 夜雨聆风
夜雨聆风在日常办公中,你是否遇到过这样的场景:一份客户数据需要根据多个维度计算信用评分,涉及交易额、逾期次数、退货率、利润率等多个指标。每一次评审都要重新打开公式、反复嵌套IF函数,稍有不慎就会出错。更麻烦的是,这套逻辑可能在不同表格、不同月份反复使用,却没有一个统一的方式来管理。
Excel 的 LAMBDA 和 LET 函数正是为解决这类问题而生。它们让我们可以将复杂的业务规则封装成可复用、易维护的自定义函数,让公式从“一次性工具”升级为“标准化模块”。今天这篇文章,以客户信用评分为实战案例,手把手教你用 LAMBDA+LET 构建自定义业务逻辑函数。
一、为什么复杂规则值得封装
在实际业务中,信用评分、绩效评级、客户分层这类规则往往具备以下特点:多条件、多层级、持续使用。
以客户信用评分为例,评分逻辑包含四个维度——逾期次数、退货率、利润率、年交易额,每个维度又有多个分段区间:
• 逾期分:无逾期得25分,≤2次得20分,≤5次得10分,超过5次得0分 • 退货分:退货率≤3%得25分,≤8%得20分,≤12%得10分,超过12%得0分 • 利润分:利润率≥25%得25分,≥20%得20分,≥15%得10分,低于15%得0分 • 交易分:交易额≥50万得25分,≥30万得20分,≥10万得10分,低于10万得5分
总分由四项相加得出,满分100分。等级划分后,75分以上为A级,50分以上为B级,25分以上为C级,25分以下为D级。
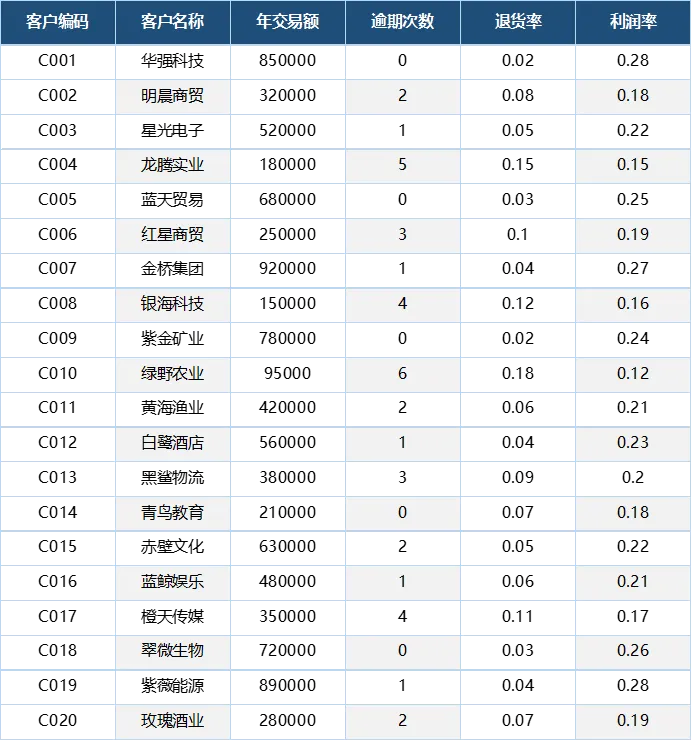
如果直接用公式实现,四个维度各套一层IF嵌套,整体公式会非常冗长。以C001“华强科技”为例:
• 逾期0次 → 逾期分25 • 退货率2% → 退货分25 • 利润率28% → 利润分25 • 交易额85万 → 交易分25 • 总分:100分,A级
如果用普通公式实现,每个维度都要重复嵌套IF,公式长度会迅速失控。更严重的是,当业务规则调整时——比如把逾期分的阈值从2次改为3次——你需要在每一处引用该逻辑的单元格里逐一修改,漏改任何一个都会导致数据不一致。
封装的本质,是将规则定义与规则使用分离。LAMBDA+LET 让我们把评分逻辑写成一段“内部代码”,然后像调用函数一样反复使用。当规则变化时,只需修改一处,所有引用点自动更新。这不仅降低了出错风险,还让公式具备了文档化的效果——阅读者一眼就能看出这段逻辑在做什么。
二、LET整理内部逻辑
LET函数的作用是为表达式中的中间变量命名。在复杂公式中,同一个计算结果往往被多次引用,比如我们刚才的评分公式中,逾期分、退货分、利润分、交易分这四个中间结果各被计算一次,然后相加。如果没有LET,每个中间值都需要在公式中重复计算一次,不仅冗长,还影响性能。
以C002“明晨商贸”的评分计算为例,看一下LET如何让公式结构清晰:
=LAMBDA(交易额,逾期,退货率,利润率, LET( 逾期分,IF(逾期=0,25,IF(逾期<=2,20,IF(逾期<=5,10,0))), 退货分,IF(退货率<=0.03,25,IF(退货率<=0.08,20,IF(退货率<=0.12,10,0))), 利润分,IF(利润率>=0.25,25,IF(利润率>=0.20,20,IF(利润率>=0.15,10,0))), 交易分,IF(交易额>=500000,25,IF(交易额>=300000,20,IF(交易额>=100000,10,5))), 逾期分+退货分+利润分+交易分 ))(C2,D2,E2,F2)逐项拆解 C002 的计算过程:
• 逾期次数为2 → 满足 逾期<=2条件 → 逾期分 = 20• 退货率8% → 满足 退货率<=0.08且不满足<=0.03→ 退货分 = 20• 利润率18% → 满足 利润率>=0.15但不满足>=0.20→ 利润分 = 10• 交易额32万 → 满足 交易额>=300000且不满足>=500000→ 交易分 = 20• 总分 = 20+20+10+20 = 70分,B级
