 夜雨聆风
夜雨聆风源码剖析
调度器
这一节算是来到了后端的处理流程,要先从调度器开始说起!
// 图分割结构体,表示计算图中的一个子图或分割,包含分割的后端 ID、输入张量列表和对应的计算图视图structggml_backend_sched_split {int backend_id; // 分割对应的后端 IDint i_start; // 分割的起始节点索引int i_end; // 分割的结束节点索引(不包含)structggml_tensor* inputs[GGML_SCHED_MAX_SPLIT_INPUTS]; // 分割输入张量列表int n_inputs; // 分割输入张量数量// graph view of this splitstructggml_cgraph graph; // 具有修改输入的图的副本,仅包含分割内的节点和叶子,输入张量被替换为分割输入张量};// GGML 后端调度器structggml_backend_sched {bool is_reset; // true if the scheduler has been reset since the last graph split // 是否自上次图分割以来重置了调度器bool is_alloc; // 是否已为当前图分配了张量int n_backends; // 后端数量ggml_backend_t backends[GGML_SCHED_MAX_BACKENDS]; // 后端列表ggml_backend_buffer_type_t bufts[GGML_SCHED_MAX_BACKENDS]; // 后端对应的缓冲区类型列表ggml_gallocr_t galloc; // 后端分配器// hash map of the nodes in the graphstructggml_hash_set hash_set; // 图中节点的哈希集合int * hv_tensor_backend_ids; // [hash_set.size] // 张量对应的后端 IDstructggml_tensor ** hv_tensor_copies; // [hash_set.size][n_backends][n_copies] // 张量副本int * node_backend_ids; // [graph_size] // 节点对应的后端 IDint * leaf_backend_ids; // [graph_size] // 叶子节点对应的后端 IDint* prev_node_backend_ids; // [graph_size] // 上一次图分割时节点对应的后端 ID,用于检测图分割引入的变化int* prev_leaf_backend_ids; // [graph_size] // 上一次图分割时叶子节点对应的后端 ID,用于检测图分割引入的变化// copy of the graph with modified inputsstructggml_cgraph graph; // 具有修改输入的图的副本// graph splitsstructggml_backend_sched_split* splits; // 图分割列表int n_splits; // 图分割数量int splits_capacity; // 图分割列表容量// pipeline parallelism supportint n_copies; // 每个张量的副本数量,包括原始张量和分配给不同后端的副本int cur_copy; // 当前副本索引int next_copy; // 下一个副本索引ggml_backend_event_t events[GGML_SCHED_MAX_BACKENDS][GGML_SCHED_MAX_COPIES];// 每个后端每个副本的事件列表,用于同步副本之间的操作structggml_tensor* graph_inputs[GGML_SCHED_MAX_SPLIT_INPUTS]; // 图输入列表,用于图分割时跟踪输入张量int n_graph_inputs; // 图输入数量structggml_context* ctx; // GGML 上下文 ggml_backend_sched_eval_callback callback_eval; // 评估回调函数,用于在图计算过程中评估节点void* callback_eval_user_data; // 评估回调函数的用户数据char* context_buffer; // 用于后端缓冲区的上下文数据,大小为 context_buffer_sizesize_t context_buffer_size; // 上下文缓冲区大小bool op_offload; // 是否启用操作卸载,优先在支持卸载的后端上运行操作,即使它们的权重在其他后端上int debug; // 调试标志,位掩码,允许启用不同级别的调试输出// used for debugging graph reallocations [GGML_SCHED_DEBUG_REALLOC]// ref: https://github.com/ggml-org/llama.cpp/pull/17617int debug_realloc; // 调试重新分配标志,位掩码,允许启用图重新分配的调试输出int debug_graph_size; // 调试图大小,当前图的节点数量,用于检测图重新分配引入的变化int debug_prev_graph_size; // 调试前一个图大小,上一轮图分割时的节点数量,用于检测图重新分配引入的变化};源码
参考上一节优化器代码的解析,在 ggml_opt_eval(...) 函数中调用了计算图的计算函数 ggml_backend_sched_graph_compute(...):
在 GGML 的后端调度里,可以把流程分成两层:
• 分割器(Splitter)层: ggml_backend_sched_split_graph(...)• 调度执行(Scheduler Runtime)层: ggml_backend_sched_compute_splits(...)
