 夜雨聆风
夜雨聆风往期推荐:
文献分享:自动化深度学习用于超声视频中局部肝病变检测,一项多中心研究
文献分享:基于多参数 MRI 的临床、影像组学、深度学习和机器学习集成分析用于预测局部晚期直肠癌肿瘤增殖和预后
文献分享:多尺度空间上下文建模肿瘤内异质性,以预测乳腺癌对新辅助治疗的反应
文献分享:乏氧相关和免疫表型相关融合模型用于TACE治疗的肝细胞癌的非侵入性预后预测:一项多中心研究
人工智能生成的在精神病学背景下描绘患者使用聊天机器人的情景案例的评估
背景
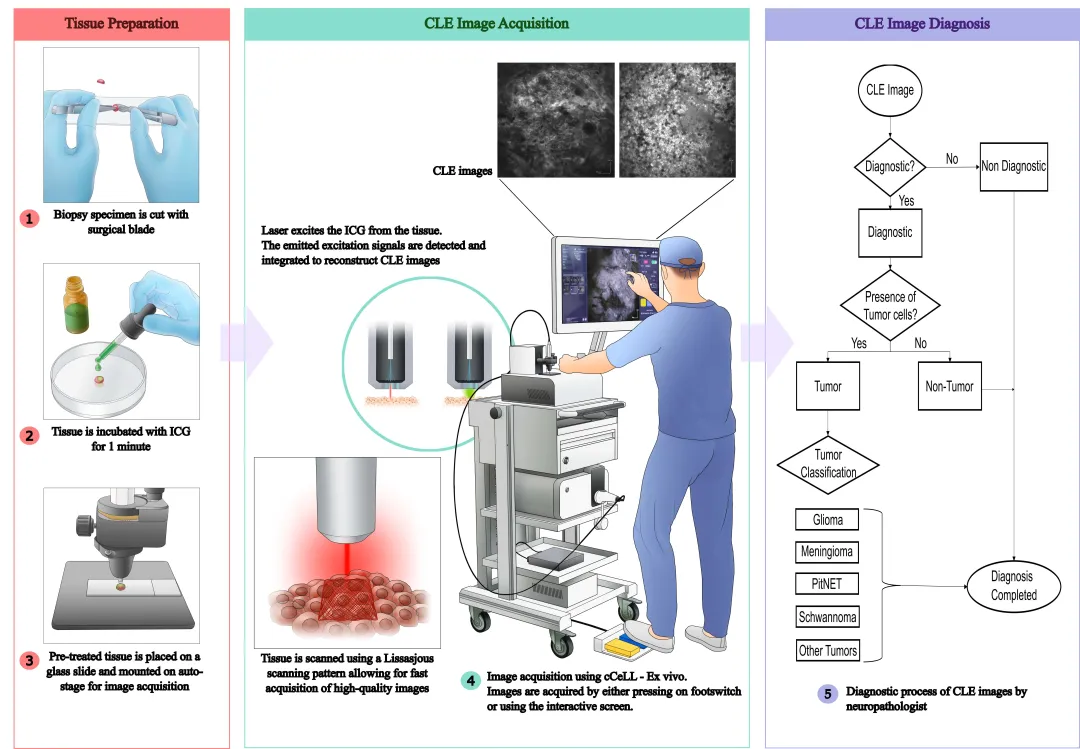
颅内肿瘤术中快速病理诊断对手术决策至关重要:既影响是否调整切除策略,也与保证“最大安全切除”相关,尤其是在高等级胶质瘤及转移瘤等需要评估肿瘤边界/浸润范围的情境中。 目前临床上主要依赖冷冻切片(Frozen section, FS),其确实是标准方案,但存在两类现实瓶颈:一是诊断周转时间通常需要约 20–30 分钟,可能拖慢术中决策(尤其当需要评估多个取材点时);二是存在物流与资源约束(标本需转运至病理科、且需有病理医师/病理团队待命)。因此,研究者希望找到一种能更接近“实时”的术中诊断平台。
共聚焦激光显微内镜(Confocal laser endomicroscopy, CLE)通过对含荧光染料处理后的组织进行快速高分辨成像实现图像式诊断,并且在该研究中采用了 ICG(吲哚菁绿)荧光方案,具有既往神经外科安全性基础。该研究在此基础上进一步引入了用于辅助诊断的 AI 模型,目标是同时提升诊断效率与工作流可用性。
方案设计
这项研究是一个**多中心、前瞻性、评估者盲法(assessor-blinded)**的临床试验,用于证明 CLE 相对 FS 的非劣效性,并在完成诊断性能评估的同时开发并验证一个基于 CLE 图像的 Swin Transformer 架构的 AI 分析模型。
从试验规模与抽样/排除机制看,设计要点包括:
入组与分析集
1.设定了为证明非劣效性所需的最小样本量:基于
1.显著性水平 ( \alpha = 0.05 )
2.检验功效 (1-\beta = 0.9)
3.非劣效界值(non-inferiority margin)为 5%
2.最小需要 445 份活检(biopsies)。
3.最终入组:504 份活检 / 406 例患者。
4.形成最终全分析集(FAS):461 份活检 / 376 例患者,满足并超过最小样本量。
5.排除原因(共 43 份活检)包括:
1.触发排除标准(4)
2.CLE 探头或 ICG 染料相关技术问题(5)
3.标注错误(2)
4.永久切片(PS)结果不清(2)
5.缺失数据(30,例如 CLE 图像不足或 FS 结果缺失)
取材来源与组织学谱系
6.活检部位分布:肿瘤核心占多数(382/461, 82.8%),其次为肿瘤边缘(47/461, 10.2%),正常脑组织(32/461, 6.9%)。
7.病理诊断类别:包括 meningiomas、gliomas、PitNET、schwannomas、其他肿瘤(other tumors,包含转移瘤/颅咽管瘤/淋巴瘤等)、以及非肿瘤(non-tumor)。
