 夜雨聆风
夜雨聆风Karpathy 说,他从来没有像现在这样,觉得自己作为程序员「落后了」。
这话从别人或者我的嘴里说出来,可能就还算是正常 ……但 Karpathy 这么说,分量就还是不太一样了。
……但 Karpathy 这么说,分量就还是不太一样了。
Karpathy是 OpenAI 联合创始人、Tesla AI 负责人、如今 Eureka Labs 的创始人,整个深度学习时代最具影响力的技术布道者之一。虽然喜欢造词,被认为有些“网红”属性,但也是凭本事而红,没有任何水分。
上周,他在 Sequoia Capital 的 AI Ascent 2026 大会上,和 Sequoia 合伙人 Stephanie Zhan 做了一场 30 分钟的炉边对话。
主题是:软件正在经历第三次范式转移。
Stephanie Zhan 在活动结束后,发了段总结称:
“ 去年他造了「vibe coding」这个词,今年,他「从未如此觉得自己作为程序员落后了」。
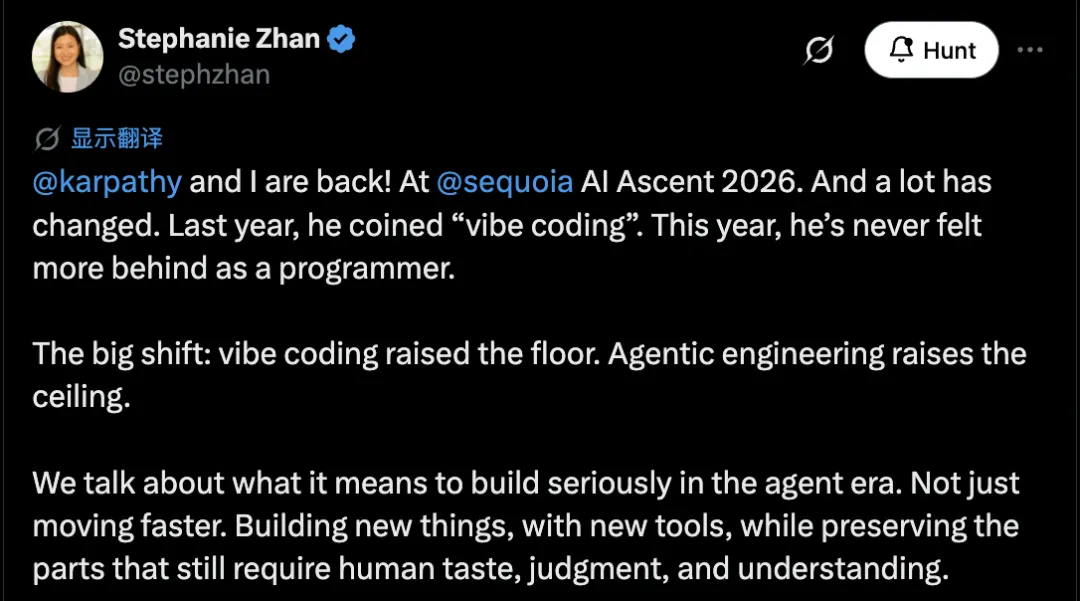
她还用一句话概括了整场对话的核心内容:
“ Vibe Coding 抬高的是地板,Agentic Engineering 抬高的是天花板。一个关乎准入,更多人能参与构建。另一个关乎卓越,用 Agent 的同时不牺牲安全、可靠性、可维护性,以及品味。
而 Karpathy 自己也在事后发了一条长帖总结了三个主题。
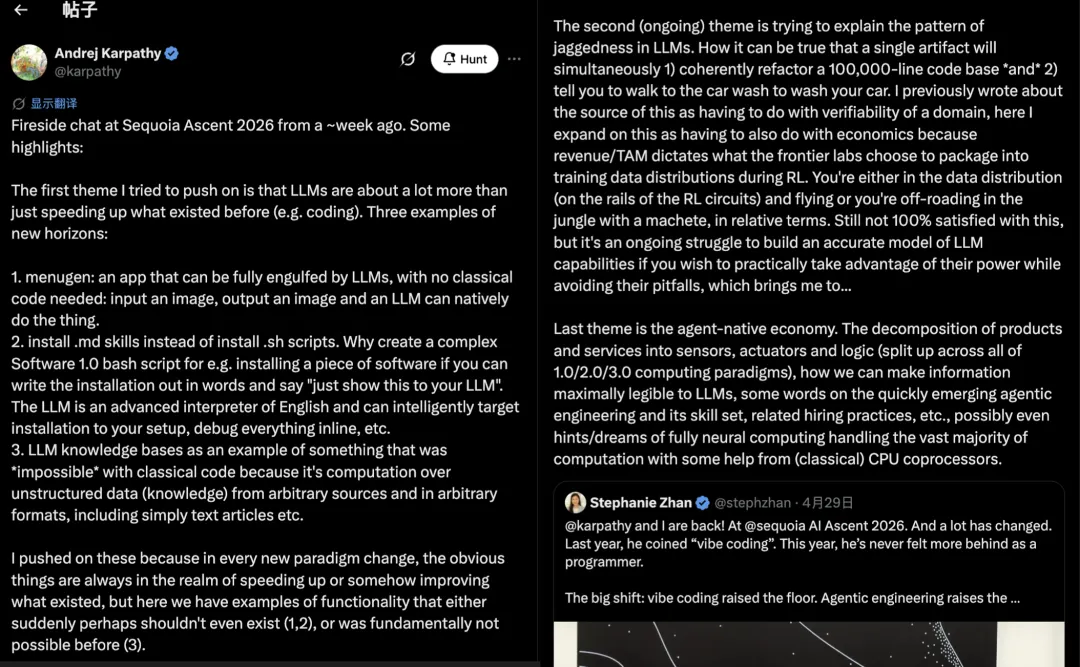
其中,最重要的一段是关于 LLM 的「新疆域」:
01“ LLM 远不只是加速已有的工作流(比如写代码)。有些应用可以被 LLM 完全吞噬,无需传统代码。有些安装脚本可以用英文 .md 文件替代 .sh 脚本,因为「LLM 就是一个高级的英文解释器」。还有像 LLM 知识库这样的东西,以前根本做不了,因为它需要对非结构化数据做计算。
