 夜雨聆风
夜雨聆风本文运用qwenVL模型反推图片、视频的关键词 你可以输入请用中文描述他就会给你输出中文提示词(默认出来是英文的提示词)
本文不用魔法,也可以安装
我一个程序员都得研究半天的东西 我真的不敢想象普通人玩comfyui的时候,是多么绝望。 你如果跟着我的博文搞下去 基本很难卡到问题。 如果你在别的地卡到问题才看到我这篇 没事你可以直接在下面找到答案直接找答案,我都是一路踩过来的 
A ComfyUI-Manager upgrade required报错-解决方案 python pip install -r 报错-解决方案 python llama_cpp_install.py报错-解决方案 ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。解决方案
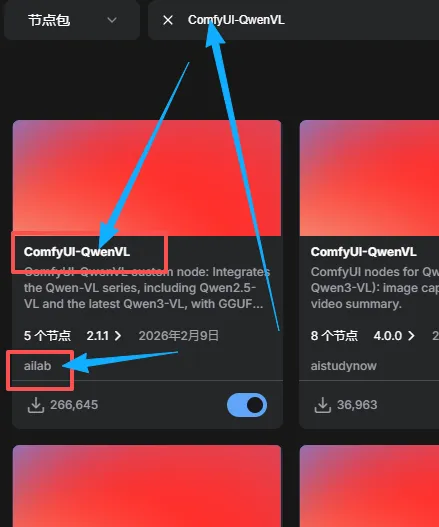
ComfyUI-QwenVL(https://github.com/1038lab/ComfyUI-QwenVL)
安装 llama-cpp-python(https://github.com/1038lab/ComfyUI-QwenVL/blob/main/docs/LLAMA_CPP_PYTHON_VISION_INSTALL.md)
