 夜雨聆风
夜雨聆风本文共约6100字,预计阅读时间 8-10分钟。
"我这周让 AI 帮我写了 80 条商品页主标题、20 个 EDM 主题、30 个广告 hook,太爽了。"
这是上个月一个出海护肤品牌的内容负责人 Lin 在群里说的话。她团队两个人,过去三周做的活,AI 一周帮她做完了。
她接下来做的事,是凭直觉从这 130 条里挑了 12 条全部上线——4 条铺给商品页,3 条进 EDM,5 条进 Meta 广告投放。

月度复盘时,ROAS 跌了 35%,邮件打开率从 22% 滑到 14%。她在复盘文档里写了一句话——"感觉每一条文案都被用户'看烦了'。"
她以为 AI 给的是产能。但实际跑下来,AI 也连带送来了另外两件事——"决策疲劳"和"用户注意力配额加速耗尽"。
这不是 Lin 一个人的故事。Criteo 在 2026 年 3 月发表的文章《From Sameness to Standout: The Next Era of DTC Brands》里有一个判断很扎心——DTC 行业过去赖以胜出的几大战术,performance marketing、网红合作、订阅模型,已经全部沦为“基本面”,单靠这些再也跑不出来。大量品牌正在被淹没在 Criteo 所说的 “同质化的海洋”里。
而 AI 量产文案,正在加速这片海洋的扩张。不是 AI 写得不好。是写得太多,又太轻易地全部上线了。
本文想和大家聊一件反直觉的事——AI 时代越来越紧缺的可能不是产能,而是过滤器。
而 A/B 测试在 AI 时代的角色,可能已经不再只是"假设验证工具",更像是一个"反向筛选器"。它的真正价值不再只是从 50 个版本里找出那 1 个赢家,而是在你的用户还没看到之前,把那 49 个不该上线的版本提前关掉。
一、当产能从 5 倍变 50 倍:你看到的不是机会,是决策灾难
AI 量产带来的"产能幻觉"
在 AI 之前,一个内容运营一周能写 5 条商品页 H1、3 个 EDM 主题、4 个广告 hook,已经算合格产出。随写得慢,但每一条都过脑子,每一条都有自己的判断。
AI 之后呢?她一天就能产出 50 条。第二天再来 50 条。一周下来 200-300 条。
这看起来是 50 倍产能。但请诚实回答:你真的有能力在 50 个商品页主标题里"凭直觉"挑出最好的那 3 个吗?
认知心理学里有一个被反复研究的现象叫"决策疲劳"——当备选项的数量超过一定阈值,人的决策质量会明显下滑,常见的走向是两种极端:要么彻底放弃决策("算了 12 条全部上线吧"),要么退回到熟悉的偏见("我看这条像我们品牌的语气,就这条")。AI 把决策成本从"写"转移到了"挑",但人的挑选能力并没有跟着 AI 同步放大。
"全部上线"的隐藏代价
紧接着的第二个动作可能更值得警惕。一旦"全部上线"被默认成 AI 时代的合理选择,下面这三件事很容易同时发生。
第一,用户的注意力配额被消耗。同一类用户在两周内被你的 12 个版本反复触达,他们对你品牌的所有文案都开始麻木。这不只是广告疲劳,是品牌疲劳——比广告疲劳更难逆转。
第二,品牌识别度被你自己稀释。当你的 12 个商品页主标题风格各异、CTA 各不一致、价值锚点跳来跳去,新用户根本拼不出"这是个什么品牌"的整体感。
第三,数据反馈失真。当 12 个版本在同一时间窗口里抢同一波用户,谁也不能干净地反映自己的真实表现。你以为你在做测试,其实你在做一锅噪声极大的乱炖。
Liquid Death 的"反同质化"押注
Liquid Death 是一个把普通矿泉水卖成 14 亿美元估值的美国品牌,所有 social copy、广告 hook、产品描述都来自一个小到"塞得进一辆大 SUV"的内部创意团队(这是创始人 Mike Cessario 公开聊过的描述),由 VP Creative Andy Pearson 带队,他们把自己定位成"一个碰巧在卖水的娱乐公司",不是"一个会做广告的水公司"。