Software 1.0
在理解什么是 Software 3.0 之前,我们先回头来看看 1.0 和 2.0。
Software 1.0 是我们熟悉的传统编程。
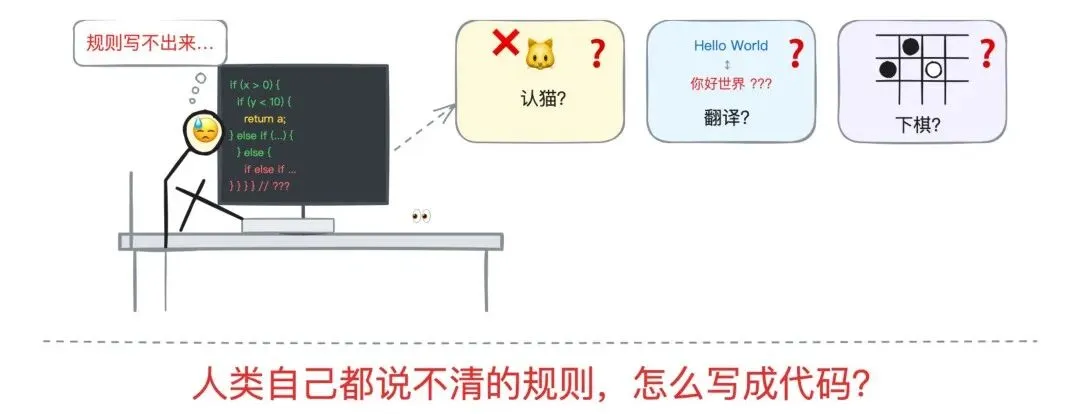
程序员用 Python、C++、Java 写代码,每一行都是明确的指令:如果 A 则执行 B,否则执行 C。逻辑是人写的,bug 也是人造的。
从 1950 年代到现在,绝大多数软件都属于这个范畴。
这套范式统治了软件工程半个多世纪。
它的好处显而易见:确定性强,可调试,可解释。但它也有一个根本性的局限,扩展性受限于人类的智力和时间。
你写不出一个手动规则,让计算机从一张照片里认出一只猫。你写不出一段逻辑,让机器把中文翻译成英文。你更写不出一个算法,让 AI 从零学会下围棋。
毕竟这些任务……人类自己都说不清楚规则是什么,怎么写成代码呢?
022017 年:Software 2.0
2017 年 11 月,Karpathy 还在 Tesla 做 Autopilot 的时候,在 Medium 上写了一篇博客:Software 2.0。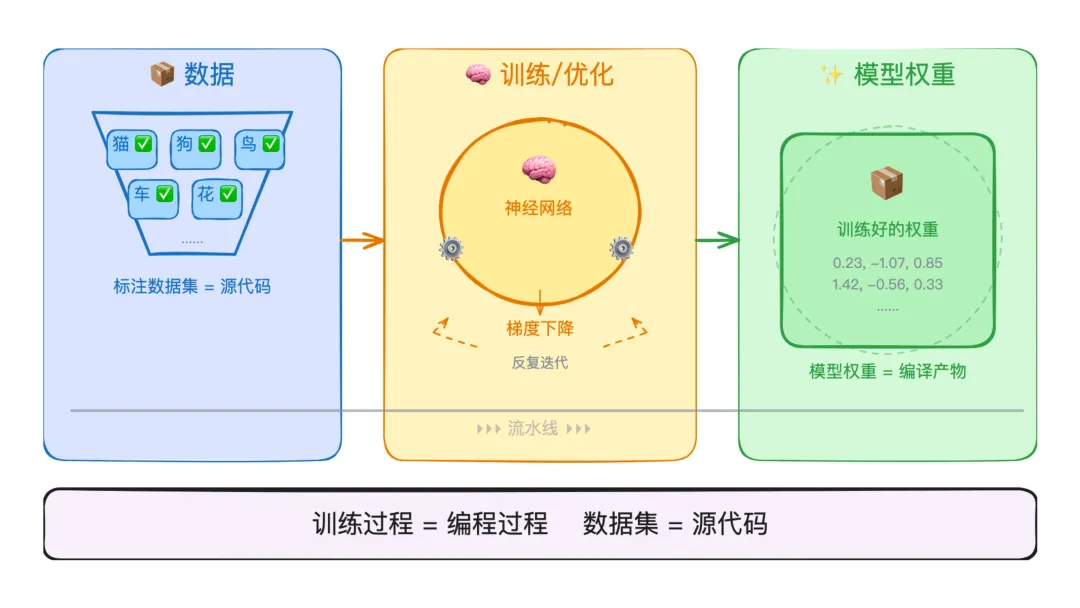
这篇文章后来被认为是 AI 领域最有影响力的概念文章之一。
他的核心论点是:神经网络不只是一种新工具,它代表了一种全新的编程范式。
在 Software 1.0 里,程序员写代码。在 Software 2.0 里,程序员准备数据和目标函数,然后让优化算法(梯度下降)去搜索出一组神经网络权重。
“ Software 2.0 是用一种更抽象、对人类更不友好的语言写成的,比如神经网络的权重。没有人参与编写这些代码,因为权重的数量实在太多了(典型的网络可能有几百万个权重),直接用代码编写已经不可能。
换句话说,训练过程就是编程过程,数据集就是源代码。
