 夜雨聆风
夜雨聆风
上一篇《别再把 RAG 当知识库:用 AutoClaw 搭一套会进化的 Karpathy LLM Wiki》发出后,很多朋友已经把基础流程跑起来了。
但很快,一个问题反复出现:
AutoClaw 为什么一读 PDF 就容易翻车?
有人论文顺序乱了,有人财报表格被拆碎,有人公式没了、图注错位了,扫描件更是直接读不出来。
这通常不是 LLM-Wiki 的问题,也不是 AutoClaw 不行。
真正的问题在入口:
PDF 解析这一步,已经把原材料弄坏了。
LLM-Wiki 的核心不是“临时问答”,而是在 ingest 阶段把资料编译成 source、concept、analysis、索引、日志和 QA。入口错了,后面生成得再漂亮,也是在错误原料上加工。
所以这篇只解决一个关键问题:
给 AutoClaw 装上 PaddleOCR 文档解析和 OCR 技能,让 LLM-Wiki 先读准,再沉淀。
很多人最开始用 pdfplumber 读 PDF。它对文本层干净、排版简单的文件很好用,但真正放进 LLM-Wiki 的资料往往没这么乖。
更常见的是:
• 论文:双栏、公式、图表、参考文献 • 财报研报:跨页表格、指标口径、附注说明 • 手册资料:截图、流程图、代码块、复杂目录 • 扫描件:没有文本层,本质是一张张图片
普通文本提取最容易出四类问题:阅读顺序错、表格结构丢、公式符号坏、扫描件失准。临时问答还能忍,但 LLM-Wiki 会把结果写进 pages/,后续继续引用和回写。入口错误会变成长期错误。
遇到 PDF 翻车,很多人的第一反应是继续改 prompt。但如果解析层已经失败,prompt 没法凭空还原原文结构。
