 夜雨聆风
夜雨聆风点击上方卡片关注我
MBZUAI(穆罕默德·本·扎耶德 AI 大学)和 UCL(伦敦大学学院)的研究团队最近发了一篇 40 多页的论文,把 Claude Code 公开的 TypeScript 源码从头到尾拆了一遍。
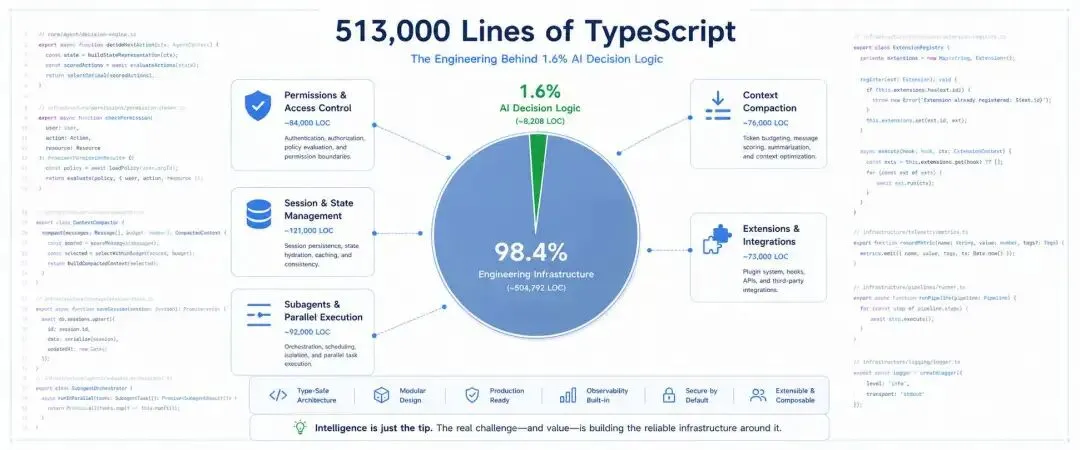
结论挺有意思的,513,000 行代码里,真正跟 AI 决策相关的只占 1.6%。剩下的 98.4% 全是工程基础设施:权限管理、上下文压缩、会话存储、工具调度这些。
这个比例本身就说明一个问题:做一个好用的 AI 编程工具,模型能力只是起点,真正的壁垒在工程。
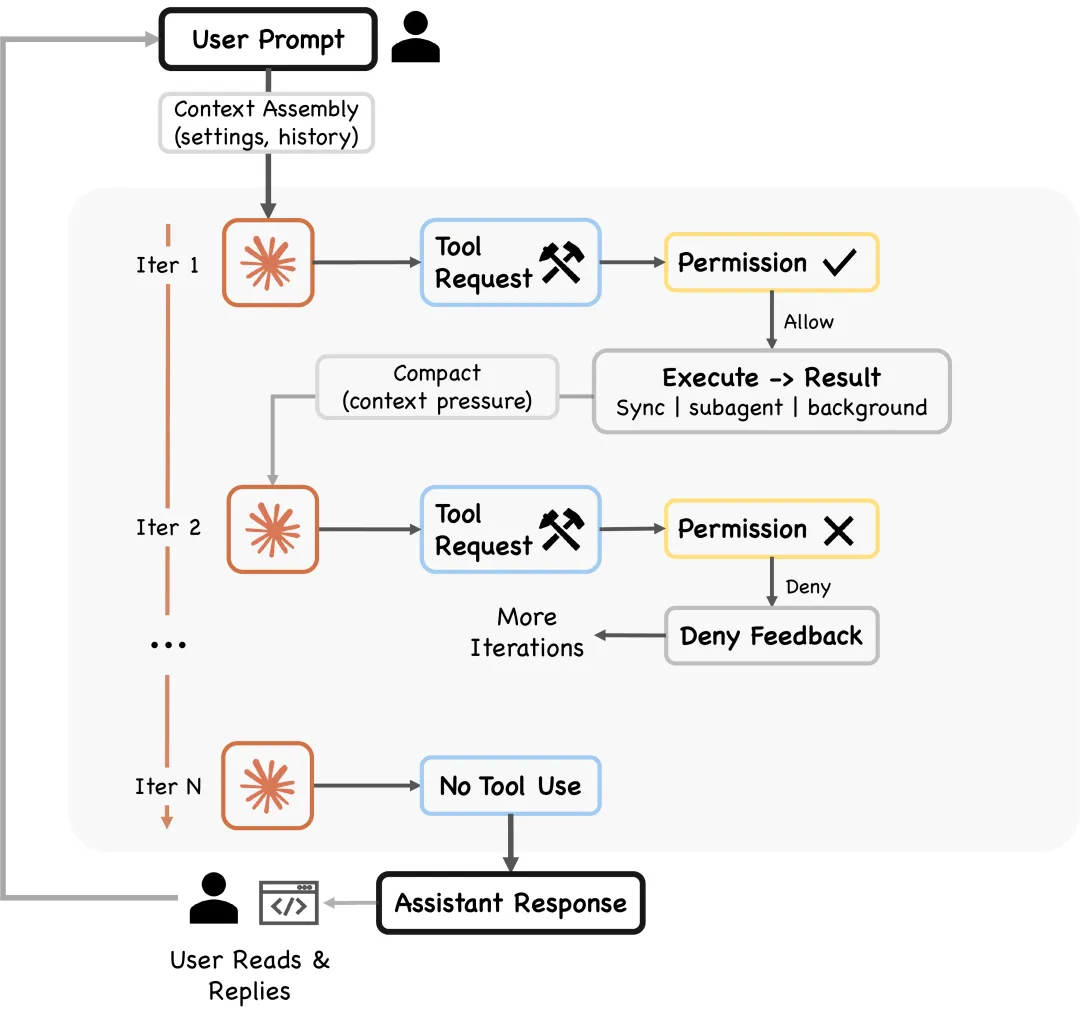
核心架构:一个 while 循环
Claude Code 的核心,说出来可能让人意外,就是一个 while 循环:调用模型 → 执行模型请求的工具 → 把结果喝回去 → 重复,直到任务完成。
没有复杂的 planner,没有状态机,没有多步编排图。模型读上下文,决定下一步干什么,调工具,观察结果,继续走。
整个过程是完全由模型驱动的,它自己决定什么时候停下来,什么时候再跑一轮。
研究者把这叫“Kernel + Harness”架构:一个极薄的 AI 内核,包在一个很厚的确定性外壳里,所有工程复杂度都在循环外面,不在里面。
换句话说,Claude Code 不是靠精巧的编排逻辑让 AI “更聪明”,而是靠工程系统让 AI “不出事”。模型负责思考,Harness 负责兜底。这个分工清晰得让人意外。
