 夜雨聆风
夜雨聆风物理AI具身智能VLA模型深度解读2026年观察

如果说GPT给了AI一个"灵魂"——能说话、会推理、懂逻辑——那么物理AI正在做的事情,是为这个灵魂重塑一副肉身。
不是比喻。是字面意思。


2025年智元+宇树两家中国企业占据全球人形机器人市场份额
我最近有个习惯——每次打开新闻,先数数今天有几个新机器人视频刷屏了。
上个月还在数个位数,现在已经要用十位数了。不是视频变多了,是机器人真的变多了。
今年春晚,超过200台人形机器人同台亮相。抖音相关话题曝光破亿。老一辈那天在客厅看完,第一句话是:"这机器人……像真人的。"
不是"很厉害啊",是"像真人的"。这个细节让我想了很久。
🧠
从"大脑"到"小脑":补齐那条最难的腿
技术核心
过去几年我们讨论的AI,说白了是一种"云端的大脑"——它有逻辑、有知识、能推理,但它对物理世界一无所知。你问它"拿起这个玻璃杯需要多大力气",它能给你讲牛顿第三定律,但它不知道玻璃的触感,不知道杯子装水和没装水的重量差异,更不知道手指应该施加多少克力才不会摔碎。
这就是具身智能要解决的核心问题:让AI理解物理世界,并在其中真实行动。
关键词解释:VLA模型
Vision-Language-Action,视觉-语言-动作三合一模型。它不是三个系统拼在一起,而是真正统一的神经网络——看到什么、听到什么指令、做出什么动作,一气呵成。由谷歌DeepMind的RT-2(Robotic Transformer 2)率先奠定框架,此后迅速成为具身智能领域的主流技术路线。
以前的机器人是怎么工作的?程序员写死代码:向前移动10厘米,然后抓取,然后旋转45度。整个动作序列硬编码。一旦环境稍有变化——桌子高了2厘米,或者零件颜色换了——机器人就会懵。
VLA模型的逻辑不一样。你对它说"把桌上的杯子放到水槽里",它通过视觉感知环境,理解语义指令,然后自主规划动作序列并执行。它不需要你告诉它"先走几步、转几度、开合手指多少毫米"。
好吧,我承认这听起来还是很抽象。
更直白的比喻是:以前教机器人搬东西,是给它背诵"搬东西的步骤说明书";VLA是让它直接看几千段人类搬东西的视频,然后……它就会了。
空间智能(Spatial Intelligence)是什么?

AI开始理解"重量感""易碎性""摩擦力"这类隐性物理属性。识别"这是玻璃杯"是视觉任务,但知道"抓它需要多大力、落地会碎"才是空间智能。这是机器人从"认识物体"到"真正使用物体"的分水岭。
这里有一条技术线,业界叫做"端到端学习"。之前说了,不展开了。
我想强调的是另一个细节:这条技术路线,中国企业已经在独立推进。千寻智能自研的Spirit VLA模型,2026年1月开源的Spirit v1.5版本,在RoboChallenge评测中以50.33%成功率超越了美国Physical Intelligence(π0.5)。星动纪元自研了端到端VLA具身大脑ERA-42,硬件自研比例超95%。
不是追随者的姿态了,这话说得可能有点大,但数据摆在那里。
🏭

场景革命:从工厂车间到家庭厨房
应用落地
2026年,机器人产业有一个关键词的切换,从"技术验证"变成了"量产交付"。
这不是口号。是有人真的在数出货台数了。
🔧
工业制造:柔性生产
宁德时代、博世、丰田工厂里,银河通用Galbot S1已经"正式入职",双臂最大负载50公斤,在粉尘、震动、极端温差环境下稳定运行。
🌏
出海:东南亚制造带
越南已成中国工业机器人出口第一大目的国(2025年1-11月)。智元机器人2026年初宣布泰国战略,与当地企业合建智能工厂。
🛢️
高危作业:中东能源
宇树科技B2工业四足机器人进入ADNOC(阿布扎比国家石油公司)供应链,承担高温沙漠油管巡检,人类不愿意去的地方,机器人去。
🏥
医疗机器人:外科精度
LEM Surgical的Dynamis双臂手术机器人已获FDA批准并进入常规脊柱手术临床,使用NVIDIA Isaac系统训练,在数字孪生里练了无数遍再上真人。
这里我想多说一件事:不规则物体处理,这曾经是自动化生产线的死穴。
传统工业机械臂最怕什么?怕"无法预知的形状"。蔬菜、衣服、不规整的零部件——这些东西让全刚性的编程逻辑彻底崩溃。而VLA模型让机器人可以在看到实物的那一刻动态规划抓取方案。分拣蔬菜、折叠衣服,这两件听上去超简单的事情,花了人类工程师将近二十年才大致搞定。
顺带一提,宇树科技的G1消费级人形机器人,身高1.2米,自重35公斤,已经上了亚马逊和速卖通。出海业务占宇树整体业绩约50%。我不知道这意味着什么,但感觉是一个值得记住的数字。
中国的底气来自哪里?
