写在前面:这篇文章源自我看到黄佳老师一张关于 Token 经济学的课件后的延伸思考。原图提出了三个概念——Token Debt、Token Leverage、Token Refactoring Dividend,本质上是把软件工程的成熟思想搬到了 LLM 时代。我越想越觉得,这不只是一套省钱方法论,而是 AI 应用进入"工程化深水区"的一个重要信号。
一、一个被忽视的转折点
过去两年,做 AI 应用的同行们大多经历过一个共同阶段——只要能跑通就行。模型够强,prompt 写得糙一点没关系;context 不够长,那就把所有能塞的都塞进去;效果不稳定,那就再加几个 few-shot 例子兜底。这个阶段,我们用的是"算力换时间"的打法,反正 token 便宜,反正模型在变强,反正用户少。但今年开始,越来越多团队开始算一笔账:当 DAU 从 1 万涨到 100 万,每次调用多花的那 2000 个 token,会变成什么?答案是:一笔每月几十万、上百万的真金白银,以及一个永远卡顿的产品体验。这就是 Token 经济学浮出水面的背景。它不是某个技术新概念,而是 AI 应用从 demo 走向规模化时,必然撞上的一堵墙。更有意思的是,当我们认真审视这堵墙,会发现它的结构和软件工程师们撞过几十年的那堵墙——技术债务——长得几乎一模一样。二、三个概念,一套老配方
Token Debt(Token 债务):因架构设计不当而产生的持续性 token 浪费。比如每次调用都发送完整上下文不做裁剪,债务随调用量线性增长。Token Leverage(Token 杠杆):用少量 token 撬动大量高质量输出的能力。比如精心设计的 system prompt,用 200 tokens 指令省掉 2000 tokens 的纠错。Token Refactoring Dividend(Token 重构红利):重构 prompt 或架构后获得的长期 token 节省。比如把万能 prompt 拆成 3 个专用 prompt,总消耗降 60%。懂软件工程的朋友看到这里应该会心一笑——这不就是技术债、抽象能力、重构红利的 LLM 版本吗?但我想说的是:正是这种"直接平移能成立",才是最值得我们重视的事情。三、为什么老配方依然有效?
LLM 应用看起来是个全新物种——模型替代了一部分逻辑,prompt 替代了一部分代码,context 成了新的状态管理单元。但底层的工程问题,并没有因为换了实现介质就消失。恰恰相反,软件工程几十年沉淀下来的核心原则,在 LLM 时代被重新激活了。SOLID 原则中的单一职责(SRP),对应到 prompt 设计就是:一个 prompt 只做一件事。万能 prompt 之所以浪费 token,本质上就是违背了 SRP——它承担了太多职责,每次调用都要把所有职责的"上下文成本"全部支付一遍。DRY 原则(Don't Repeat Yourself),对应到 context 管理就是:相同的指令、相同的背景、相同的格式约束,不应该在每次调用里重复出现。这就是为什么 prompt caching、system prompt 复用、模板抽象这些技术会迅速成为标配。关注点分离(Separation of Concerns),对应到 LLM 架构就是:检索、推理、生成、校验,应该是分层的。如果你把这些都揉进一个超长 prompt 里让模型一次性搞定,token 消耗一定爆炸。抽象与封装,对应到 agent 设计就是:工具调用、子任务委派、记忆管理,每一层都应该有清晰的接口和最小信息暴露。所以那张课件里的三个 Token 概念,与其说是"新发明",不如说是软件工程经典思想在新介质上的投影。Token Debt 就是技术债,Token Leverage 就是抽象能力,Token Refactoring Dividend 就是重构红利。换汤不换药,但这碗药,正是 AI 应用现在最需要喝的。四、Token Debt:那些正在悄悄发生的浪费
