 夜雨聆风
夜雨聆风「智编说AI」漫画科普系列·第六集
把 PDF 变成 XML?先让 AI 做好元数据提取
AI 先整理元数据,编辑再校对把关。
🤔 PDF 扔给 AI,就能生成 XML 吗?

▲ PDF 不能直接变 XML,先把元数据整理准
上集预告已经发出一段时间,其间有读者问智编:PDF 扔给 AI,是不是就能直接生成 XML?这个问题很真实。很多数据规范较好的编辑部已经被 XML、JATS、Crossref、DOAJ 这些词绕晕了,也确实希望少一点复制粘贴。可这里不能急着说“自动生成”。更稳妥的入口,是让 AI 先把论文里的基础信息摘出来:题名、作者、单位、摘要、关键词、基金、DOI……这些元数据整理准了,后面的 XML 才有可靠的源头。
📋 同一批信息,被反复填写
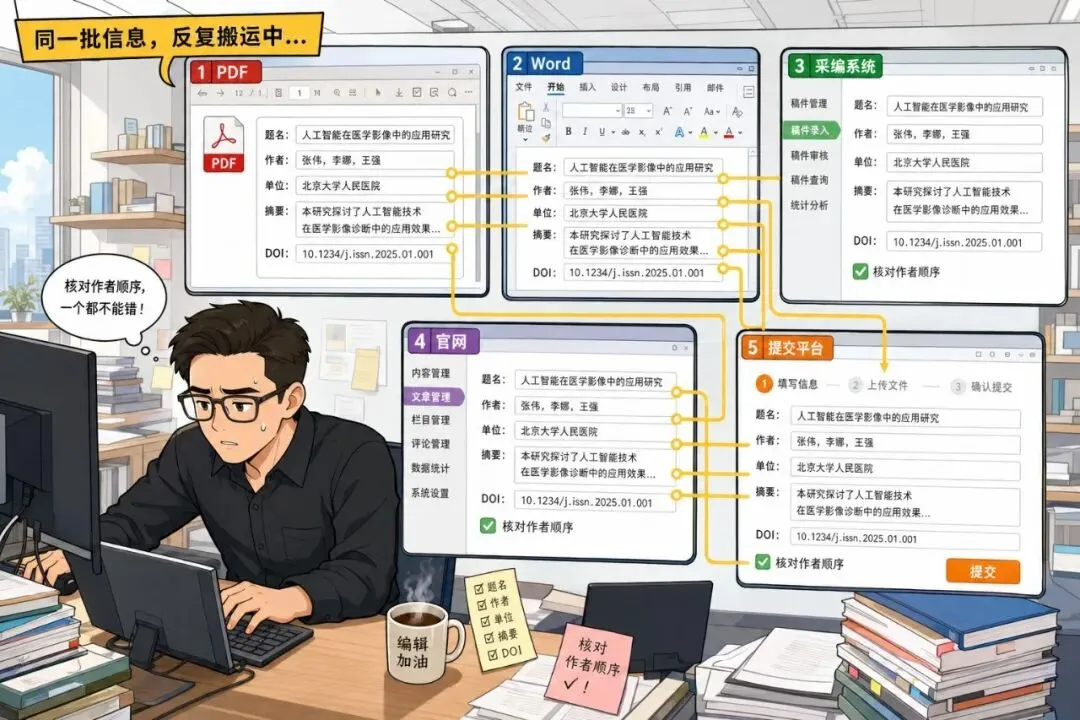
▲ 同一批信息在多个系统之间反复搬运
技术编辑最怕的,不一定是看不懂 XML,而是同一批信息在不同地方来回搬。PDF 里有一遍,Word 稿里有一遍,采编系统里还要填一遍,官网发布、数据库提交又各有格式。题名少一个副标题,作者顺序换了一下,单位编号漏了一个上标,后面都可能跟着出问题。这件事不难,却很耗人;看起来只是复制粘贴,真正麻烦的是反复核对。AI 能切入的,正是这段机械整理工作。
🪪 元数据是论文的身份证