他在文章中列了一长串 Software 2.0 已经「吃掉」Software 1.0 的领域:
图像识别从手工特征工程变成了深度卷积网络,语音识别从高斯混合模型变成了端到端神经网络,机器翻译从基于短语的统计方法变成了 Transformer 架构,围棋从手写评估函数变成了 AlphaGo Zero 的自我对弈。
而 Software 2.0 的好处在于:计算图是同质的(主要就是矩阵乘法),方便硬件优化。运行时间可预测,没有死循环。不需要动态内存分配,不会内存泄漏。
而且在很多领域,它的表现已经远超人类手写的方案。
在文章末尾,Karpathy 当时预言,当我们最终造出 AGI 的时候,它一定是用 Software 2.0 写的。
这个预言可以说是非常成功了,只不过在 2026 年的今天看来……好像只说对了一半,因为:
033.0 来了
Karpathy 自己承认,Software 2.0 的文章写得太早了,当时 GPT 还没出现,Transformer 才刚刚发表。他没有预见到一个东西:大语言模型。
Software 2.0 的编程方式是:准备数据,设计网络结构,训练。这个过程需要大量的机器学习专业知识,需要 GPU 集群,需要几周甚至几个月的训练时间。门槛极高。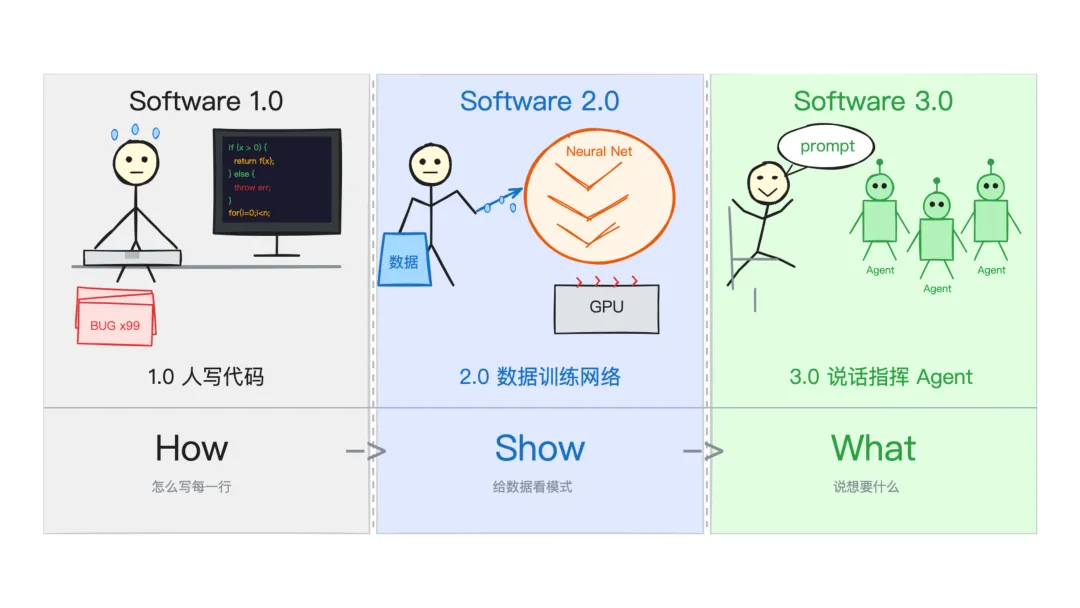
而 Software 3.0 的编程方式,则完全不同。
你写一段 prompt,给模型一些上下文,它就执行了。
不需要训练,不需要梯度下降,不需要标注数据。
你用自然语言「编程」,用 context window 作为「内存」,用工具调用作为「系统调用」。LLM 成了一个新型的计算解释器,而 prompt 就是它的源代码。
Karpathy 在这次 AI Ascent 上把三代软件做了一个清晰的总结:
• Software 1.0:人写代码
• Software 2.0:神经网络用数据训练出来
