 夜雨聆风
夜雨聆风
From Context to Skills: Can Language Models
Learn from Context Skillfully?
报告原文地址:https://arxiv.org/pdf/2604.27660
报告概述
这篇由清华大学等机构联合发布的论文《From Context to Skills》,针对大语言模型在长文档、专业手册中“现学现用”的短板,提出一个无需人工标注、无需外部奖励信号的技能自动提取框架 Ctx2Skill。该框架通过多智能体自我博弈,从复杂上下文中自主挖掘可复用的自然语言技能,并在 CL-bench 基准上将 GPT‑4.1 的解决率从 11.1% 拉升至 16.5%,GPT‑5.1 从 21.1% 拉升至 25.8%。
核心洞察
技能发现可以告别“人海战术”:以往需要领域专家逐条总结文档才能构建的技能库,现在被一个 Challenger-Reasoner 对抗系统取代,完全自动化,且不依赖任何外部校验信号。
自我博弈中的“防崩盘”机制比迭代本身更重要:不加约束的多轮对抗会导致技能过度特化、反噬通用能力,Ctx2Skill 用跨时间重放选出平衡点,这是性能稳定的关键。
强模型产出的技能可以“降维”赋能弱模型:GPT‑5.1 生成的技能套用在 GPT‑4.1 上,效果接近 GPT‑4.1 自己生成的技能,但反过来提升有限,说明技能质量天花板由生成方的认知水平决定。
一、大模型为什么需要“现学现用”?
当前语言模型在竞赛数学、编程挑战等任务上表现亮眼,但这些任务的知识大多已存在于预训练数据中。现实世界的大量任务要求模型面对从未见过的专业上下文——比如一份刚发布的产品维修手册、一份临床试验报告——并直接从中学习规则、步骤,然后解决相关问题。这种能力在论文中被定义为上下文学习。
然而,实验数据戳破了对长上下文窗口的幻想。CL‑bench 测试中,当前最先进的模型 GPT‑5.1 整体解决率也只有 21.1%,Gemini 3 Pro 为 15.8%,说明即便把文档完整“喂”给模型,它也很难真正内化其中的程序性知识并将其用于推理。
图1:Ctx2Skill 的设计理念
图1直观展示了 Ctx2Skill 的核心思路:从冗长的技术文档中,自动提炼出一组清晰、可复用的自然语言技能,这些技能如同“思维脚手架”,能让任意模型在后续任务中更快、更准地调用上下文知识。
二、没有老师,没有考卷,如何自学技能?
搭建这样一个自动技能提炼系统,面临两个死结:人工标注代价过高,文档动辄数十页且技术密集;外部反馈信号缺失——没有执行结果或标准答案来判断技能的好坏。Ctx2Skill 的解法是构建一套带自我进化能力的多智能体自我博弈循环。
