 夜雨聆风
夜雨聆风我认真想了一下,我自己的知识分布在多少个地方。
飞书文档里一些,Notion里一些,微信收藏里一些,浏览器书签里一些,本地零散的Word和PDF里一些,脑子里还残存一些,但越来越少了。
上个月我想找半年前看过的一篇产品方案,翻了四十分钟没翻到。最后发现它在一个我几乎已经忘记的飞书文档里,嵌在一个被归档的群聊的某个话题里。
四十分钟。
就为了找一个我之前已经看过、并且认真做了笔记的东西。
那一刻我突然意识到一个挺恐怖的事实。我每天都在产生知识,但这些知识像沙子一样从指缝里漏掉,什么都留不住。
你大概率也是这样。

知识散落在各个平台,像沙子一样从指缝漏掉
后来这些平台我一个都不用了
不是突然删的,是慢慢就不再往里面放东西了。
因为我在Obsidian里搭了一套东西,比所有这些平台加起来都好用。而且Claude Code能直接住进去,帮我管理和连接所有笔记。
我慢慢把重要的文档都转成了Markdown,搬进了Obsidian。飞书里的、Notion里的、收藏夹里的,一个一个迁。
Obsidian是啥?(中文常称 “黑曜石”),是一款本地优先、基于纯 Markdown 格式、主打双向链接与知识网络构建的笔记与个人知识管理工具。
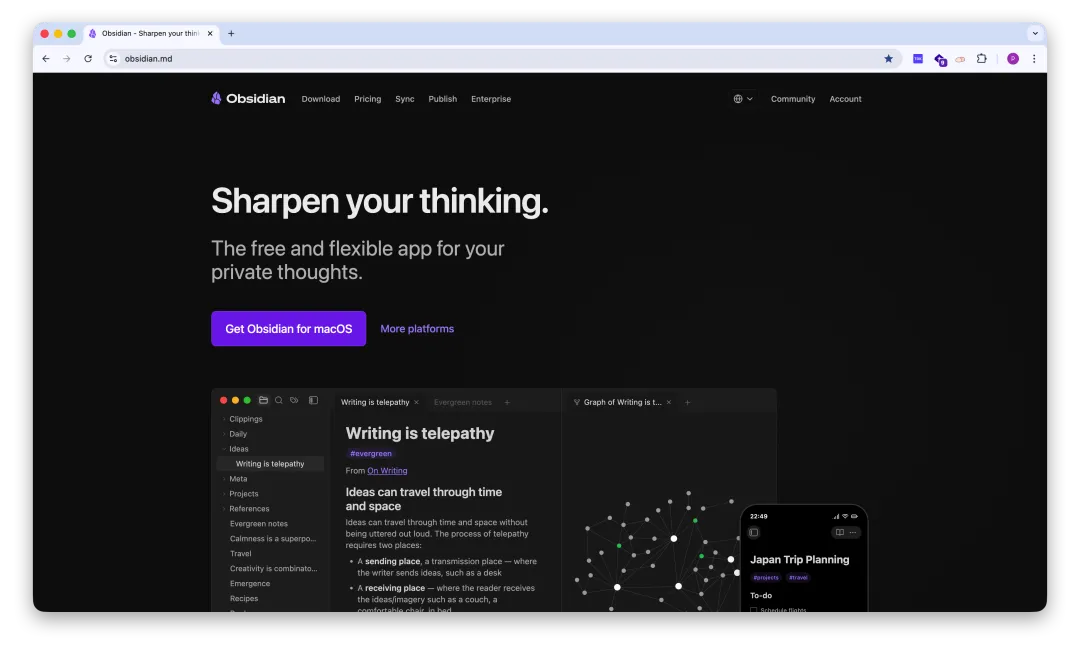
现在我的所有知识,就躺在一个文件夹里,用 obsidian 管理着。

所有知识汇聚到一个文件夹
一件让我重新审视这件事的事
最近,Andrej Karpathy做了一件有意思的事。
没有发论文,没有搞新模型,他把自己的知识管理方法开源了,一个GitHub Gist。
思路很有意思。他不把LLM当搜索引擎用,而是当「知识工程师」。你往里面扔原始资料,PDF也好、网页也好、代码仓库也好,LLM自动帮你编译成结构化的wiki。有目录、有交叉链接、有概念索引。
底层基础设施是什么?Obsidian加Markdown。
这件事刷屏的时候,我正好在整理自己的Obsidian知识库。
我没用Karpathy的方法,但我在做同一件事,只是方式更笨一些。

