术拐点显现。然而,当SerDes速率从224G向448G演进时(对应NVIDIA 2028年的Feynman平台),铜缆在机架内的传输距离将进一步缩短,无源铜缆可能仅支持数十厘米的有效距离。这一物理极限将迫使部分机架内互联从铜缆转向光互联(CPO或近封装光学)。NVIDIA在GTC 2025上发布的Spectrum-X和Quantum-X硅光交换机,以及GTC 2026上展示的Kyber光电一体化封装方案,均指向光互联向机架内渗透的技术准备。2028年前后将成为"光入铜域"的真正转折点。
长期(2029年以后):光铜边界重新划定。随着CPO和近封装光学方案的成熟,光互联将从机架间向机架内、从交换机侧向计算卡侧持续渗透。铜缆的适用范围将逐步收窄至封装体内部和板级极短距离互联。但铜缆不会完全消失——在毫米级距离上,铜互联的成本、功耗和可靠性优势是光互联难以匹敌的。
辩证结论:铜缆在2026年并未进入需求下行通道——恰恰相反,AI服务器出货量增长和单机铜缆用量增加正在推动铜缆需求创新高。但投资者需要关注的是,铜缆需求的增长窗口是有时间边界的:2028年的Feynman平台和448G SerDes将开始侵蚀铜缆在机架内的应用场景。对于铜缆产业链企业而言,当前的高景气度是确定的,但"光铜并举"终将演变为"光进铜退"——只是这个转折点比市场此前预期的更晚(2028年而非2026年),且过程是渐进式而非断崖式的。
供应链瓶颈与风险提示
当前光通信产业链面临几个关键供应瓶颈:激光器芯片供应紧张——无论是EML还是CW激光器,高速品类(100G EML、100mW级CW)均处于供不应求状态,磷化铟衬底供应受限和产能周期叠加需求爆发,缺口预计持续至2027年;CPO技术采用节奏不确定——CPO的规模化部署取决于良率、可维护性和供应链成熟度,任何一个环节的延迟都可能影响光互联向机架内渗透的时间表;地缘政治因素——半导体设备和先进工艺的出口管制可能影响国内光芯片和交换机芯片企业的技术追赶节奏。
九、总结与展望
服务器互联正在经历一场从芯片到数据中心的系统性变革。在芯片层面,UCIe 3.0将chiplet互联速率提升至64 GT/s,为异构集成提供了标准化基础。在节点层面,NVLink 5.0的1,800 GB/s带宽已将72-GPU机架构建为单一计算域,NVLink 6.0将在Rubin平台上再次翻倍。在总线层面,PCIe 7.0的128 GT/s为AI加速卡和高速网络设备提供了充足的I/O带宽。在集群层面,以太网正在以Ultra Ethernet标准挑战InfiniBand的传统霸主地位。
物理层方面,224G SerDes正在进入商用部署,它与铜缆、光模块、LPO和CPO的技术路线交织,构成了一张复杂的技术选择矩阵。铜缆在机架内短距场景中仍具不可替代的成本和功耗优势,但其适用范围正随SerDes速率的提升而持续收窄。光模块从800G向1.6T演进的过程中,LPO架构的兴起标志着光电分界面正在从模块内部向主机ASIC侧迁移。而CPO作为终极形态,正在从概念验证走向早期商用,预计在2028年后进入规模化部署。
从产业链角度看,国内企业在光模块和光器件环节已建立全球领先地位,中际旭创、新易盛和天孚通信的2025年业绩均验证了这一判断。在光芯片和交换机芯片等高壁垒环节,源杰科技和盛科通信代表了国产替代的方向,但与国际领先水平仍存在需要时间弥合的差距。
对于AI算力基础设施而言,互联不再仅仅是"连接",而是与计算、存储并列的三大核心支柱之一。未来几年,谁能在互联的带宽密度、能效比和系统集成度上取得突破,谁就有可能定义下一代AI基础设施的技术范式。
免责声明:本文仅为技术研究和行业分析,不构成任何投资建议。文中提及的公司名称仅用于技术方案说明。
数据来源说明:文中市场数据分别引用自Cignal AI(2025年光模块出货数据)、Dell'Oro Group(2025年网络交换机市场数据)、IDTechEx(2025年12月CPO市场预测)等公开信息。企业财务数据引用自各公司2025年年报或半年报公告,如未特别标注则为截至2025年底的最新公开数据。
