 夜雨聆风
夜雨聆风
点击蓝字,关注我们

打破摩尔定律的“天花板”:先进封装如何让AI芯片突破极限?
当晶体管的尺寸微缩逼近物理极限,一场围绕“如何把芯片拼起来”的静默革命,正在决定下一个十年AI算力的最终形态。
2016年,AlphaGo击败李世石,宣告了AI时代的到来。彼时,支撑其运算的芯片,其性能提升尚能遵循摩尔定律的节奏——每两年晶体管密度翻一番。
然而,当时间来到2025年,为训练GPT-5这类万亿参数大模型而设计的AI芯片,其算力需求正以每年翻数倍的速度狂飙,摩尔定律的“钟摆”却肉眼可见地慢了下来。
单纯依靠晶体管微缩这条老路,已经无法满足AI对算力近乎贪婪的渴求。
于是,工程师们的目光从“如何把晶体管做小”,转向了“如何把芯片拼得更好”。先进封装,这个曾经被视为制造流程末端“打包”环节的技术,一跃成为决定AI算力上限的关键变量。
01 算力困局,当摩尔定律踩下刹车
要理解先进封装为何如此重要,得先看看AI芯片到底“饿”到什么程度。
你知道吗?一颗为AI训练设计的高端芯片,其内部超过70%的功耗和超过60%的延迟,并非来自核心的计算单元,而是消耗在数据搬运上。
这就是著名的“内存墙”问题:计算核心的速度越来越快,但数据从存储单元(如高带宽内存HBM)搬运到计算核心的速度,却严重滞后。

传统上,计算核心和内存是两颗独立的芯片,通过PCB板上的导线连接。这就好比一个拥有超级大脑的数学家,但他的所有参考书都存放在城市的另一座图书馆里,每次思考问题,他都需要开车穿过拥堵的市区去取书,效率可想而知。
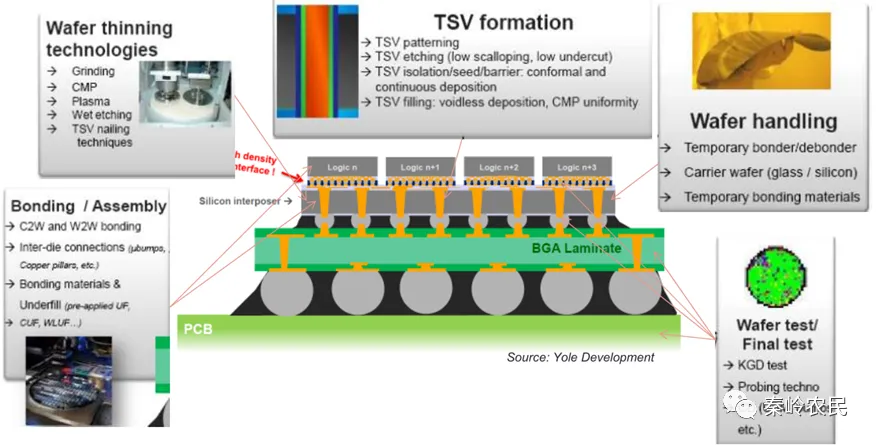
为了解决这个问题,行业最初采用了 “2.5D封装” 。这就像给数学家和图书馆之间修了一条专属高速公路(硅中介层),把两者并排放在同一个“底座”上,缩短了通勤距离。
台积电的 CoWoS 技术正是这一路径的集大成者,它将逻辑芯片和多颗HBM内存集成在一个硅中介层上,大幅提升了带宽。
根据台积电2026年1月发布的《先进封装技术白皮书》显示,其最新一代CoWoS技术,可实现高达8颗HBM3e内存与一颗超大尺寸逻辑芯片的集成,总带宽突破9TB/s。
这已经是一个惊人的数字。但对于下一代AI芯片而言,这还不够。
当芯片设计者试图把更多计算核心、更大容量的内存塞进系统时,他们遇到了新的天花板:封装本身的物理极限。
硅中介层的尺寸受限于光罩尺寸和良率,难以无限扩大;并排放置的芯片,其互连密度和信号传输距离也面临瓶颈。
更重要的是,热。当多颗高功耗芯片紧密排列,热量堆积如同一个微型火山,散热成为比性能更优先的生死问题。
02 三维突围,从“平房”到“摩天大楼”的芯片革命
既然平面(2.5D)的扩展遇到瓶颈,工程师们很自然地想到了一个方向:向上,向三维空间要性能。