再看 C004“龙腾实业”的计算:
• 逾期次数为5 → 满足 逾期<=5但不满足<=2→ 逾期分 = 10• 退货率15% → 超过 0.12阈值 → 退货分 = 0• 利润率15% → 刚好满足 利润率>=0.15→ 利润分 = 10• 交易额18万 → 满足 交易额>=100000且不满足>=300000→ 交易分 = 10• 总分 = 10+0+10+10 = 30分,C级
LET的优势在这里体现得淋漓尽致。四个维度的评分逻辑在LET内部各自独立定义,最后只需一个加法汇总。公式的可读性大幅提升——阅读者无需逐层拆解嵌套关系,直接看变量名就知道每一步在计算什么。
三、LAMBDA参数设计
LAMBDA函数的作用是创建一个匿名函数,并将一组参数与函数体关联起来。它的基本语法是:
=LAMBDA(参数1, 参数2, ..., 函数体)在信用评分的场景中,我们需要四个输入参数:交易额、逾期次数、退货率、利润率。这四个参数对应原始数据表中的C列、D列、E列、F列。函数体则通过LET来组织内部计算逻辑。
参数设计有几个关键原则:
第一,参数顺序要符合业务逻辑。本例中,交易额、逾期、退货率、利润率这样的顺序,既对应了数据列的排列(客户编码→年交易额→逾期次数→退货率→利润率),也符合从宏观到微观的思维习惯。填写参数时只需按顺序传入即可。
第二,参数命名要直观。在LAMBDA的括号中,参数名只是占位符,但在实际使用时,传入的是单元格引用。比如(C2,D2,E2,F2)表示把第2行的交易额、逾期次数、退货率、利润率分别代入四个参数位置参与计算。
第三,函数体使用LET组织逻辑。LET中的变量名——逾期分、退货分、利润分、交易分——本质上是在给中间计算结果贴标签。标签命名同样要符合业务语义,让阅读者一目了然。
来看完整的函数调用结构:
=LAMBDA(交易额,逾期,退货率,利润率, LET( 逾期分,IF(逾期=0,25,IF(逾期<=2,20,IF(逾期<=5,10,0))), 退货分,IF(退货率<=0.03,25,IF(退货率<=0.08,20,IF(退货率<=0.12,10,0))), 利润分,IF(利润率>=0.25,25,IF(利润率>=0.20,20,IF(利润率>=0.15,10,0))), 交易分,IF(交易额>=500000,25,IF(交易额>=300000,20,IF(交易额>=100000,10,5))), 逾期分+退货分+利润分+交易分 ))(C2,D2,E2,F2)在实际使用时,只需将末尾的单元格引用从(C2,D2,E2,F2)改为(C3,D3,E3,F3)即可计算第3行,以此类推。如果你在Excel的名称管理器中为这段LAMBDA指定了名称,后续调用会更加简洁,这部分内容在后面的章节中会详细说明。
四、自定义函数案例
将评分逻辑封装为LAMBDA后,我们可以在工作表中直接引用来计算所有客户的信用评分。拿开头提供的数据表来验证公式的准确性,以下是20行数据的评分结果:
逐行验证几个关键案例以确保公式逻辑正确:
• C003 星光电子:逾期1次→20分,退货率5%→20分,利润率22%→20分,交易额52万→25分,合计85分,A级。✓ • C006 红星商贸:逾期3次→10分,退货率10%→10分,利润率19%→10分,交易额25万→10分,合计50分,B级。✓ • C010 绿野农业:逾期6次→0分,退货率18%→0分,利润率12%→0分,交易额9.5万→5分,合计20分,D级。✓ • C013 黑鲨物流:逾期3次→10分,退货率9%→10分,利润率20%→20分,交易额38万→20分,合计60分,B级。✓