图2:Ctx2Skill 整体框架
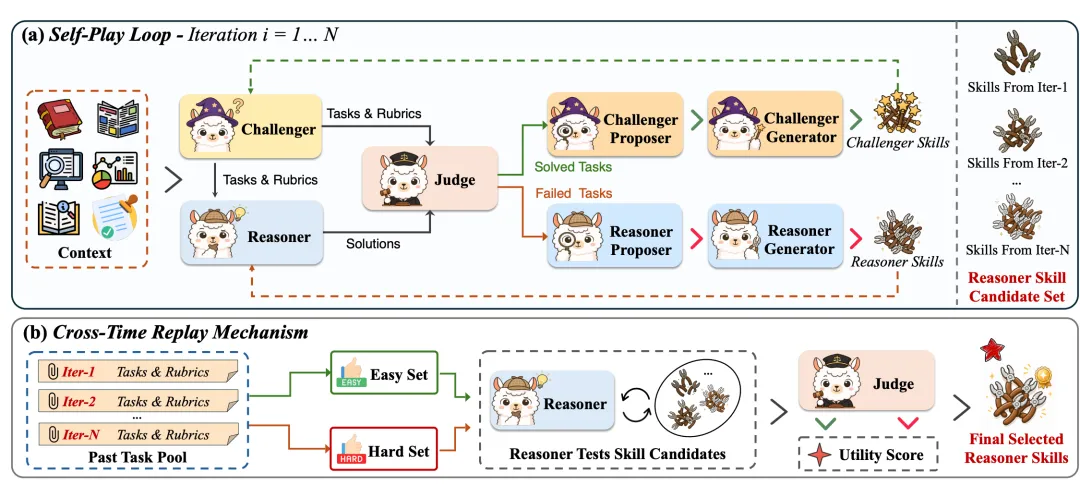
图2由上下两部分构成:上方的自博弈循环中,Challenger 出题、Reasoner 答题、Judge 判分,并按失败/成功将案例分流给各自的技能更新流水线;下方的跨时间重放机制则从历史技能快照中选出泛化最强的版本。
在每一轮迭代中,五个固定权重的语言模型角色分工协作:
Challenger:根据自己积累的技能集,从上下文生出数个任务与对应的判分规则,目标是探出 Reasoner 的薄弱点。
Reasoner:借助当前技能集作答。
Judge:严格按规则给“通过/不通过”的二元判定。
Proposer(两侧各一):分别汇总 Reasoner 没做对的案例和 Challenger 被轻易破解的案例,诊断当前技能的全盘缺口,输出一份高层次的修改建议。
Generator(两侧各一):把建议变为具体的技能文件更新。
这套机制的关键在于:Challenger 绝不是固定的出题机器,它也拥有自己的技能集并不断进化,形成持续的竞争压力;而 Reasoner 的技能更新也完全由失败案例驱动,逐步补齐知识盲区。整个过程没有任何参数更新,也没有使用任何外部反馈,所有改进都以自然语言技能文件的形式沉淀下来。
然而,纯粹的持续对抗会引发一种“内卷式崩坏”——Adversarial Collapse。随着迭代次数增加,Challenger 会产出越来越极端、偏离上下文主流知识的任务,Reasoner 的技能也随之长成“奇技淫巧”,反而在正常任务上性能退化。
为此,Ctx2Skill 设计了一个跨时间重放机制。在每轮结束时,系统会把当前最难的失败案例和最易的成功案例分别存入“硬探针集”与“易探针集”。全部迭代结束后,用历轮 Reasoner 技能快照重新回答这两组题目,计算硬题解决率与易题解决率的乘积,选出乘积最高的那一轮技能作为最终输出。这个乘积式的设计非常聪明:既能踢掉那些只顾啃硬骨头却丢了基本盘的后代技能,也能淘汰安于现状的早期版本,保证所选技能集既稳健又精进。
三、数据说话:GPT‑4.1 解决率从 11.1% 到 16.5%,而且技能还能跨模型移植
实验在专门测试上下文学习能力的 CL‑bench 上进行,涵盖领域知识推理、规则系统应用、程序性任务执行和经验发现与模拟四大类。
表1:Ctx2Skill 主要结果(节选)
| Ctx2Skill | 16.5 | +5.4 | ||
| Ctx2Skill | 25.8 | +4.7 |