这就是 “3D封装” 的核心思想。不再满足于把芯片并排摆放,而是像盖摩天大楼一样,将不同功能的芯片(如计算核心、缓存、I/O)垂直堆叠起来,并通过穿透硅晶圆的微型垂直互联通道直接连接。
这种思路彻底改变了芯片的架构哲学。
想象一下,之前数学家需要去图书馆,后来图书馆搬到了隔壁(2.5D)。现在,3D封装相当于把图书馆的每一层楼都改造成一个专业书房,并且用高速电梯(硅通孔,TSV)直接连通到数学家所在的楼层。他需要什么资料,电梯直达,瞬间获取。
这种“立体集成”带来了几个革命性的优势:
第一,极致的互连密度与带宽。 平面互连的I/O数量受限于芯片边缘,而垂直互连的TSV可以遍布整个芯片面积。这就像从只能在边境口岸通关,变成了全国任何一个点都能直飞,通信能力指数级提升。
第二,显著的功耗降低。 垂直互连的路径长度是以微米甚至纳米计,比传统PCB上厘米级的走线短了几个数量级。信号传输所需能量大幅下降,这对于功耗动辄数百瓦的AI芯片至关重要。
第三,异质集成的终极形态。 AI系统不仅需要通用的计算核心(如CPU、GPU),还需要专用的AI加速器、高速网络芯片、甚至光引擎。3D封装允许使用不同工艺节点、不同材质(硅、化合物半导体)制造的芯片,像乐高一样最优组合。
目前,全球三大半导体制造巨头都在这一领域全力竞逐:
| 互连间距 | |||
| TSV密度 | |||
| 对准精度 | |||
| 集成层数 | |||
| 数据来源 |
从表格中可以看出,台积电在互连密度和集成层数上暂时领先,这得益于其在晶圆级键合技术上的长期积累。而英特尔则强调其混合键合技术能实现极低的互连电阻和电容。
但无论哪条路径,目标都是一致的:将互连延迟和功耗降至最低,打造一个真正“无缝”的异构计算系统。
03 核心战场,HBM与逻辑芯片的“生死相依”
在AI芯片的3D堆叠中,最经典、也最迫切的一对组合,就是逻辑芯片(如GPU) 与高带宽内存。
HBM本身就是一个3D封装技术的杰作。它将多个DRAM芯片通过TSV垂直堆叠,并与一个底层逻辑控制芯片封装在一起,提供了远超传统内存的带宽。

但真正的性能飞跃,发生在HBM与GPU/TPU进行3D堆叠时。这不再是通过中介层“肩并肩”,而是“面对面”甚至“心连心”的融合。
目前最前沿的探索,是将HBM的IO层(负责与外界通信的部分)直接堆叠在逻辑芯片之上,或者反之。这种架构下,数据通路被缩短到极限。
根据三星在2026年第一季度发布的技术路线图,其正在研发的“HBM4”标准,将首次原生支持与逻辑芯片的3D堆叠,目标是将有效带宽在HBM3e的基础上再提升一倍以上,同时将访问功耗降低40%。
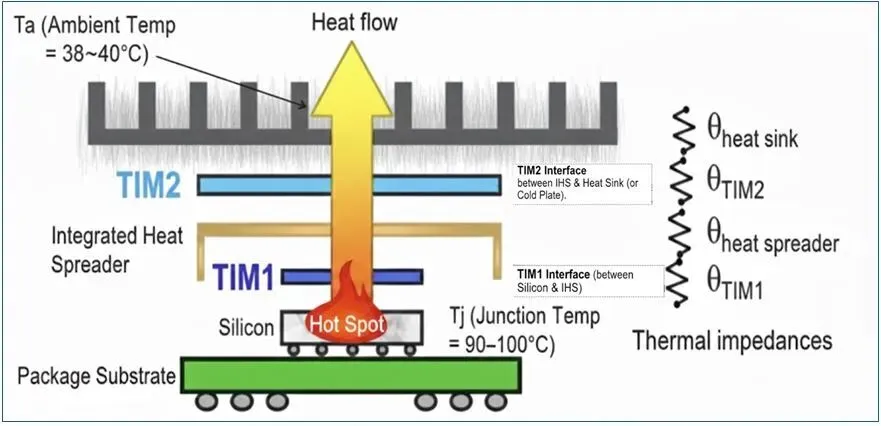
然而,这条路布满荆棘。最大的挑战来自于 “热应力”。
DRAM芯片对温度极其敏感,而GPU/TPU是巨大的发热源。当两者紧密贴合,GPU产生的热量会直接传导至HBM,导致其性能不稳定甚至失效。
