 夜雨聆风
夜雨聆风几周前我开始看 llama.cpp 的源码。想看看"为什么我这台本地的笔记本也能跑得动 7B 甚至 14B 模型",结果发现——这个项目太有意思了。所以我准备尝试写篇系列文章(又开新坑😂)。
从推理引擎开始,如果你也想知道 llama.cpp 的推理引擎 GGML 是怎么设计的,可以看看这篇文章,希望对你有帮助。这是整个系列的第一篇,后面还有 GGUF 格式、130+ 架构支持、推理管线、量化系统、GPU 后端等。
引言:先说清楚这篇文章怎么读
GGML 源码让我感觉:每个设计决策都是被逼出来的。 不是"我觉得这样很酷所以我要这样做",而是"不这样做就解决不了前面的问题"。
所以这篇文章的写法也很简单:先问"为什么需要这个东西",再讲"它是怎么实现的"。 每一步都标注了真实 GGML 源码中对应的位置——你可以随时打开源码对照着看。
为了让你不迷失在 8000 行 C 代码里,我还写了一个 400 行的教学版实现叫 micro-ggml(https://github.com/LiCong-22/micro-ggml)。它在逻辑上和 GGML 完全一致,但只有最核心的骨架(主要源码太复杂了,让ai整了一版简易版本 )。文章里会反复引用它。
)。文章里会反复引用它。
第一章:张量——一切计算的基石
1.1 什么是张量?它解决什么问题?
大模型的计算说穿了就是对一堆多维数组做操作:矩阵乘法、加法、ReLU、归一化...
天真一点的话,你可以为每种数据都单独声明变量——float x[768]、float W[768][768]... 但当模型有 290+ 个这样的数组、每个形状都不同,你还一个一个手写吗?显然不行。
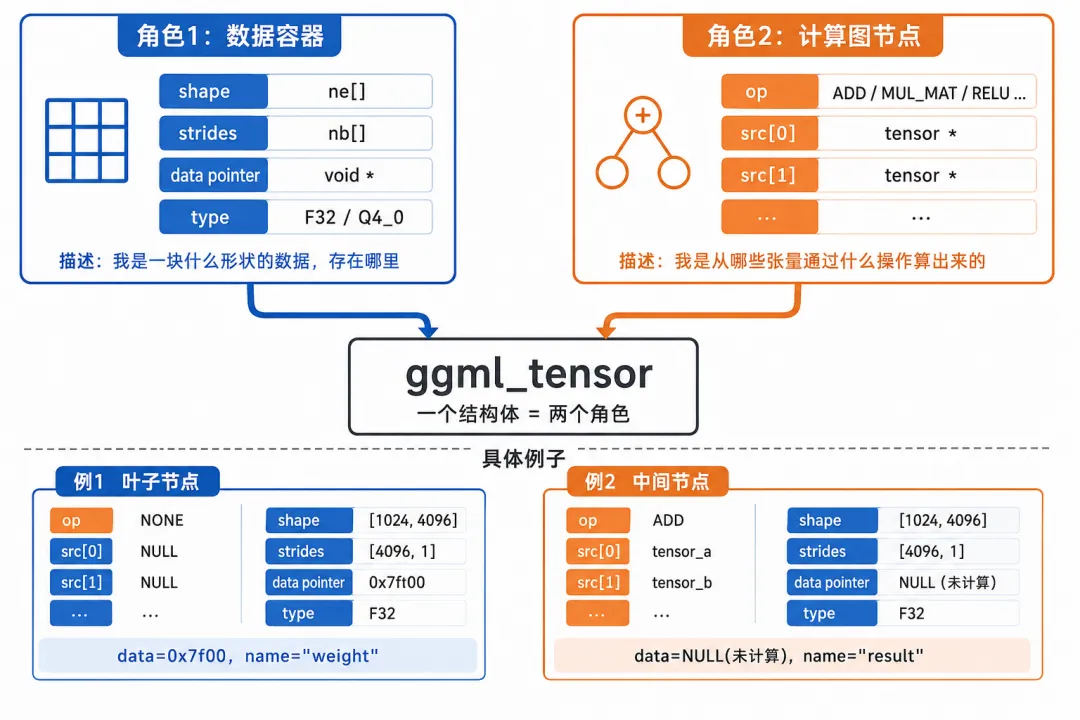
所以 GGML 定义了一个统一数据结构来描述任意形状、任意类型的数据。它叫"张量"(Tensor,就是一个多维数组的统一称呼),定义在 ggml.h:660:
struct ggml_tensor {enum ggml_type type; // 数据类型:F32? F16? Q4_0(量化格式)? 40+ 种int64_t ne[GGML_MAX_DIMS]; // ★ 各维度有多少个元素(逻辑形状)size_t nb[GGML_MAX_DIMS]; // ★ 各维度的字节步长(物理布局)enum ggml_op op; // 我是哪种运算的结果(叶子节点=NONE)struct ggml_tensor * src[10]; // ★ 我的输入是哪几个张量void * data; // 指向实际浮点数的内存char name[64]; // 调试名字,如 "blk.0.attn_q.weight"};
这个结构体同时扮演两个角色:角色一:数据容器。type + ne[] + nb[] + data 完整描述了"我是一块什么形状的数据,存在哪"。
角色二:计算图节点。op + src[] 完整描述了"我是从哪些张量通过什么运算产生的"。"叶子节点"(权重、输入数据)的 op=NONE、src 全是 NULL,说明数据是外部提供的,不需要计算。
为什么这俩字段这么重要? 因为有了 op 和 src[],你就不需要手写执行顺序了。你只需要说"我要 a + b",GGML 自己知道:先确保 a 和 b 都算好了、然后调用加法函数、结果放哪。整个推理引擎的自动编排,全靠这两个字段。
拿 PyTorch 对比一下:你得用 torch.Tensor 存数据,用 torch.autograd.Function 记计算——两套独立系统。GGML 一个结构体全干了。说实话我第一次看到这个设计的时候,心想"这也太简单了吧"——但越看越觉得这恰恰是最精妙的地方。
1.2 ne 和 nb 的分离——为什么需要两个数组?
说实话,这个设计我第一遍看源码的时候没注意——"不就是 shape 和 stride 吗,PyTorch 也有"。后来才发现,GGML 对这个东西的用法比 PyTorch 激进得多。
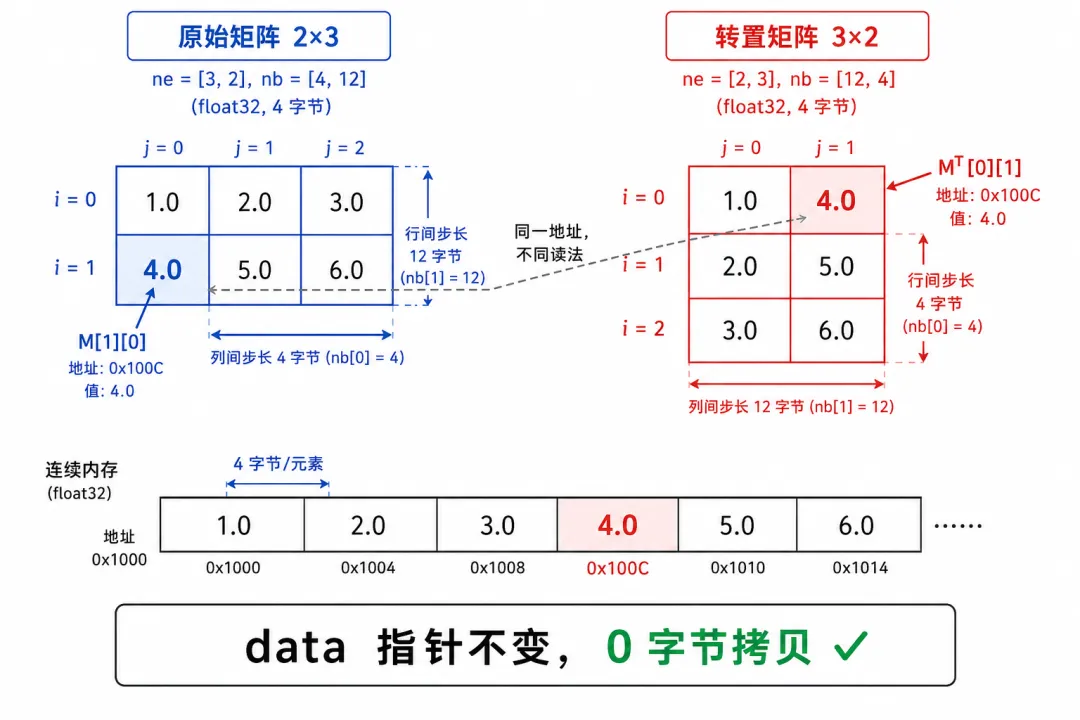
ne[](number of elements) 是逻辑形状:第 0 维有几个元素,第 1 维有几个...