▲ 元数据像论文身份证,源头信息不能写错
所谓元数据,可以先别把它想成代码。它更像一篇论文的身份证:这篇文章叫什么,谁写的,作者来自哪里,讲了什么主题,发表在哪一期,有没有 DOI,基金项目怎么标注。系统识别论文、读者检索论文、平台交换数据、机构统计成果,都离不开这些信息。XML 只是承载元数据的一种结构化方式。编辑真正要守住的,是源头信息准确、完整、能被检查。标签可以交给工具生成,身份证上的信息不能写错。
🧩 AI 先提取,再归类
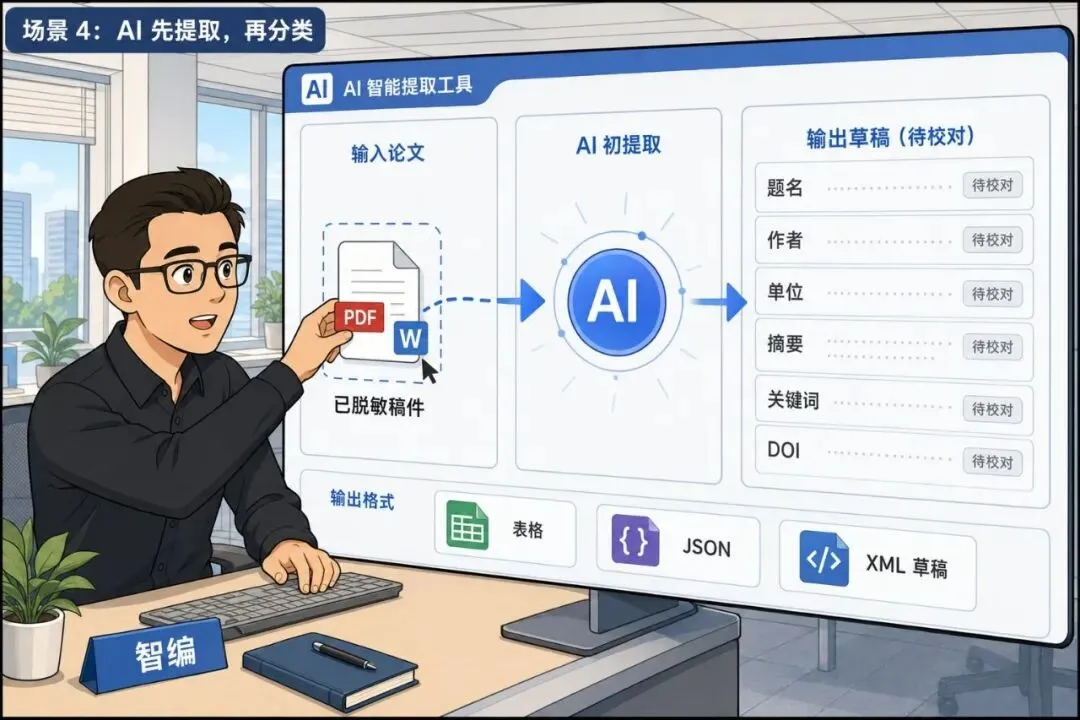
▲ AI 适合先做提取和归类,但输出仍是草稿
AI 比较适合做的,是初步提取和字段归类。比如把论文首页、摘要页、脚注里的信息读出来,整理成表格;也可以按编辑部模板,输出 JSON、CSV 或 XML 草稿。注意,这里的关键词是“草稿”。涉及未发表稿件时,还要沿用上一集说过的安全边界:该脱敏就脱敏,该用合规工具就用合规工具,不要把审稿人信息、作者联系方式、内部处理意见随手传上去。AI 可以帮忙打底,但不能替编辑签字。
🔍 编辑必须校对细节