• Software 3.0:通过 prompt、上下文、Agent、工具、记忆和验证来编程
context window 成了新的编程界面。
04MenuGen 的例子
Karpathy 举了一个他自己做的项目:MenuGen。
想象一下这个场景:你走进一家餐厅,拍了一张菜单照片,然后一个 App 自动识别出每道菜的名字,搜索菜品图片,重新排版生成一个带图片的漂亮菜单。
用传统方式做这件事,流程大概是这样:先用 OCR 识别文字,再用 NLP 提取菜名,然后调用图像搜索 API,最后写前端来重新排版。至少得写几百行代码,可能还需要一两天。
而 Karpathy 发现,直接把照片扔给 Gemini,让它在原图上叠加菜品图片,整个中间层的 App 都变得多余了。
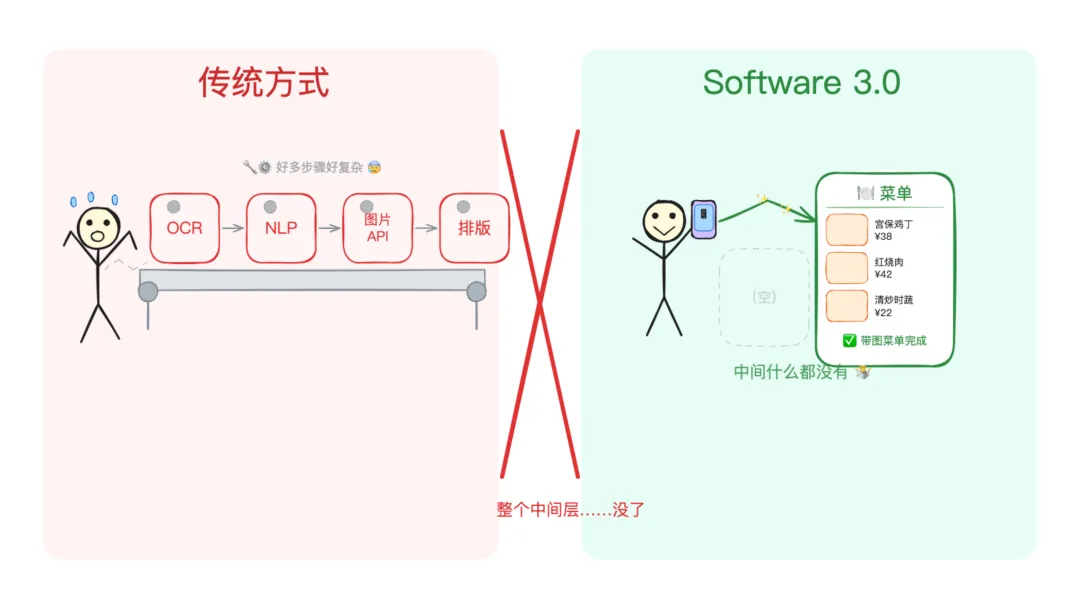
这就是 Software 3.0 最具颠覆性的地方:有些应用不是被做得更快了,是直接被模型的原生能力吞掉了。
05“ 不要只问 AI 能帮你更快地构建什么。要问:AI 让什么变得不再必要。
Vibe Coding 到 Agent Engineering
「Vibe Coding」这个词是 Karpathy 自己在 2025 年初造的,见:传奇音乐制作人Rick Rubin将《道德经》魔改成Vibe Coding版《编程之道》背后的故事。

当时 AI 编程工具刚起步,他用这个词来形容一种新的开发方式:不看代码细节,凭直觉和自然语言跟 AI 协作,「感觉对了就行」。
然后,这个词火了,火到他自己都没想到。
但 Karpathy 这次想说的是:Vibe Coding 仅仅只是热身,而已。
2025 年 12 月,他说自己经历了一个「翻转」。从自己写 80% 代码、Agent 写 20%,一下子变成了 20/80。
在 2026 年,这个比例还在继续倾斜。