正确思路是:
先让 AutoClaw 具备更强的文档解析能力,再让 LLM-Wiki 做知识编译。
这次安装两个 PaddleOCR Skills:
paddleocr-doc-parsing:文档解析
适合复杂 PDF、论文、财报、研报、白皮书和产品手册。重点是保留标题、段落、阅读顺序、表格、公式、图表和版面结构。
paddleocr-text-recognition:文字识别
适合图片、照片、截图、扫描件和图片型 PDF。
一句话:
复杂文档走文档解析,图片文字走文字识别。
原来的 LLM-Wiki 流程是:把资料放进 raw/,让 AutoClaw 按 SCHEMA.md 生成 source、concept、analysis、index、log 和 QA。

当 raw/ 里是 PDF、扫描件或图片时,中间要补一层高精度解析:先用 PaddleOCR 读准结构,再让 LLM 理解、压缩、链接和回写。
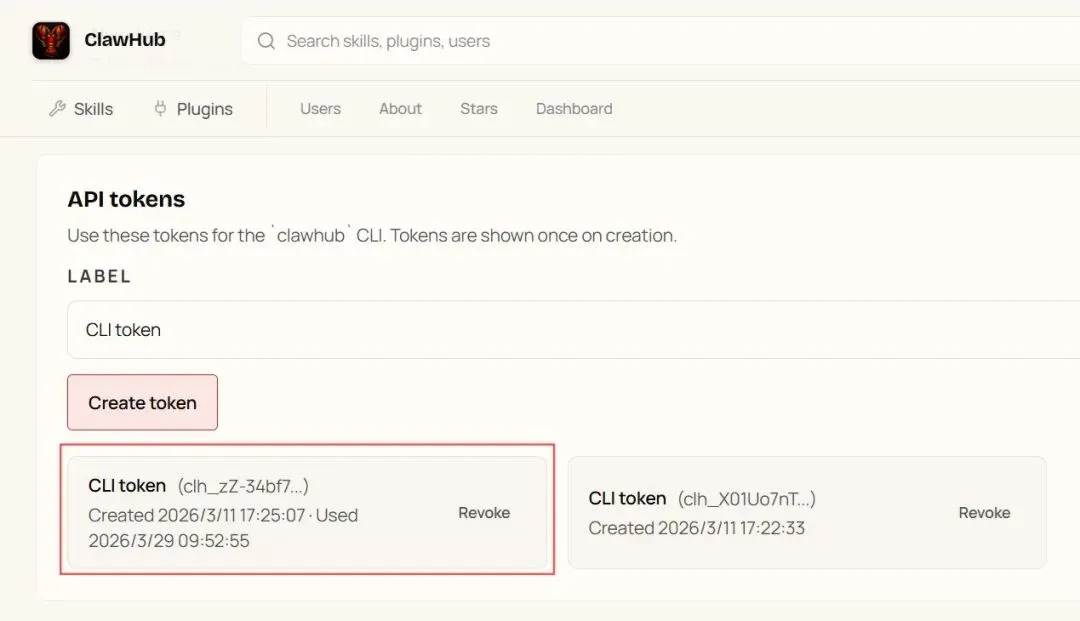
1. ClawHub Token
访问 https://clawhub.ai,登录后进入 Settings,创建 API tokens。它通常以 clh_ 开头。
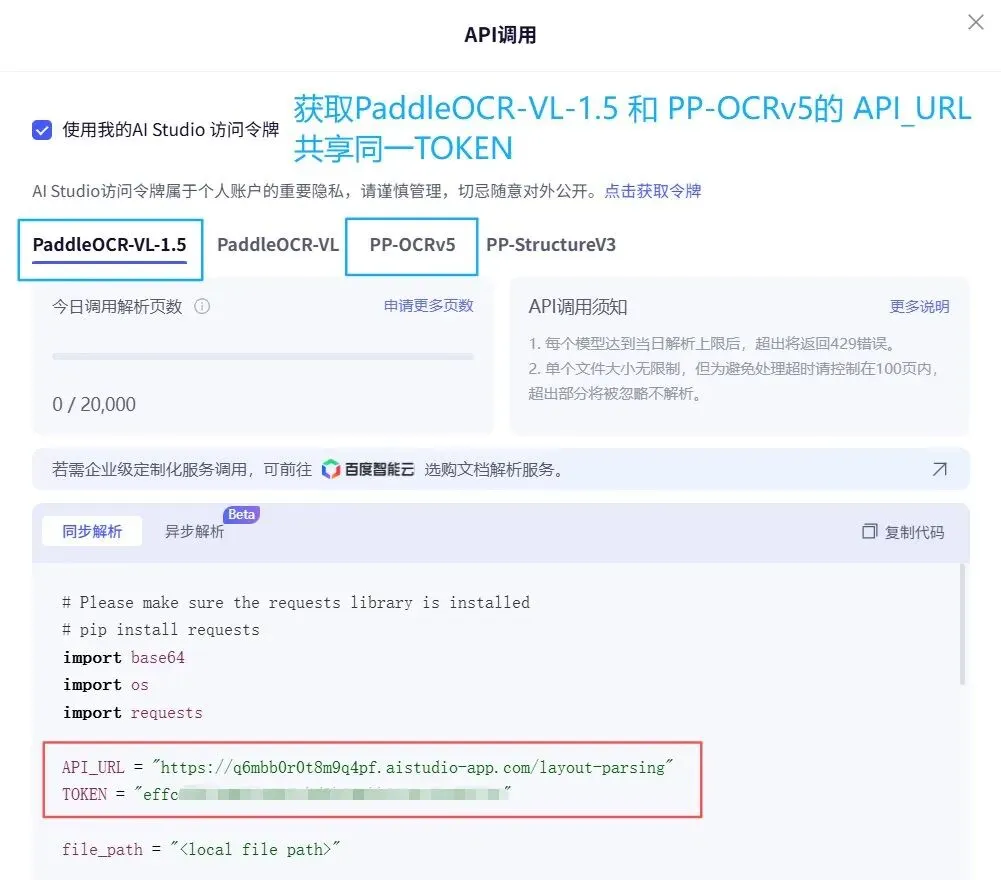
2. PaddleOCR API 信息
访问 https://www.paddleocr.com,进入模型服务页面,复制三项信息:
• PaddleOCR-VL-1.5 的 API_URL • PP-OCRv5 的 API_URL • PaddleOCR 官网 的 Access Token
