 夜雨聆风
夜雨聆风像ChatGPT这些千亿、万亿参数的前沿大模型,是靠几十万颗 GPU协同训练出来的。这些 GPU 分布在全球超算集群的数千台服务器里,每一秒都要交换 TB 级别的数据,而且必须完全同步锁步执行, 只要有一个 GPU 的数据传输慢了、丢了、堵了,全场所有 GPU 都得原地等待,海量算力直接白白浪费。
这就是 AI 训练最头疼的“尾延迟”问题。
更麻烦的是:
- 集群越大,网络拥塞和硬件故障就越频繁。
- 一个小故障就能让整个训练任务崩溃,浪费数小时甚至数天的算力。
所以,大模型训练需要一个既能跑得快、又极其抗造的网络协议。
OpenAI 联合 AMD、Broadcom、Intel、Microsoft、NVIDIA等科技巨头,专门为十万级 GPU 超算集群研发了新一代 RDMA 传输协议——MRC(多路径可靠连接)。目前 MRC 已经大规模部署在 OpenAI Stargate、微软 Fairwater 等顶级超算集群,用来训练 ChatGPT、Codex 等核心大模型,还通过开放计算项目(OCP)开源。(文末附MRC报告下载)

目前 AI 训练最常用的底层网络技术叫 RoCE。它的特点是:
- 每个数据传输(即一个 QP,队列对)固定走一条路径。
- 交换机会根据哈希算法,把不同流分到不同路径(这叫 ECMP)。
看上去挺合理,但实际运行中有几个致命伤:
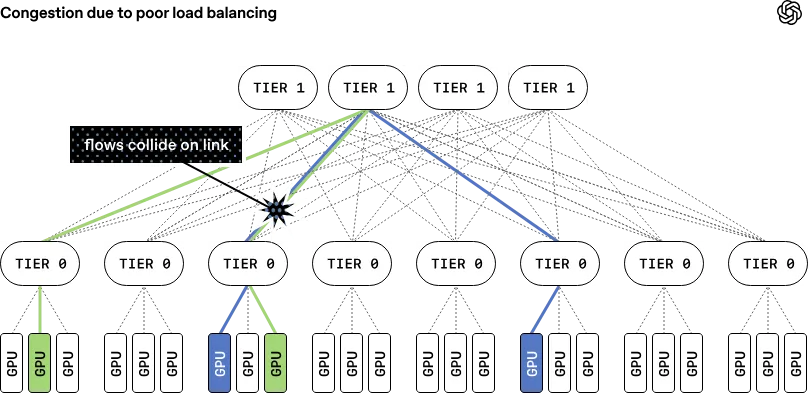
ECMP 的哈希并不完美。很容易出现两条大流被分到同一条链路,而旁边好几条链路空闲。这就像高速公路,两条大卡车队挤进同一车道,其他车道空荡荡。结果就是拥塞、丢包、变慢。
即使没有冲突,一条流也最多只用一条链路。如果你的网卡有 8 条 100Gb/s 的链路(总共 800Gb/s),但一个 QP 只能用其中一条,那其他 7 条就浪费了。
某条链路闪断一下(比如几毫秒),RoCE 就会大量丢包,训练任务直接崩溃。因为 RoCE 没有快速重传和多路径切换能力。
MRC 做的第一件事,就是彻底打破“一条流一条路”的束缚。
把同一个传输的数据包,打散成几百个小包,同时通过几百条不同的路径发送。
这就是包喷洒(Packet Spraying)。
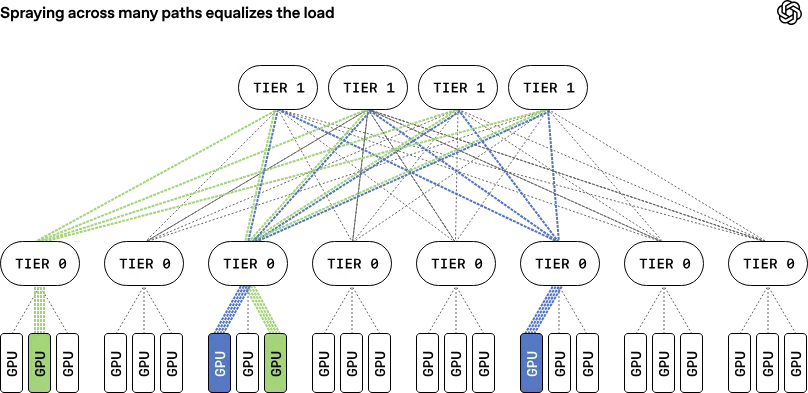
这样做的好处显而易见:
- 没有拥塞热点:每条路径都只承担很小一部分流量。
- 故障几乎无感:某条路径坏了,只是几百条中的一条,丢几个包重传即可,整体传输不受影响。
- 利用全部带宽:网卡的 8 个平面、每个平面里的几十条路径,全都能用上。
但是,包喷洒会带来一个新问题:数据包到达目的地是乱序的。传统协议必须按顺序接收,丢一个包,后面所有包都得等,造成队头阻塞;乱序就要等重传,性能暴跌。该怎么解决?