nb[](number of bytes) 是物理步长:在维度 i 上"走一步",地址增加多少。
一个 2 行 3 列的 FP32 矩阵(FP32 = 32 位浮点数,每个数占 4 字节,是机器学习中最常用的"全精度"格式):
物理内存(6 个连续的 float, 共 24 字节):地址: 0x1000 0x1004 0x1008 0x100C 0x1010 0x1014值: 1.0 2.0 3.0 4.0 5.0 6.0ne[0]=3, ne[1]=2 ← "3列2行"nb[0]=4 ← sizeof(float) = 4 字节nb[1]=12 ← nb[0] × ne[0] = 4 × 3
访问任意元素 M[第i行][第j列] 的通用公式:
地址 = (char*)data + i × nb[1] + j × nb[0]关键来了——转置矩阵。传统做法是拷贝数据重新排列,但 GGML 只交换 nb:
转置前: ne=[3,2], nb=[4,12]访问 M[0][1] → 0x1000 + 0×12 + 1×4 = 0x1004 → 2.0转置后: ne=[2,3], nb=[12,4] ← ne 和 nb 角色互换了!访问 M^T[1][0] → 0x1000 + 1×4 + 0×12 = 0x1004 → 2.0↑ 读到的是原矩阵 M[0][1],恰好就是转置期望的值
data 指针没变,物理内存没动,0 字节拷贝。 只换了一套 nb,就从同一块内存"读"出了不同的矩阵。
reshape(变形)也是同理。6 个连续的 float,设 ne=[6,1] 是列向量,ne=[2,3] 是 2×3 矩阵,ne=[3,2] 是 3×2 矩阵——只改 ne 和 nb,数据不动。这就是 GGML 里 reshape、transpose、permute 全部被标记为"空操作"(ggml_op_is_empty 返回 true)、执行时直接跳过的数学基础。
1.3 量化——14GB 模型为什么能跑在 8GB 内存上
说到张量的数据类型,就不得不提量化。这是 llama.cpp 能让大模型塞进小内存的看家本领,也很能体现 GGML 的实用主义哲学——"差不多对就行了,省下的内存是实打实的"。当然这个后面后重点讲讲,但是这里现介绍下。
基本思想:不存每个权重的精确值,而是把一批权重(32 个或 256 个)分到一组,共享一个缩放因子(scale),组内每个权重只存"相对 scale 的位置"。
FP32: 权重 = 0.3741 → 4 字节Q4_0: 32 个权重共用 1 个 scalescale = 0.4(用 FP16 存,FP16 = 16 位半精度浮点数,2 字节)权重_量化值 = round(0.3741/0.4 × 15) = 9 (4 bit)32 个权重一共: 2 + 32×0.5 = 18 字节vs 原本 128 字节 → 压缩 7 倍
GGML 的量化格式分为三大家族,区别在于块多大和scale 怎么存:
为什么 K 系列要把 scale 也量化? Q 系列每 32 个值用 2 字节存 scale——每个值分摊 2/32 = 0.0625 字节元数据开销。K 系列每 256 个值用 12 字节存 16 个量化 scale——每个值分摊 12/256 = 0.047 字节,更省。省出来的 bit 可以给权重本身,或者进一步降低 bpw。
为什么 IQ 系列能用更少的 bit 达到相同质量? 传统量化对所有权重一视同仁。但现实中有些权重的误差对最终输出影响大(重要),有些影响小。IQ 系列用一个叫 importance matrix 的东西量化"这个权重有多重要"——重要的多给 bit,不重要的少给。所以你看到一个 IQ2_XXS(2.06 bpw)可能和 Q3_K(3.44 bpw)质量差不多。
推理时量化数据怎么用? 权重以量化格式存在 backend buffer 里(②),推理时每个操作的计算函数先反量化(dequantize)一行到 Scratch Buffer,再做计算。比如 Q4_0 的矩阵乘法:先把 32 个 4-bit 值反量化成 32 个 float(w[i] = scale × quant_value[i]),然后用这些 float 做标准的浮点矩阵乘法。反量化开销很小,因为 memory-bound 场景下,省下的内存带宽远大于解压的 ALU 开销——这正是量化的精髓:"在内存瓶颈上做节俭,在计算瓶颈上做冗余。"
一个 35B 参数的 MoE 模型(MoE = Mixture of Experts,混合专家——总参数很多但每次推理只激活一小部分),Q4_K_M 量化后约 21 GB。但用 IQ2_M(~2.7 bpw)可以压到约 14 GB。这就是一个 35B 模型能在你 15 GB 内存 + 12 GB 显存的机器上跑起来的原因——量化 + CPU+GPU 混合推理。
1.4 视图系统——reshape/transpose/permute 怎么做到零拷贝的?
前面讲了 ne/nb 分离可以在数学上实现零拷贝。但 GGML 在工程上是怎么做的?答案是 视图系统。
每个 ggml_tensor 有两个字段专门支持视图:
struct ggml_tensor {// ...struct ggml_tensor * view_src; // 如果我是视图,指向源张量size_t view_offs; // 我在源张量中的偏移量(字节)// ...};
创建视图的流程(ggml_new_tensor_impl, ggml.c:1712):
当你调用 ggml_reshape(ctx, a, new_shape) 时:
// 1. 在 context 中创建新张量壳子(no_alloc 模式,不需要新数据空间)result = ggml_new_tensor_impl(ctx, a->type, dims, new_ne, a, 0);// ↑ ↑// view_src=a view_offs=0// 2. 修改 ne 和 nb 以适应新形状(数据还是 a 的数据)result->ne = new_ne;// nb 按新 ne 重算// 3. 贴标签result->op = GGML_OP_RESHAPE;result->src[0] = a;// result->data = a->data + 0 ← 和 a 指向同一块内存!
对于 transpose、permute、slice(切片),逻辑完全一样,只是 nb 的计算方式不同: - reshape:改 ne,nb 按新 ne 重新计算 - transpose:交换 ne[0]↔ne[1],nb[0]↔nb[1] - permute:重排 ne[] 和 nb[] 的对应关系 - slice:改 ne(取子集),data 地址加 offset
视图链的展平(ggml.c:1723-1727):
如果你对同一个数据连续做多次视图操作(reshape→transpose→slice),会形成一条视图链:数据 → reshape视图 → transpose视图 → slice视图。每次访问数据都要跳三层指针。
GGML 在创建新视图时自动展平这条链:
if (view_src != NULL && view_src->view_src != NULL) {view_offs += view_src->view_offs; // 累加偏移量view_src = view_src->view_src; // 跳过中间层,直接指向根部}
这样 slice 视图的 view_src 直接指向原始数据张量,而不是 transpose 视图。不管链有多长,始终只跳一次指针。
为什么这些操作是"空操作"?
ggml_op_is_empty(ggml-impl.h:88)对 RESHAPE、VIEW、TRANSPOSE、PERMUTE 返回 true。在 ggml_graph_compute_thread 中,空操作直接被跳过——不分配 compute buffer,不执行计算函数。 因为"计算结果"已经在源张量的 data 里了,只是被换了一套 ne/nb 来读。
这和 Galloc 形成了有趣的对比:Galloc 通过 reuse 减少内存分配次数,而视图系统通过"共享 data 指针"完全不产生分配。两种优化互不冲突——视图只管元数据层的复用,Galloc 管数据层的复用。
第二章:Arena Allocator——批量内存管理
张量有了,但 290 个张量怎么管?总不能用 malloc 申请 290 次吧。这章聊聊 GGML 的"内存池"。
2.1 290 个张量,难道 290 次 malloc?