llama-cpp-python下载库 https://github.com/JamePeng/llama-cpp-python/releases?page=1
Qwen3-VL-8B-Thinking-GGUF(https://hf-mirror.com/Qwen/Qwen3-VL-8B-Thinking-GGUF)
反推、打标签的意思是很好理解 比如别人照片拍得很漂亮。 你选中一张你的照片,想让ai帮你生成一张和他风格、角度、姿势等一样额照片 脸是你的。 那收集照片信息的操作就叫图片反推,打标签。 模型不同、版本不同,精度不同,都会影响最后出来的结果。 我选qwenVL作为首选因为他文档全,步骤命令,而且具备图片和视频解析的能力 下面我列出26年4月29号为止,新一代的反推模型(开源与否自行查证,我也是网上收集来的。)
▍PART 流程简要
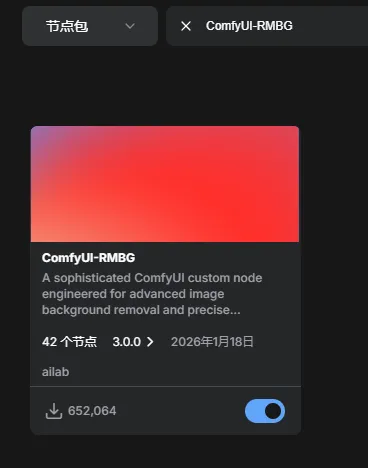
安装插件:菜单 → 管理扩展功能 → 分别安装
ComfyUI-QwenVL、ComfyUI-RMBG、comfyui-videohelpersuite。导入工作流并准备模型文件夹:进入 ComfyUI 安装目录下的
