 夜雨聆风
夜雨聆风⚡ AI Infra 消息速报
2026-05-08 · 每日一报,聚焦前沿
[1] Prompt Caching 是构建 Claude Code 的一切:7 条架构级经验 #智能体工程
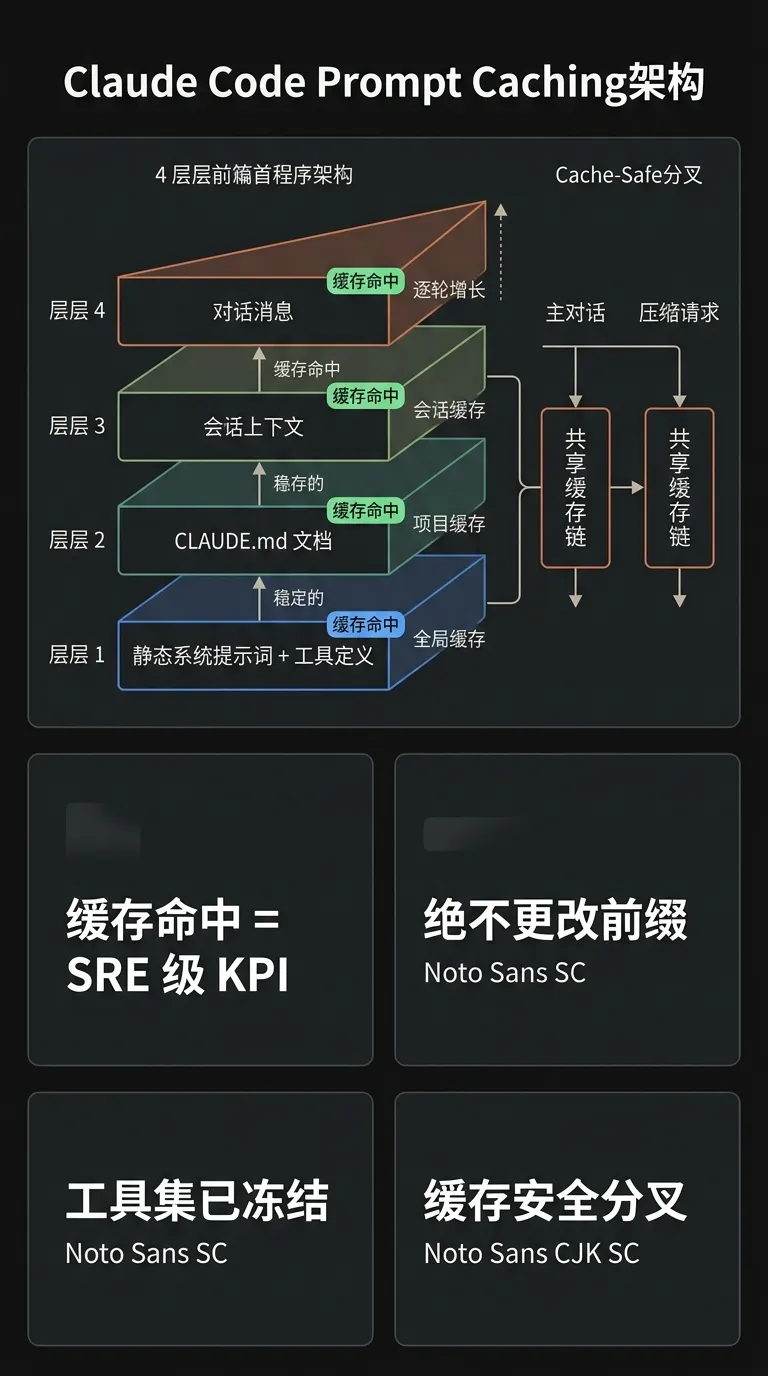
Anthropic 工程师发布技术博客,揭示 Claude Code 的底层设计哲学:Prompt Cache 命中率是基础设施级监控指标,地位等同于服务器 uptime,命中率下降直接触发 oncall 告警。
怎么用:
• Prompt 排列铁律:静态系统 prompt + 工具定义 → CLAUDE.md 文档 → Session 上下文 → 对话消息,越不变的越往前放,时间戳、动态内容塞进 user message,不动 system prompt
• 别换模型:缓存与模型绑定,换模型 = 全部重建;子 Agent 独立上下文干活,结果传回主对话
• 工具集全程不动:session 期间加减任何工具都会断缓存;Plan Mode 用 `EnterPlanMode` / `ExitPlanMode` 两个工具切换,而非增删工具集