如果每个 tensor 都单独 malloc: - 分配慢:malloc 需要查空闲链表、找合适大小的块 - 泄漏风险:忘记 free 一个就是内存泄漏 - Cache 差:数据分散,CPU 缓存命中率低
2.2 方案:一次申请一大块,内部顺序追加
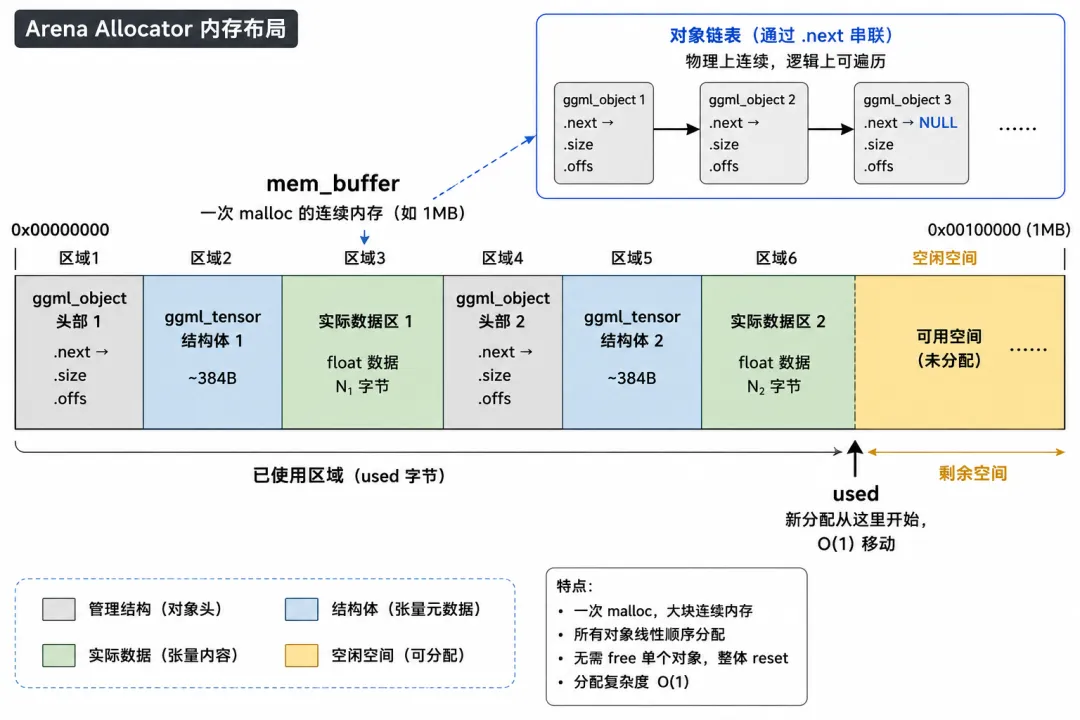
GGML 的做法叫 Arena Allocator:一次 malloc 一大块连续内存,所有张量在里面顺序排列(ggml.c:1557)。
mem_buffer (一次 malloc 1MB):┌──────────┬──────────────┬──────────┬──────────────┬─────┐│ 张量#1│ 张量1的数据 │ 张量#2│ 张量2的数据 │ ... ││ (结构体) │ (实际float值) │ (结构体) │ (实际float值)│ │└──────────┴──────────────┴──────────┴──────────────┴─────┘
"分配新张量"只需把尾指针后移(O(1))。"释放"就是整块内存一起 free(O(1))。不存在碎片、不需要空闲链表。就像一个大操场——人只会往后站,不留空隙;散场时所有人一起走。
2.3 但真实 GGML 更精妙——对象链表
micro-ggml 的 Arena 只有尾指针移动。但真实 GGML 在每个张量前加了一个 ggml_object 头部,串联成链表(ggml.c:1654)。
为什么需要链表?因为后续流程中,需要把 Arena 里所有张量的数据统一迁移到 backend buffer——可能是 GPU 显存,可能是 mmap 映射的文件。ggml_backend_alloc_ctx_tensors_from_buft(ggml-alloc.c:1237)遍历 context 里所有张量,统一分配 buffer:
第 1 遍:遍历 context,算总数据大小 = 122 MB第 2 遍:分配 buffer = malloc(122MB) 或 cudaMalloc(122MB)第 3 遍:逐个 tensor,在 buffer 里线性分配空间tensor->data = buffer_base + offsettensor->buffer = buf第 4 遍:从 GGUF 文件拷贝权重值到 buffer(或用 mmap,不拷贝)
设计原则:张量的"身份证"(结构体)和"身体"(权重数据)是分离的——结构体在 CPU 的 Arena 里,数据可能在 GPU 显存里。两者通过 tensor->data 和 tensor->buffer 指针连接。
2.4 mmap(内存映射)——100GB 模型"瞬间"加载
这可能是 GGML 最被低估的性能特性。llama.cpp 默认使用 mmap 来"加载"模型。
传统做法:打开文件 → malloc 一块内存 → fread 把整个文件内容读到内存 → 关闭文件。100GB 文件 = 需要 100GB 物理内存,而且加载过程要等几分钟。
mmap 的做法:告知操作系统"把磁盘上这个文件的第 N 到第 M 字节,映射到我进程地址空间的第 P 到第 Q 个虚拟地址"。操作系统返回"好的,已记录"。数据没有从磁盘读入内存——只是建了一个映射关系。
mmap(GGUF文件, offset, length) 后:磁盘上的 GGUF 文件: 进程虚拟地址空间:┌──────────────────┐ ┌──────────────────┐│ 文件头 │ │ 0x7f0000000000 ││ KV 元数据 │ ═══映射═══→│ (指向文件头) ││ ... │ │ 0x7f0000001000 ││ token_embd 权重 │ ═══映射═══→│ (指向权重数据) ││ blk.0.attn_q │ │ ... ││ ... │ │ │└──────────────────┘ └──────────────────┘
程序通过 tensor->data 指针访问权重时,直接读虚拟地址。如果这个地址的对应页面还没加载到物理内存,CPU 触发缺页中断(page fault),操作系统透明地从磁盘读取对应的 4KB 页到物理内存,然后程序继续——完全不知道刚才发生了什么。
关键效果:
- 加载速度
: llama_model_load_from_file几乎瞬间返回。100GB 模型"打开"和 100MB 模型一样快——都是建虚拟地址映射。 - 内存消耗
:实际物理内存占用只取决于推理过程中真正访问到的数据。如果某些层的权重在当前推理中没有被用到,它们对应的页面永远不会被加载。 - 多进程共享
:如果多个 llama.cpp 进程加载同一个 GGUF 文件,它们共享同一份物理内存页面(操作系统级别的 page cache),不需要各自占用一份。
但 mmap 也有局限:它要求 GGUF 文件在磁盘上的布局和内存访问模式匹配。GGUF 格式(系列第二篇会讲)就是为此设计的——权重按层连续存储,和推理时的访问顺序一致,最大化缺页中断的批量效率。
第三章:延迟执行——GGML 最重要的架构决策
3.1 构建阶段:只贴标签,不计算
当你写 relu(Wx + b) 时:
wx = ggml_mul_mat(ctx, W, x); // ①wx_b = ggml_add(ctx, wx, b); // ②out = ggml_relu(ctx, wx_b); // ③
每一行都只是"描述",没有计算。 来看 ggml_add_impl(ggml.c:2004):
struct ggml_tensor * ggml_add_impl(ctx, a, b, bool inplace) {result = inplace ? ggml_view_tensor(ctx, a): ggml_dup_tensor(ctx, a); // 复制 a 的形状result->op = GGML_OP_ADD; // ★ 贴标签:"我是加法"result->src[0] = a; // ★ 记下:"我从 a 来"result->src[1] = b; // ★ 记下:"我从 b 来"// result->data = NULL // 没算!return result;}
ggml_add 不做加法。 它只创建一个新张量壳子,贴上标签,然后返回。
inplace 参数是干什么的? 如果 inplace=true,result 不是分配新内存,而是复用输入 a 的数据空间。计算结果直接覆盖 a。这适用于"算完加法后 a 的原值已经没用了"的场景——省一次内存分配,也减少 Galloc 压力。不是所有操作都支持 inplace,GGML 只在明确安全时才用。
3.2 执行阶段:遍历图,分发计算
真正计算发生在 ggml_graph_compute_thread(ggml-cpu.c:2962):
for (node_n = 0; node_n < cgraph->n_nodes; node_n++) {node = cgraph->nodes[node_n];if (ggml_op_is_empty(node->op)) continue; // reshape/transpose 跳过if (!(node->flags & GGML_TENSOR_FLAG_COMPUTE)) continue;ggml_compute_forward(¶ms, node); // ★ 真正执行!if (node_n + 1 < cgraph->n_nodes)ggml_barrier(threadpool); // barrier(关卡):所有线程必须到达这里,才能继续}
ggml_compute_forward(ggml-cpu.c:1692)是一个巨大的 switch:
switch (node->op) {case GGML_OP_ADD: ggml_compute_forward_add(params, node); break;case GGML_OP_MUL_MAT: ggml_compute_forward_mul_mat(params, node); break;case GGML_OP_ROPE: ggml_compute_forward_rope(params, node); break;case GGML_OP_FLASH_ATTN_EXT: ggml_compute_forward_flash_attn(...); break;// ... 100+ 个 case}
每个计算函数从 node->src[]->data 读输入,算结果,写入 node->data。
3.3 为什么延迟执行能带来图复用?
LLM 生成对话时,每吐一个字(token)都要把整个网络跑一遍。但网络结构完全不变,变的只是每一步输入的 token。
如果把"描述"和"执行"混在一起,每吐一个字都要重新描述整个网络(几百次函数调用 × 500 tokens)。
延迟执行让你可以:构建一次,执行 N 次。
在真实 llama.cpp 中,图复用不是"凭感觉"的,而是由 can_reuse()(llama-graph.h:572)做严格的结构等价性检查。只有确认新旧两个 llm_graph_params 在拓扑层面上完全一致,才复用旧图。
检查分为两组:
第一组:ubatch 结构检查——这批 token 的"排列方式"是否和上次一样?
// ubatch 级别bool can_reuse =ubatch.n_tokens == other.n_tokens && // token 数相同?ubatch.n_seqs == other.n_seqs && // 序列数相同?ubatch.n_seqs_unq == other.n_seqs_unq && // 唯一序列数相同?ubatch.n_seq_tokens == other.n_seq_tokens && // 每序列 token 数相同?same_token_or_embd; // 输入类型一致(token vs embedding)
n_tokens 是最关键的——它决定了计算图中每个中间张量的 ne[] 最后一维。n_tokens 变成 2,所有的 Q、K、V、attention mask 的形状都翻倍,图结构就不一样了。
第二组:上下文参数检查——推理模式、适配器、采样器是否和上次一样?