Cessario 在 2025 年讲过他们对 AI 的态度——他们不"对抗 AI",但 AI 在他们手里的角色是"被训练成像他们那样思考的工具",而不是直接产出能上线的内容。他原话的意思是:创意团队的价值不在 output(产出量),在 vision(判断力)。这种价值排序决定了——哪怕 AI 一天能写 100 条文案,没经过这套创意判断的版本,仍然不会被推上线。
Liquid Death 的反向证明很清楚:当所有人都让 AI 量产泛文案时,"少而锋利"的差异化叙事才是穿透注意力的护城河。它不是反对 AI,它反对的是"AI 量产 + 直接上线"这条流水线。
而对大多数没有 Liquid Death 这种创意密度的品牌来说,要解决的不是"换个团队手写",而是装一个工业级的过滤器。
二、换个思路:A/B 测试不是"挑赢家",是"杀输家"
A/B 测试在前 AI 时代的角色
A/B 测试在之前的角色非常清晰——一个谨慎的运营提出 1 个假设(比如"把 CTA 从'立即购买'改成'今天试试'是否更好"),跑 14 天,看显著性,决定要不要采用。
之前可以把 A/B 当做是验证器。一次跑 1 个假设、2 个版本,慢慢攒一年下来30+有效结论。

这套节奏在 AI 时代撑不住了。当 AI 一天能给你产出 50 个候选版本,你不可能用"一周跑一个 A/B"的速度消化。如果坚持老节奏,要么积压几百个版本永远等不到测试,要么就是 Lin 那种凭直觉全上线的灾难。
AI 时代的角色重定位:从验证器到过滤器
这个时候 A/B 测试可能需要被重新定义——它的真正价值不再只是"挑出那 1 个对的",更值钱的是"快速且批量地砍掉那 49 个错的"。
这两个动作听上去像同义词,其实差很远。
"挑出对的"是一种正向逻辑,它要求你在测试结束时给出一个干净的赢家结论。这种逻辑下,每个测试都要等"统计显著"才能下结论,时间成本很高。
"砍掉错的"是一种反向逻辑。它的目标是用最低的暴露成本,把明显跑不赢的版本提前关掉,让剩下的少数几个进入正式比较。它不要求每一轮都给出赢家,它只要求每一轮都筛掉一批。
"挑赢家"是一年验证 30+假设。"杀输家"是一周过滤 50 个候选——筛剩 5-10 个进入下一轮。
Booking.com 的工业化过滤逻辑
Booking.com 是这个思路最极致的工业化样本。这家公司在多个公开演讲里披露过一个数字——他们每年同时跑超过 25,000 个 A/B 测试。任何一个用户访问 Booking.com 时,平均会被分配到 50-100 个不同的实验组。
很多人看到这个数字会以为他们的产品团队是天才,能想出 25,000 个假设。但仔细看 Booking.com 内部对 A/B 测试角色的定义就会明白——他们从来没把 A/B 测试当作"找最优解的工具",他们把它当作"快速否决次优解的过滤器"。
Booking.com 多位前产品负责人在公开演讲里都讲过一个事实:他们绝大多数的 A/B 测试结果是"没有显著差异"或"新版本输给老版本"。这意味着相当比例的实验本质上是在确认"这个改动不值得上线"。这不是低效,这是过滤系统的正常工作状态——把绝大多数候选项干净地拒掉,让真正有差异的少数版本浮出来。
如果你接受这个视角,AI 量产对你来说就不是负担。它是一个让过滤器有更多原料可筛的输入端。
三、AI 内容反向过滤的 3 个机制
理念讲清楚了,下面是落地。具体到独立站操作面上,"反向过滤" AI 内容有三个机制。
机制一|分层圈选:别让 50 个版本和你最值钱的用户对赌
这是最容易被忽视、也是代价最大的一步。
很多团队做 A/B 测试的默认做法是"100% 流量分两半,一半看 A,一半看 B"。在测试 1-2 个深度假设时这套思路没问题。但你现在面对的是 AI 量产的 50 个候选版本,其中至少 30 个是要被淘汰的。这种情况下还做 50/50 全量分流,等于让你最值钱的用户去当"陪测员"。
实操上更稳的做法是分层圈选。
把流量切成两层——已验证的稳定基线(比如旧版本的商品页文案)保留 90-95% 流量;测试候选版本只跑 5-10% 流量。这 5-10% 也不是随便分的,圈选时优先用"低 LTV 用户"或"新访客组",避免让高价值老客户去承担测试摩擦。