• MCP 延迟加载:大量工具只放轻量 stub(`defer_loading: true`),需要时再拉完整 schema,前缀永远稳定
• Cache-Safe Forking:context 压缩请求必须带完全一样的 system prompt + 工具定义,与主对话共享缓存链,压缩成本趋近于零
提效价值:对正在构建 Agent 产品的团队,这不是"做完顺便加缓存",而是从第一天起围绕缓存约束做架构设计。Compaction 功能已内置 API,可直接调用
🔗 https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything
[2] DFlash on TPU:Diffusion-style 投机解码实现 3× 推理提速 #训练推理算法
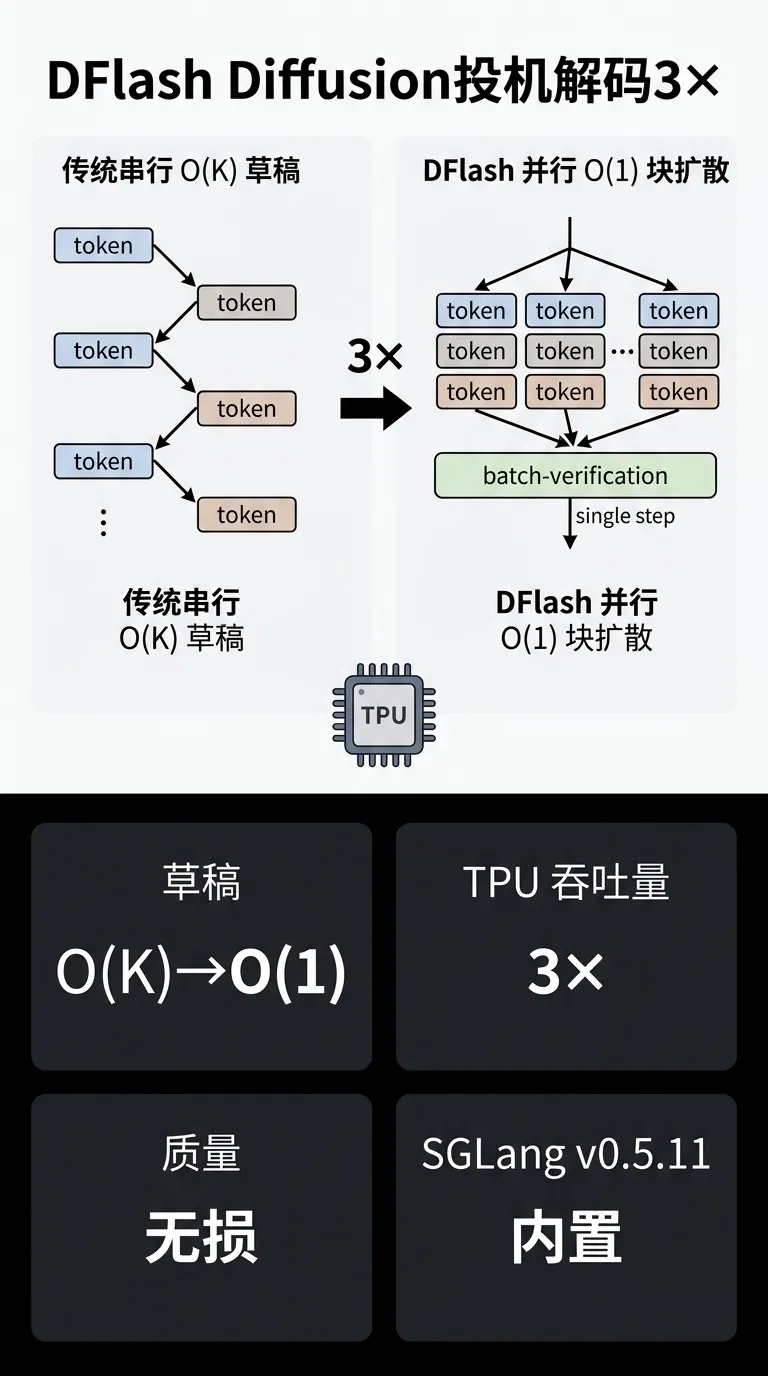
算法改进:DFlash 将经典顺序 O(K) 草稿生成替换为并行 O(1) block-diffusion 方案,集成进 vLLM TPU 路径。多 token 并行草稿 + batch 级验证,彻底消除 auto-regressive draft 的串行瓶颈
质量/效率收益:TPU 端到端吞吐提升 3×,输出质量无损