他甚至因此患上了「AI 精神病」(AI psychosis):每天对着 Agent 说话 16 个小时,Agent 跑完一个任务就想立刻开下一个,token 没花完就觉得自己在偷懒。
在这次演讲中,Karpathy进一步把这种转变拆成了两个层次:
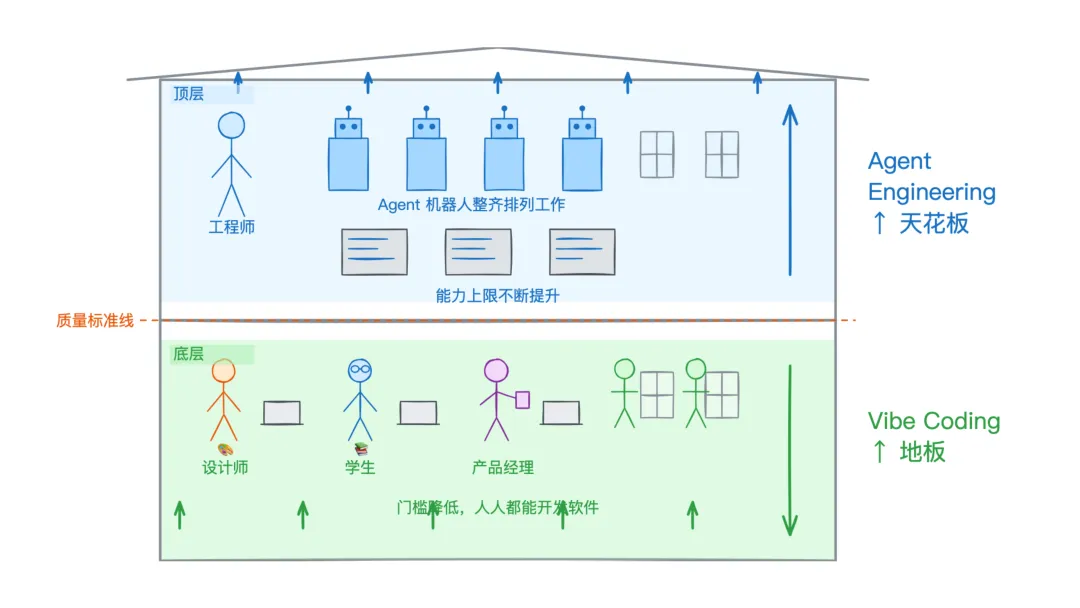
Vibe Coding 抬高了地板。
任何人,哪怕完全不懂编程,都能用自然语言描述需求,让 AI 生成一个可用的应用。这在以前不可想象。一个设计师可以做原型,一个产品经理可以做内部工具,一个学生可以做自己的项目。门槛被拉到了接近零。
Agent Engineering 抬高了天花板。
专业开发者使用 Agent 的方式完全不同。他们并非「让 AI 帮忙写代码」那么简单,他们在设计一整套系统:Agent 生成方案,Agent 编码,Agent 测试,Agent 相互检查。这套流程要保证没有安全漏洞,架构要干净,系统要稳健。
这就是 Karpathy 说的「Agentic Engineering」,智能体工程。
06“ Vibe Coding 抬高的是所有人能做软件的下限。Agentic Engineering 要保住的是专业软件过去已有的质量门槛。
可验证性
Karpathy 在演讲中还提出了一个观点:传统软件自动化的是你能规格化的东西,而 AI 自动化的是你能验证的东西。
这在我看来,其实相当关键。
代码写的对不对?跑个测试就知道了;数学上算的对不对?算一下就有了;安全上有没有漏洞?有扫描工具可以来发现。
这些领域有一个共同特征:输出可以被客观评估。
正因为可以验证,这些任务才能进入强化学习的循环,才能让模型越练越强。
这也是为什么 AI 在编程、数学、代码安全等方面进步飞速,而在「常识推理」方面总是犯一些让人匪夷所思的错误。
Karpathy 举了个例子:模型可以重构一个十万行的代码库,可以发现零日漏洞,但它也会告诉你,「你的车在 50 米外的洗车店,建议步行过去」。