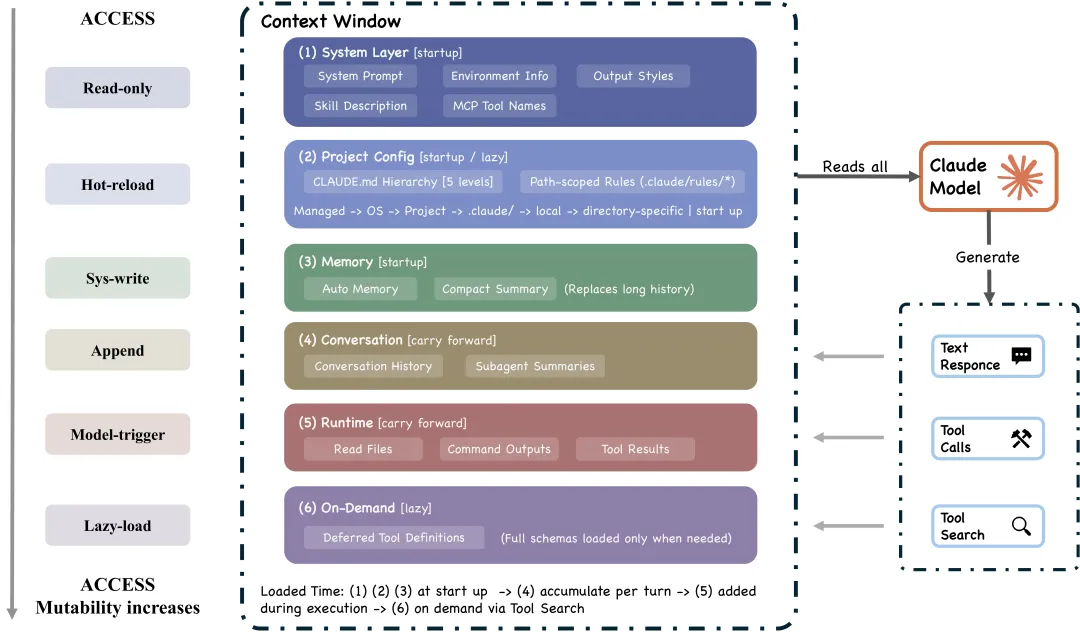
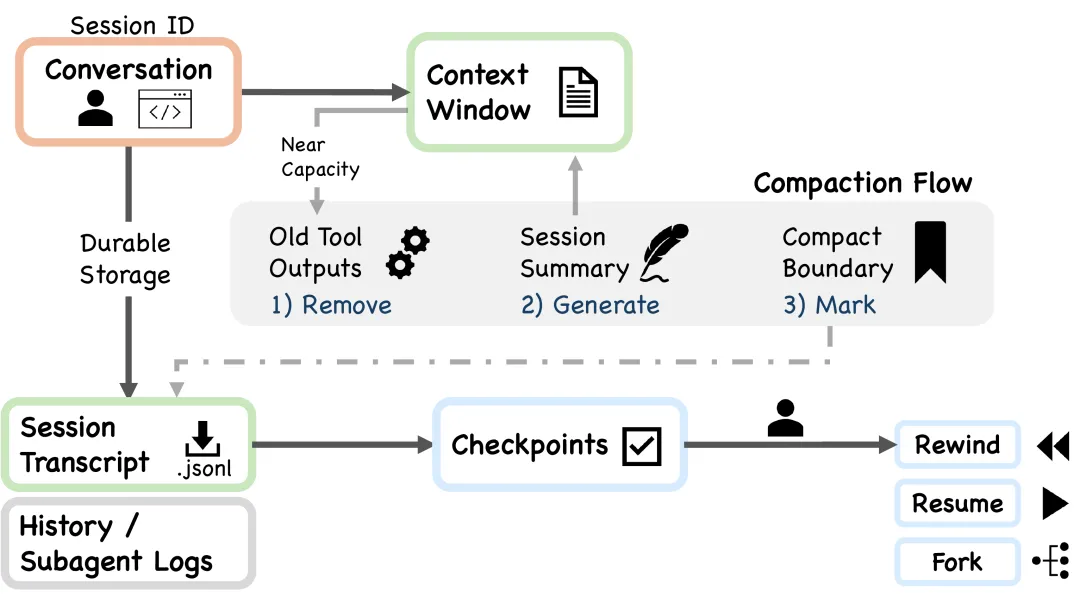
5 层上下文压缩
200K 的上下文窗口听着很大,实际跑一个复杂的多文件调试 session,填满的速度比想象的快。
Claude Code 设计了 5 层压缩机制,从便宜到贵依次触发:
Budget reduction — 削减工具输出的预览长度 Snip — 删掉会话前面已经没用的工具结果 Microcompact — 压缩特定段落 Context collapse — 把大段对话总结成摘要 Auto-compact — 全 session 总结,最后手段
系统在上下文用到 92% 的时候自动触发,从第 1 层开始往下试,能在便宜的层解决就不动贵的。
这个设计的好处是:大部分时候前两层就能腾出足够空间,不需要动到代价最大的全 session 总结。
CLAUDE.md 永远不会被压缩。它不是存在内存里的,每次都从磁盘重新读取,你写在 CLAUDE.md 里的项目约定、架构决策、编码规范,不管 session 怎么压缩,都不会丢。
这也是为什么社区里反复强调“把最重要的规则写在 CLAUDE.md 里”,不是因为它位置显眼,而是因为它在架构层面享有“永不删除”的特权。
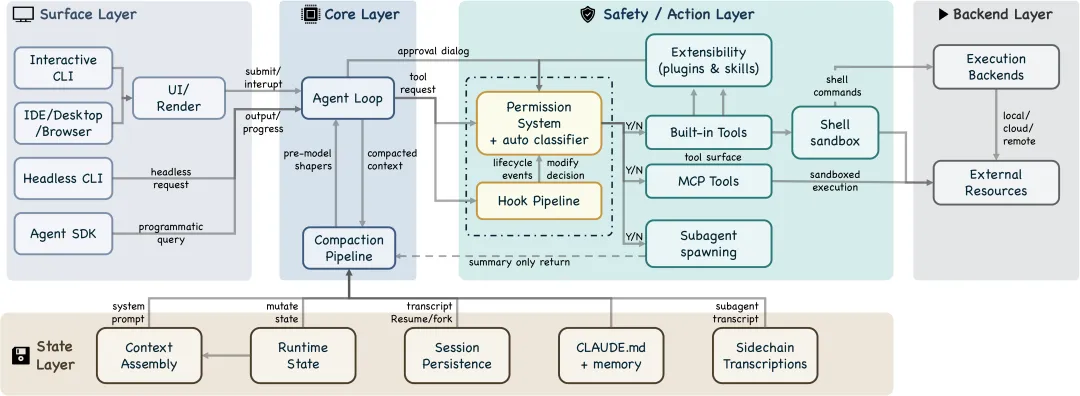
权限系统:7 种模式,8 级优先级
三层结构:第 1 层(工具注册过滤)被禁的工具直接从模型视野里移除,模型连看都看不到;第 2 层(单次调用检查)每次工具调用都根据工具名、参数、工作目录做规则验证;第 3 层(交互式询问)没有匹配规则时实时问用户,用户的回答变成当前 session 的规则。