pipeline/serving 适配:DFlash 已作为 SGLang v0.5.11 的 spec-decode kernel 集成;国产芯片需适配 block-diffusion 并行草稿调度逻辑,与传统 EAGLE/Medusa 路径有架构差异
🔗 https://developers.googleblog.com/supercharging-llm-inference-on-google-tpus-achieving-3x-speedups-with-diffusion-style-speculative-decoding/
[3] 本周 AI Infra 相关项目 Top 3 #框架

| 项目 | 一句话介绍 | ⭐ Stars/周 |
|------|-----------|------------|
| TradingAgents
TauricResearch | 多 Agent LLM 金融交易框架,分工研究员/分析师/风控角色 | 约 +8,000 |
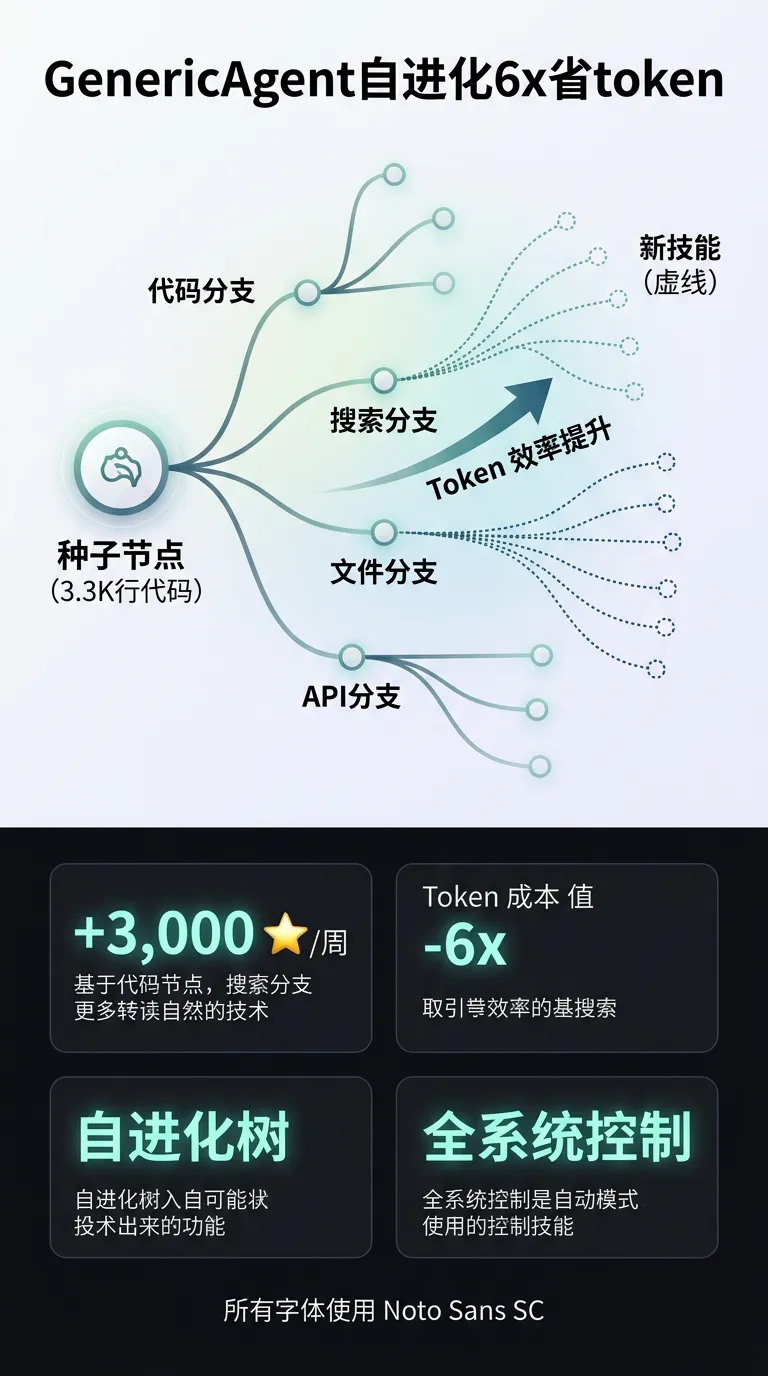
| GenericAgent
lsdefine · arXiv 2026-04-21 | 自进化 Agent,3.3K 行种子树成长,token 消耗降 6× | 约 +3,000 |