Karpathy将LLM当「知识工程师」,用Obsidian做底层基础设施
我是怎么把Obsidian变成Claude Code的家的
先说结果。
现在遇到任何问题,我第一反应不是打开搜索引擎,而是打开Obsidian,问Claude Code。
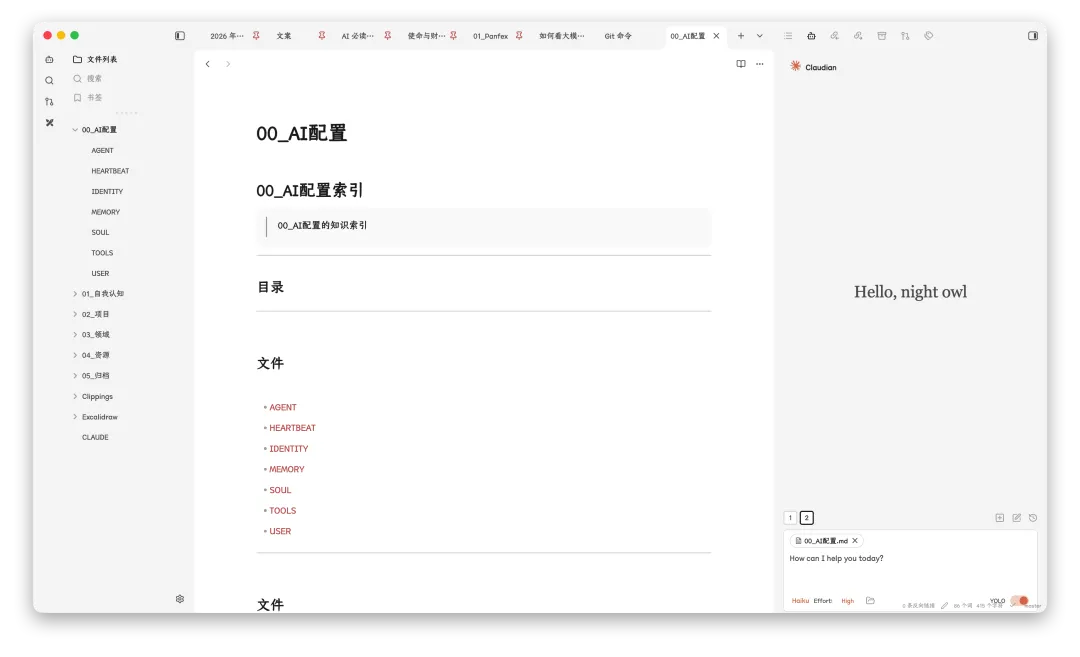
要启动一个新项目,第一件事也是打开Obsidian。
因为这个知识库里有我所有的笔记、所有的项目经验、所有的技术积累。而Claude Code住在里面,它能读到所有东西。
和Claude Code沟通之后,所有重要的结论、决策、踩坑记录,都会被沉淀成文件,安安静静躺在我的vault里。
但真正让这件事发生质变的,不是我存了多少文件。
是我在Obsidian里建了一套东西,让Claude Code从零开始认识了我。

Claude Code住进知识库,帮你管理和连接所有笔记
7个文件,让AI认识你
这是我自己摸索出来的,也是整个工作流里最关键的一环。
我在Obsidian的知识库根目录下,建了一个叫 00_AI配置 的文件夹,里面放了7个文件。
这套结构不是我自己发明的,是参考了一个叫OpenClaw的AI Agent框架。OpenClaw的官方定义里,这些文件各有分工,每个文件解决一个具体问题:
AGENT — 启动控制器。定义了每次新会话开始时按什么顺序读取文件、心跳机制怎么触发、会话结束时怎么检查产出。简单说就是「我该怎么运转」。
SOUL — 人格和行为边界。定义了Agent的性格、语气、底线。比如「不要编造数据」「拿不准先问」。这是「我该做什么样的人」。
IDENTITY — 身份信息。名字、风格、签名、头像。这是「我是谁」。
USER — 用户档案。你是谁、做什么工作、目标是什么、性格特点是什么、有哪些重要关系。这是「我在帮谁」。
MEMORY — 长期记忆。沉淀过的认知、决策、教训、重要偏好。每次启动都会读,跨会话保持连续性。这是「我记得什么」。
TOOLS — 工具笔记。技能怎么用、本地有什么特殊配置、踩过什么坑。这是「我会用什么」。
HEARTBEAT — 定期巡检清单。定期检查有没有什么需要关注的事。这是「我该主动做什么」。