这件事在 Ptengine 的后台就是一个组合动作——先在数据中心圈出"高价值用户组"和"新访客用户组",再在 A/B 测试模块自定义流量配比,给新版本设置 5-10% 的小流量。这样即便 AI 量产的 49 个版本在 5-10% 流量上彼此互殴,也不会动摇你的主盘。
Ritual 的"老客户体验防火墙"
Ritual 是把"测试克制"做出风格的 DTC 案例。这家做女性维生素订阅的美国品牌在落地页和内容迭代上有一套被公开聊过的工作流——先把数据流的可信度打牢,再用最简单的实验确立测量基线,最后才允许快速实验进入更复杂的内容层。换句话说,他们不会让"AI 一次产出的 50 个候选"直接面对全量用户去赌——基础测量框架和小流量预筛是放在快速迭代之前的硬规则。
逻辑也很清楚:订阅模型的 LTV 高度依赖"用户对产品体验的预期一致性"。一个老用户上周看到的是 A 风格、这周登录变成 B 风格、下周又变成 C 风格,她对你产品到底是什么的认知会开始模糊。模糊的瞬间,就是订阅取消的瞬间。
新版本的责任是抢新流量,不是教育老客户。
机制二|短周期 A/B + 主动停损:让"杀版本"成为一个常规动作
机制一处理"测试摩擦的边界",机制二处理"过滤速度"。
传统 A/B 测试的默认终点是"等到统计显著性达到 95% 才下结论"。这套标准对一个深度假设来说很合理,但当你面对的是 AI 量产的几十个候选时,等到完整显著性可能已经晚了——你不一定需要"非常确定 B 版本输给 A 版本"才能动手,很多时候只要"差不多确定它跑不赢,就提前关掉它"。
把这件事做成节奏,会比硬等显著性更顺手——把每个 A/B 测试的窗口切得更短,比如把第一个 48 小时设为"早期信号检查点",第三天再做一次中期复盘。每次检查点上,对那些数据明显落后的版本(点击率落差 30% 以上、加购率落差 50% 以上等等,按品类自己校准阈值),直接做主动停损,腾出来的流量回流到剩下的候选上。
这套机制的实操参数其实很直接——把"什么时候查、查什么、达到什么差距就停"这三件事写进流程,团队对齐一遍,就不需要每天盯着仪表盘纠结"这个版本要不要继续跑"。运营最稀缺的资源是注意力,他应该把注意力花在两件更重要的事上:上游产新版本、下游定方向。
Hims & Hers 的"多落地页 + 持续 A/B"打法
Hims & Hers 是 DTC"多落地页 + 大规模 A/B"打法被业内反复研究的代表。这家公司每季度向付费投放投入约 1.82 亿美元(接近营收一半),独立站日均访客约 200 万——这些数字都是公开披露的。它的核心打法不是给每个产品写一版精修落地页,而是按"用户心态切片"准备多个版本:脱发用户、护肤用户、心理健康用户每一类都有自己专属的落地页和文案路径,每条路径内部又持续做 A/B 迭代。
这种规模下,"凭直觉挑赢家"在实操上几乎走不通。他们的解法更接近"把决断权交给数据":每个版本进 A/B,跑不赢的就被主动停掉,流量回到剩下的候选上。整个流程的瓶颈往往不在"多产几条文案",而在"过滤器的速度能不能跟得上产能"。这可能就是 AI 时代 A/B 测试该有的样子——它的角色更像是替你把不该上线的东西先干掉。
机制三|内容差异度审计:区分"真测试"和"换皮测试"
机制一和机制二是过滤器的"硬件"。机制三是过滤器之前的过滤器——它确保你交给过滤器筛的东西,本身值得被筛。
AI 写的 50 个版本,往往只是"换词不换骨"。它会替换形容词、调整语序、轮换 CTA 动词,但底层的价值锚点和叙事结构基本没动。这种情况下你跑 A/B,跑出来的结果大概率都是"没有显著差异"——因为它们本来就是同一个版本的多个化身。
判断方法可能不是看文字本身,更可靠的是看用户行为。
Casper 的"规格 vs 场景"审计样本
Casper 床垫的产品文案有两种典型路径——
规格化路径:"7 层混合弹簧加高密度记忆棉,承托压力均匀分布,零度温感不闷热"。
场景化路径:"醒来的那一刻,肩膀第一次没有抗议。"