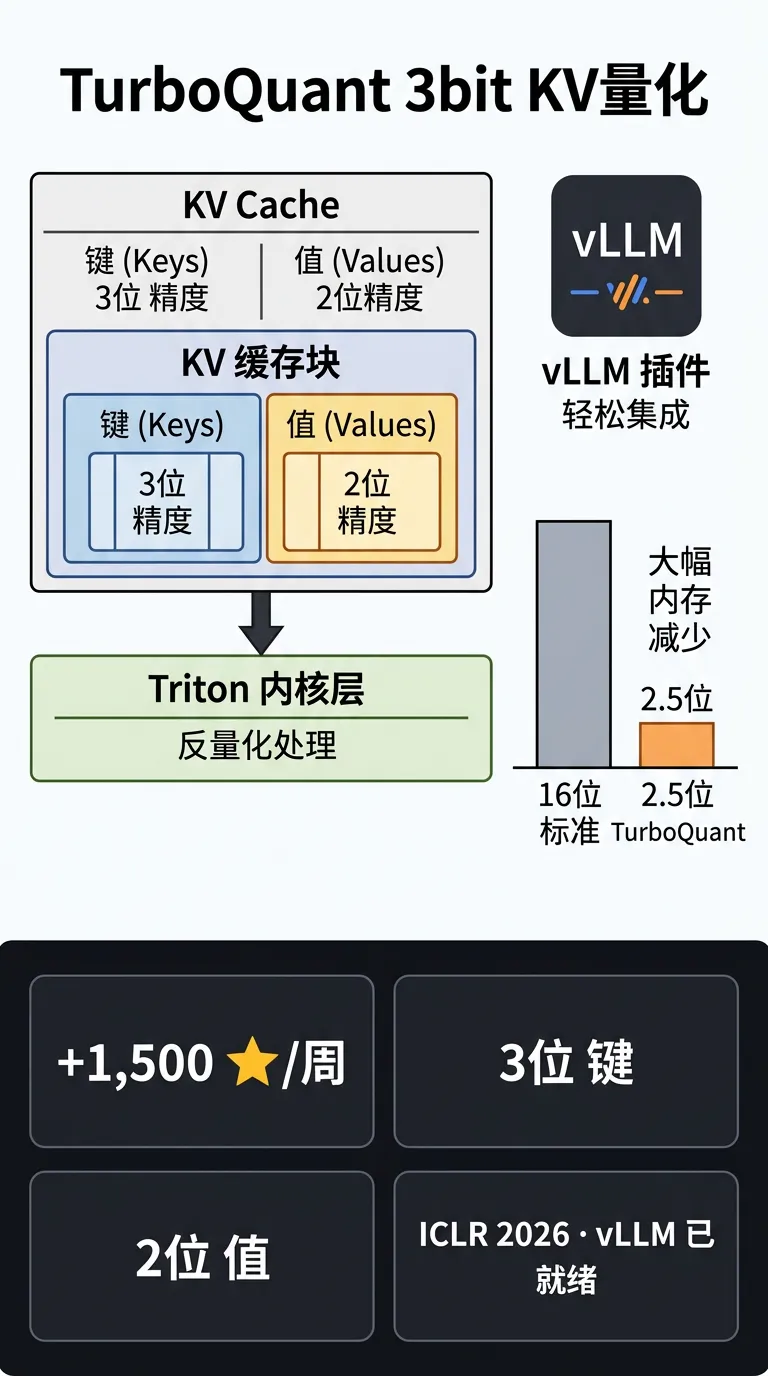
| TurboQuant
0xSero · ICLR 2026 | 3-bit keys/2-bit values KV cache + Triton kernels + vLLM 集成 | 约 +1,500 |
这些工具在实际工作中怎么用:
• TradingAgents:多角色分工范式(研究员→分析师→风控)可直接迁移到"Infra 调研→方案设计→Code Review"三段式 Agent 流水线
• GenericAgent:自进化 skill tree 机制适合企业内部知识库驱动的 Agent,6× token 节省在 API 成本敏感场景价值显著
• TurboQuant:ICLR 2026 论文级 KV 量化,含即插即用 vLLM 集成,可直接在推理链路测试内存节省
🔗 https://github.com/trending/python?since=weekly
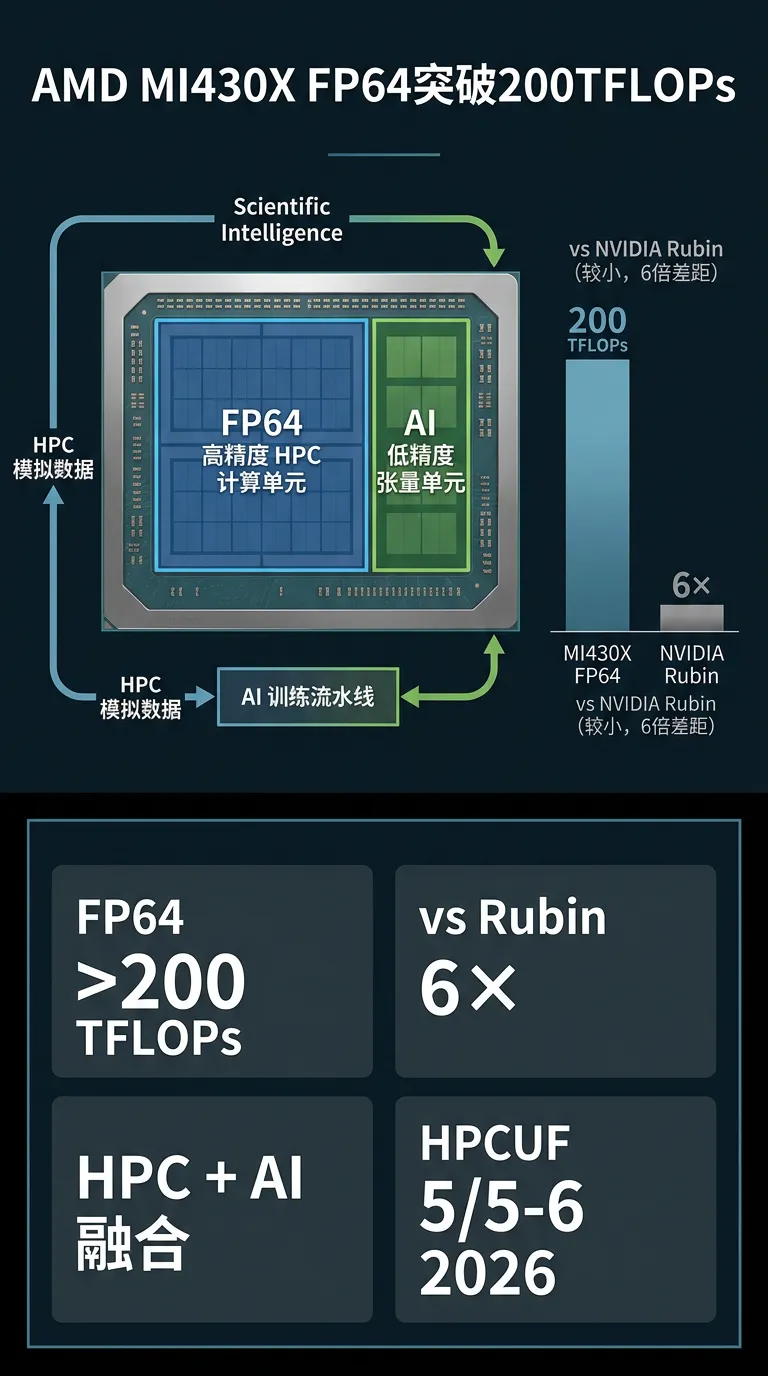