工程师们为此绞尽脑汁,发展出复杂的热管理架构:在芯片间嵌入微米级的散热柱(Thermal Interposer)、采用导热系数极高的界面材料、设计复杂的三维微流道进行液冷。
这不仅仅是封装问题,更是一个涉及材料科学、流体力学和精密制造的系统工程。谁能更好地解决3D堆叠下的散热问题,谁就能在下一代AI芯片的竞赛中占据制高点。
04 未来蓝图,面板级封装与产业链重塑
当芯片堆叠的层数越来越多,尺寸越来越大,传统的基于圆形硅晶圆的封装方式,其效率低、成本高的缺点愈发凸显。
于是,一个更激进的构想被提出:面板级封装。
顾名思义,就是像生产液晶显示器面板一样,在更大尺寸的方形玻璃或树脂面板上进行芯片的集成与封装。这能极大提升生产效率,降低单位成本。
台积电将其面板级封装技术命名为“CoPoS”,并视其为继CoWoS之后的下一个战略重点。
根据行业分析机构Yole Développement在2025年第四季度的报告预测,面板级封装市场将从2025年的约35亿美元,增长至2028年的超过120亿美元,年复合增长率高达50%以上。
而整个先进封装市场,在AI、HPC等需求的强力驱动下,规模将在同期达到820亿美元。
这不仅仅是技术的演进,更是产业链价值与格局的重塑。
过去,封装测试是相对独立和分散的环节。如今,随着CoWoS、SoIC、Foveros等技术与前道制造工艺(如光刻、刻蚀)的绑定越来越深,台积电、英特尔、三星等制造巨头正在将封装能力深度整合,形成“设计-制造-封装”一体化的超级护城河。

对于其他厂商,尤其是中国的半导体产业而言,这既是挑战也是机遇。挑战在于,顶级先进封装的技术壁垒极高,涉及大量Know-how和专利。
机遇则在于,在追赶绝对制程工艺的同时,通过系统级的封装创新,整合相对成熟的工艺芯片,完全有可能在特定应用领域(如自动驾驶、边缘AI)实现性能的弯道超车。
例如,通过将多颗14nm或28nm的国产计算芯片与先进封装的HBM集成,其整体性能可能媲美单一颗采用更先进制程但封装落后的国外芯片。
05 结语
从2.5D到3D,从晶圆级到面板级,先进封装的故事,本质上是一个从“单体智能”到“系统智能” 的进化故事。
它不再追求单个晶体管的完美,而是致力于让不同出身、不同专长的芯片“团队”实现最高效的协作。当摩尔定律在微观尺度上步履蹒跚时,先进封装在宏观的集成尺度上,为算力增长打开了新的平行宇宙。
未来的AI芯片,可能不再是一个我们传统认知中的“方形薄片”,而是一个由计算层、存储层、网络层、甚至光电转换层垂直构筑的微型“立体城市”。
这座城市内部,数据通过纵横交错的纳米级“高速路网”光速流动;而封装技术,就是那位总建筑师,决定着这座城市的格局、效率与最终的高度。
这场静默的革命,正将芯片性能的“天花板”,推向我们此前难以想象的新维度。