8.CLE 在外显部位取材后以**离体(ex vivo)**方式成像并与 FS/PS 对照。
CLE 与 FS 的比较端点与统计思路
1.主要比较指标:肿瘤检出层面的诊断准确度(accuracy),同时报告灵敏度(sensitivity)与特异度(specificity),并通过非劣效检验框架确认 CLE 不劣于 FS。
2.还提供了一致性/错误归因:如 CLE 与 FS 的一致率(concordance rate),以及双方各自“纠正对方错误”的病例数。
3.针对肿瘤/非肿瘤取材比例不均衡的问题,研究者进行了灵敏度分析(包括 balanced accuracy 等指标)。
CLE 的工作流与质量控制
1.该研究提到 CLE 的离体流程中,ICG 染料孵育仅需 1 分钟,使得整体周转时间显著缩短。
2.同时,研究者观察到 CLE 成像质量与操作者熟练度相关:9 份活检因图像质量不足被归为非诊断(过亮/过暗导致肿瘤特征不清、或因“黏附/脆弱组织”造成伪影)。
3.为降低这种差异,他们采用了**薄的单层包裹(single-layer wrap)**策略用于改善部分黏附/脆弱组织的成像,并通过培训(workshop)缩短新手学习曲线。
4.另一个层面是解读一致性:对神经病理学读片者进行了结构化培训;培训后专家与新手之间的解释一致性良好(文中给出 κ 值)。
AI 模型设计与集成目标
1.研究开发了一个基于 CLE 图像的 AI 诊断模型,采用 Swin Transformer 的层级框架(hierarchical framework)。
2.AI 的目标任务至少包含两级信息:
1.肿瘤/非肿瘤检测(tumor detection)
2.活检亚型/分型诊断(biopsy subtype diagnosis)
3.该研究报告了 AI 的诊断准确度指标,并强调其与 CLE 平台结合的潜力。
结果解读(性能与时间)
总体准确度与非劣效性
1.CLE 检出肿瘤总体诊断准确度:0.94(433/461,95%CI 0.91–0.96)
2.FS 的总体诊断准确度:0.92(422/461,95%CI 0.89–0.94)
3.准确度差值(CLE − FS):-0.02(95%CI -∞ 到 0.0096)
4.关键解释点在于:准确度差的置信区间上界未超过 5% 的非劣效界值,因此统计上支持 CLE 相对于 FS 非劣效。
5.McNemar 检验 P=0.14,进一步支持两种方法在此层面的总体差异并不显著。
灵敏度与特异度
1.灵敏度:CLE 0.96 vs FS 0.95(P=0.40,差异不显著)
2.特异度:CLE 0.79 vs FS 0.68(P=0.31,差异不显著) 这意味着在区分“有肿瘤/无肿瘤”方面,CLE 与 FS 的综合表现接近,并且在特异度上呈现更好的点估计。
一致性与互补纠错
1.CLE 与 FS 一致率:0.90
2.CLE 纠正 FS 误判:29 例(6.3%)
3.FS 纠正 CLE 误判:18 例(3.9%)这种“互补性”通常提示两种方法受限方式不同(例如影像信息类型、采样点/读片标准等),而不是简单的同质错误。