custom_nodes\ComfyUI-QwenVL\example_workflows,将任一.json工作流拖入 ComfyUI 界面,立即Ctrl+S保存。然后在models目录下新建LLM\Qwen-VL\Qwen3-VL-2B-Instruct文件夹(根据工作流默认模型名调整)。下载模型文件:访问
https://hf-mirror.com/搜索工作流默认模型(如Qwen3-VL-2B-Instruct),切换到 Files 页面逐一下载所有文件到上一步新建的文件夹中。安装依赖并运行:参考作者另一篇
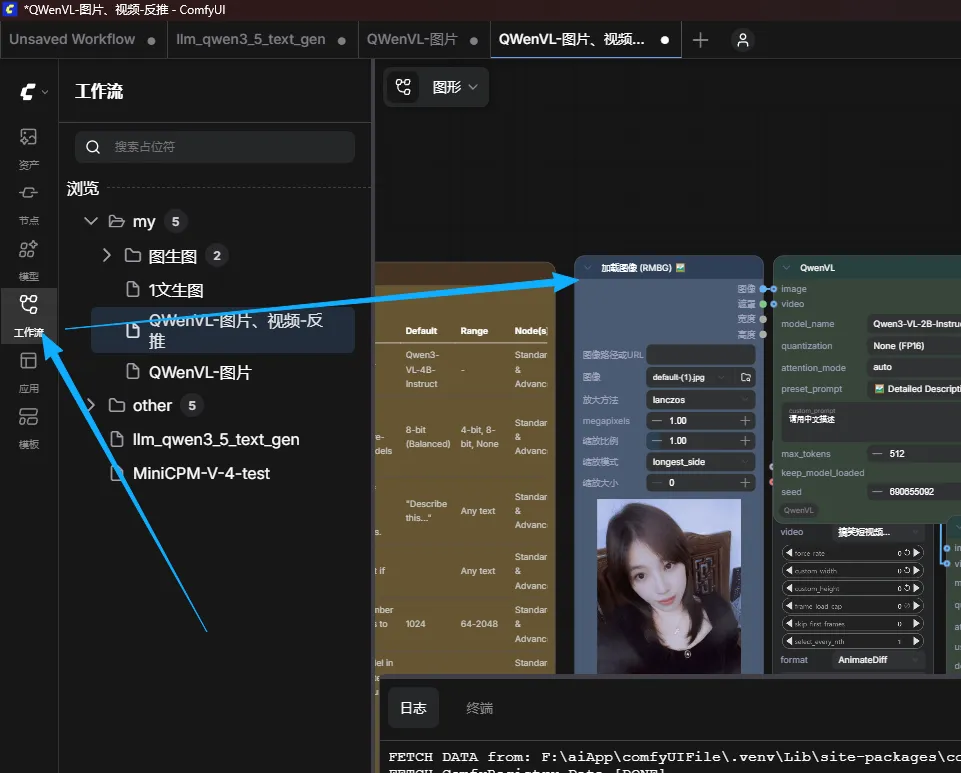
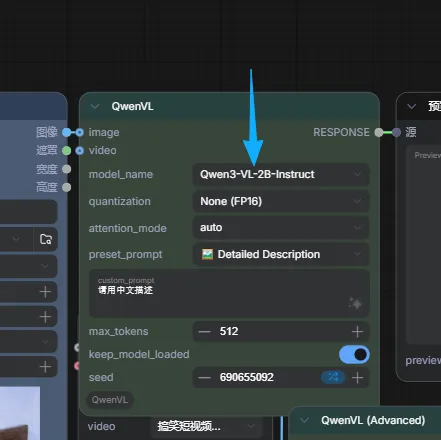
llama-cpp-python安装教程完成依赖安装 → 重启 ComfyUI → 打开保存的工作流 → 加载图片并输入中文提示词(模型支持中文)→ 点击运行,即可反推出关键词。
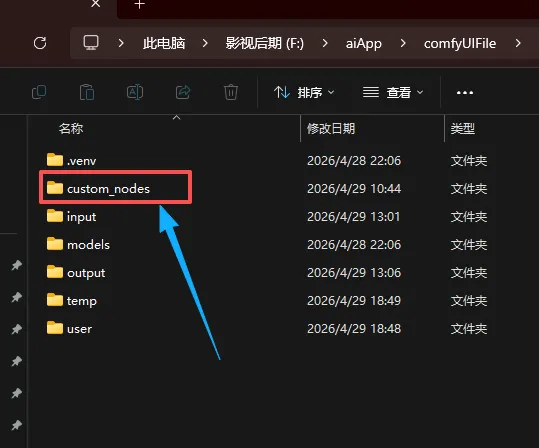
F:\aiApp\comfyUIFile\custom_nodes\ComfyUI-QwenVL
有一个example_workflows文件夹
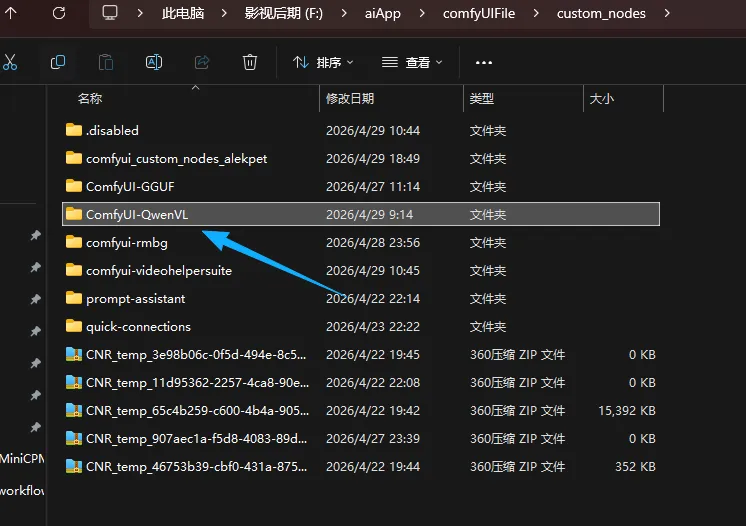
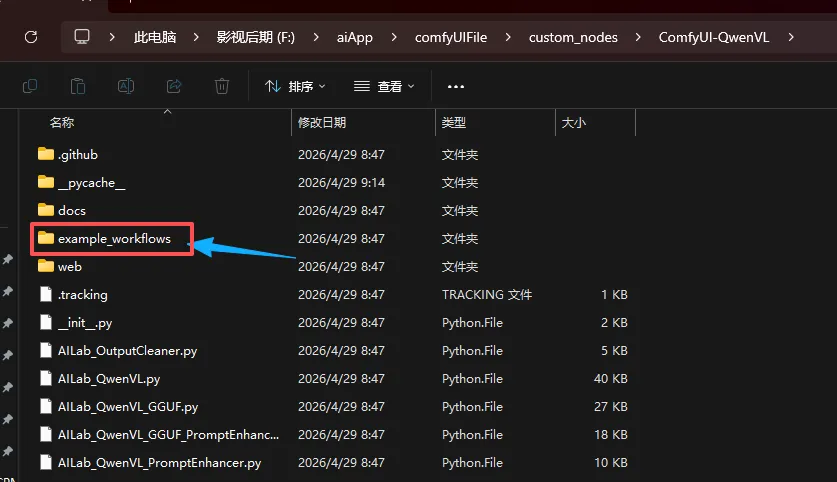
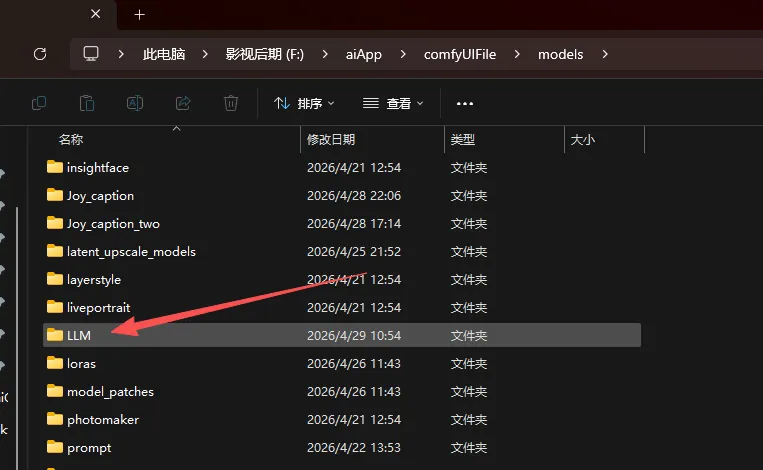