这种现象叫做「锯齿状智能」(jagged intelligence)。
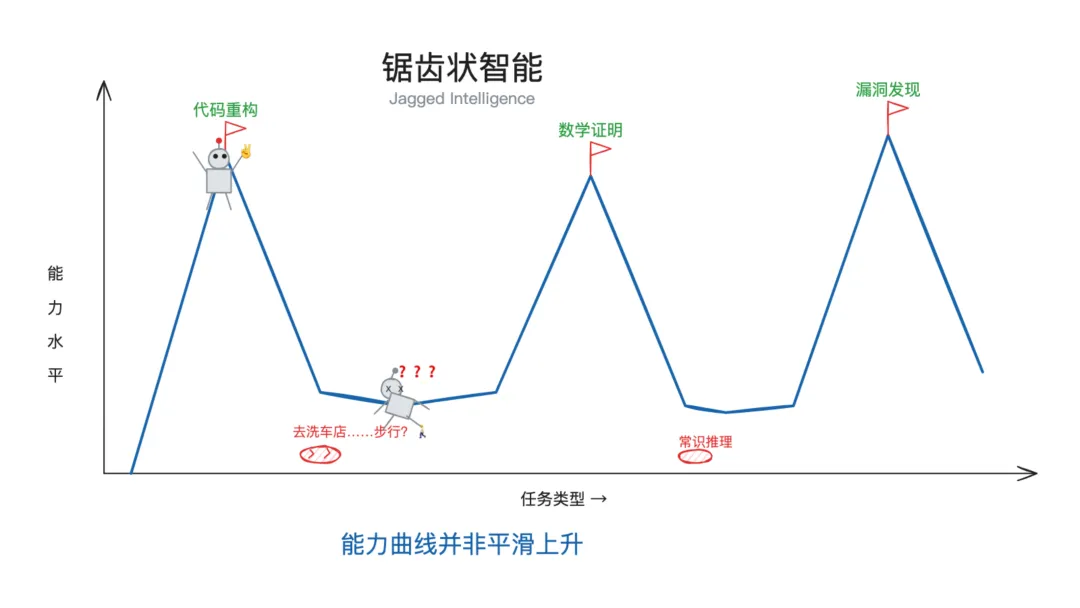
能力曲线并非平滑上升,有高峰,也有断崖。高峰出现在实验室有数据和奖励信号覆盖的领域,断崖出现在训练分布之外的地方。
Karpathy 在事后的推文进一步进行了解释:锯齿状分布不仅与可验证性有关,还和经济学有关。收入和市场规模(TAM)决定了前沿实验室在强化学习训练中选择覆盖哪些领域。
“ 你要么在数据分布之内,在 RL 的轨道上飞驰。要么在轨道之外,拿着砍刀在丛林里开路。
好比 Claude 能重构十万行代码,因为有人花了钱让它训练这个能力。但「怎么去洗车」这种问题,没人付钱去训练,也不是模型的重点了。
这其实不是智能的问题,是经济分配的问题。
而对创业者来说,对应的机会则是:找到那些可以构造验证环境、但还没被大实验室的强化学习覆盖到的领域。如果你能自己设计奖励函数,即便主流模型没有针对性优化,你也能通过微调获得显著优势。
07Harness
Karpathy 还聊到了一个概念:harness(套件/脚手架)。
这个词最近在 Agent 技术中特别火热。我之前也专门写过一篇文章《模型不是关键,Harness 才是》来介绍。
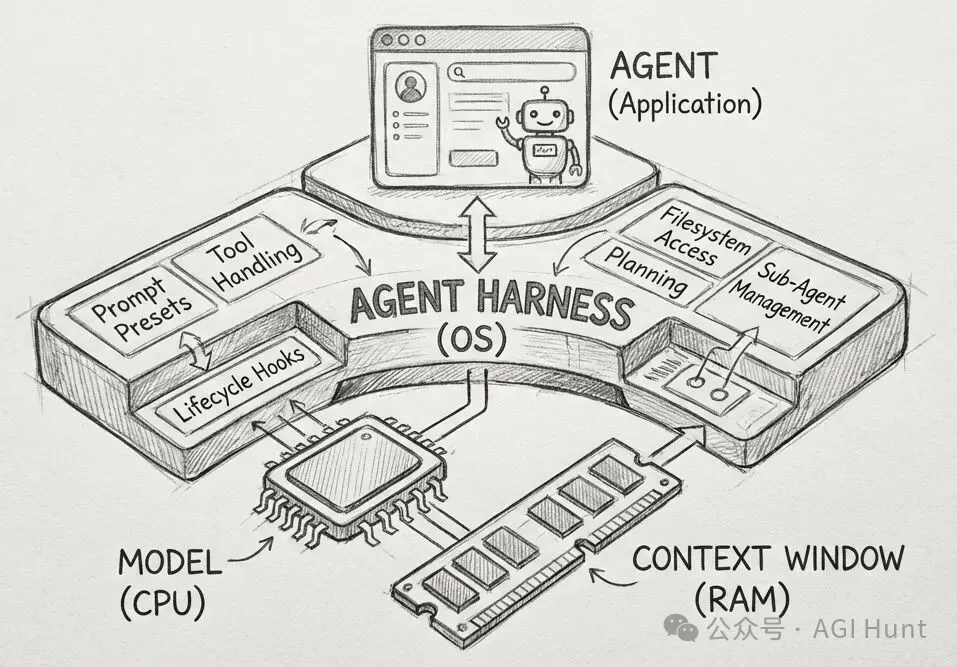
Harness 概念最早是 HashiCorp 联合创始人 Mitchell Hashimoto 在今年 2 月提出的。他在用 AI 做 Ghostty 项目时总结出一条原则:
“ 每当你发现 Agent 犯了一个错误,你就花时间去工程化一个解决方案,让它再也不会犯同样的错。
后来包括 Cursor,OpenAI,Anthropic 等也纷纷发表了关于 Harness 的工程博客。
比如 Anthropic 的博主中讨论到的核心问题是:AI Agent 如何在多个上下文窗口之间保持进度?