MRC 给每个数据包都加了RDMA 虚拟地址 + 远程密钥,接收方的网卡拿到包后,不管顺序,直接写入内存对应位置。硬件原生支持乱序写。这样,乱序不再是问题。
光有协议还不够,网络拓扑也要配合。MRC 没有在传统网络上凑活,而是重新设计了超算网络的硬件架构——多平面拓扑,也是 MRC 的物理基础。
- 传统单平面:一块 800Gb/s 的网卡当作一个整体,连到一台 T0 交换机。一台交换机只有几十个高速端口,所以需要三层甚至四层交换机才能连到几万块 GPU,成本高、延迟大、故障影响广。
- MRC 多平面:把 1 张 800G 网卡拆成 8 条 100G的独立链路(或者 4 条 200Gb/s),搭建8 套完全独立的 Clos 网络平面,2 层交换机就能连13.1 万 GPU。
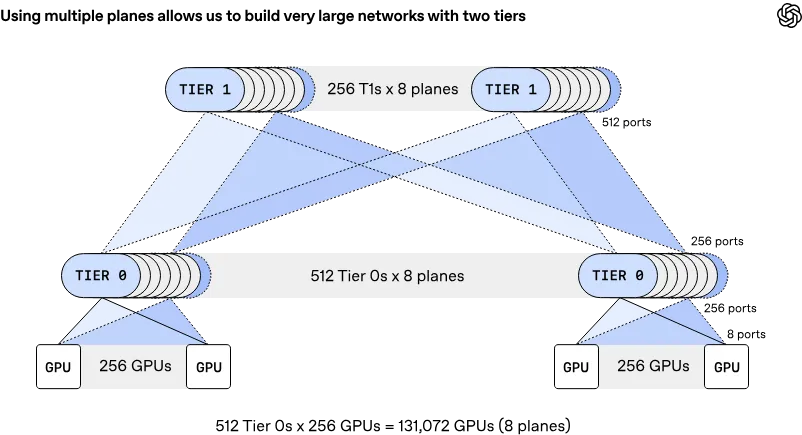
多平面拓扑的四大核心优势:
1. 极简架构,降本降耗
相比传统 3 层网络,多平面只用 2 层交换机,节省2/3 的光模块、3/5 的交换机,功耗和硬件成本直接砍半,还减少了大量故障点。
2. 延迟大幅降低
数据传输最长只经过 3 台交换机,传统网络要 5~7 台,端到端延迟直接减少 30% 以上。
3. 故障影响微乎其微
单条 T0-T1 链路故障,只损失 0.4% 带宽;网卡坏一个端口,只损失 12.5% 带宽,训练任务完全能扛住,不会崩。
4. 本地流量更高效
单跳就能连接 256 个节点,大量数据在底层交换机就近传输,不用往上绕,减轻上层交换机压力。
但问题来了:多平面有几百条路径,传统协议只能走单路径,根本用不上这么多冗余资源。MRC 的传输层设计,就是为了把多平面的潜力彻底榨干。
关键点:MRC 的包喷洒会均匀地覆盖所有平面。每个平面里的每条路径也会被均匀使用。这样,即使某个平面里部分链路坏了,MRC 也能自动避开,整体性能下降很少。
MRC 不是盲目乱喷,它给每个路径维护了一小段状态,用来判断这条路是否健康。
交换机会在拥塞时打 ECN 标记(显式拥塞通知)。接收方收到后,通过 SACK 包告诉发送方:“这条路有点堵”。发送方就暂时停用这个路径,换成备用路径。这样拥塞自然消失。
如果某个路径丢了包(没有收到确认),MRC 会立刻假定这条路已经坏了,直接从活跃集里移除它,不再使用。然后重传丢掉的包(通过其他路径)。整个过程在几十微秒内完成。
有一种丢包不是因为路径坏了,而是目标端口瞬间拥塞(很多流同时涌向同一个 GPU)。传统协议会丢包,引发重传,然后发送方误以为路径坏了。
MRC 做了个巧妙设计:当交换机因为输出端口拥塞要丢包时,它不丢弃整个包,而是切掉数据部分,只把包头(很小)优先发过去。接收方看到空头,就知道是拥塞丢包,不是路径坏,于是发出 NACK 要求重传。这样 MRC 不会错误地拉黑一条健康的路径。
被拉黑的路径是不是永远不用了?并不是。MRC 会定期发送轻量的探测包,看看这条路是否恢复正常。如果探测成功,自动重新启用,不会永久拉黑,保证路径利用率最大化。
这是 MRC 最激进、也最巧妙的设计。
传统网络里,交换机要跑 BGP、OSPF 等动态路由协议,实时计算网络拓扑,出现故障时自动绕路。但这样做有几个大问题:
- 收敛慢:要几秒甚至几十秒才能稳定,这期间大量丢包。
- 交换机软件复杂,容易有 bug。论文里提到,一个 18 万台交换机的数据中心,17% 的故障来自软件 bug。
- 控制平面和数据平面可能分裂:交换机觉得链路是好的,但实际上已经不会转发数据了(非常难诊断)。
