 夜雨聆风
夜雨聆风让 AI 改个小 bug,又快又准;让它连续重构代码、跑测试、修失败、更新文档——它就开始绕圈、忘步骤、生成一堆废话。ICML 2026 最新论文找到了原因:LLM Agent 的真正瓶颈在于任务链条的长度。哪怕推理规则完全相同,只要动作序列变长,训练就会剧烈不稳定,甚至直接崩塌。
AI 到底卡在哪?一篇 ICML 论文把问题拆开了
你一定有过这样的体验:让 AI 做一件简单的事,它表现得像个天才。但一旦任务变复杂、步骤变多,它就像换了个人——前后矛盾、重复操作、越走越偏。
过去的解释通常是"模型还不够聪明"、"上下文窗口不够长"、"RL 算法还不够强"。
但 2026 年 5 月 4 日,arXiv 上线了一篇来自延世大学和微软研究院的论文,直接把这些说法翻了个底朝天。
论文标题:《On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length》,已被ICML 2026接收。
▲ arXiv 论文摘要页,显示已被 ICML 2026 接收
作者团队包括 Sunghwan Kim、Junhee Cho、Taeyoon Kwon、Furu Wei 等人,横跨延世大学与微软研究院。他们问了一个非常尖锐的问题:
当 AI Agent 在长任务上失败时,到底是它"解不了",还是任务链条太长导致训练过程本身先崩了?
实验设计:把"任务太长"变成唯一变量
为了回答这个问题,作者做了一件极其聪明的事:构造了一组 controlled tasks,让 Agent 面对完全相同的推理规则和决策结构,唯一的区别只有完成任务所需的动作步数。
论文原文写得很明确:
"we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion."
「我们构造了一组受控任务,Agent 面对的决策规则和推理结构完全相同,唯一的区别在于成功完成任务所需的动作序列长度。」
主实验环境选的是数独(Sudoku)。Agent 需要对 9x9 网格执行填格动作,空格数量决定了任务的 goal distance——空格越多,需要的步骤越长。为了排除"空格多=题目难"的干扰,作者用 HoDoKu 校验器过滤,只保留基础技巧就能解的题目。
论文把数独按空格数分成 7 个等级(L1 到 L7),其中 L1-L4 用于训练,L5-L7 是训练时从未见过的超长任务。基座模型用的是 Qwen3-1.7B。
这个设计的精妙之处在于:它把"任务太长"从一个模糊的吐槽,变成了一个可以精确测量的独立变量。
核心发现:短任务稳定提升,长任务直接崩塌
结果相当残酷。
论文摘要中最关键的一段:
"Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges."
「仅仅增加 horizon length 就能形成训练瓶颈,引发由探索困难和信用分配挑战驱动的严重训练不稳定。」
具体来说:
- L1-L2(短目标距离)
:RL 训练持续改善,曲线平稳上升。 - L3-L4(长目标距离)
:训练出现严重不稳定,甚至发生catastrophic collapse(灾难性崩塌)。
崩塌还伴随一个标志性现象:模型生成的回复越来越长、越来越失控——maximum-length response ratio 急速上升。模型不知道该在哪里停下来,开始疯狂输出。
这个结果推翻了一个常见假设:只要模型够强、数据够多、算法够好,长任务自然能搞定。事实恰好相反——单纯把任务拉长,就足以让训练崩掉,哪怕背后的推理规则一点没变。
崩塌背后的两个杀手
论文拆出了两个导致长程训练崩塌的核心机制:
第一,探索困难指数级增加。长任务需要连续做对更多步。随着 horizon 增加,随机或次优策略采样到一条完整成功轨迹的概率急剧下降。早期一个小错误就会锁死后续所有状态,成功路径变得极度稀疏。
第二,信用分配变成噪声炸弹。在稀疏奖励设置里,如果第 50 步失败了,整条 50 步轨迹都会收到负反馈。这样一来,很多本来正确的中间动作也会被错误惩罚,梯度信号充满噪声,模型越训越差。
用大白话说:步骤一多,模型既找不到正确路径,也分不清哪一步做对了哪一步做错了。两个问题叠加,训练直接失控。
"加大模型"和"换更好的算法"能救吗?
你可能会想:用更大的模型是不是就行了?