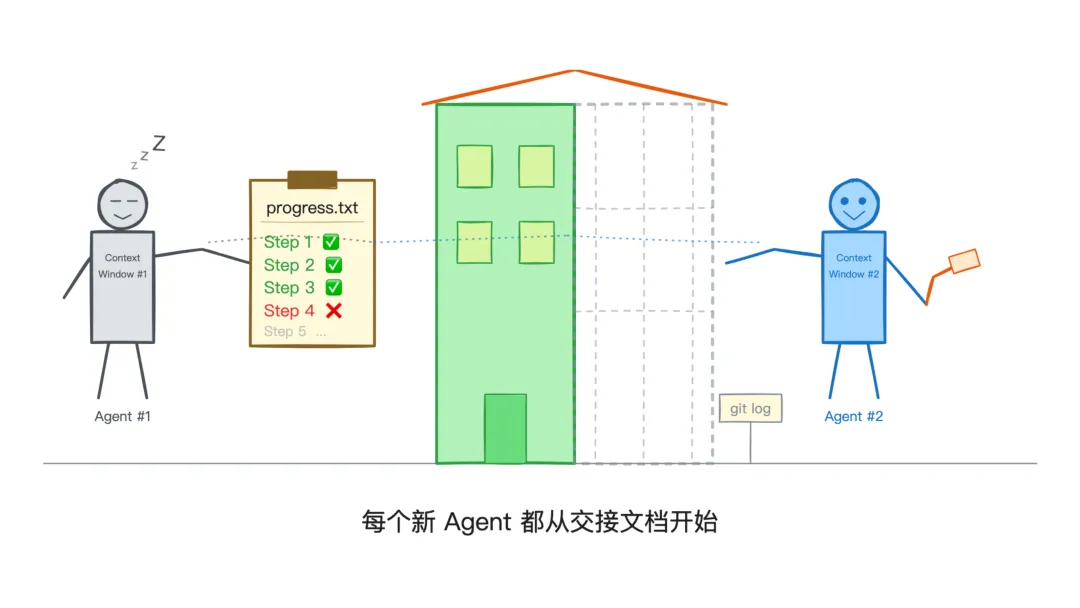
他们的方案是:初始化 Agent 搭建环境、创建进度文件(claude-progress.txt)、建立基准 commit。执行 Agent 逐个完成功能,每次新的 context window 开始时,先读 git log 和进度文件,接着上一轮继续。
这就像是给 Agent 写了一份交接文档。
而 Karpathy 的观点则更为激进:未来的软件应该为 Agent 重写,完全不用考虑人类用户。
现在的软件界面是给人用的,有按钮、有菜单、有鼠标。但 Agent 不需要这些。Agent 需要的是:机器可读的接口、明确的权限声明、可分解的工作流、清晰的指令格式。
他在推文中还举了一个小例子:为什么还要写复杂的 .sh 安装脚本?你完全可以用一个 .md 文件,用英文把安装步骤写清楚,然后告诉用户「把这个文件给你的 LLM 看就行」。
LLM 作为高级解释器,可以智能地根据你的系统环境调整安装过程,遇到问题也能内联调试。
用 .md 替代 .sh,替代 .py 和 .go 等等,也是我最近的用法。
08人的位置
说了这么多 AI 和 Agent,Karpathy 倒也没忘了说回人类自己。
他的判断是:理解力是不可外包的。
Agent 可以调 API,可以写代码,可以做测试。但有几件事它确实还做不了:
系统规格设计:比如用户系统应该用稳定的 user ID 而不是邮箱地址来关联资金,这种判断需要理解业务逻辑,需要经验,需要对后果的预见。
概念理解:你需要真正懂张量是什么、内存视图怎么工作、存储机制背后的原理,而不只是知道 API 的名字。否则你无法判断 Agent 写的代码是不是在做正确的事。
品味:Agent 写的代码经常「能跑但很丑」。它通过了所有测试,功能也对,但架构一团糟、命名一塌糊涂、复杂度失控。你需要知道什么是好的设计。
“ 你可以外包你的思考,但不能外包你的理解。
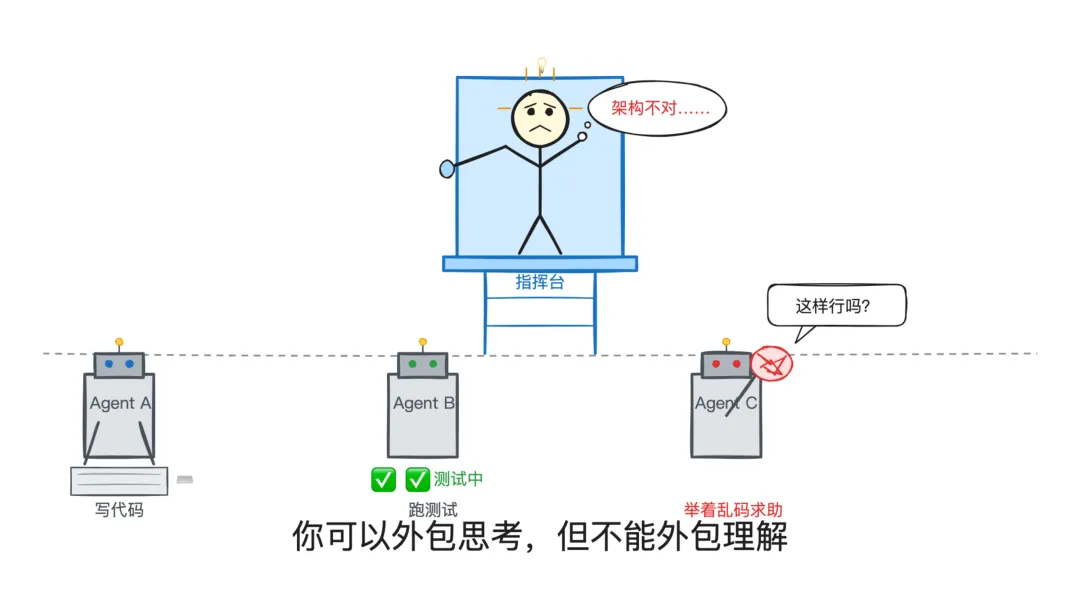
如果你不理解系统在做什么,你就没办法在 Agent 犯错的时候知道它错在哪里。
而 Agent 一定会犯错。
我有时也会,在对方回答我严肃的工作问题时说“AI 认为……”时,会打断他说:不要“AI 认为、AI 的判断”,要“你认为、你的判断”。
09三代软件
回看这三代软件范式的演进,其中的主线是:人类参与的方式在不断变化。
Software 1.0 时代,程序员是作者。每一行代码都是他亲手敲出来的,逻辑是他设计的,bug 是他修的。他对整个系统有完全的控制权,也承担全部的责任。
Software 2.0 时代,程序员变成了教练。他不再直接写逻辑,而是准备训练数据、设计网络结构、调整超参数,然后让优化算法去搜索解决方案。他的工作从「告诉机器怎么做」变成了「给机器看该怎么做」。
Software 3.0 时代,程序员变成了指挥官。他不需要准备数据,不需要训练模型,他只需要用自然语言描述意图,给出上下文,然后指挥一群 Agent 去执行。他的工作从「给机器看」变成了「告诉机器要什么」。