7 种运行模式,从 default(只对高风险操作询问)到 auto(ML 分类器自动判断)到 bypassPermissions(完全信任,用于沙箱环境)。
8 级规则优先级:Policy → User → Project → Local → CLI flag → cliArg → command → session。设计哲学是:安全不应该是粗暴的全部拦截,而是精确地只拦那些真正需要人判断的操作。
4 种扩展机制
Hooks(零成本)— 事件触发的确定性脚本,模型完全不参与。
Skills(低成本)— 可复用的动作模板,模型按需调用。
Plugins(中成本)— 打包的工具集,有独立上下文。
MCP(高成本)— 完整的外部服务集成。
不是所有事情都该用 MCP,确定性操作用 Hook,知识复用用 Skill,别什么都往 MCP 上堆。一个 MCP 服务的工具描述可能就占几千 token,接五六个 MCP 光工具列表就吃掉了你十分之一的上下文窗口。
正确的思路是:能用 Hook 解决的不用 Skill,能用 Skill 解决的不上 MCP,越轻量越好。
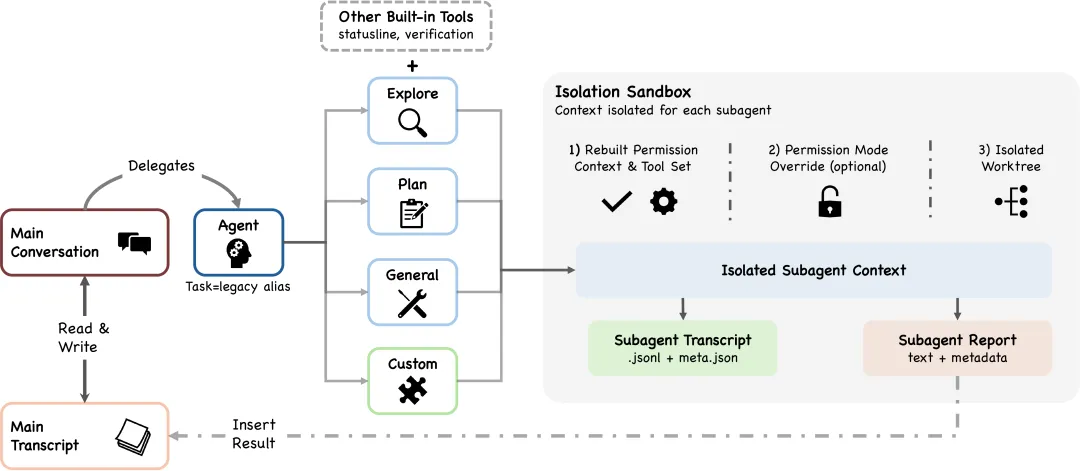
Subagent:独立 worktree,只返回摘要
Claude Code 拆分任务时会起 subagent。每个 subagent 跑在独立的 git worktree 里——文件系统隔离,上下文隔离,不会互相污染。