▲ 编辑校对是结构化传播的质量闸口
AI 提取完,编辑还得回到原文。最容易错的往往不是大标题,而是细节:作者和单位对应错了,基金编号少了一个字符,DOI 里的“0”和“O”混了,通讯作者脚注没识别出来,中英文题名没有对应上,关键词分隔符被改乱。技术编辑的价值,不在机械搬运,而在判断、核验和规范化。这一步不能省。少看一眼,错误可能从元数据表一路带到 XML、官网页面和外部平台。
🌐 XML 只是其中一站
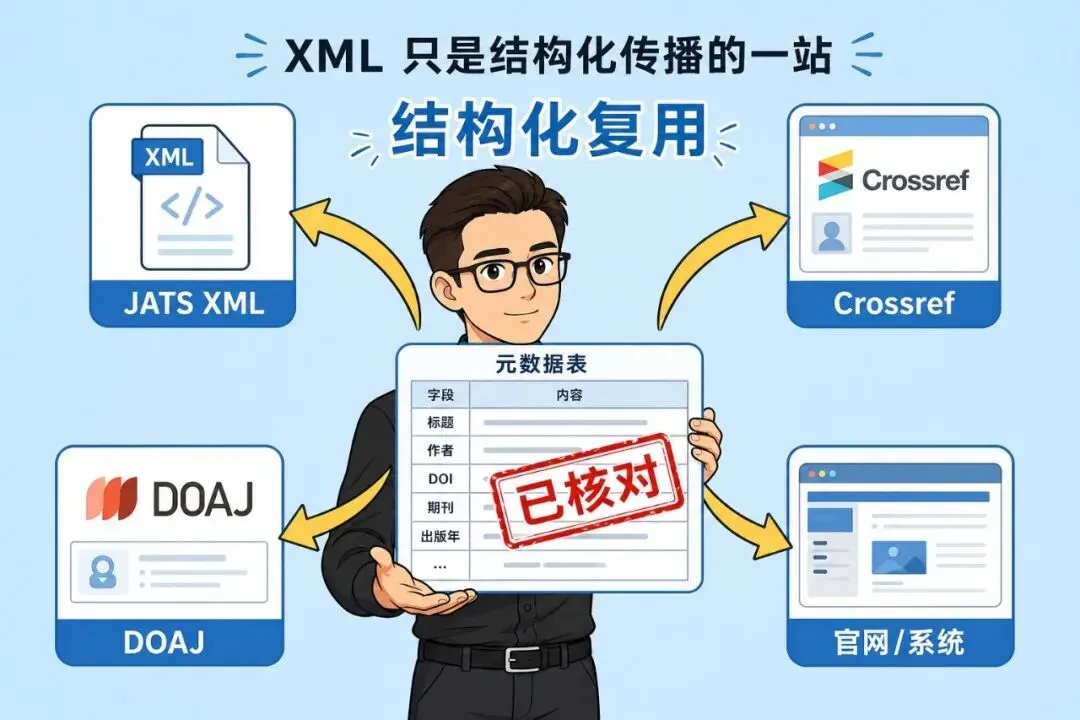
▲ 校对后的元数据,才能稳定流向多个平台
一张校对过的元数据表,不只服务 XML。它还可能流向 DOI 注册、开放获取平台、采编系统、期刊官网、数据库接口。不同平台有各自规则,编辑部不必把每套规则都背下来,但要明白一件事:底层用的仍是那一组结构化信息。源头字段整理得清楚,后续转换、映射和提交会稳很多;源头已经错了,XML 标签再漂亮,也只是把错误包装得更整齐,再传到更多地方。
✅ AI 初稿,编辑确认,系统复用

▲ AI 做初稿,编辑做确认,系统做复用
智编给编辑部设计的流程很朴素:稿件进来后,AI 先做元数据初提取;编辑对照原文和采编记录逐项确认;确认后的字段再做标准化处理,比如作者顺序、单位格式、关键词分隔、基金写法、DOI 书写;随后按需要输出为 XML 草稿、表格或系统字段。AI 做初稿,编辑做确认,系统做复用。这套流程的目标不是削弱技术编辑,而是把人从低价值搬运里拉出来,把精力留给质量把关。
而是让编辑更早发现错误
✨ 金句收束与下集预告

▲ 结构化不是把人拿掉,而是把错误拦住
这一集,智编想留下的一句话是:XML 自动化的起点,不是让 AI 替编辑做决定,而是让编辑更早发现错误。AI 负责把散落的信息先拢起来,编辑负责核对、修正和判断,系统负责接收和复用。对期刊来说,结构化不是炫技,也不是把人拿掉,而是让论文更容易被识别、传播和引用。下一集,我们继续聊一个更贴近案头工作的场景:能不能让 AI 先帮编辑看看参考文献和格式问题?咱们下期见。
「智编说AI」漫画科普系列·第六集 完
敬请期待 👀