深圳"机器人谷",10公里内能配齐近半数核心零部件,80%零部件40公里内找到供应商。国内机器人核心零部件国产化率已超70%。江苏产业链覆盖率达93.8%。不是靠补贴撑出来的规模,是真实的供应链密度。
🌐
数字孪生与"数据炼金":先在虚拟世界练完,再来现实世界上岗
技术底层
机器人学习有一个根本性的难题:弄坏了怎么办?
训练一个机器人在真实世界里学习,意味着它要撞到东西、摔东西、伤到人。每台机器人原型可能值数十万美元。出了错,损失是真实的。这也是为什么几十年来机器人进化速度那么慢——物理世界的试错代价太高了。
1
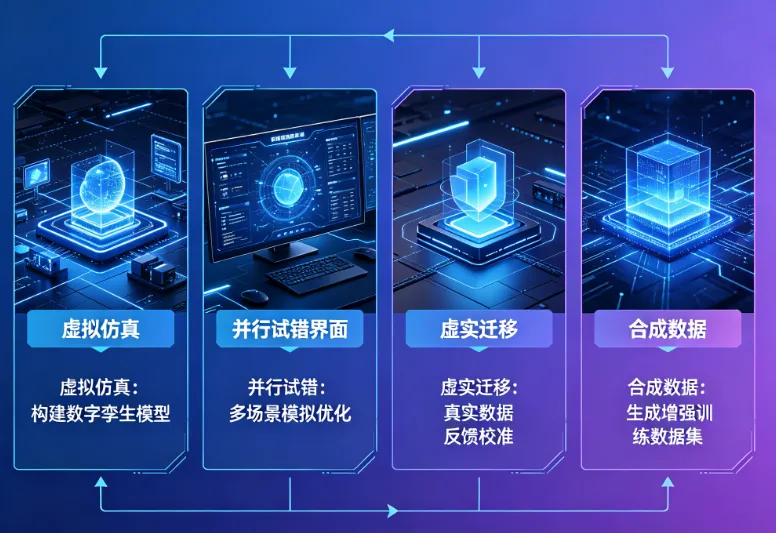
建立数字孪生:用NVIDIA Omniverse等仿真平台,构建和现实物理规律一模一样的虚拟环境。重力、摩擦力、材料形变,全部精准模拟。
2
并行强化学习:在虚拟世界里同时跑几千个机器人实例,24小时不停地试错。换算成人类时间,相当于"练了一万年"。机器人撞坏了?重启,继续练。
3
Sim-to-Real迁移:把虚拟世界练出来的策略,"下载"到物理机器人里。这一步很难——虚拟和现实之间永远有差距——但NVIDIA Isaac GR00T的光照真实感渲染和Cosmos Transfer合成数据,正在大幅压缩这条鸿沟。
4
合成数据补充:现实中收集的数据永远不够用。当真实数据耗尽,AI开始"自己生成训练数据"——用扩散模型生成高质量物理仿真视频,给自己打标签,训练自己。这是一个有点令人头皮发麻的循环。
CES 2026的现场
英伟达CEO黄仁勋在今年CES演讲中说,AI的演进将从感知、生成、代理,最终发展到能理解物理世界的"物理AI",并断言物理AI的"ChatGPT时刻"即将到来。他不是在画饼,英伟达2026年CES上直接把整个物理AI技术栈拿到展厅,从重型装备、工厂助手到手术机器人,全线亮相。
我也不确定这个"ChatGPT时刻"具体是哪一天。但有一个参照系可以用:ChatGPT从发布到破亿用户用了两个月,而人形机器人从2024年全球出货2000台到2025年1.8万台,用了一年,同比增幅508%。
增速的形状是一样的。
⚠️
它拥有了身体——然后呢?