一句话:splitter 产计划,scheduler 按计划执行。
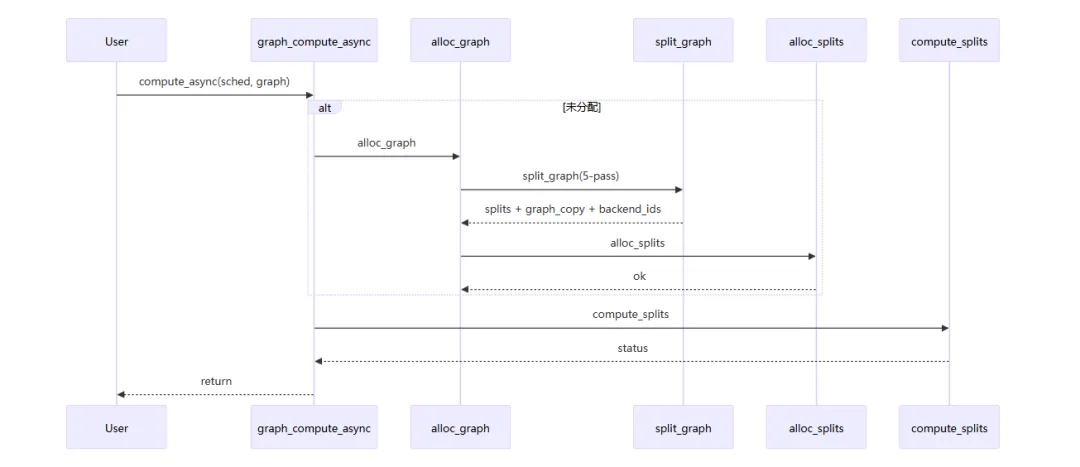
ggml-backend.cpp
// 计算图的计算,默认是同步的enum ggml_status ggml_backend_sched_graph_compute(ggml_backend_sched_t sched, struct ggml_cgraph * graph){enumggml_status err = ggml_backend_sched_graph_compute_async(sched, graph);ggml_backend_sched_synchronize(sched);return err;}// 计算图的计算,异步的,调用者需要在之后调用 ggml_backend_sched_synchronize 来确保计算完成enum ggml_status ggml_backend_sched_graph_compute_async(ggml_backend_sched_t sched, struct ggml_cgraph * graph){GGML_ASSERT(sched); // 断言 sched 不为 NULLif (!sched->is_reset && !sched->is_alloc) { // 如果 sched 没有被重置且没有被分配,则重置 schedggml_backend_sched_reset(sched); // 重置 sched }if (!sched->is_alloc) { // 如果 sched 没有被分配,则分配图if (!ggml_backend_sched_alloc_graph(sched, graph)) { // 如果分配图失败,则返回分配失败的状态return GGML_STATUS_ALLOC_FAILED; } }// 计算图的计算returnggml_backend_sched_compute_splits(sched);}// 分配计算图的资源,包括为每个节点分配后端和内存boolggml_backend_sched_alloc_graph(ggml_backend_sched_t sched, struct ggml_cgraph * graph){GGML_ASSERT(sched);GGML_ASSERT((int)sched->hash_set.size >= graph->n_nodes + graph->n_leafs);GGML_ASSERT(!sched->is_alloc); sched->cur_copy = sched->next_copy; sched->next_copy = (sched->next_copy + 1) % sched->n_copies;ggml_backend_sched_split_graph(sched, graph); // 根据当前的计算图分割信息,更新调度器中的节点和叶子后端 IDif (!ggml_backend_sched_alloc_splits(sched)) {returnfalse; } sched->is_alloc = true;returntrue;}...// assigns backends to ops and splits the graph into subgraphs that can be computed on the same backend// GGML 后端调度器的核心函数,根据当前的后端分配情况为计算图中的节点分配后端,并将图分割成可以在同一后端上计算的子图voidggml_backend_sched_split_graph(ggml_backend_sched_t sched, struct ggml_cgraph * graph){// reset splits sched->n_splits = 0; sched->n_graph_inputs = 0; sched->is_reset = false;// 初始化哈希集合和后端分配数组structggml_init_params params = {/* .mem_size = */ sched->context_buffer_size,/* .mem_buffer = */ sched->context_buffer,/* .no_alloc = */true };ggml_free(sched->ctx); // 释放之前的上下文,如果有的话 sched->ctx = ggml_init(params); // 创建新的上下文,用于图分割过程中分配临时张量if (sched->ctx == NULL) {GGML_ABORT("%s: failed to initialize context\n", __func__); }// pass 1: assign backends to ops with pre-allocated inputs// 第一步:为具有预分配输入的操作分配后端for (int i = 0; i < graph->n_leafs; i++) {// 叶子节点通常是输入张量或权重张量,优先根据它们的缓冲区类型分配后端structggml_tensor * leaf = graph->leafs[i];int * leaf_backend_id = &tensor_backend_id(leaf);// do not overwrite user assignmentsif (*leaf_backend_id == -1) { *leaf_backend_id = ggml_backend_sched_backend_id_from_cur(sched, leaf); } }// 根据非叶节点的输入为其分配后端for (int i = 0; i < graph->n_nodes; i++) {// 非叶节点通常是操作节点,根据其输入张量的后端分配后端,优先考虑权重张量的后端structggml_tensor * node = graph->nodes[i];int * node_backend_id = &tensor_backend_id(node);// do not overwrite user assignmentsif (*node_backend_id == -1) { *node_backend_id = ggml_backend_sched_backend_id_from_cur(sched, node);#if 0// srcif (node->op == GGML_OP_NONE) {continue; }for (int