// 参数级别bool can_reuse =cparams.embeddings == other.embeddings && // 是否提取 embedding(改变输出结构)cparams.causal_attn == other.causal_attn && // 因果/双向注意力(改变 mask 结构)arch == other.arch && // 模型架构(不同模型图完全不同)gtype == other.gtype && // 图类型(编码器 vs 解码器)cvec == other.cvec && // Control Vector 指针loras == other.loras && // LoRA 适配器指针(第三章 3.1 讲的 inplace add)cross == other.cross && // 交叉注意力数据samplers_equal(samplers, other.samplers); // 采样器配置
为什么连指针也要检查?loras、cvec、cross 都是指针比较(==),不是内容比较。因为 LoRA 适配器改变了图结构——它在每个 ggml_mul_mat 旁边插入了额外的矩阵乘法和加法节点。LoRA 换了 → 图拓扑不同 → 必须重建。
当 can_reuse 返回 false 时,process_ubatch 调用 graph_reserve → 分配新的 graph_ctx(Arena) → 重新调用 llm_build_xxx 构建 287+ 个节点 → 重新拓扑排序 → 保存到 gf_res_prev 供后续复用。但如果返回 true,这些全部跳过——十几个内存分配、几百次函数调用、一次拓扑排序,全部省掉。
但"图复用"的前提是图已经存在了。那么图是怎么来的?当你写了 ggml_mul_mat、ggml_add、ggml_relu 这些"贴标签"调用后,它们通过 src[] 互相引用形成了一张网。但这张网需要一个执行顺序——你不能先算 wx+b 再算 wx。这就引出了下一章的主题。
第四章:计算图与拓扑排序
4.1 通过 src[] 形成有向无环图(DAG)
第三章讲了 ggml_mul_mat、ggml_add、ggml_relu 这些"贴标签"调用。每调用一次,就在 graph_ctx 里创建一个新壳子,并且通过 src[] 指向前面的壳子。
经过三次调用后,内存里有这些张量:
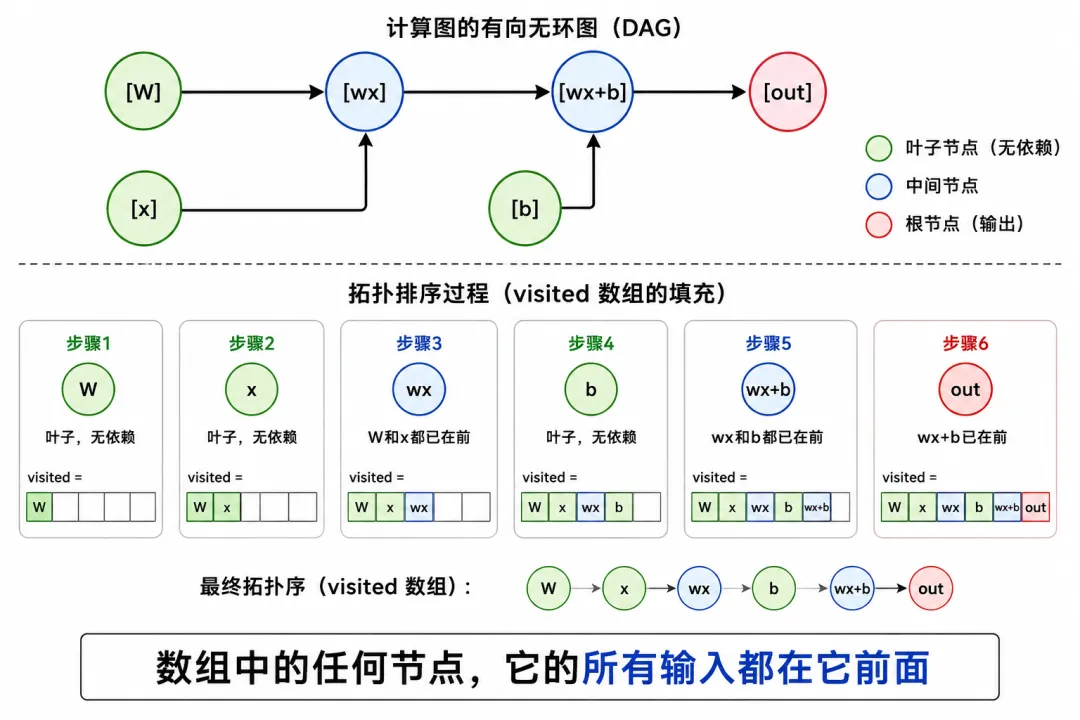
w: op=NONE, src=[], data=权重值 ← 叶子(Arena ①)x: op=NONE, src=[], data=输入值 ← 叶子b: op=NONE, src=[], data=偏置值 ← 叶子wx: op=MUL_MAT, src=[w,x], data=NULL ← 中间(graph_ctx ③)wx+b: op=ADD, src=[wx,b], data=NULL ← 中间out: op=RELU, src=[wx+b], data=NULL ← 根
src[] 把这些张量连接成了一个有向无环图(DAG)——"有向"因为指针有方向(src 指向前驱),"无环"因为有环就没法执行了。
W ──┐├──→ wx ──→ wx+b ──→ outx ──┘ ↗/b ─┘
图结构的核心约束:你不能先执行 wx+b 再执行 wx——算 wx+b 时 wx 的数据还没出来。 需要拓扑排序,把所有节点排成一个"每个节点都在它的输入后面"的序列。
4.2 从根节点出发收集所有祖先
ggml_build_forward_expand 的工作就是:从 out 出发,沿着 src[] 指针向上走,收集所有需要计算的节点,排好序。
具体做法是 DFS(深度优先搜索):对于每个节点,先递归处理它的所有 src[],然后再把自己加入列表。这样保证任何节点的输入都在它前面。
4.2 代码实现:mg_visit — DFS + 去重
从最终输出出发,用 DFS 向上追溯。micro-ggml 的 mg_visit 函数体只有 15 行:
staticvoidmg_visit(mg_tensornode, mg_tensor **visited, intn) {for (int i = 0; i < *n; i++)if (visited[i] == node) return; // 去重for (int i = 0; i < 4; i++)if (node->src[i])mg_visit(node->src[i], visited, n); // ★ 先递归处理输入visited[(*n)++] = node; // ★ 最后加自己}
追踪一遍 mg_visit(out, [], 0):
❶ mg_visit(out) → 处理 src: wx+b❷ mg_visit(wx+b) → 处理 src: wx, b❸ mg_visit(wx) → 处理 src: W, xW: src=[] → visited[0]=W, n=1x: src=[] → visited[1]=x, n=2→ visited[2]=wx, n=3b: src=[] → visited[3]=b, n=4→ visited[4]=wx+b, n=5❻ → visited[5]=out, n=6结果: [W, x, wx, b, wx+b, out]
叶子在数组最前面,根在最后面。按此顺序执行,每个节点的输入必定已算好。真实 GGML 用 hash set 做去重(O(1) 而非 O(n)),逻辑不变。
第五章:Galloc——中间结果的智能回收
前面的 Arena 解决了"结构体放哪"的问题,但中间结果的数据怎么管?每次 decode 有 287 个节点,如果每个都 malloc,不仅慢,而且会出现大量"已经没人用但还没释放"的垃圾占着内存。
Galloc 就是解决这个问题的:一个能分配、能释放、能复用的图级内存管理器。
5.1 问题:不是所有中间结果都需要同时活着
看第三章的 relu(Wx+b) 例子。计算顺序是 W → x → wx → b → wx+b → out。当算到 wx+b 时,wx 已经没用了——out 只需要 wx+b。但如果不管它,wx 的数据会一直占着内存直到整张图执行完毕。
对于 287 个节点的真实推理,这种"算完就扔"的中间结果占大多数。同时存活的通常只有几十个。所以理想做法是:算完就回收,后面节点复用这块空间。
5.2 怎么知道"没人需要了"?use_count 引用计数
第一步:构建图时统计。 拓扑排序完成后,遍历所有节点,对每个节点的 src[] 加引用计数:
// 构建图时(ggml_build_forward_expand 内部)for (int i = 0; i < n_nodes; i++) {node = cgraph->nodes[i];for (int s = 0; s < GGML_MAX_SRC; s++) {if (node->src[s]) {cgraph->use_counts[hash(node->src[s])]++; // src 多了一个消费者}}}
对于 relu(Wx+b):
W: use_count=1(被 wx 引用)x: use_count=1(被 wx 引用)wx: use_count=1(被 wx+b 引用)b: use_count=1(被 wx+b 引用)wx+b: use_count=1(被 out 引用)out: use_count=0(最终输出)
第二步:执行时每算完一个节点就检查。 看第八章 8.4 讲过的主循环,每算完一个节点后:
for (节点 N 的每个 src) {src->use_count--;if (src->use_count == 0 && src->data != NULL && src != 叶子节点) {galloc_free(galloc, src->data, size); // ♻ 回收src->data = NULL;}}
use_count 从 N 到 0 的那一刻,意味着"所有需要读这个数据的下游节点都已经算完了"——这是释放的精确时刻。
5.3 释放到哪?空闲链表的三种操作
Galloc 的核心数据结构是按地址排序的空闲块链表:
struct free_block {size_t offset; // 在 compute buffer 中的偏移size_t size; // 大小(字节)};// 空闲块数组,按 offset 升序排列struct free_block free_list[MAX_BLOCKS];int n_free;
操作一:分配(alloc)——两阶段 Best-Fit
真实 GGML 的 ggml_dyn_tallocr_alloc(ggml-alloc.c:200-260)有两阶段搜索:
阶段 1:在非末尾的空闲块中找 best-fit。 遍历除了最后一个以外的所有空闲块,找"能装下且浪费最少"的块。为什么排除最后一个?最后一个块后面是未分配空间,可以"生长"——留给阶段 2。
for (int c = 0; c < n_chunks; c++) {for (int i = 0; i < chunk->n_free_blocks - 1; i++) {if (block->size >= size && block->size <= best_fit_size) {best = block; // 更新最佳匹配}}}