你没有就新建一个LLM文件夹(要大写)
点进去新建一个Qwen-VL文件夹
点进去再新建一个Qwen3-VL-2B-Instruct
你看下现在我目录结构是这样的
F:\aiApp\comfyUIFile\models\LLM\Qwen-VL\Qwen3-VL-2B-Instruct
这个Qwen3-VL-2B-Instruct 你要自己看着改下哈
因为我导入的工作流第一个就是Qwen3-VL-2B-Instruct 所以我下载也是下载Qwen3-VL-2B-Instruct,所以文件夹名字就直接是Qwen3-VL-2B-Instruct
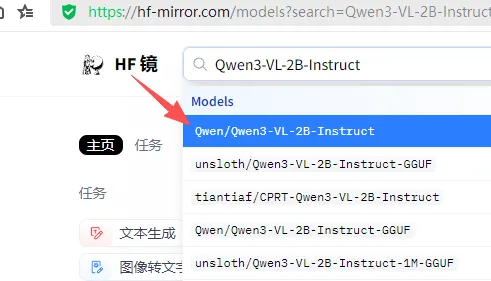
打开https://hf-mirror.com/搜默认的模型,我搜的是Qwen3-VL-2B-Instruct,所以这个模型为例
认准作者是Qwen开头
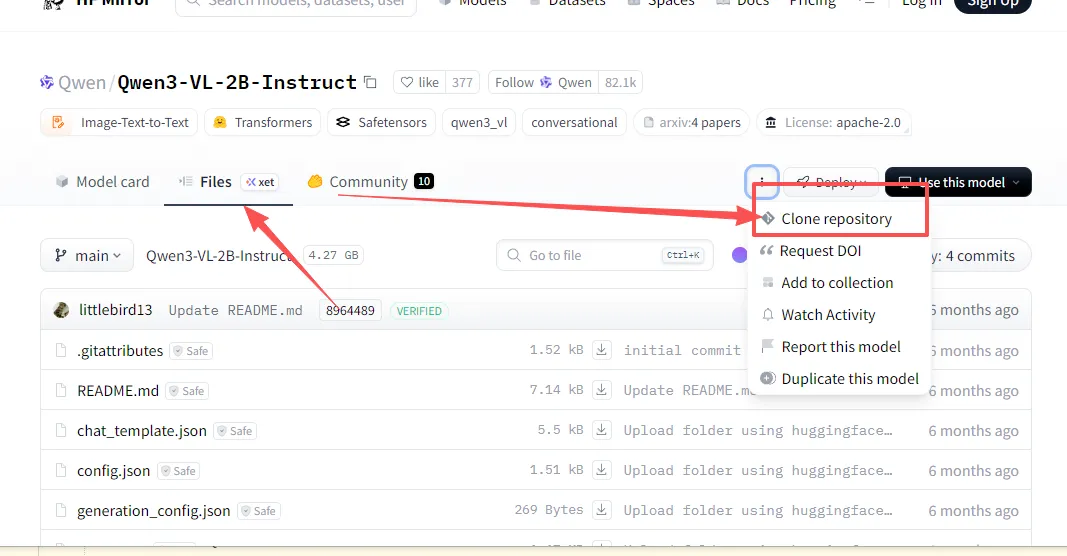
你如果不会git
右边有下载按钮,你一个个吓到你本地我们刚才新建的文件夹
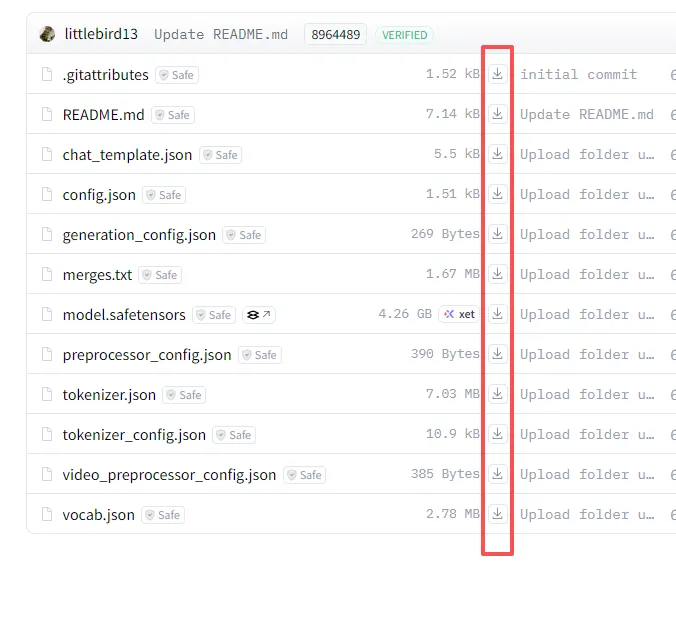
你如果会用git你就直接git下载到刚才我们新建的文件夹里
但是你要注意 他下到大模型 可能会下载失败!!!!
你记得单独下载
然后回头算在个数是不是对得上!!!