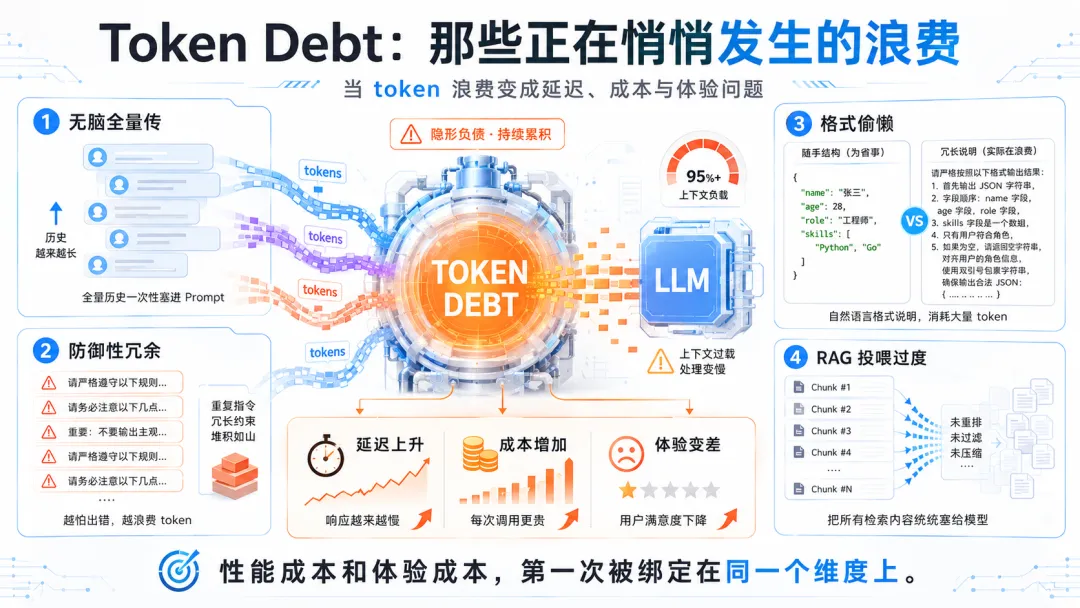
我观察过不少团队的 LLM 应用代码,发现 Token Debt 通常以这几种形态存在:第一种是"无脑全量传"。对话系统里,每一轮都把完整历史塞进去。用户聊到第 20 轮,prompt 里还带着第 1 轮的寒暄。开发者知道这样不对,但"先这样跑着,以后再优化"——这句话就是技术债的标准开场白。第二种是"防御性冗余"。因为模型偶尔会出错,所以 prompt 里堆满了"请务必"、"千万不要"、"如果...就...否则..."的各种防御性指令。每条单独看都有道理,加在一起就是几百上千个冗余 token。第三种是"格式偷懒"。本来用 JSON schema 一个字段就能约束的输出,用了三段自然语言描述。本来一个枚举值就能解决的,列了十个例子。第四种最隐蔽——"RAG 投喂过度"。检索回来 10 个 chunk,不做重排序、不做压缩、不做相关性过滤,全部喂给模型。美其名曰"让模型自己判断",实际上是把判断的成本转嫁给了每一次调用。这些债务的共同特征是:单次看微不足道,规模化后致命。更可怕的是,Token Debt 还有一个软件工程债务没有的特性——它是用户可感知的。技术债主要影响开发效率和系统稳定性,用户感知不强。但 Token Debt 不一样,它直接表现为延迟。Context 越长,首 token 延迟越高,流式输出越慢。用户不知道你在还什么债,他只知道你的产品"卡"。这是 AI 时代的特殊性:性能成本和体验成本,第一次被绑定在了同一个维度上。五、Token Leverage:好工程师和好工程师的差距
我特别喜欢"杠杆"这个词,因为它精确描述了好 prompt 工程师和普通 prompt 工程师之间真正的差距。普通做法是:遇到问题,加指令。模型不听话,加一句"请严格遵守";输出格式错了,加一段格式说明;偶尔幻觉,加一条"不要编造"。Prompt 越长,问题反而越多,因为长 prompt 本身就在稀释模型的注意力。什么是支点?支点是那种"改动一处,收益十处"的设计点。比如:一个清晰的角色设定("你是一个严谨的法律分析助手"),可能比十条具体规则更有效。一个合理的输出 schema,比一段格式描述节省 80% 的纠错成本。一个好的 few-shot 例子,胜过五个平庸例子。一个明确的"不要做什么"清单,比模糊的"请做什么"更省 token。这些支点的共同特征是:它们利用了模型的归纳能力,而不是对抗它。模型本身就有强大的模式识别和泛化能力,好的 prompt 是给它一个清晰的方向,让它自己沿着方向走;坏的 prompt 是不信任模型,每一步都要手把手指挥。这一点和带团队是一样的。好 leader 给方向、设标准、放手让人做;差 leader 事必躬亲、每个细节都要管,最后团队既累又没产出。Token Leverage 的本质,是对模型能力的信任和合理利用。这种信任不是盲目的,而是建立在对模型行为充分理解基础上的——知道它擅长什么、不擅长什么,知道在哪里该放手、在哪里该约束。这恰好对应软件工程里的"抽象能力"——好的抽象不是写更多代码,而是用更少的代码表达更多的意图。六、Token Refactoring Dividend:最被低估的长期价值