为什么是 Best-Fit?小洞刚好补小坑,大洞留给大块。 如果选了最大的块,一个大洞被切走一小块后剩余部分还是很大(浪费),而且后续的大 tensor 可能找不到足够大的洞。
命中后:从该块切走 size 字节,剩余部分变小留在空闲列表。如果刚好用完(剩余 0),删除该空闲块。
阶段 2:没找到合适的,尝试用最后一个空闲块。 最后一个块的独特之处是它可以"生长"——因为它后面是未分配内存。这里用 reuse_factor 来量化"浪费程度":
int64_t reuse_factor = chunk->max_size - block->offset - size;// reuse_factor < 0:需要扩容// reuse_factor = 0:完美匹配// reuse_factor > 0:有多余空间浪费
遍历所有 chunk,选 reuse_factor 最优的:优先完美匹配,其次浪费最少。
阶段 3:都不行,开新 chunk。 真实 GGML 支持最多 16 个独立 buffer chunk。新 chunk 的初始大小是 max(size, max_chunk_size)。如果已经用满 16 个配额,最后一个 chunk 可以无限大。
操作二:释放(free)——插入 + 合并
释放时不是简单地追加到空闲列表末尾。因为列表按 offset 排序,需要找到正确的插入位置:
void galloc_free(ptr, size) {offset = ptr - buffer_base;// 1. 找到插入位置(保持 offset 升序)for (int i = 0; i < n_free && free[i].offset < offset; i++);// 2. 检查能否和前一个块合并if (i > 0 && free[i-1].offset + free[i-1].size == offset) {free[i-1].size += size; // 合并!// 再检查能否和后一个合并if (i < n_free && offset + size == free[i].offset) {free[i-1].size += free[i].size;删除 free[i]; // 三合一}return;}// 3. 检查能否和后一个合并if (i < n_free && offset + size == free[i].offset) {free[i].offset = offset;free[i].size += size;return;}// 4. 不能合并,插入新块数组后移,插入 {offset, size} 到位置 i}
相邻合并是反碎片化的关键。 如果连续三个中间结果先后被释放,它们不会变成三个小碎片——而是自动合成一个大块,可以被后续的大 tensor 使用。
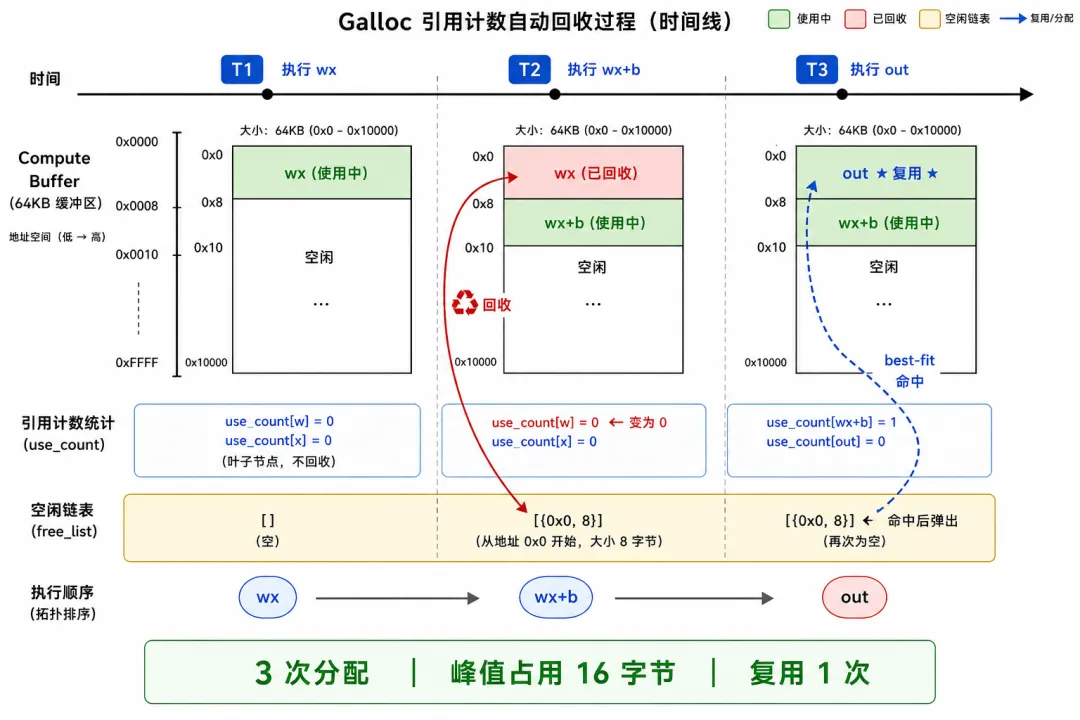
5.4 完整追踪——三分三释,峰值 16B
以 relu(Wx+b) 为例,每个中间结果是 2 个 float(8 字节)。初始 Galloc:64KB 全空,n_free = 0。
T1: alloc 8B → 没有空闲块 → 从末尾分配 → wx->data = offset 0空闲列表: [] (空)已用: [0, 8) = wxT2: alloc 8B → 没有空闲块 → 从末尾分配 → wx+b->data = offset 8空闲列表: []已用: [0, 8) = wx, [8, 16) = wx+b节点 wx+b 执行完毕:wx->use_count: 1 → 0 → ♻ free(offset 0, size 8)空闲列表: [{0, 8}] ← wx 的 8 字节被回收已用: [8, 16) = wx+bT3: alloc 8B → best-fit:遍历空闲列表[{0, 8}]: 8 >= 8 → 命中!完美匹配!out->data = offset 0 ★ 复用!空闲列表: [] (刚好用完了)已用: [0, 8) = out, [8, 16) = wx+b
3 次分配,峰值内存 16 字节(而非 24 字节),1 次复用。 对于 287 个节点,这个效果被放大几百倍——compute buffer 通常只需要几十 MB,而不是几百 MB。
5.5 真实 GGML 的 Galloc 还多了什么
micro-ggml 版是单 buffer + 简单空闲链表。真实 GGML(ggml-alloc.c:200-260)多了:
- 多 chunk
:每个 GPU 后端有自己的 compute buffer 作为独立 chunk(最多 16 个) - Chunk 动态增长
:最后一个 chunk 的空闲块可以超出 max_size限制扩容 - 对齐处理
:所有分配都对齐到后端的对齐要求(CPU 16B,GPU 128B+) - Chunk 间最佳匹配
:两阶段搜索跨所有 chunk,选全局最优
但核心思想一模一样:引用计数判定"何时回收",空闲链表管理"回收到哪",Best-Fit 决定"怎么复用"。
第六章:KV Cache——让生成速度从 O(n²) 降到 O(n)
前面五章讨论了"内存怎么管"和"计算怎么排"。但 LLM 推理还有一个独特的性能瓶颈——Attention 的计算量随序列长度平方增长。KV Cache 就是解决这个问题的。
6.1 问题:每生成一个新 token,都要重新算所有历史 token 的注意力?
回顾 Attention 的计算公式:
Attention(Q, K, V) = softmax(Q × K^T / √d) × V
在 autoregressive 生成中,第 1 步只有 token[0],第 2 步有 token[0,1],第 3 步有 token[0,1,2]...
如果没有缓存,第 N 步需要计算 N 个 token 的 Q、K、V,然后做 N×N 的注意力矩阵。总计算量是 O(n²)。
但注意一个关键事实:已经生成过的 token,它们的 K 和 V 向量不会改变。 因为 Transformer 是"因果"的——每个 token 只能看到自己和前面的 token,后面发生的事情不影响它。
所以 GGML 的做法是:把每一层已经算过的 K 和 V 缓存起来。 下次只需要算新 token 的 K 和 V,然后从缓存读历史的 K 和 V。
6.2 KV Cache 的工作原理
KV Cache 是一个 [n_kv, n_embd_head * n_head_kv] 的大矩阵,每层一个 K 缓存和一个 V 缓存。
第 1 步 (token_0): 算 K₀, V₀ → 写入缓存 [0]Attention: Q₀ × [K₀] → 结果第 2 步 (token_1): 算 K₁, V₁ → 写入缓存 [1]Attention: Q₁ × [K₀, K₁] → 结果↑ Q₁ 只算一次,K₀ 从缓存读第 N 步 (token_N): 算 Kₙ, Vₙ → 写入缓存 [N]Attention: Qₙ × [K₀...Kₙ] → 结果
每一步只用算1 个新 token 的 Q、K、V,然后做 1×N 的注意力。总计算量降到 O(n)。
6.3 内存开销和优化
KV Cache 的内存是巨大的。对于 LLaMA-7B(32 层,32 头,128 维/头,FP16):
每层 K 缓存: n_ctx × n_head_kv × n_embd_head × 2 bytes= 4096 × 32 × 128 × 2 = 32 MB每层 V 缓存: 同样 32 MB32 层总计: 32 × (32 + 32) = 2 GB
这就是为什么长上下文会吃大量内存——KV Cache 是 O(n_ctx) 的。
GGML 对此有多个优化: - GQA(分组查询注意力):不是每个 Q 头都有独立的 K、V 头,而是多个 Q 头共享一组 K、V(比如 8 个 Q 头共享 1 组 KV),直接成倍缩小 KV Cache - 量化 KV Cache:ggml_context_params.type_k 和 type_v 可以把 K、V 也量化(如 Q8_0、Q4_0),进一步压缩 - 滑动窗口(SWA):只保留最近 W 个 token 的 KV,老的直接丢弃
6.4 KV Cache 和 Galloc 的关系
KV Cache 的内存不在 Galloc 管理的 compute buffer 里。它是独立分配的大块内存(llama_kv_cache_init),生命周期和 llama_context 绑定。
Galloc 管的是"当前这一次 decode 的中间结果"(Q、K、V 的计算结果、Attention 输出、FFN 中间值)。这些用完就回收。而 KV Cache 是跨 decode 持久化的——这一次 decode 写入的 K、V,下一次 decode 还要读。
第七章:Scratch Buffer——所有节点共享的草稿纸
7.1 Compute Buffer 存"输出",Scratch 存"过程中"
Galloc 管理的 compute buffer 只存节点的输出。但节点内部需要额外临时空间。
Flash Attention 是什么? 它是一种优化过的注意力计算方法——不一次性算出整个 Q×K^T 矩阵(太大,放不进 cache),而是把 Q 和 K 切成小块(tile),一块一块地算,算完一块立刻做 softmax,避免把巨大的中间矩阵写到慢速内存。这里说的"Q 的 tile(256×96)"就是指切出来的一个小块。这些小块是算完就扔的临时数据,正好用 Scratch Buffer 存放。
7.2 为什么能共享?