你下载完,他是这样的,自己对下有没有漏掉。
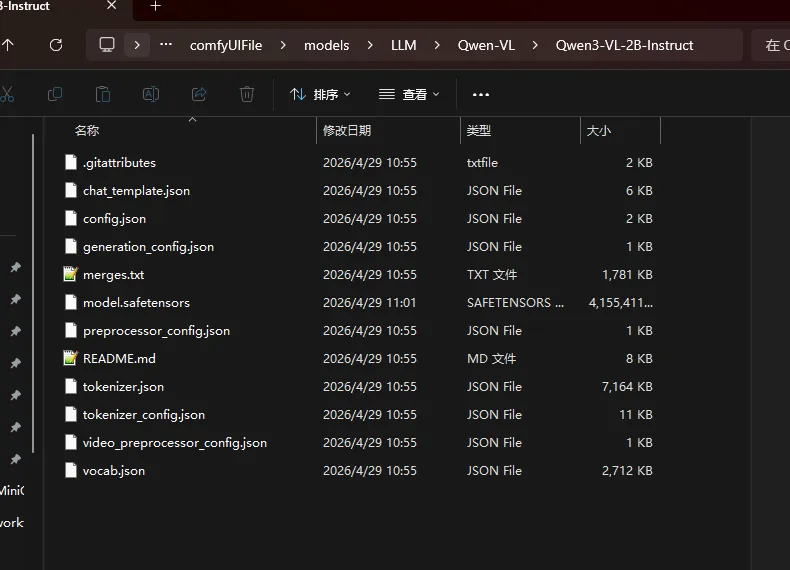
好了简单的操作过去了
上点难度了
官方github文档:https://github.com/1038lab/ComfyUI-QwenVL
你点的开你就点,点不开你随我操作就完事了。
我是怎么这个文档?
我先跟你说下,也方便你后续自己找
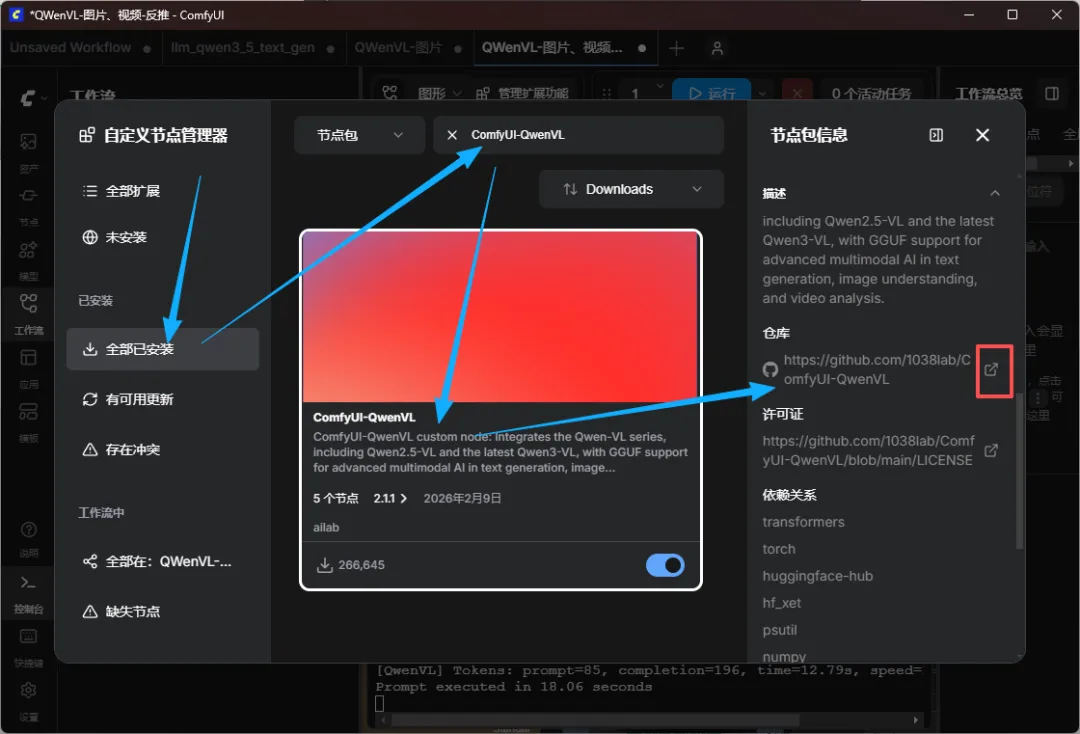
你在已经安装的扩展插件里面找到ComfyUI-QwenVL
点他后右边节点包信息往下滑
就会出来他github的库
你要是没出来你关掉窗口多点几次就会出来了
哪个博主有我写的这么细致的你就说?这不先一键三连下?