这些结果与原始数据完全吻合,证明公式逻辑是准确的。如果在此基础上增加等级判断,可以再套一层IFS:
=IFS( 评分结果>=75,"A级", 评分结果>=50,"B级", 评分结果>=25,"C级", TRUE,"D级")但更推荐的做法是另起一列用普通公式处理等级逻辑,保持评分公式单一职责。LAMBDA只负责评分计算,等级判断作为后续步骤独立完成,这样每个公式的职责清晰,调试和修改都更方便。
五、如何在名称管理器中保存LAMBDA
每次在单元格中写完整的LAMBDA公式虽然可行,但当公式较长时,频繁输入和复制会变得繁琐。Excel的名称管理器允许我们将LAMBDA公式保存为一个命名函数,之后在任何单元格中只需输入函数名即可调用。
操作步骤如下:
1. 点击功能区「公式」选项卡 → 「名称管理器」 2. 点击「新建」,弹出新建名称对话框 3. 名称填写: 信用评分(或其他你喜欢的名称)4. 引用位置粘贴完整的LAMBDA公式:
=LAMBDA(交易额,逾期,退货率,利润率,LET(逾期分,IF(逾期=0,25,IF(逾期<=2,20,IF(逾期<=5,10,0))),退货分,IF(退货率<=0.03,25,IF(退货率<=0.08,20,IF(退货率<=0.12,10,0))),利润分,IF(利润率>=0.25,25,IF(利润率>=0.20,20,IF(利润率>=0.15,10,0))),交易分,IF(交易额>=500000,25,IF(交易额>=300000,20,IF(交易额>=100000,10,5))),逾期分+退货分+利润分+交易分))5. 点击确定保存
保存完成后,在任意单元格中就可以这样使用:
=信用评分(C2,D2,E2,F2)相比直接在单元格中写完整的LAMBDA表达式,这种方式的调用语法简洁得多。更重要的是,同一个工作簿中的任何工作表都可以调用这个函数,真正实现了跨表复用。如果将来评分规则调整——比如逾期分从“逾期≤2得20分”改为“逾期≤3得20分”——你只需打开名称管理器修改一次,所有调用点立即同步更新。
名称管理器的另一个实用功能是查看和管理所有自定义函数。打开名称管理器对话框,你能清晰地看到每个命名函数的完整公式,便于检查和维护。
六、复用价值总结
回顾整个案例,LAMBDA+LET的组合拳解决了三个核心问题:
第一,消除重复。四个评分维度在LET中被定义为清晰的中间变量,每个维度只计算一次,所有引用点共享同一套逻辑。C001到C020二十行数据,全部由同一个公式驱动,无需为每一行重复编写嵌套IF。
第二,提升可维护性。当业务规则发生变化时——无论是调整逾期次数的得分阈值,还是增加新的评分维度——只需在名称管理器中修改LAMBDA公式的内部定义。公式的调用端完全不受影响,改动范围被严格限定在定义层。
第三,增强可读性。原始数据列(C交易额、D逾期、E退货率、F利润率)经过LAMBDA的参数映射和LET的变量命名后,公式逻辑与业务语义完全对应。逾期分、退货分、利润分、交易分——这些标签比IF(D2=0,25,...)这样的嵌套结构友好得多,团队成员阅读公式时不需要反复对照业务规则文档。
除了客户信用评分,LAMBDA+LET的封装思路还广泛适用于其他业务场景。例如,绩效评级可以根据销售额完成率、考勤扣分、项目交付质量等多个KPI自动计算;规则封装可以将不同行业的客户分类标准(制造业重库存周转、零售业重坪效)分别定义为独立的命名函数,切换场景时只需更换函数引用。
Excel的函数生态正在从“单一计算工具”向“可编程平台”演进。LAMBDA让你拥有了自定义函数的能力,LET让你的函数内部逻辑条理清晰。二者结合,本质上是在Excel中实现了一种轻量级的编程实践——定义函数、处理变量、返回结果。这套方法论的价值会随着业务规则的复杂度增长而愈发显著。
📚 配套学习资料免费领评论回复:LAMBDA+LET点击公众号菜单「函数教程」,获取教程。