因为图节点是严格串行的(每个节点后都有 barrier)。上一个节点完全结束,下一个才开始。所以 scratch buffer 可以"当前节点用完,下一个直接覆盖"。
ggml_graph_plan(ggml-cpu.c:2737-2960)遍历所有节点,估算每个的 scratch 需求,取最大值:
for (i = 0; i < n_nodes; i++) {switch (node->op) {case GGML_OP_FLASH_ATTN_EXT:prefill = sizeof(float) * (Q_TILE*DK + 2*Q_TILE*KV_TILE + ...) * n_tasks;decode = sizeof(float) * (heads*chunks*(2+DV) + n_tasks*(DK+2*DV));cur = MAX(prefill, decode);break;case GGML_OP_MUL_MAT: cur = sizeof(float) * n_tasks; break;case GGML_OP_SOFT_MAX: cur = sizeof(float) * ne0 * n_tasks; break;// ...}work_size = MAX(work_size, cur); // 取最大值!}cplan.work_size = work_size + CACHE_LINE_SIZE * n_threads;
对于 MiniMind(64M 模型,16 线程),Flash Attention 在 prefill 阶段(预填充:一次性处理用户输入的整个 prompt,通常几百到几千个 token 一起算)的 scratch 约 14 MB。即使图有 287 个节点,scratch buffer 也只需要 14 MB——因为取的是最大值,不是累加。7.3 完整的 Plan 函数——每种操作需要多少 scratch?
ggml_graph_plan(ggml-cpu.c:2737-2960)遍历图中所有节点,对每种操作估算它需要的临时空间和并行任务数。以下是完整的分类:
不需要 scratch 的操作(直接读写 src→dst,不需要中间缓冲):
GGML_OP_ADD, GGML_OP_MUL, GGML_OP_RELU, GGML_OP_GELU, GGML_OP_SILUGGML_OP_RMS_NORM, GGML_OP_SCALE, GGML_OP_SQR, GGML_OP_SQRTGGML_OP_CLAMP, GGML_OP_STEP, GGML_OP_TANH→ cur = 0 (不需要临时空间)
需要少量 scratch 的操作(每线程一个累加器或临时行缓冲):
GGML_OP_MUL_MAT: cur = sizeof(float) * n_tasks (每线程一个累加器)GGML_OP_SOFT_MAX: cur = sizeof(float) * ne0 * n_tasks (每线程一行 exp 和 sum)GGML_OP_ROPE: cur = sizeof(float) * ne0 * n_tasks (每线程旋转后的行)GGML_OP_TOP_K: cur = sizeof(int32_t) * ne0 * n_tasks(每线程排序索引)
需要大量 scratch 的操作(tile 缓冲 + 累加器):
GGML_OP_FLASH_ATTN_EXT:prefill: sizeof(float) * (Q_TILE*DK + 2*Q_TILE*KV_TILE + Q_TILE*DV+ KV_TILE*DV + KV_TILE*DK) * n_tasks解释: 每个线程需要 Q tile, K tile, V tile, QK^T 矩阵,softmax 中间值共 ~229K floatsdecode: sizeof(float) * (heads*chunks*(2+DV) + n_tasks*(DK+2*DV))解释: 每个线程只需要 VKQ 累加器 + 查询缓冲,比 prefill 小得多cur = MAX(prefill, decode) (取两种情况的最大值)
每次类型转换需要临时缓冲的操作:
GGML_OP_CPY, GGML_OP_DUP:如果涉及量化类型转换(如 Q4_0→F32),需要每线程一行 F32 缓冲cur = sizeof(F32) * ne0 * n_tasks
最终 work_size:
// 对所有节点取最大值work_size = MAX(work_size, cur);// 加上各线程的 cache line 对齐间隔cplan.work_size = work_size + CACHE_LINE_SIZE * n_threads;
为什么是取最大值而不是求和? 因为节点是串行执行的(barrier 保证)。同一时刻只有一个节点在用 scratch buffer,所以只需要够最大的那个用就行。
为什么加 CACHE_LINE_SIZE * n_threads? 每个线程的 scratch 区域之间需要一个 cache line(通常 64 字节)的间隔,防止"伪共享"——两个线程的变量在同一个 cache line 里,一个线程写会导致另一个线程的 cache line 失效,即使它们逻辑上不共享任何数据。
第八章:线程模型——从"每次创建"到"永久等待"
8.1 为什么 OpenMP 不够好?
OpenMP 是什么? 它是一套用于 C/C++ 的并行编程接口——你在代码里加一行 #pragma omp parallel for,编译器就自动帮你把循环拆到多个线程上并行执行。不用手写线程创建代码,非常方便。
但 OpenMP 的问题是:每次进入并行区域,线程都要"召集"(fork),退出的时"解散"(join)。 召集和解散本身有开销——需要内核参与、需要同步。对于 LLM 推理来说,每秒要执行几十次 decode,每次都 fork/join 的话,召集解散的开销会叠加到不可接受的程度。
8.2 Spin-then-Sleep:自旋一段时间,没活了才睡眠
GGML 使用自定义线程池。从线程是永久循环的,不销毁(ggml-cpu.c:3097)。主线程通过一个原子变量tp->n_graph 通知有活——原子变量是一种特殊的变量,多个线程同时读写它也不会产生数据错乱(硬件保证的"读-改-写"一气呵成,不会被其他线程打断)。
等待策略是"先自旋,再睡眠"(ggml-cpu.c:3054-3086):
// 第 1 步:自旋等待(spin)const uint64_t n_rounds = 1024UL * 128 * threadpool->poll;for (i = 0; !ready && i < n_rounds; i++) {ggml_thread_cpu_relax(); // PAUSE 指令,不占 ALU 管道}// 第 2 步:如果还没活,进入睡眠if (!ready) {ggml_mutex_lock(&mutex);while (!ready) ggml_cond_wait(&cond, &mutex); // 被内核挂起ggml_mutex_unlock(&mutex);}
为什么是 Spin-then-Sleep?纯 sleep 有上下文切换开销(微秒级),对高频 decode 来说不可接受。纯 spin 浪费 CPU。折中:先自旋一小段时间(约 10 万次 PAUSE,微秒级),大概率在这期间主线程就 kickoff 了。真的等久了才睡。
8.3 单操作内部如何并行:按行切分
GGML 的并行发生在两个层面:
层面 1:节点间串行(barrier 同步)。每个节点后所有线程汇合,确保依赖关系。
层面 2:节点内并行(按行切分数据)。一个操作内部,不同线程处理不同行。
以矩阵加法为例(ggml_compute_forward_add):
8 个线程处理 800 行的加法:线程 0: 行 [0, 100)线程 1: 行 [100, 200)...线程 7: 行 [700, 800)每个线程只读写自己负责的行,不需要锁。
以矩阵乘法为例(ggml_compute_forward_mul_mat):
C = A^T × B线程 0: 计算 C 的列 [0, M/nth)线程 1: 计算 C 的列 [M/nth, 2*M/nth)...每个线程有自己独立的临时累加器(在 Scratch Buffer 里分配),因此也不需要锁。
为什么 GGML 选择"按行切分"而非"按元素切分"? 因为按行切数据对 CPU 缓存友好——相邻元素在内存中也相邻。一个线程连续访问自己那几行时,CPU 一次性把相邻数据都加载到缓存里(这叫"空间局部性"),缓存命中率高。按元素切(比如线程 0 处理第 0, 8, 16... 号元素)会导致每个线程访问的地址是跳跃的,缓存刚加载的数据用不上就被踢出去了。
GGML 不支持"多操作同时执行"。 因为图是 DAG,节点间有严格依赖。在保证正确性的前提下,同时执行多个互不依赖的节点理论上是可行的,但 GGML 选择了更简单的设计——barrier 同步,一个节点一个节点地做。对于 autoregressive 推理(batch=1)这种场景,节点间的依赖几乎是全链式的,并行多个节点本来也没意义;只有在 batch 很大的 prefill 阶段才有价值,但那个阶段每个节点内部已经用满了所有线程。
8.4 一个完整的计算函数长什么样——以加法为例
前面讲了"按行切分"的概念。现在看真实 GGML 里的加法计算函数是怎么写的(简化版,只保留 F32 路径)。
源码在 ggml/src/ggml-cpu/ops.cpp:654,分两个版本:量化版本(ggml_compute_forward_add_q_f32)和 F32 版本。我们看 F32 版本的核心逻辑:
voidggml_compute_forward_add(const ggml_compute_params * params, // 线程参数(ith=线程编号, nth=总线程数)ggml_tensor * dst) // 目标张量{const ggml_tensor * src0 = dst->src[0]; // 输入 aconst ggml_tensor * src1 = dst->src[1]; // 输入 bconst int nr = ggml_nrows(src0); // 总行数(所有维度展开后)const int ith = params->ith; // 当前线程编号:0, 1, 2, ...const int nth = params->nth; // 总线程数// ★ 核心:按行切分const int dr = (nr + nth - 1) / nth; // 每个线程处理多少行(向上取整)const int ir0 = dr * ith; // 当前线程的起始行const int ir1 = MIN(ir0 + dr, nr); // 当前线程的结束行// 逐行处理for (int ir = ir0; ir < ir1; ++ir) {// 计算这一行在内存中的起始地址const char * src0_row = (char *)src0->data + ir * src0->nb[1];const char * src1_row = (char *)src1->data + ir * src1->nb[1];char * dst_row = (char *)dst->data + ir * dst->nb[1];// 逐元素加法for (int j = 0; j < src0->ne[0]; ++j) {float a = *(float *)(src0_row + j * src0->nb[0]);float b = *(float *)(src1_row + j * src1->nb[0]);*(float *)(dst_row + j * dst->nb[0]) = a + b;}}}
三个关键点:
1. 通过 ne 和 nb 访问数据,不是直接用数组下标。 注意 ir * nb[1] 和 j * nb[0]——这就是之前讲的"用步长访问任意形状张量"在计算函数里的应用。因为用了 nb,这个函数能处理转置后的张量(nb 被修改过的情况)。
2. 按行而不是按元素切分。dr * ith 到 dr * (ith+1) 是连续的行范围。一行内的所有元素都在同一个线程上处理,保证了 cache 友好——相邻元素在内存中相邻,被一起加载到缓存。
3. 不需要锁。 每个线程只写自己负责的行,读写的地址范围完全不重叠。没有数据竞争,所以不需要 mutex 或原子操作。
如果量化版本呢?