然后你看清楚
他是要先安装llama-cpp-python的 那个蓝色的“说明”是可以点的
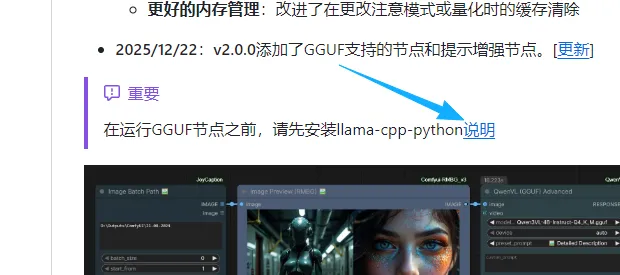
你会跳到这个页面https://github.com/1038lab/ComfyUI-QwenVL/blob/main/docs/LLAMA_CPP_PYTHON_VISION_INSTALL.md
这个是llama-cpp-python的安装教程。
你如果不会来,看我这篇👇👇👇
▍PART 安装ComfyUI-QwenVL的依赖
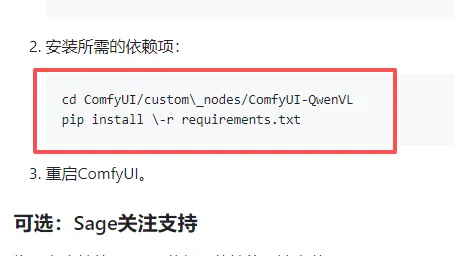
如上图
是的
就算我们从comfyUI里安装了ComfyUI-QwenVL插件
ComfyUI-QwenVL依赖还是要在装一边!!!
你自己替换下路径我就不在重复了