表1显示,在 GPT‑4.1、GPT‑5.1、GPT‑5.2 三个主干模型上,Ctx2Skill 不仅每次都带来大幅绝对提升,且相比“让模型单次通读文档直接总结技能”的 Prompting 方法和基于滑动窗口的 AutoSkill4Doc,优势稳定在 3–4 个百分点以上。
任务难度分布也值得注意。在需要深度归纳和步骤还原的“程序性任务执行”与“经验发现与模拟”两类子场景中,Ctx2Skill 对 GPT‑4.1 的增益分别达到 +7.2% 和 +5.1%,远高于简单检索类问题,说明框架挖掘出的技能确实凝结了隐性程序知识,而非单纯的信息摘抄。
图4:GPT‑4.1 各子类别解决率变化
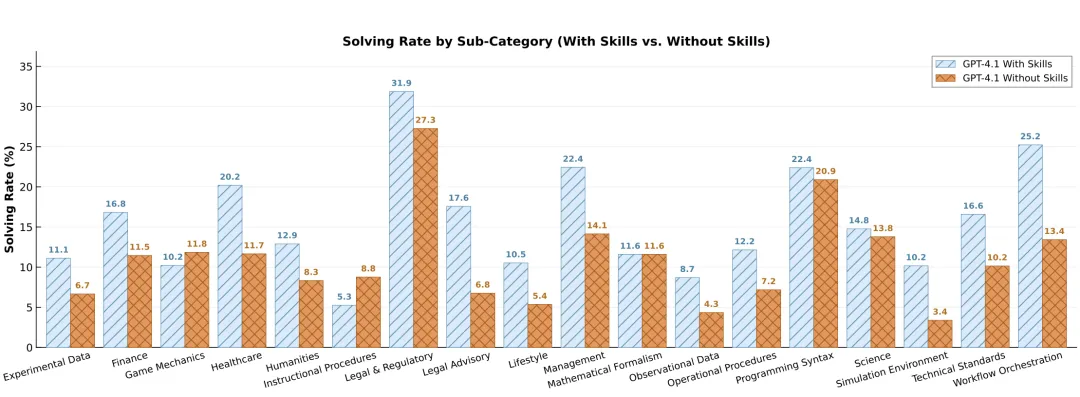
从子类别雷达图可看到,绝大多数任务类型都获得正向提升,尤其在“工作流编排”子项上提升高达 11.8 个百分点,验证了技能在结构化推理中的价值。
表3 消融实验要点(GPT‑4.1 / GPT‑5.1)
消融实验传递出最清晰的信号:移除 Challenger 的技能进化机制导致性能下滑最剧烈,因为 Reasoner 失去了有效的对抗压力,知识挖掘不充分;关闭跨时间重放后,用最后一轮技能直接上场,性能大幅倒退,验证了后期技能过拟合的存在。
技能迁移实验还揭示了一个有趣的不对称现象:GPT‑5.1 产出的技能交给 GPT‑4.1 使用,整体解决率达到 16.1%,几乎与 GPT‑4.1 自产技能持平;但 GPT‑4.1 的技能给 GPT‑5.1 用时,提升幅度明显缩水。这说明强模型不仅能为自己,也能为弱模型提取出高质量的程序性知识,但弱模型受限于认知能力,无法充分“萃取”出同等水平的技能。
图3:跨时间重放所选迭代的分布
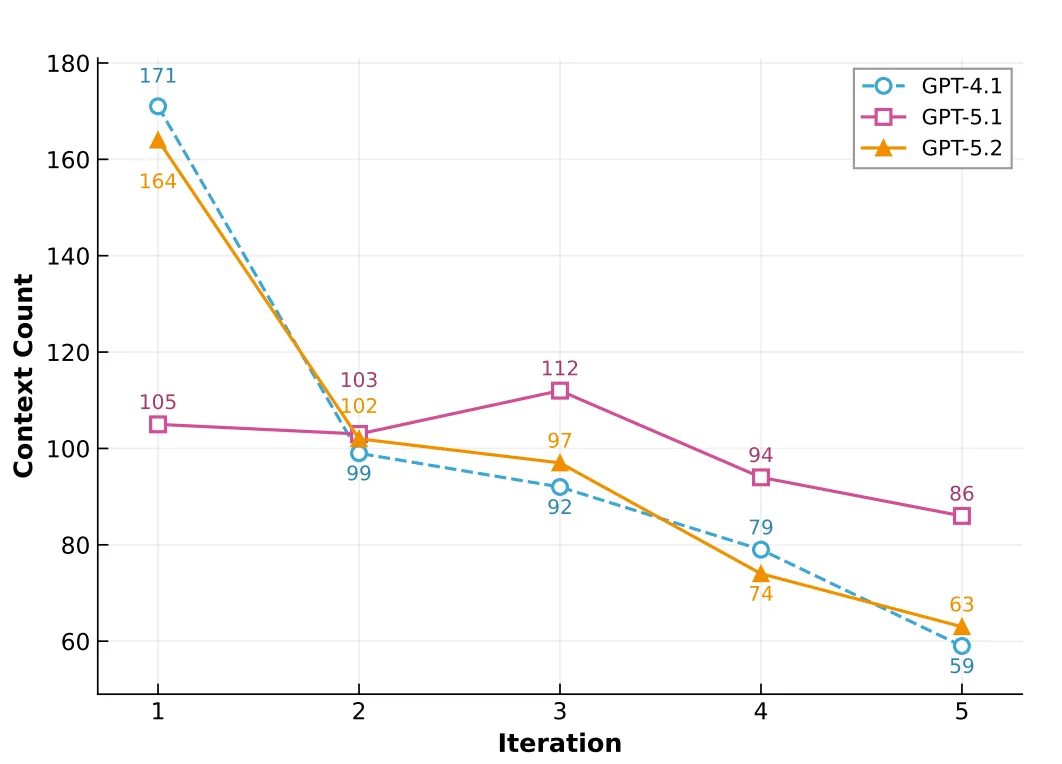
从图中可以看到,最优技能快照多集中在前几轮,印证了早期技能已经捕获大量核心知识;但也有一定比例的后代迭代被选中,说明对于知识结构更复杂的文档,多走几轮对抗确实有帮助。
结语:当“学技能”不再是人类的特权
Ctx2Skill 提供了一个务实的范式:大模型不再只是被动地用长上下文窗口“硬读”文档,而是能够主动将文档消化为一组可执行、可迁移的技能,进而让任意模型在相同文档上获得立竿见影的能力加成。对于需要频繁处理手册、标准、法规等行业用户来说,这意味着有可能建立一个自动化的文档→技能流水线,大幅降低定制化应用的门槛。
当然,这依然只是开始。当前单次文档大约需要 5 轮自博弈,消耗一定的 API 资源,且技能质量直接受限于生成方的模型能力。但对于那些看重精度远胜于成本的场景,用一个强模型生产技能、再由更廉价的模型大规模部署,已经是触手可及的策略。未来,如何将这一套自进化机制扩展到多模态上下文、融入工具调用反馈,将是更有想象空间的下一站。