关键设计:subagent 内部可能消耗了 100K+ token,但返回给父 agent 的只是 1,000-2,000 token 的摘要。这就是为什么用 subagent 比在主对话里塞所有任务效率高,父 agent 的上下文不会被撑爆。
举个具体例子:你让 Claude Code 重构一个模块,它可能会起一个 subagent 去跑测试、另一个去检查类型。每个 subagent 各自消耗几万 token,但父 agent 只收到两句话:“测试全过了”、“类型检查没问题”。主会话的上下文干干净净。
Session 存储:只追加,不覆盖
Session 以 JSONL 文件形式存在 .claude/projects/ 里。存储模型是 append-only,永远不会原地覆盖。会话完全可审计,claude --continue 能精确恢复到上次的状态。
从零开始一个新 session 会有“冷启动惩罚”。一个已经跑了一段时间、理解了你代码库的 session,和一个刚启动的,效果是不一样的。前者已经知道你的文件结构、命名习惯、哪些测试容易挂,后者什么都不知道。
所以 claude --continue 不只是“接着聊”的意思,而是接着用一个已经有积累的 agent。这个设计让长期项目的体验越来越好,而不是每次都从零开始。
写在最后
回头看这篇论文拆出来的东西,Claude Code 的设计思路可以用一句话概括:把 AI 当成一个能力很强但需要严格管理的员工。
模型本身只负责“想”,决定下一步干什么,剩下的 51 万行代码,全在解决“怎么让它安全地干、高效地干、干完还能接着干”这个问题。