文档解析 API 给复杂 PDF 用,文字识别 API 给图片和扫描件用,Access Token 两个技能共用。
克隆提示词仓库:
“git clone https://github.com/AIwork4me/llm_wiki_prompt.git”
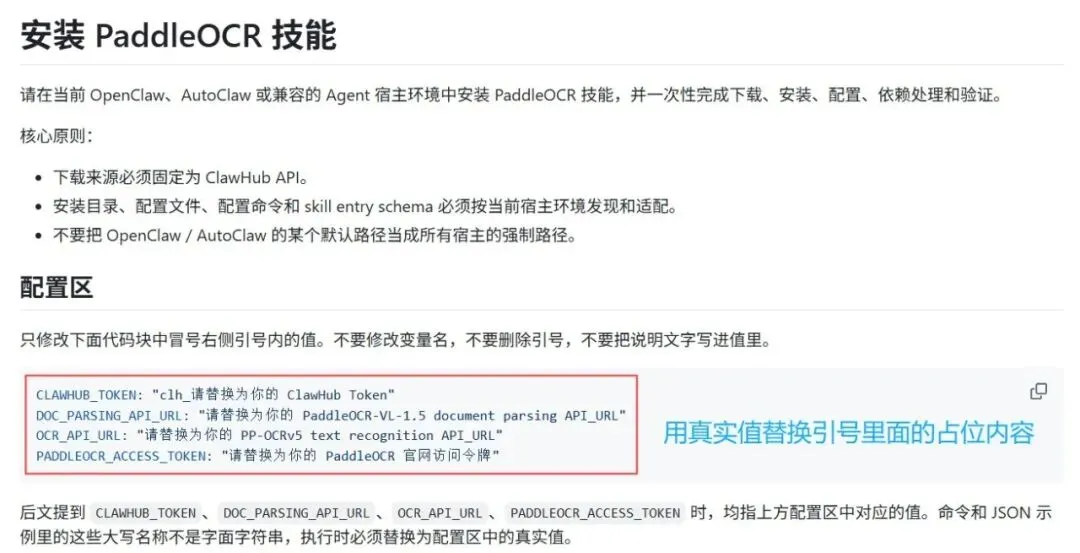
打开: prompts/install_paddleocr_skills_prompt.md
只改开头“配置区”里引号内的值:
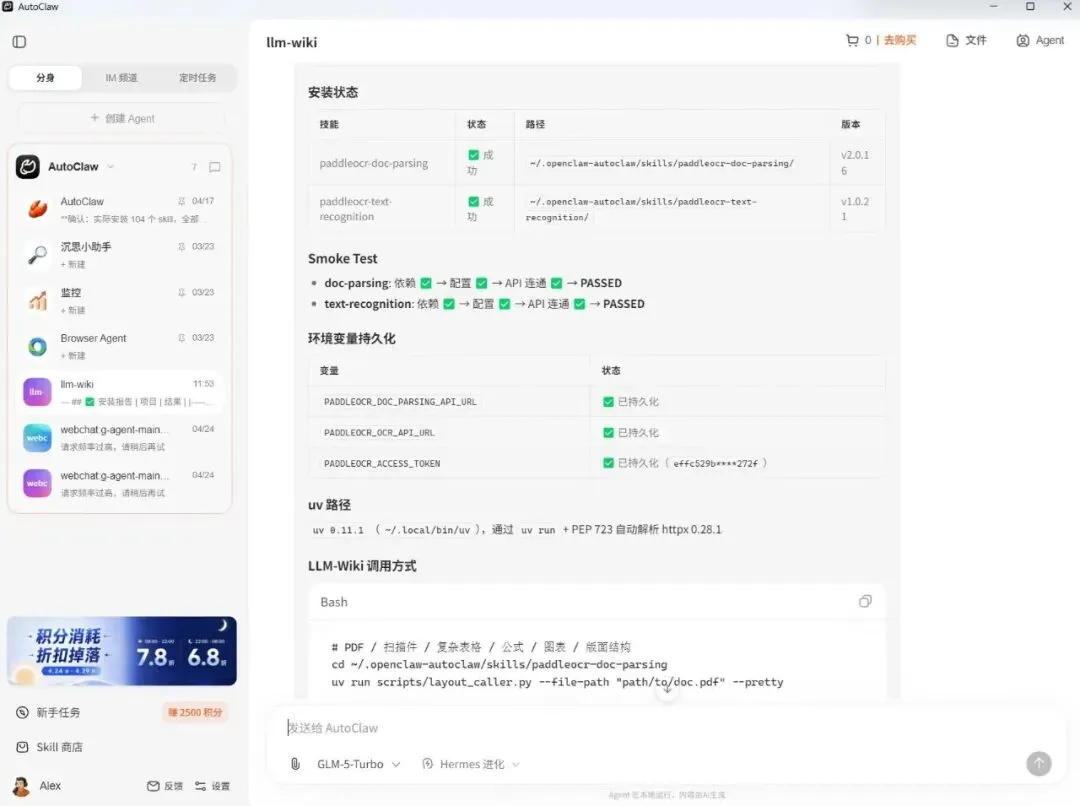
然后,把整份提示词发给 AutoClaw。
看到安装成功、配置持久化、smoke test 通过,就说明 PaddleOCR 技能已经安装成功。
让 LLM-Wiki 真正用上它
技能装好后,不要只说 "请 ingest raw/articles/attention.pdf",而要明确分两步:
"请先使用 paddleocr-doc-parsing 解析 raw/articles/attention.pdf, 尽量保留章节、阅读顺序、表格、公式、图表标题和图注。 解析完成后,再按当前 SCHEMA.md 执行 LLM-Wiki ingest: 创建或更新 source 页,提炼 concept / entity / analysis, 同步 index.md,在 log.md 记录,并生成 qa-reports/self-check。"
如果处理截图或扫描件:
"请使用 paddleocr-text-recognition 提取 raw/images/xxx.jpg 的文字, 再把识别结果作为 raw source 写入 LLM-Wiki。 QA 中说明原始文件、使用技能、低置信区域,以及哪些内容是模型综合。"
重点是:不要直接“总结 PDF”。先解析,再 ingest;先保真,再压缩。
LLM-Wiki 最重要的不是“自动生成很多 Markdown”,而是让资料成为可追溯的 source,更新已有概念,修正旧结论,并在未来继续被复用。
这一切都有一个前提:
原始资料必须先被读准。
PaddleOCR 给 AutoClaw 补上的,正是这个前提。
PDF 读准了,source 页才稳;source 页稳了,concept 页才不会乱;query-writeback 才真的有复利。
从现在开始,把资料放进 raw/,让 AutoClaw 先用 PaddleOCR 读懂它,再按 SCHEMA.md 编译进 wiki。
好资料进来,好结构留下,好知识越用越多。
• PaddleOCR Agent Skills 文档:https://www.paddleocr.ai/latest/version3.x/deployment/skills.html • ClawHub Document Parsing:https://clawhub.ai/bobholamovic/paddleocr-doc-parsing • ClawHub Text Recognition:https://clawhub.ai/bobholamovic/paddleocr-text-recognition