j = 0; j < GGML_MAX_SRC; j++) {structggml_tensor * src = node->src[j];if (src == NULL) {continue; }int * src_backend_id = &tensor_backend_id(src);if (*src_backend_id == -1) { *src_backend_id = ggml_backend_sched_backend_id_from_cur(sched, src); } }#endif } }// pass 2: expand current backend assignments// assign the same backend to adjacent nodes// expand gpu backends (i.e. non last prio) up and down, ignoring cpu (the lowest priority backend)// thus, cpu will never be used unless weights are on cpu, or there are no gpu ops between cpu ops// ops unsupported by the backend being expanded will be left unassigned so that they can be assigned later when the locations of its inputs are known// expand gpu down// 第二步:扩展当前的后端分配// 将相同的后端分配给相邻的节点,优先扩展 GPU 后端(即非最后优先级),忽略 CPU(最低优先级),因此除非权重在 CPU 上,或者在 CPU 操作之间没有 GPU 操作,否则 CPU 将永远不会被使用。后端不支持的操作将保持未分配,以便稍后在知道其输入位置时进行分配。首先向下扩展 GPU 后端 {// 向下扩展 GPU 后端:从图的开始到结束遍历节点,如果遇到一个已经分配了 GPU 后端的节点,就尝试将同一个后端分配给它的相邻节点,直到遇到一个不支持该后端的节点或者遇到 CPU 后端为止int cur_backend_id = -1;for (int i = 0; i < graph->n_nodes; i++) {structggml_tensor * node = graph->nodes[i];if (ggml_is_view_op(node->op)) { // 视图操作不参与后端分配的扩展,因为它们不涉及实际的计算,可以在任何后端上运行continue; }int* node_backend_id = &tensor_backend_id(node); // 获取当前节点的后端 ID,如果已经分配了后端,并且不是 CPU 后端,就将其作为当前后端 ID 进行扩展if (*node_backend_id != -1) {if (*node_backend_id == sched->n_backends - 1) {// skip cpu (lowest prio backend) cur_backend_id = -1; } else { cur_backend_id = *node_backend_id; } } elseif (cur_backend_id != -1) {// 如果当前节点没有分配后端,并且当前后端 ID 不为 -1(即正在扩展一个 GPU 后端),就尝试将当前后端分配给该节点,如果该节点支持当前后端的话ggml_backend_sched_set_if_supported(sched, node, cur_backend_id, node_backend_id); } } }// expand gpu up {// 向上扩展 GPU 后端:从图的结束到开始遍历节点,尝试将 GPU 后端分配给相邻的节点,直到遇到一个不支持该后端的节点或者遇到 CPU 后端为止int cur_backend_id = -1;for (int i = graph->n_nodes - 1; i >= 0; i--) {structggml_tensor * node = graph->nodes[i];if (ggml_is_view_op(node->op)) {continue; }int * node_backend_id = &tensor_backend_id(node);if (*node_backend_id != -1) {if (*node_backend_id == sched->n_backends - 1) {// skip cpu (lowest prio backend) cur_backend_id = -1; } else { cur_backend_id = *node_backend_id; } } elseif (cur_backend_id != -1) {ggml_backend_sched_set_if_supported(sched, node, cur_backend_id, node_backend_id); } } }// expand rest down {// 向下扩展剩余的后端:再次从图的开始到结束遍历节点,对于那些在第一次扩展中未被分配后端的节点,如果它们的相邻节点已经分配了后端,就尝试将同一个后端分配给它们,直到遇到一个不支持该后端的节点为止int cur_backend_id = -1;for (int i = 0; i < graph->n_nodes; i++) {structggml_tensor * node = graph->nodes[i];if (ggml_is_view_op(node->op)) {continue; }int * node_backend_id = &tensor_backend_id(node);if (*node_backend_id != -1) { cur_backend_id = *node_backend_id; } elseif (cur_backend_id != -1) {ggml_backend_sched_set_if_supported(sched, node, cur_backend_id, node_backend_id); } } }// expand rest up {// 向上扩展剩余的后端:再次从图的结束到开始遍历节点,对于那些在第一次扩展中未被分配后端的节点,如果它们的相邻节点已经分配了后端,就尝试将同一个后端分配给它们,直到遇到一个不支持该后端的节点为止int