F:\aiApp\comfyUIFile\.venv\Scripts\python.exe -m pip install -r "F:\aiApp\comfyUIFile\custom_nodes\ComfyUI-QwenVL\requirements.txt"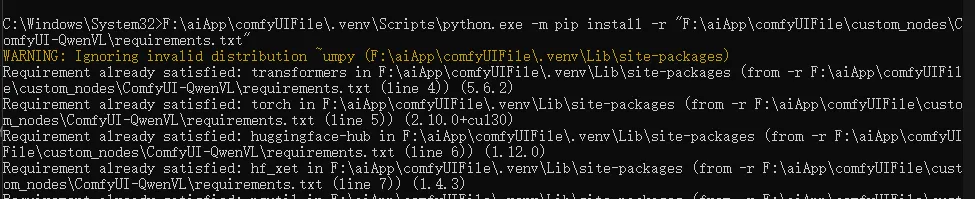
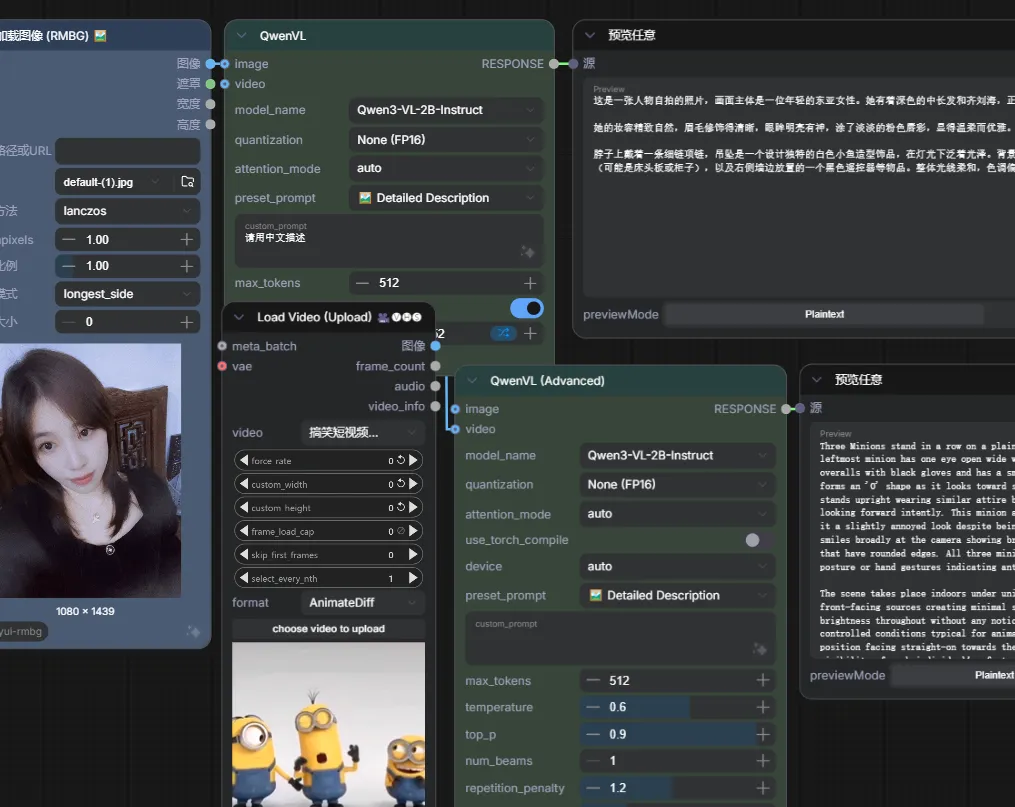
关掉comfyui 重新打开comfyui 打开文章前面让你保存的工作流 加载图片哪个你选一张图片,提示词是可以输入中文的,你如果后续大模型只支持因为,你可以找翻译软件翻译下或者,我有教怎么直接在提示词节点一键翻译。=》comfyUI图文教程2-提示词翻译(CLIP文本编码) 然后点运行
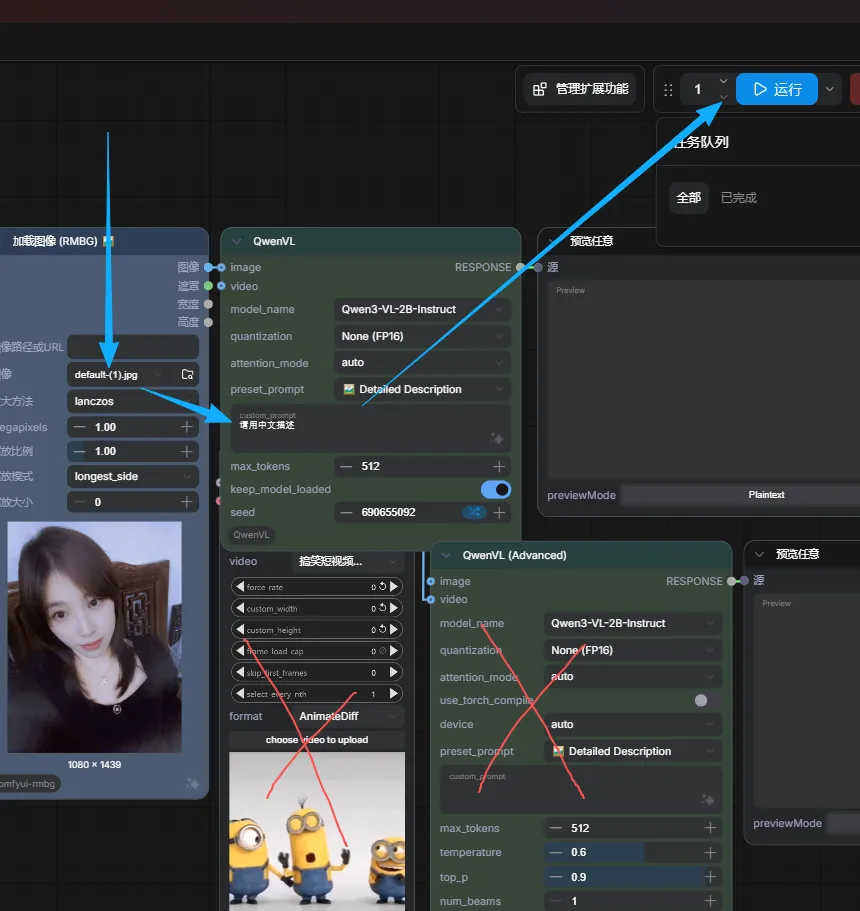
