 夜雨聆风
夜雨聆风分享一个近期的发文黄金组合:文档理解 + 多模态LLM!这方向巨火,因为它直指“文档GPT”这个终极应用。很多人觉得直接用GPT-4V就行,但它处理复杂版式时效果不佳,这就给专门模型留下了巨大的创新空间。
目前的“卡点”在于如何高效融合文本、版式和图像,单纯拼接外部编码器已经很难打动审稿人。因此,现在的创新路线都集中在让LLM自身学会“看”懂版面结构,比如设计轻量化方式注入2D位置信息,或用CoT预训练来教会它分析逻辑。发文时,核心就是讲清楚你的方法如何更优雅地解决效率与融合的痛点。
本文整理了8篇文档理解 + 多模态LLM前沿论文,附结构图+代码,旨在节省各位前期找资料的时间,帮助理清思路,快速找到最适合自己的创新点。强推对此感兴趣的朋友人手一份。


标题: URaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
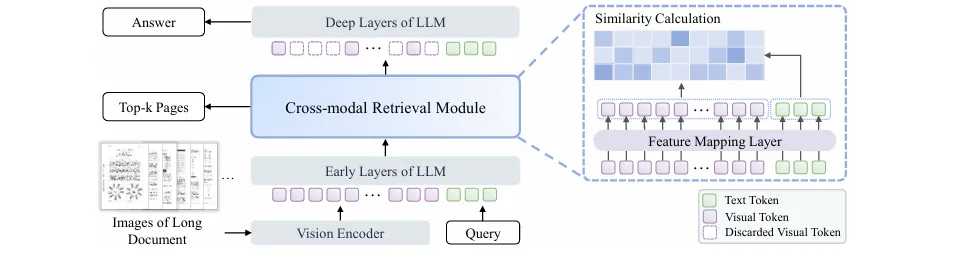
关键词: 长文档理解, 多模态大模型, 统一检索与生成, 计算效率, 从粗到细推理 单位: 华南理工大学, 华为技术有限公司 方法: 针对多模态大模型(MLLM)处理长文档时,因无关内容导致信息干扰以及Transformer架构二次方计算成本过高的问题,论文提出了URaG框架。该框架在一个单一的MLLM内部统一了检索与生成过程。其核心原理是受人类“从粗到细”阅读模式启发,通过引入一个轻量级跨模态检索模块,将MLLM的浅层Transformer转化为一个高效的证据选择器。该模块在推理早期识别并保留与问题最相关的页面,同时丢弃无关页面,从而让深层网络能集中计算资源于关键信息,以提升准确性和效率。
创新点:
本文中的关键公式如下: 使用上下文后期交互机制计算查询与每个文档页面之间的相似度得分:
其中, 和 分别是查询和第 个页面的特征序列。
检索模块使用以下损失函数进行优化:
其中, 和 分别代表正样本和负样本的得分。
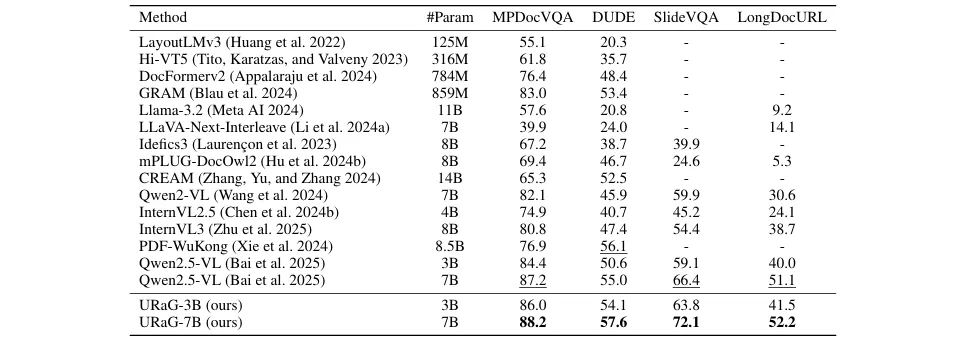
提出了URaG框架,在单一MLLM内部无缝集成了证据检索与答案生成,实现了端到端的优化,无需外部检索系统。 创新地设计了轻量级跨模态检索模块,利用MLLM的浅层隐藏状态进行证据定位,解决了外部检索器带来的系统复杂性和优化不一致问题。 通过在推理过程中动态丢弃不相关页面,有效缩短了深层Transformer的处理序列长度,显著降低了计算开销(实验表明减少了44-56%的FLOPs)。 首次通过系统性实证研究,揭示并利用了MLLM在处理长文档时固有的“从粗到细”推理模式,即浅层网络广泛关注、深层网络聚焦证据。