安全与伦理
好吧,必须说一个让人不那么舒服的话题。
语言模型出错,最坏的结果是说了一句错误的话。物理AI出错,可能是机械臂打到了旁边的工人,或者手术机器人偏了两毫米。
这是2026年法律和监管领域最热的议题之一:当AI拥有物理实体,谁来负责?
目前已知的安全机制
① 力控关节:关节力矩实时监测,感知到异常阻力立即停止;② 数字孪生预演:部署前在仿真环境里模拟所有边缘场景;③ 分级权限:危险操作需要人类确认;④ 物理隔离冗余:关键医疗机器人双系统互备。但这些仍然是工程手段,不是终极答案。
宇树科技创始人王兴兴说过一句话,我觉得是目前对这个行业最诚实的判断:"具身智能仍处在起步阶段,如果未来几年出现具备大规模应用能力的具身智能AI大模型和技术突破,那时候热度'会远超移动互联网'。"
注意那个"如果"。
行业内有些偏悲观的声音认为:瑞银证券预计2026年全球人形机器人出货量约3万台,2030年约15万台,2035年才到100万台。这个斜率,讲真,没那么陡峭。而湖北人形机器人董事长说,"真正进入家庭,还需5到8年的技术积累和完善。"
我个人觉得两个判断都不算错,只是在描述不同的事情——工业场景的渗透速度,和消费级场景的渗透速度,不是同一条曲线。
本文涉及技术/平台:VLA模型NVIDIA OmniverseIsaac GR00TCosmos TransferSim-to-Real宇树科技智元机器人千寻智能Physical Intelligence
世界经济论坛今年2月有一句话,我觉得是对这个时代最精准的定格:"21世纪20年代中期,或许会被铭记为这样一个时期——AI不再仅作为一种基于屏幕的生产力工具,而是开始作为物理系统在实体经济中运行。"
从对话框里的文字,到真实世界里的手和脚。这个转变比"更聪明的chatbot"要大得多。
我的判断是:接下来两三年,工厂会先变,然后是医院和仓库,最后才是你家客厅。节奏不会那么快,但方向不会错。
这是题外话:我有时候想,等机器人真的进了家庭,人类每天面对的"他者"就又多了一种。那时候我们管它叫什么——工具?助手?还是某种更尴尬的词?我也不确定。
📌 延伸阅读建议
想深入了解具身智能产业链布局,可关注:NVIDIA GTC 2026大会具身智能专题、宇树科技/智元机器人官方技术博客、arXiv上的VLA模型综述论文(2505.04769)。国内产业动态推荐持续跟踪36氪机器人频道及OFweek机器人网。
本文数据来源:IDC《全球人形机器人市场分析》(2026年1月)、集邦咨询、瑞银证券、M&M Research、国务院发展研究中心报告、NVIDIA官方博客、36氪、OFweek等公开资料。市场预测数据存在不确定性,不构成任何投资建议。文中部分细节为作者基于公开信息的推演,不代表相关企业官方立场。