他其实会先跑视频的工作流 但是因为你视频不存在他会跳过 所以其实你运行成功后,你可以单独把图片的工作流和视频的工作流分开来 如下图这样 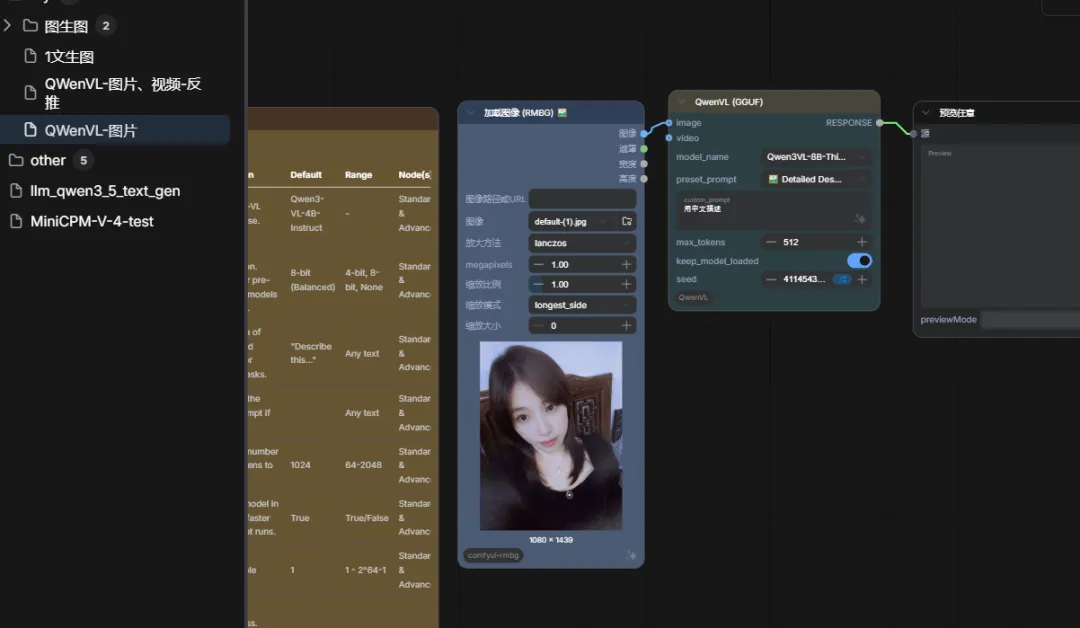
很简单, 就是重复拖F:\aiApp\comfyUIFile\custom_nodes\ComfyUI-QwenVL\example_workflows里面的.json文件到comfyui里面后删掉没用的就好 或者你直接下图这样,一个一个拉下也可以
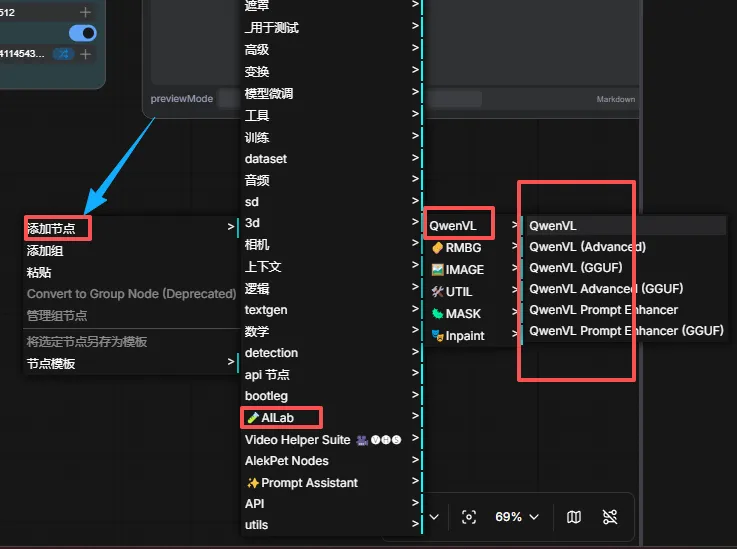
到这里我不知道你还会不会碰到别的问题,如果你碰到了,就底部评论区发下,我看到了如果不忙在回你,毕竟这篇是我当天试出来后,回忆写的。会漏掉应该很正常 我后面文章会写怎么下载qwenVL的gguf版本并被comfyui识别。到时候可以在底部 评论区找到(文章只有微信端打开才看得到评论区)
雪狼之夜ps:既然都看到这行了,不如给个3连,亲~~~
☟