7个文件组成完整的认知框架,让AI从零认识你
这7个文件合在一起,就是一个完整的「认知框架」。
Claude Code每次启动,按顺序读完这7个文件,就知道我是谁、你在帮我什么、之前我们做过什么决策、踩过什么坑、用过什么工具。
它就不再是一个通用助手了。它是你的助手。
你试试就知道,这个区别,用过了回不去。
为什么偏偏是Obsidian
说到这里你肯定会想,这些东西放Notion行不行?放飞书文档行不行?
坦率地讲,不行。
Obsidian有一个特质,在AI时代几乎是不可替代的,本地优先。
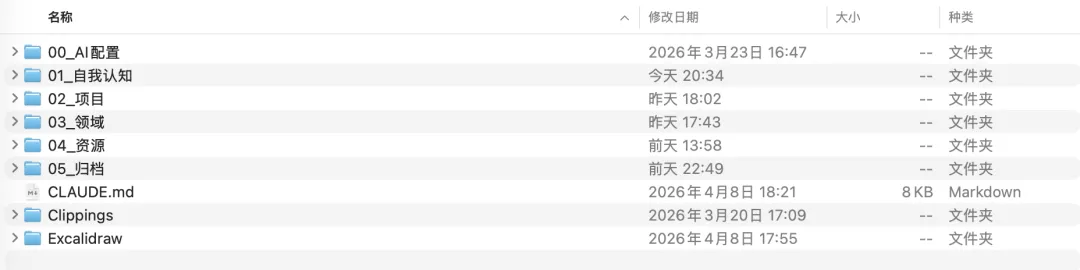
你所有的笔记,就是一个个.md文件,躺在你自己电脑的硬盘上。不依赖任何服务器,不依赖任何公司的存亡。
Claude Code需要直接操作你的文件系统。它能读文件、写文件、搜索文件、编辑文件。这整条链路,在本地Markdown文件上跑得丝滑无比。
你换成Notion试试?得调API、得处理格式、得应对权限问题。折腾一圈,灵感都凉了。
而且Markdown是AI最友好的格式之一。Claude、GPT、Gemini,全吃得透透的。你不需要任何中间转换,AI直接读、直接写、直接改。
还有一点经常被忽略的。
Obsidian用的是开放格式。就算有一天这公司倒闭了,你的笔记还是你的,用任何文本编辑器都能打开。十年后,哪怕所有工具都消失了,Markdown文件还在那里等你。

所有知识就在你的硬盘上,真正的本地优先
你的知识库不是某个产品的附属品,它是你的资产。
Notion、飞书文档这些云端工具,它们存的是「它们的文件」。你随时可能因为权限变更、服务调整、公司策略变化而失去这些东西。
Obsidian存的是「你的文件」。真正的你的。
从存知识到长知识
我跟你说说我现在的工作流。
遇到一篇好的文章或者有价值的技术文档,扔进Obsidian。
和Claude Code讨论问题的时候,重要的结论会被沉淀成文件。
项目结束之后,复盘和经验教训会被整理成笔记。
然后Claude Code会帮我做一件事,发现这些散落在各处的笔记之间的关联。
比如我写了一篇关于AI Agent工作流的文章和一篇关于项目复盘的文章,Claude Code会发现这两篇其实在讨论同一个问题,建议我建一个双向链接。
比如我的MEMORY文件里记录了一个踩坑经验,某天我在另一个项目里遇到类似问题时,Claude Code会主动提醒我。

知识在生长,不是在堆积
你的知识在生长,不是在堆积。
回想一下我开头说的那个问题。知识散落在飞书文档、Notion、微信收藏、浏览器书签、本地零散文件里。
现在这些问题在Obsidian里全部消失了。
所有的知识都在一个地方。都是Markdown格式。Claude Code全都能读到。笔记之间的关联由AI帮你维护。
再也不用在废墟里考古了。
后面会慢慢写
这篇文章只是一个开头。
我自己的Obsidian是怎么配置的,和Claude Code怎么对接的,00_AI配置里每个文件具体怎么写、写了什么内容,怎么让Claude Code真正「认识」你,怎么搭建一个会自己生长的知识网络。
这些东西,我打算一篇一篇写出来。
如果你现在还没开始管理自己的知识库,不用焦虑。先装个Obsidian,建一个vault,把你最常用的那几个文档转成Markdown扔进去。

先跑起来,你的知识比你想象的要多得多
先跑起来。
你会慢慢发现,你的知识比你想象的要多得多,只是之前它们都散落在各个角落,没有人帮你把它们串起来。
1880年代,电力开始在美国普及的时候,很多工厂主买了发电机和电动机,但生产效率并没有提升。
因为他们只是用电动机替代了蒸汽机,整个生产方式没有变。
AI也是一样。装了工具不等于用了AI,真正吃到红利的人,是那些想明白AI到底意味着什么,然后重新设计自己工作方式的人。
你的知识库,就是最好的起点。