真实的 ggml_compute_forward_add 要处理量化输入(src0 是 Q4_0 格式,src1 是 F32)。逻辑变成:
for (int ir = ir0; ir < ir1; ++ir) {// 1. 把 src0 的这一行反量化成 F32(临时存在 Scratch Buffer 里)dequantize_row_q(src0_row, wdata, ne00); // Q4_0 → F32// 2. 逐元素加法for (int j = 0; j < ne00; ++j) {float a = wdata[j]; // 反量化后的值float b = *(float *)(src1_row + ...); // 直接读 F32dst_row[j] = a + b;}}
量化版本中,wdata 指向 Scratch Buffer(params->wdata,在 ggml_graph_plan 中估算和分配的临时空间)。每个线程有自己独立的区域(ne00 + CACHE_LINE_SIZE × ith 偏移),互不干扰。这就是 Scratch Buffer 在操作内部的用法,它把第七章(Scratch)和第八章(线程)在实际代码中串了起来。
8.5 一段关于"后端"的插话
本章讲的线程池、barrier 同步、按行切分——全部是 CPU 后端的实现。但 GGML 支持多种硬件:CPU(AVX/NEON)、NVIDIA GPU(CUDA)、Apple GPU(Metal)、Intel GPU(SYCL)、华为 Ascend(CANN)...
这些后端共享完全相同的上层代码。ggml_graph_compute 的主循环、ggml_compute_forward 的分发 switch、计算图的结构——全都不变。变的是每个操作的计算函数内部:CPU 版本按行切分给多个线程,CUDA 版本把矩阵分块发射到上千个 GPU 核心。后端的差异被 ggml_backend 接口封装起来了——这是系列后话了,待我有时间填坑。
第九章:一次真实推理的完整数据追踪
前面八章,每章讲了一个独立的概念。你可能会想:这些东西各自听懂了,但它们是零散的。好,这章我们就来一次"实战演练"——拿一个真实的 MiniMind 模型,从"你好"两个字出发,追踪一次完整的推理。你会看见 Arena、延迟执行、计算图、Galloc、KV Cache、Scratch Buffer、线程并行这一整套东西,是怎么在同一瞬间一起干活的。
9.1 用 MiniMind 模型来演示
我们用一个真实模型——MiniMind 这个LLM系列之前讲过(64M 参数,架构和 Qwen3 完全一致,只有 8 层但麻雀虽小五脏俱全)——来追踪一次完整的推理。
模型: MiniMind 3 (qwen3 架构)参数量: 63.91 M (六千四百万)层数: 8嵌入维度: n_embd = 768注意力头: n_head = 8, n_head_kv = 4 (GQA, Q:K=2:1)头维度: n_embd_head = 96词表大小: n_vocab = 6400FFN 维度: n_ff = 2432RoPE 频率: freq_base = 1,000,000(RoPE = 旋转位置编码,让模型知道每个 token 在第几个位置;Qwen3 用了超大的频率基数,更好地支持长上下文)
9.2 第 1 步:分词(Tokenize)
输入: "你好"↓ llama_tokenize(vocab, "你好", ...)输出: tokens = [1968] ← "你好"恰好是一个完整 token,1 个
9.3 第 2 步:调用链全景——从前端 API 到 GGML 操作
当 llama_decode(ctx, batch) 被调用时,实际执行路径是:
llama_decode() ← llama.cpp 公共 API(第三章 3.3 讲的 can_reuse 就在这里)└─→ llama_context::decode() ← 检查 batch、更新 memory、拆分 ubatch└─→ process_ubatch() ← 决定"复用旧图还是重建新图"├─ can_reuse? YES → 只更新输入(图复用,第六章 3.3)│ 直接 ggml_graph_compute(gf, galloc)│└─ can_reuse? NO → graph_reserve() 分配新的 graph_ctx(第二章 Arena)└─→ llm_build_qwen3() 构建计算图│在 graph_ctx 里调用 287 次 ggml_xxx():├─ ggml_mul_mat(ctx, wq, cur) ← 矩阵乘法节点│ → result->op=MUL_MAT, src=[wq, cur]│ → result->data=NULL(延迟执行,第三章 3.1)│├─ ggml_rope(ctx, Q, pos) ← RoPE 节点├─ ggml_rms_norm(ctx, cur, w) ← 归一化节点├─ ggml_flash_attn_ext(ctx, ...) ← 融合注意力节点└─ ... ← 共 287 个节点└─→ ggml_build_forward_expand() ← 拓扑排序(第四章)└─→ ggml_graph_compute(gf, galloc) ← 执行(第三章 3.2)
关键理解:llm_build_qwen3 里的每一行 ggml_mul_mat、ggml_rope、ggml_rms_norm 都是在 graph_ctx(no_alloc=true 的 Arena)里创建新的 ggml_tensor 壳子,设置 op 和 src[],然后立即返回。287 次调用,287 个壳子,零计算。和第三章讲的 ggml_add_impl 完全一样。
这 287 个节点被 ggml_build_forward_expand 做拓扑排序后存在 ggml_cgraph 里。然后 ggml_graph_compute 按第三章 3.2 的方式——遍历节点数组、调用 ggml_compute_forward 分发到具体计算函数。
9.4 第 3 步:一次矩阵乘法的完整追踪——从 API 到硬件
我们现在聚焦到计算图中最核心的一个操作——第 0 层的 Q 投影(wq × cur)。来看看它怎么从"图中的一个壳子"变成"真正的计算结果"。
构建阶段(第三章 3.1):
// llm_build_qwen3 内部,il=0(第 0 层)ggml_tensor * Qcur = ggml_mul_mat(ctx0, model->layers[0].wq, cur);
这一行在 graph_ctx(Arena,第二章)里创建了一个新壳子:
Qcur = {ne = [768, 1] ← 形状:768列 × 1行(1个token的Q向量)nb = [4, 3072] ← 步长op = GGML_OP_MUL_MAT ← 贴标签:矩阵乘法src[0] = model->layers[0].wq ← 权重(在模型 Arena 里,①)src[1] = cur ← 输入(在计算图 Arena 里,③)data = NULL ← 还没算!}
wq 是权重张量,shape [768, 768]——768 维输入,768 维输出(Q、K、V 各自独立投影)。cur 是当前层的输入,shape [768, 1]——768 维的向量,来自 token embedding。
执行阶段(第三章 3.2):
拓扑排序完成后,Qcur 在 gf->nodes[] 数组的某个位置。ggml_graph_compute_thread 走到这个节点时:
// ggml-cpu.c:2986 的执行循环node = cgraph->nodes[node_n]; // node = Qcurggml_compute_forward(¶ms, node); // 分发到矩阵乘法计算函数
ggml_compute_forward(ggml-cpu.c:1692)看到 node->op == GGML_OP_MUL_MAT,调用 ggml_compute_forward_mul_mat(params, Qcur)。
计算函数内部(第八章 8.4 讲过的模式):
ggml_compute_forward_mul_mat(params, Qcur) {// 1. 分配输出空间if (Qcur->data == NULL)Qcur->data = ggml_galloc_alloc(galloc, 768*4); // Galloc 分配(第五章)// 2. 按行切分给 16 个线程(第八章 8.3)int ith = params->ith; // 当前线程 0~15int nth = params->nth; // 总线程数 16int rows_per_thread = 768 / 16; // 每个线程处理 48 行// 3. 执行计算(GGML 的默认约定:C = A^T × B,第四章 4.1)// A = wq [768, 768], A^T = [768, 768]// B = cur [768, 1]// C = Qcur [768, 1]// C[m][n] = sum_k A^T[m][k] * B[k][n]// = sum_k wq[k][m] * cur[k][n]for (int m = 48 * ith; m < 48 * (ith+1); m++) {float sum = 0;for (int k = 0; k < 768; k++)sum += wq->data[k + m*768] * cur->data[k];Qcur->data[m] = sum;// 累加器 sum 在 Scratch Buffer 里(第七章),每个线程独立}}
算完后,Qcur->data里有了 768 个 float,这就是第 0 层的 Q 向量。
然后呢? Q 向量被 reshape 成 [96, 8, 1](96 维/头 × 8 个 Q 头,1.4 节的视图系统),过 RoPE(旋转位置编码),进入 Flash Attention(和 KV Cache 的 K、V 做注意力计算)。
同样的流程在每一层的每一个操作上重复——K 投影、V 投影、FFN gate、FFN up、FFN down、输出投影... 287 个节点,每个节点的执行模式和 Qcur 完全一样。
9.5 第 4 步:采样(从 6400 个 logits 中选 1 个)——跨越 GGML 边界
287 个节点全部执行完毕后,计算图中最后一个节点是 lm_head(输出投影,output.weight[6400, 768] × cur[768, 1])。它的 data 里有 6400 个 float——这就是 logits(每个 token 的"原始得分")。
此时 GGML 的工作结束了。控制权交还给 llama.cpp:
// 在 llama_context::decode() 内部float * logits = llama_get_logits_ith(ctx, batch.n_tokens - 1);// logits 指向 ④ Compute Buffer 中最后一个节点的 data
MiniMind 实际的 logits 值:
logits[1968] = 12.40 ← "你好" (最高!模型太小,只会复读自己)logits[615] = 9.31 ← "问"logits[622] = 8.76 ← "⿓"...