5 层压缩保证上下文不会爆;权限系统保证它不会乱来;Subagent 保证复杂任务不会拖垮主线程;append-only 的 session 存储保证所有积累不会丢。而 CLAUDE.md 作为唯一“永不删除”的上下文,相当于给这个员工写了一份永远贴在工位上的操作手册。
这套架构对做 AI 产品的人来说,最大的启发可能是别把精力全花在模型选择和 prompt 优化上,真正决定产品好不好用的,是模型周围那 98.4% 的工程。
延伸阅读:
• 论文来源推文(含完整拆解):https://x.com/sinclairdta/status/2046388705296871886
• Claude Code 官方文档:https://docs.anthropic.com/en/docs/claude-code
• claude-code-best-practice 仓库:https://github.com/SHANRAISSHAN/claude-code-best-practice
欢迎关注,这个账号还会持续分享更多AI编程、出海工具、实战经验、踩坑记录。

我给 Codex / Claude 做了一个有网页审美能力的 Skill
GPT-Image-2 发布!三榜登顶甩开 Nano Banana,设计师要哭了
飞书开源CLI,我用Claude Code一句话读了12篇文档、建了66条选题表!
Google Stitch 2.0 太牛了!UI 丑的问题有救了
(2026年最新)Codex CLI 国内使用全攻略:终端 + VSCode + Cursor + Opencode 四种姿势全搞定