MRC 的解决方案:彻底关掉所有动态路由,改用静态源路由(SRv6)。
1. 发送端定全路径
数据发送端直接在数据包的 IPv6 目的地址里,写死完整的传输路径,包含每一跳要经过的交换机微段 ID(uSID),路径完全由发送端决定,交换机无权修改。
2. 交换机只做无脑转发
交换机里存着静态转发表(出厂配置好,永远不改),收到数据包后,只做一件事:检查自己的 ID 是否匹配,匹配就左移 uSID,按静态表转发到下一跳,不用计算、不用更新、不用判断故障。
3. 路径与熵值(EV)绑定
每个 EV 对应一条唯一的 SRv6 路径,MRC 通过切换 EV,就能切换路径,故障了直接换 EV,交换机全程不用做任何操作。

1. 无动态路由 bug:彻底杜绝交换机软件故障、转发表异常等问题,稳定性拉满。
2. 零收敛延迟:故障不用等路由计算,MRC 微秒级绕开,训练无感知。
3. 运维极简:某个交换机坏了?MRC 把所有经过它的路径都拉黑,流量自然绕开。运维人员可以直接重启那个交换机,无需协调训练任务。
MRC 最厉害的地方,就是把网络故障变成透明事件,不管是链路闪断、端口故障、交换机重启,训练任务都能稳稳扛住,几乎不影响进度。
集群里每分钟都有链路闪断,MRC 的应对:
- 立刻停用对应路径的 EV,切换到备份路径;
- 选择性重传丢失的数据包;
- 全程耗时几十微秒,训练任务无任何 measurable 影响,甚至不用紧急维修故障链路。
网卡某个端口坏了,MRC 的应对:
- 网卡检测到端口失效,通过 SACK 报文的端口状态位图,通知所有对端 GPU;
- 全网所有 QP 立刻避开这个故障平面;
- 几秒内恢复稳定,仅损失少量带宽,训练任务不崩溃、不重启。
交换机需要重启维修,MRC 的应对:
- MRC 自动绕开所有经过该交换机的路径;
- 训练任务短暂小幅降速,交换机重启后,自动恢复路径;
- 不用人工协调、不用暂停训练,运维零负担。
MRC 配套了Clustermapper 探针系统:每个节点都装探针,毫秒级扫描所有链路,精准定位故障位置,生成路径黑名单,让 MRC 提前避开坏路径,比交换机 telemetry 更精准、更实时。
对比维度 | 传统 RoCE 协议 | MRC 协议 |
传输路径 | 单 QP 走单路径,易碰撞拥堵 | 单 QP 洒 256 条路径,无拥堵 |
故障处理 | 秒级路由收敛,易崩任务 | 微秒级绕障,任务无感 |
拥堵控制 | 靠 PFC,一堵全停,队头阻塞 | 靠修剪 + 重传,无全局阻塞 |
拓扑适配 | 小集群,3~4 层交换机 | 10 万 + GPU,2 层多平面 |
运维难度 | 复杂,需调 DCQCN,易出 bug | 极简,静态路由,小团队可管 |
带宽利用率 | 60%~70% | 96%,接近满速 |
把单路径变多路径喷洒:彻底消除拥塞热点,充分利用所有网络带宽。
极致的故障容忍:链路抖动、交换机故障、端口失效,几乎都不让训练崩溃。
静态源路由(SRv6):让交换机变“傻”,大幅降低控制平面复杂度和 bug 风险。
简化运维:绝大多数故障无需紧急处理,甚至可以边修边跑。
已大规模验证:部署在 OpenAI、微软的 10 万 GPU 级集群,训练真实的前沿模型。
从技术定位来看,它并非通用型网络协议,而是针对 AI 大模型训练的特性做深度定制的优化方案,以前一个网络故障就可能让上百万美元的算力瞬间浪费,现在 MRC 让训练任务可以“骑”在故障上继续前进。
公众号后台私信260508MRC即可获取下载链接!
【投稿】:SDNLAB原创文章奖励计划