然后进入采样(Sampling)——这不是 GGML 的职责,而是 llama.cpp 的。采样器先对 6400 个 logits 做 softmax(转成概率分布),然后根据策略选 token: - Greedy(贪婪):永远选概率最高的 → 1968 → 输出"你好" → 下一次输入变成"你好你好" → 又选 1968 → 死循环 - Temperature + Top-P + Min-P(随机采样):偶尔选其他 token → 输出更多样,但 64M 的模型太小,乱选也是胡言乱语
同一个流程在 7B 模型上完全一致。 只是层数从 8 变成 32,维度从 768 变成 4096,节点数从 287 变成 1000+。每个节点的执行模式和本章追踪的 Qcur 一模一样。
9.6 性能数据
MiniMind 在 CPU 上的实际数据:prompt eval time: 0.00 ms / 1 tokeneval time: 0.00 ms / 8 runstotal time: 48.20 ms / 9 tokensgraphs reused: 8换成 7B 模型(Q4_K_M, CPU 16 线程):prompt eval: ~200 ms / 512 tokenseval: ~50 ms / tokengraphs reused: 几百次
第十章:完整架构图
前九章讲了九个独立的概念。但在一次真实的推理中,它们不是轮流的——是同时在运作的。这张图把它们全部画在一起。
当 llama_decode 被调用时: - ③ 计算图 Arena 里的 287 个 ggml_tensor,通过 src[] 指针跨 ctx 引用 ① 模型 Arena 里的权重张量 - 每个中间节点的 data 由 ④ Galloc 按 best-fit 分配,算完后 use_count 归零自动回收 - 计算函数内部通过 ⑤ Scratch Buffer 做临时反量化和累加 - ② 权重 Buffer 里的量化数据可能通过 mmap 映射自磁盘,按需加载 - 整个执行过程由 第八章 的线程池驱动,每个节点内多线程并行,节点间 barrier 同步
┌──────────────────────────────────────────────────────────────────────────┐│ llama.cpp 推理引擎 ││ ││ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ││ │ ① 模型 Arena │ │ ② 权重 Buffer │ │ ③ 计算图 Arena│ ││ │ ggml_context │──→│ backend_buf │ │ ggml_context │ ││ │ 290 个张量壳 │ │ 14 GB 连续 │ │ 287 个张量壳 │ ││ │ .data → ② │ │ malloc/mmap │ │ .data → ④ │ ││ └──────────────┘ └──────────────┘ └───────┬───────┘ ││ │ .src[] 跨 ctx 指针 ││ ┌──────────────────────┐ ┌──────────────────────────┐ ││ │ ④ Compute Buffer │ │ ⑤ Scratch Buffer │ ││ │ Galloc 管理 │ │ 一次 malloc(最大需求) │ ││ │ best-fit + use_count │ │ 所有节点共享,用完覆盖 │ ││ │ 几 MB ~ 几十 MB │ │ 几 MB ~ 几十 MB │ ││ │ 每次 decode 更新 │ │ 图执行期间临时使用 │ ││ └──────────────────────┘ └──────────────────────────┘ │└──────────────────────────────────────────────────────────────────────────┘① ② 加载时创建,永不释放。③ 图拓扑不变时复用。④ 每次 decode 更新。⑤ 每次执行分配。
图中六条数据流的对应关系:
- ①→② 的 data 指针
:模型加载时, ggml_backend_alloc_ctx_tensors_from_buft(第二章 2.3)建立 - ③→① 的 src[] 指针
: llm_build_qwen3(第九章 9.3)构建图时,每个ggml_mul_mat的src[0]指向权重张量 - ③→④ 的 data 指针
: ggml_graph_compute执行时,Galloc(第五章)分配后再设置 - ⑤ Scratch Buffer
: ggml_graph_plan(第七章 7.3)估算、ggml_graph_compute分配,每个节点执行时params->wdata指向它 - KV Cache(图中未画出)
:独立于这五块内存,由 llama_kv_cache_init分配,跨 decode 持久化
这五块内存 + KV Cache,构成了 llama.cpp 推理时的全部内存占用。理解了它们,你就理解了 llama.cpp 的内存模型。
![[Pasted image 20260507212141.png]]
第十一章:核心源码索引
ggml/include/ggml.h:660 | |
ggml/src/ggml.c:1557 | |
ggml/src/ggml.c:1654 | |
ggml/src/ggml.c:1712 | |
ggml/src/ggml.c:2004 | |
ggml/src/ggml-cpu/ggml-cpu.c:2737 | |
ggml/src/ggml-cpu/ggml-cpu.c:2986 | |
ggml/src/ggml-cpu/ggml-cpu.c:1692 | |
ggml/src/ggml-cpu/ggml-cpu.c:3054-3086 | |
ggml/src/ggml-alloc.c:200-260 | |
ggml/src/ggml-alloc.c:1237 | |
src/llama-graph.h:572-633 | |
https://github.com/LiCong-22/micro-ggml |
第十二章:回顾与下一步
12.1 七个设计决策,一张图
回到开头那个问题:一台笔记本,怎么跑起 14GB 的模型?
现在你应该能自己回答了:
① 量化(压 7 倍) → 14GB 变 2GB,能装下了② mmap 懒加载 → 100GB 模型"瞬间"打开,OS 按需加载③ Arena Allocator → 290 个张量结构体一次申请,O(1)分配④ 延迟执行 + 图复用 → 500 次 decode 只构建一次图⑤ Galloc + 引用计数 → 中间结果用完就回收,compute buffer 只需几十 MB⑥ KV Cache → 每步只算 1 个新 token,O(n) 而非 O(n²)⑦ 长驻线程池 → 微秒级响应,没有 fork/join 开销
我写 micro-ggml 的时候有一个体会:这七个决策不是并列的"七大特性",而是一个被另一个逼出来的。张量多了要 Arena,Arena 不能回收要 Galloc,中间结果涉及注意力引出 KV Cache……像多米诺骨牌一样,一推就全倒,但每一块都必须有。
这也是为什么我觉得 GGML 值得这么长一篇文章——它不是功能的堆砌,而是一连串精心设计的"不得不这样"。
12.2 接下来你可以做什么
第一步,跑一遍 micro-ggml。 400 行 C,5 秒编译,每一步都打印内部状态。
git clone https://github.com/LiCong-22/micro-ggmlcd micro-ggml && make run
第二步,翻开真实 GGML 源码。 用第十一章的表格,找到对应的函数。看完 micro-ggml 的 mg_graph_compute(15 行),再打开 ggml-cpu.c:2986 的 ggml_graph_compute_thread(50 行),你会忍不住笑出来——"这结构一模一样啊,就多了 barrier 和线程参数"。
第三步,动手改 micro-ggml。 加一个新操作,比如 sigmoid。只需要改三处:枚举加一项、写一个 compute 函数、switch 加一个 case。理解一个系统最好的方式不是读它的源码,是在它的骨架版本上自己写。
12.3 系列后续预告
GGML 是底座,但 llama.cpp 是一个完整的推理系统。按源码的自然边界,这个系列还有六篇(争取哈) :
:
llama-model-loader.cppgguf.cpp | |||
llama-model.cppmodels/(130文件) | |||
llama-context.cppllama-graph.cpp + llama-kv-cache.cpp | |||
llama-vocab.cppllama-sampler.cpp | |||
ggml-quants.c | |||
ggml-backend.cpp |
看完第一篇,你已经懂了 GGML 的骨架。后续每一篇都是在这个骨架上叠加的生产级能力。读完整个系列,你就能自信地说:我理解 llama.cpp 是怎么工作的。
文章越来越长了...
