 夜雨聆风
夜雨聆风每天,老板或业务部门的同事都会把最新数据(通常是CSV或Excel格式)发给你,要求你导入数据库,以便BI工具能查询分析。日复一日,重复着“接收文件 → 打开数据库客户端 → 执行导入”的机械操作。
不仅枯燥,还极易出错。
有没有办法,能让这件事自动完成?答案是肯定的。今天介绍的主角是N8N —— 一个强大的开源自动化工具。只需一次配置,以后每天的数据导入工作就能在后台自动完成,彻底解放你的双手。
下面,我们就来搭建这个自动化流程。整个流程思路清晰,只有5个核心节点,就像搭积木一样简单。
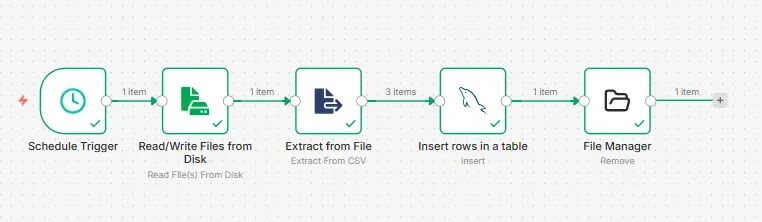
核心五步,搭建自动化流水线
1. 定时触发器
流程的第一个节点是Schedule Trigger。你可以把它理解为整个自动化的“闹钟”。在这里,你可以设置执行的周期,比如“每天上午9点”,“每周一早上”,或者更复杂的Cron表达式。它会在指定的时间自动唤醒整个流程,开始工作。
2. 文件定位器
接下来,使用 Read/Write Files from Disk 节点。你只需要告诉它一个服务器上的固定目录路径(例如 /data/inbox/)。到时候,它会自动去这个目录下寻找需要处理的文件。
3. 数据转换器
找到文件后,就需要解析数据了。
如果是CSV文件,使用 Spreadsheet File 节点,它能将CSV表格内容完美转换成后续节点可以处理的JSON格式。 如果是Excel文件,可以选择功能更强大的 Extract from File 节点系列中的Excel节点。
4. 数据库写入器
数据转换完毕,就到了关键一步——入库。使用 Postgres、MySQL 等对应的数据库节点,将上一步产出的JSON数据,通过标准的INSERT语句或批量操作,写入到目标数据库表中。这一步完成后,BI工具就能立刻查询到最新数据了。
5. 文件清理工
数据成功入库后,为了不占用磁盘空间,我们通常需要删除已处理的原文件。这里需要安装一个社区节点 n8n-nodes-filemanager。安装后,使用它的删除文件功能。
小提示:目前File Manager节点在删除“目录下所有文件”时,可能会误删目录本身。稳妥的做法是,在流程设计时就确保每次只处理一个明确命名的文件,或者通过其他逻辑确保安全。
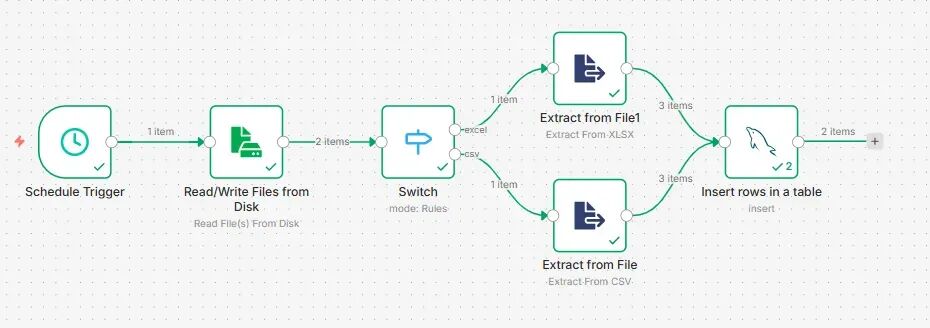
高阶玩法:兼容CSV与Excel双格式
如果你的数据源不固定,今天来CSV,明天来Excel,怎么办?
很简单,加一个 Switch 节点做智能路由。在读取文件后,用Switch节点判断文件扩展名(.csv 或 .xlsx),然后让不同格式的文件“走”不同的解析分支,最后再汇聚到统一的数据库写入节点。
行动起来,今天就开始自动化
至此,一个全自动的数据导入流水线就搭建完成了。之后你要做的,仅仅是每天在定时任务触发前,把需要处理的文件放到服务器指定目录。剩下的,就交给N8N吧。
从重复劳动中解放出来,把时间留给更有价值的分析、思考和决策。自动化不是为了炫技,而是为了让我们更专注于“人”真正擅长的事情。
希望这个流程能给你带来启发。尝试一下,你会发现,拒绝低效重复,有时候只需要一次勇敢的配置。