论文做了鲁棒性实验,把基座模型从 1.7B 换成 4B。结果:在原子动作(atomic action)设置下,4B 模型照样崩。
那换更强的 RL 优化器呢?论文还测了 GRPO-style optimizer。默认长 horizon 下,性能先升后降;只有在 horizon-reduced 设置下才能稳定改善。
作者的判断很明确:这个瓶颈跨环境、跨模型、跨优化器,是长程 LLM Agent 训练的结构性问题。
论文还在 Rush Hour 空间推理任务和 WebShop 电商环境上做了验证,趋势一致。
解法:把长路拆短,让模型走"大步"
论文提出的核心解决思路叫horizon reduction——降低有效地平线。
两种具体手段:
Macro Actions(宏动作):把多个原子动作打包成一个高层动作。比如在数独中,让模型一次生成多个填格动作;在 Rush Hour 中用 `move(id, direction, N)` 一次移动多格,替代一步一步挪。
Subgoal Decomposition(子目标分解):把一个大目标拆成多个可验证的小目标,每完成一个就给中间奖励。比如数独中,先完成一个 3x3 子格。
效果立竿见影:horizon reduction 让原本崩塌的训练重新稳定,模型在短中等 horizon 上训练后,还能泛化到训练时从未见过的更长任务。论文把这种现象命名为horizon generalization。
"models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time"
「在缩减的 horizon 下训练的模型,推理时能更有效地泛化到更长 horizon 的任务变体。」
论文的结论很干脆:
"managing the effective horizon is a fundamental prerequisite for scalable learning."
「管理有效地平线,是可扩展学习的基础前提。」
X 上的反应:有人恍然大悟,有人泼冷水
5 月 6 日,X 用户 Atal(@ZabihullahAtal)发了一条长推文解读这篇论文,迅速引发讨论。


▲ Atal 在 X 上发布论文解读,获得 2.2K 赞
Atal 把论文概括为:
"AI doesn't fail because it lacks intelligence but because tasks get too long."
「AI 失败的原因不在于缺少智能,在于任务太长了。」
"The key limitation is not knowledge. It's maintaining consistency across steps."
「关键限制不在知识层面,在于跨步骤保持一致性。」
评论区里出现了几种典型声音:
@Vanarchain认为这本质上是个系统工程问题,涉及 credit assignment、memory 和长工作流下的稳定性。
@John_W_Maki指出 long-horizon failure 可能更多来自 missing structure——缺少层级、不变量、和平衡 exploration/exploitation 的策略设计。