从 how 到 show 到 what。
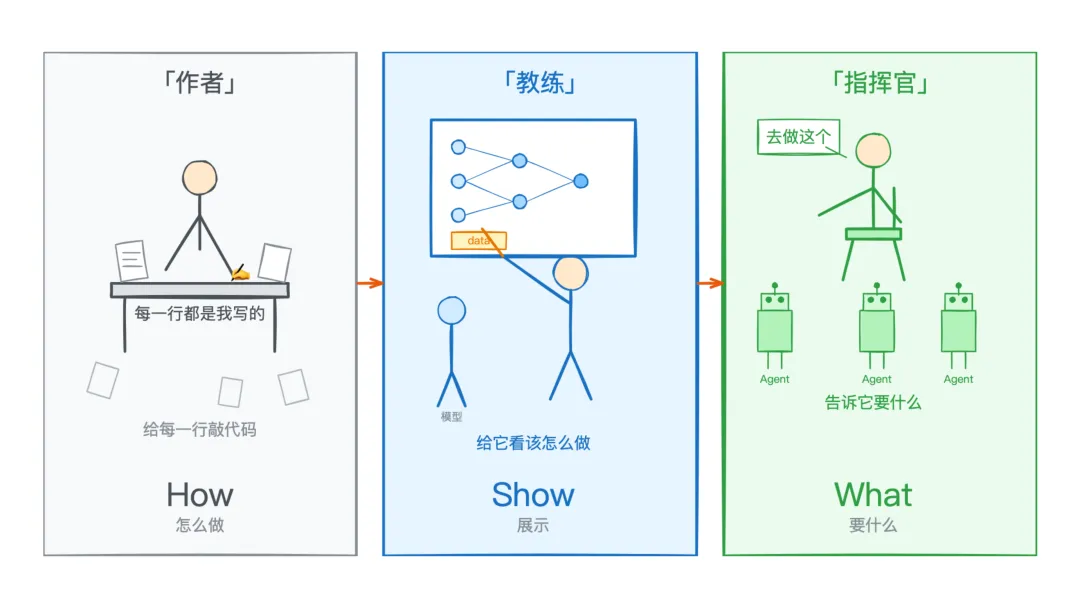
但这条主线的另一面,则是:每一代转移,人类失去的是执行细节的控制,获得的是更高层次的杠杆。
就像 Karpathy 在先前的播客里说的:以前焦虑的是 GPU 空闲,现在焦虑的是 token 没花完。以前的瓶颈是计算资源,现在的瓶颈是人。
你控制多少 token 吞吐量,决定了你能做多少事。
在推文最后,他还抛出了一个更远的展望:全神经计算(fully neural computing)。
他设想的未来是,绝大多数计算由神经网络处理,而传统的 CPU 反而成了「协处理器」,只负责一些辅助任务。
这也算是和他 2017 年 Software 2.0 文章末尾的预言遥相呼应了,当年他说 AGI 一定是 Software 2.0 写的。
现在看来,他可能觉得 AGI 更可能是 Software 3.0 催生的,在一个 LLM 为主、传统计算为辅的全新架构上运行。
103.0 时代
在我看来,Karpathy 这次没有讲太多「未来畅想」。他讲的基本都是,已经发生的事。
Software 3.0 并非只一个概念,也不是一个预测,如果你能读到这个账号的这篇文章,我想你很可能,早已置身其中,感同身受了。
Anthropic 今年发的《2026 Agentic Coding Trends Report》里提到,2025 年 agentic AI 改变了大量开发者写代码的方式,而 2026 年将是这种变革开始重构整个软件开发生命周期的一年。
而我自己,也大概是从 2025 年 下半年或什么时候开始,就没再手写过一行代码了,而是每天对着 Agent 说话数分钟甚至数小时……
Software 3.0 时代,并非即将到来、马上要来。
而是,就在当下。
◇ ◆ ◇
• Karpathy 的 Software 2.0 原文(2017):https://karpathy.medium.com/software-2-0-a64152b37c35
• AI Ascent 2026 完整视频:https://www.youtube.com/watch?v=96jN2OCOfLs
• Karpathy 的推文总结:https://x.com/karpathy/status/2049903821095354523
• Anthropic Harness 博客:https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
• Stephanie Zhan 的推文:https://x.com/stephzhan/status/2049518659513852109
• Sequoia Inference 关于 Software 3.0:https://inferencebysequoia.substack.com/p/andrej-karpathys-software-30-and