如果让 AI 围绕规格化路径产出 50 个版本,大概率你会得到 40 个"换形容词换数字"的同义改写——密度从 7 层变 9 层、形容词从均匀变服帖、CTA 从立即购买变今天体验。这 40 个版本投放到测试流量上,用户的注意力轨迹几乎没有差异——视线落点一致、停留时长相近、点击位置相同。
但只要 1-2 个版本切到场景锚点,注意力分布会立刻重构——视线会更深地下沉到 CTA 区域、CTA 上方的停留时间显著拉长、相邻的"睡眠故事"模块会被点开。
这两类差异是文案产出阶段就该被识别的。注意力热图和点击热图正是为这件事而设计——把 AI 量产的版本投放到一小块测试流量上,看用户的注意力轨迹是否在不同版本间形成"视觉差异度"。如果差异度高,进入机制一和机制二;如果差异度低,立刻打回 prompt 重写阶段。这一步省下的时间和用户耐心,远比测试结果本身值钱。
四、把"AI 量产 + A/B 反向过滤"装成一条 5 天流水线
理论说清楚了,最后给一份可执行的工作流——下周就能开跑的版本。
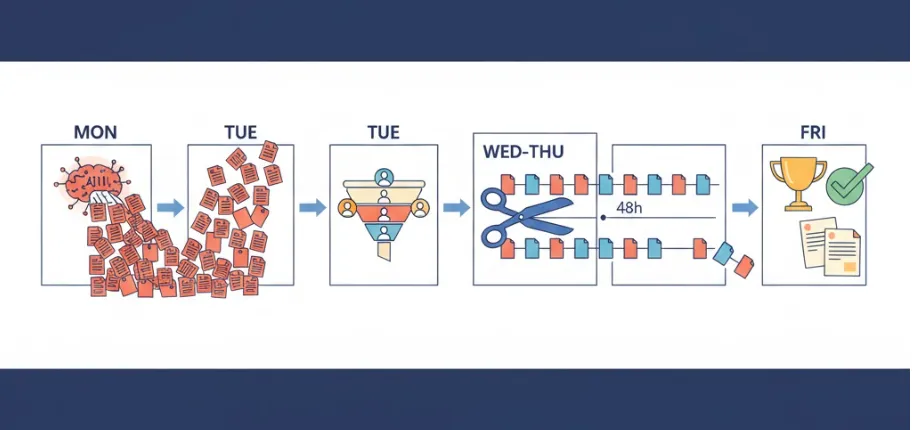
周一|AI 生产 → 50 个候选
让 AI 围绕一个明确目标(比如某个商品页的 H1、某个 EDM 主题)产出 30-50 个版本。先不预设赢家,保留多样性。这一阶段建议不要做太多人工筛选——在这个数量级,人的直觉判断很难保持准确。
周二|差异度审计 + 用户组分配
第一,把 50 个候选丢进机制三的差异度审计:用注意力热图小规模预投放(500-1000 UV 即可),过滤掉"换皮测试"的版本,只留下真有差异的 15-20 个。
第二,配置机制一的分层圈选:5-10% 的新访客流量进入测试组,90-95% 的高价值用户保持基线体验。
周三-周四|短周期 A/B + 主动停损
启动 A/B 测试,把检查节奏定成 48 小时一查。两天后做第一次早期信号复盘——明显落后的版本直接停掉,不必等正式显著性。停损的差距阈值要团队提前对齐(比如点击率落后 30% 以上停、加购率落后 50% 以上停)。剩下的版本继续跑到周五。
周五|决赛 + 定稿
剩下的 5-10 个版本进入正式 A/B 决赛,跑 7-14 天定稿。这一步用的是传统 A/B的严谨标准,因为剩下的少数版本值得这个等待。
OODA 循环加速
这条流水线本质上是把 OODA 工作法(观察→定位→决定→执行)从月度循环压缩到周度循环——每周完成一次完整的"产-测-淘-放",每周给出一个可信赖的赢家。
更值得留意的是,你看测试报告时关注的指标可能也得变。过去你大概只看"哪个版本赢了"。现在更值得留意的是——50 个候选里有多少在 48 小时早期信号检查时就被你主动停掉,多少进入决赛,决赛赢家比基线提升多少。前两个指标更接近 AI 时代过滤器健康度的真实信号。
结语
写到这里,想再回到开头 Lin 的那句话——"我让 AI 帮我写了 130 条,太爽了。"
她真正的失误,不在于"用了 AI",而在于"相信了 AI 给的那种产能感"。每个走得久一点的内容操盘手最后都会验证一个事实——决定一个品牌能走多远的,从来不是产能,而是过滤的克制。
AI 没有改变这条规律,AI 只是把它放大了。
你过去一周写 5 条、凭直觉挑 1-2 条上线,赌的是判断力别出错。现在你一周能产 50 条,赌的是流程能不能替你扛住"决策疲劳"。后者要赢,已经不太只是依靠判断力本身了——更多需要的是流程和数据替你的直觉做一道"冗余备份"。
A/B 测试可能就是这道备份。它不是来证明你聪明的,更多时候,它是来替你兜底直觉的。
如果你愿意,下周一可以试一件不大但具体的事——挑你最近 AI 写的某一类文案(商品页 H1 或 EDM 主题都行),选 5 个候选,分配 5% 流量,48 小时回头看一次,主动停掉明显跑不赢的那 1-2 个,剩下的继续跑。一周下来你大概率会拿到两个小小的意外:你"很喜欢"的版本,往往是数据最先关掉的那一批;最终跑赢的那一两个,也往往不是你凭直觉会挑的那个。
这不是工具的胜利,更像是流程的胜利。AI 已经替你把产能问题基本接住了。
下一关,要看你的过滤器了。
END
往期回顾