@MarcelVelica把它和 agentic systems 中已知的性能退化联系起来:compounding error 和 weak credit assignment 跨步骤累积。
不过也有反对意见。@CustomAIMath直接泼冷水,认为 length 根本不是关键,问题更可能出在用户指令不清楚,导致 AI 不得不做假设。
这场争论本身就很有意思:到底是 AI 的训练结构有硬伤,还是人类给的指令太烂?
对 Agent 开发者来说,这意味着什么?
WisPaper 在博客解读中给出了一组非常实操的建议,标题也相当直白——《The Hidden Wall: Why Horizon Length—Not Reasoning—Is Killing Your LLM Agent》。

▲ WisPaper 博客标题:Horizon Length 才是杀死你的 LLM Agent 的隐形墙
核心建议:
"Don't just add more data. Check your average interaction horizon."
「别只顾着加数据,先看看你的平均交互步数。」
落到工程层面:
- 用高层 API 替代低层点击
:让模型执行"创建 PR""运行测试并总结失败原因",替代一步步点界面。低级动作越多,出错机会越多,奖励信号越嘈杂。 - 让模型生成可执行脚本/批处理命令
:把多个原子操作压缩成一个 macro action。 - 在长任务中设置可验证的 milestone
:比如"依赖安装成功""单测通过""页面元素存在"。每个 milestone 都是一个 subgoal,能给中间反馈。 - 用 process reward 给中间步骤打分
:避免只有最终成功/失败的稀疏奖励。 - 训练时用 curriculum
:从短 horizon 到中等 horizon,再迁移到长 horizon,别一上来就让模型啃最长的任务。
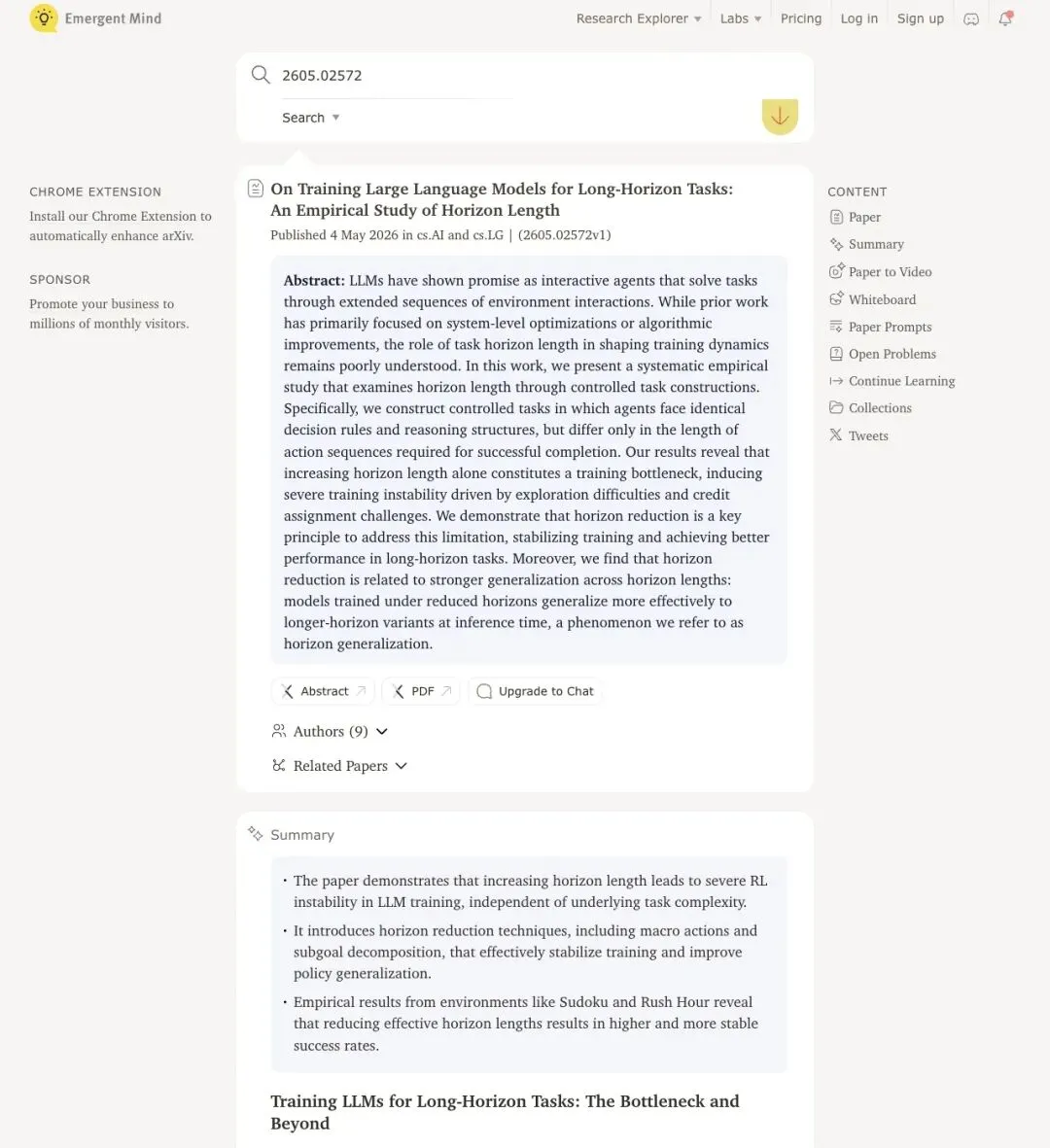
▲ Emergent Mind 论文解读页:降低 effective horizon 可获得更高、更稳定的成功率
别急着喊"AI 已经很聪明了"
这篇论文确实把一个重要事实摆到了台面上:很多 AI Agent 的失败,问题出在训练过程遭遇了长程链条的结构性瓶颈,而不仅仅是"模型太笨"。
但边界也要看清楚。
论文的实验环境是精心控制的文本游戏——数独和 Rush Hour。真实世界的 web browsing、coding、GUI automation 还会遇到网页变化、工具报错、权限问题、噪声反馈等一堆额外因素。
而且论文明确指出:horizon generalization 主要发生在推理结构相似的任务之间。如果任务需要全新的推理技巧,单纯缩短 horizon 未必管用。

▲ alphaXiv 社区论文入口,支持 highlight 和讨论
所以更准确的理解是:这篇论文给出了一个强机制解释和一套可迁移的设计原则,但它还没有在所有 Agent 场景中被验证。
不过对于正在做 Agent 产品的团队来说,启发已经足够明确——
在追求让 AI 更聪明之前,先想想怎么把它要走的路拆短。
— END —