周转时间(工作流收益)
1.CLE 的中位周转时间(turnaround time):5 分 56 秒
2.FS 的中位周转时间:20 分钟
3.差异具有统计学意义(文中给出 P < 0.001) 解释上,研究认为 CLE 更快与其工作流程更简化有关:ICG 孵育只需约 1 分钟,同时避免了标本转运与病理科/团队等待造成的延迟。并进一步提出若可在术中区域部署设备、或实现图像传输到读片端,时间还可继续压缩。
肿瘤亚型/分型层面
1.文中指出 CLE 在不同肿瘤子类型上的表现总体与 FS 可比,但对某些分级(如中低级别胶质瘤与正常脑/胶质增生的区分)存在与传统 FS 类似的困难。
2.“other tumors”组的异质性较高,属于解释时需要更谨慎的部分(因为包含多种病种,模型/诊断判别可能在不同类别上性能不均)。
AI 模型性能(辅助诊断潜力)
1.AI 在肿瘤检测准确度:0.94
2.AI 在活检亚型诊断准确度:0.88结果总体“看起来有效”,并且与 CLE 的整合方向一致;但仍需要放在临床落地验证的语境中看待(例如跨中心外推、真实世界部署、标注一致性等)。
可改进点(基于研究内容的“下一步”)
结合文中讨论与试验过程的暴露问题,可以归纳出几类最直接的改进方向:
降低“成像质量依赖操作者”的影响
1.当前非诊断病例中有相当部分来自图像过亮/过暗或分辨率不足,以及黏附/脆弱组织导致的伪影。
2.虽然薄包裹策略与培训改善了一致性,但仍建议进一步把“图像质量控制”做成标准化流程,例如:自动曝光/亮度校准、伪影识别与重拍机制、以及对不同组织黏附性的预设参数。
从 ex vivo 向 in vivo 进一步演进
1.研究指出:离体流程仍需要组织处理与转运/操作;若能实现探头在体使用,才能真正更接近实时诊断。
2.但文中也提示体内场景会引入额外挑战:染料方案标准化、运动伪影抑制等。后续改进需要专门针对这些工程/生物学变量设计验证。
建立图像传输与远程读片的闭环(telepathology)
1.文中提到如果 CLE 图像可以直接传输给神经病理学读片端,并配套受保护的数据传输软件/平台,能够在没有现场病理资源或夜间 FS 不可用时形成重要替代方案。
2.因此下一步应关注端到端系统验证:延迟、丢包、隐私合规、以及远程读片一致性是否维持在可接受范围。
AI 的临床验证与可解释性
1.AI 已给出较高准确度点估计,但未来需要进一步:
1.更严格的跨中心外推与盲法评估(避免模型对数据分布“适配”)
2.与临床决策路径的耦合验证(例如 AI 作为“二读”还是“独立判读”时的增益)
3.结合可解释/置信度机制,减少在低质量图像或“other tumors”高异质类别上的误判风险。
扩大对“难分类场景”的针对性训练/采样
1.中低级别胶质瘤与正常脑/胶质增生的区分困难,以及 other tumors 的类别异质性,是已被点到的短板来源。
2.后续可考虑:在这些难点类别上增加有效样本、优化取材策略(同一病灶的多点/边界采样一致性)、以及让模型训练明确覆盖这些“临床常见但难”的判别任务。