cur_backend_id = -1;for (int i = graph->n_nodes - 1; i >= 0; i--) {structggml_tensor * node = graph->nodes[i];if (ggml_is_view_op(node->op)) {continue; }int * node_backend_id = &tensor_backend_id(node);if (*node_backend_id != -1) { cur_backend_id = *node_backend_id; } elseif (cur_backend_id != -1) {ggml_backend_sched_set_if_supported(sched, node, cur_backend_id, node_backend_id); } } }// pass 3: upgrade nodes to higher prio backends with compatible buffer types// if the tensor is already in the same buffer type (*) as another higher priority backend, we should move it there// however, we also need to verify that the sources are in compatible buffer types// (*) the actual requirement is more relaxed, the buffer type of the backend should be supported by all the users of this tensor further down the graph// however, this is slow to verify, so we have a more strict requirement that the buffer type is the same// this is not uncommon since multiple backends can use host memory, with the same buffer type (eg. BLAS and CPU)// additionally, set remaining unassigned nodes to the backend with the most supported inputs// only nodes that could not be assigned during expansion due to the backend not supporting the op should be unassigned at this point// 第三步:将节点升级到具有兼容缓冲区类型的更高优先级后端// 如果张量已经在与另一个更高优先级后端相同的缓冲区类型中,我们应该将它移动到那里。然而,我们还需要验证源张量是否在兼容的缓冲区类型中。// 实际要求更宽松,后端的缓冲区类型应该被该张量在图中进一步下游的所有用户支持,但验证这一点很慢,因此我们有一个更严格的要求,即缓冲区类型必须相同。// 这并不罕见,因为多个后端可以使用主机内存,具有相同的缓冲区类型(例如 BLAS 和 CPU)。// 此外,将剩余未分配的节点设置为具有最多支持输入的后端。// 只有那些由于后端不支持操作而无法在扩展期间分配的节点此时才应该未分配。for (int i = 0; i < graph->n_nodes; i++) {// 遍历图中的每个节点,如果节点已经分配了后端,并且该后端具有与当前节点相同缓冲区类型的更高优先级后端,并且当前节点支持该更高优先级后端,那么将当前节点升级到该更高优先级后端。// 对于那些仍然未分配后端的节点,找到具有最多支持输入的后端并分配给它们。structggml_tensor * node = graph->nodes[i];if (ggml_is_view_op(node->op)) {continue; }int * node_backend_id = &tensor_backend_id(node);if (*node_backend_id == -1) {// unassigned node: find the backend with the most supported inputsint n_supported_best = -1;for (int b = 0; b < sched->n_backends; b++) {if (ggml_backend_supports_op(sched->backends[b], node)) {int n_supported = 0;for (int j = 0; j < GGML_MAX_SRC; j++) {structggml_tensor * src = node->src[j];if (src == NULL) {continue; }if ((tensor_backend_id(src) != -1 || tensor_backend_id(src->view_src) != -1) && ggml_backend_sched_buffer_supported(sched, src, b)) { n_supported++; } }if (n_supported > n_supported_best) { n_supported_best = n_supported; *node_backend_id = b;SET_CAUSE(node, "3.best"); } } } } else {// assigned node: upgrade to higher prio backend if possible// 如果当前节点已经分配了后端,那么检查是否有更高优先级的后端具有与当前节点相同缓冲区类型,并且当前节点支持该更高优先级后端,如果是这样的话,就将当前节点升级到该更高优先级后端。