[4] AMD Instinct MI430X:FP64 双精度突破 200 TFLOPs,性能超 Rubin 6 倍 #硬件
新特性/能力:原生双精度浮点(FP64)算力突破 200 TFLOPs,预计超越下一代 NVIDIA Rubin 架构 6 倍以上,定位史上 FP64 性能最强 GPU;同时兼顾低精度 AI 推理/训练算力,单芯片实现"科学 HPC + AI 训练"双负载覆盖;已确认搭载于美国橡树岭国家实验室 Discovery 超算(2028 年)和欧洲 Alice Recoque 百亿亿次超算
对 Infra 的影响:FP64 + AI 算力合体芯片定义了"科学智能"新赛道——高精度仿真数据生成 AI 训练集的闭环路径正在成熟;国产芯片需关注超算+AI 融合场景下 FP64 算力的重要性,纯 BF16/FP8 AI 芯片可能在此场景力不从心
附:厂商背景:AMD 于 HPCUF 2026 大会(5月5-6日,德克萨斯奥斯汀)提前发布,面向 HPC 与 AI 融合场景
🔗 https://mp.weixin.qq.com/s/hoEKR9qJ62-Gz-5htRlHcg
[5] 论文精选:AGoQ 激活+梯度联合量化 #训练推理算法
P01 · arXiv 2605.00539 · AGoQ
激活+梯度双路 FP8/INT8 量化,分布式训练显存显著下降,无精度损失,与 offloading 互补;框架层需在 backward pass 插入量化/反量化算子,国产芯片需支持 FP8 gradient buffer
🔗 https://arxiv.org/abs/2605.00539
[6] RadixArk $1亿种子轮 + SGLang 商业化:推理框架赛道进入竞争 #智能体工程
SGLang 母公司 RadixArk 完成 $1亿种子轮融资(5月5日),将 SGLang 推向商业化托管服务路线。这标志着"开源推理框架→商业级 SLA 服务"路线在大模型推理侧正式成熟,与 OpenAI、Anthropic 的托管 API 形成直接竞争。
怎么用:关注 SGLang 商业版与开源版的 feature 分化节奏;企业级 SLA 支持落地后可评估替换自建推理集群方案
提效价值:国产芯片厂商需跟上 RadixArk 商业优先级变化,确保 Day-0 适配不落后;开源社区 PR 合入可能放缓,需提前 fork 维护关键 patch
🔗 https://techcrunch.com/2026/05/05/radixark-100-million-seed-round/