如果说 Token Debt 容易被识别、Token Leverage 容易被追求,那么 Token Refactoring Dividend——重构红利——就是最容易被忽视的那一个。重构意味着:动一个已经能跑的系统、承担短期风险、付出短期成本、收益要等很久才能显现。这套描述适用于一切重构,但在 AI 应用里尤其残酷。LLM 应用的"能跑"和"跑得好"之间,差距非常大。一个臃肿的万能 prompt,在测试场景下可能 100% 通过,但在生产环境里每次都在烧钱。一个杂糅的 agent 流程,可能每个 case 都能完成任务,但每个任务都比合理设计多消耗 5 倍 token。这种情况下,重构的 ROI 计算需要做时间维度的折现。重构红利 =(单次节省的 token × 调用频次 × 时间窗口)- 重构投入第一,调用频次是放大器。同样的优化,每天 100 次调用和每天 100 万次调用,价值差 1 万倍。所以重构应该优先针对高频链路。第二,时间窗口决定了视野。短期看,重构是赔钱买卖;放到 6 个月、12 个月维度看,红利会指数级累积。第三,重构投入包含隐性成本。不只是开发时间,还有测试成本、风险成本、上线成本。所以一次到位的重构往往比小步迭代更划算。更重要的是,Token Refactoring Dividend 还有一个软件工程重构红利没有的优势——它的收益是可测量的。技术债重构后的"代码可维护性提升"很难量化,但 token 消耗下降是直接可见的数字。这是一个工程师能用来说服老板的稀有时刻——你可以拿出明确的 ROI 数据,告诉财务这次重构每月能省多少钱。七、把这套思维落地:从识别到行动
讲了这么多原则,落到实操,我觉得有几件事是任何 LLM 应用团队都值得马上做的。不能优化你看不见的东西。给每一次调用打点,记录 input tokens、output tokens、cache hit rate、latency。一周后看分布,你会震惊地发现自己的应用在哪里漏钱。很多团队用 LLM 用了一年,居然不知道自己最高频的那个调用平均吃多少 token。这就像开公司不看财报,肯定是要出事的。Prompt 应该被当作代码来管理——有版本、有 review、有回归测试。每次修改 prompt,都要在标准测试集上跑一遍,确认效果不退化、token 不暴涨。没有评估机制的 prompt 优化都是在赌博。你以为你在节省 token,可能只是在牺牲质量。哪些 prompt 是"万能 prompt"?应该被拆分?哪些场景在重复传递相同的 context?应该用 caching?哪些链路存在明显的 over-engineering?应该简化?这个清单是动态的,但有清单本身就比没清单强 100 倍。最深层的改变不在工具和流程,而在文化。如果团队里讨论一个新功能时,没人问"这会消耗多少 token",那么 Token Debt 就会无声无息地累积。好的工程文化,是让"算 token 账"变成像"算复杂度"一样自然的工程师本能。八、写在最后:经济学视角的真正意义
写到这里,我想回到那张课件的标题——Token 经济学。为什么用"经济学"这个词?我觉得这个词的选择非常精准。经济学研究的是稀缺资源的最优配置。在 LLM 时代,token 就是那个新的稀缺资源——它有成本(API 费用)、有上限(context window)、有时间维度(延迟)、有边际效用递减(context 越长模型越分心)。把 token 当作经济资源来思考,意味着我们要从"能不能用"上升到"怎么用最优"。这个跨越,恰恰是任何技术从早期阶段走向成熟阶段的标志。互联网早期,没人算带宽账;现在 CDN 和压缩是基本功。云计算早期,没人算资源账;现在 FinOps 是一个独立学科。接下来,token 经济学会成为每个 AI 应用团队的必修课。会算 token 账的团队,能跑出可持续的商业模式;不会算的,会在某个增长拐点上被成本压垮。而那张课件里的三个概念——Debt、Leverage、Dividend——只是这门新学科的入门词汇。真正的功夫,在于把软件工程几十年沉淀下来的智慧,重新用 token 的语言讲一遍。 夜雨聆风
夜雨聆风