标题: DocLayLLM: An Efficient Multi-modal Extension of Large Language Models for Text-rich Document Understanding
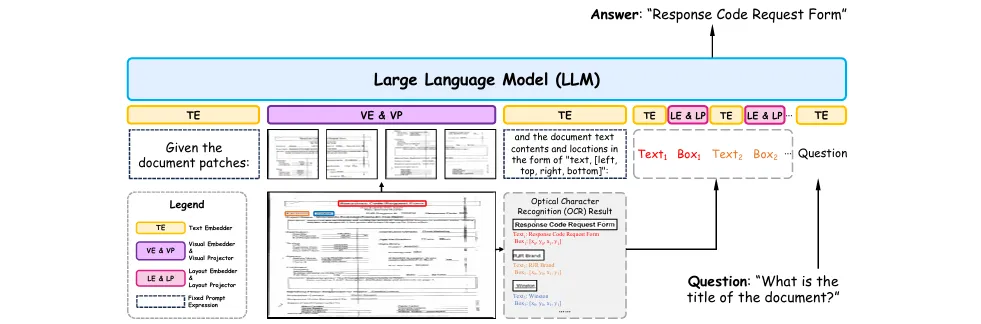
关键词: 富文本文档理解, 多模态扩展, OCR依赖, 思维链(CoT), 轻量化训练 单位: 华南理工大学, 阿里云计算 方法: 针对现有富文本文档理解方法要么计算资源需求大(如OCR-free方法依赖高分辨率图像),要么多模态融合效率低(如依赖外部文档编码器)的问题,论文提出了DocLayLLM。这是一种为LLM设计的高效多模态扩展方案。它通过将文档的视觉图像块(patch tokens)和2D位置信息(positional tokens)与OCR提取的文本内容一起,轻量化地整合到LLM的输入中。整个文档内容由LLM自身统一编码,充分利用了LLM强大的文本理解能力,并增强了其对OCR信息的感知,避免了使用额外的文档编码器。
创新点:
本文中的关键公式如下: 将文档图像块输入视觉编码器(VE)和视觉投影层(VP),得到视觉特征嵌入:
将OCR文本框坐标输入布局编码器(LE)和布局投影层(LP),得到布局特征嵌入:
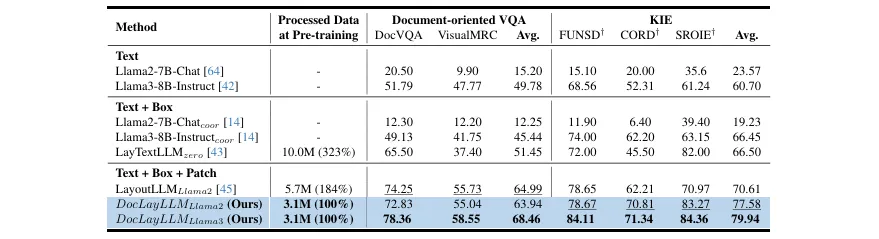
提出了一种高效的LLM多模态扩展方法,通过将文档图像块、2D位置和文本内容统一编码为LLM的输入,增强了模型对富文本档的理解能力。 创新地引入“CoT预训练”(CoT Pre-training)策略,通过从非问答数据中自动生成大规模带有思维链的训练数据,显著增强了模型的推理和文档理解能力。 首次从思维链角度审视数据退火,并提出了“CoT退火”(CoT Annealing)策略,在微调后期逐步增加直接答案数据的比例,提升了模型生成精确答案的能力和数据利用效率。 通过轻量化训练(仅用约3.1M预训练和300K微调数据),在多个基准测试上实现了超越现有OCR依赖和OCR-Free方法的性能,验证了方法的效率和效果。
本文整理了8篇文档理解 + 多模态LLM前沿论文,附结构图+代码,旨在节省各位前期找资料的时间,帮助理清思路,快速找到最适合自己的创新点。强推对此感兴趣的朋友人手一份。