for (int b = 0; b < *node_backend_id; b++) {if (sched->bufts[b] == sched->bufts[*node_backend_id] && ggml_backend_supports_op(sched->backends[b], node)) {bool supported = true;for (int j = 0; j < GGML_MAX_SRC; j++) {structggml_tensor * src = node->src[j];if (src == NULL) {continue; }if (!ggml_backend_sched_buffer_supported(sched, src, b)) { supported = false;break; } }if (supported) { *node_backend_id = b;SET_CAUSE(node, "3.upg");break; } } } } }// pass 4: assign backends to remaining src from dst and view_src// 第四步:根据目标节点和视图源节点为剩余的源节点分配后端for (int i = 0; i < graph->n_nodes; i++) {structggml_tensor * node = graph->nodes[i];int * cur_backend_id = &tensor_backend_id(node);if (node->view_src != NULL && *cur_backend_id == -1) { *cur_backend_id = tensor_backend_id(node->view_src);SET_CAUSE(node, "4.vsrc"); }for (int j = 0; j < GGML_MAX_SRC; j++) {structggml_tensor * src = node->src[j];if (src == NULL) {continue; }int * src_backend_id = &tensor_backend_id(src);if (*src_backend_id == -1) {if (src->view_src != NULL) {// views are always on the same backend as the source *src_backend_id = tensor_backend_id(src->view_src);SET_CAUSE(src, "4.vsrc"); } else { *src_backend_id = *cur_backend_id;SET_CAUSE(src, "4.cur"); } } }// if the node is still unassigned, assign it to the first backend that supports it// 如果当前节点仍然未分配后端,那么将其分配给第一个支持它的后端for (int b = 0; b < sched->n_backends && *cur_backend_id == -1; b++) {ggml_backend_sched_set_if_supported(sched, node, b, cur_backend_id); }GGML_ASSERT(*cur_backend_id != -1); }// pass 5: split graph, find tensors that need to be copied// 第五步:分割图,找到需要复制的张量 {int i_split = 0;structggml_backend_sched_split * split = &sched->splits[0];// find the backend of the first split, skipping view ops// 找到第一个分割的后端,跳过视图操作,因为它们不涉及实际的计算,可以在任何后端上运行int i = 0;for (; i < graph->n_nodes; i++) {structggml_tensor * node = graph->nodes[i];if (!ggml_is_view_op(node->op)) { split->backend_id = tensor_backend_id(node);break; } } split->i_start = 0; split->n_inputs = 0;int cur_backend_id = split->backend_id;for (; i < graph->n_nodes; i++) {// 遍历图中的每个节点,如果遇到一个节点的后端与当前分割的后端不同,或者该节点的输入需要在不同且不兼容的后端之间复制,那么就结束当前分割并开始一个新的分割。// 对于每个节点,检查它的输入张量是否在同一后端上,如果不是,并且当前分割的后端不支持跨后端复制,那么就需要开始一个新的分割,以便在新的分割中处理这些输入张量。structggml_tensor * node = graph->nodes[i];if (ggml_is_view_op(node->op)) {continue; }constint node_backend_id = tensor_backend_id(node);GGML_ASSERT(node_backend_id != -1); // all nodes should be assigned by now, this can happen if there is no CPU fallback// check if we should start a new split based on the sources of the current node// 如果当前节点的后端与当前分割的后端不同,或者当前节点的输入张量需要在不同且不兼容的后端之间复制,那么就需要开始一个新的分割。bool need_new_split = false;if (node_backend_id == cur_backend_id && split->n_inputs > 0) {for (int j = 0; j < GGML_MAX_SRC; j++) {structggml_tensor * src = node->src[j];if (src == NULL) {continue; }// check if a weight is on a different and incompatible backend// by starting a new split, the memory of the previously offloaded weights can be reused// 校验如果权重在不同且不兼容的后端上,通过开始一个新的分割,可以重用之前卸载的权重的内存// 这里的逻辑是,如果当前节点的后端与当前分割的后端相同,并且当前分割已经有输入了,那么就检查当前节点的输入张量,如果有输入张量在不同且不兼容的后端上,那么就需要开始一个新的分割,以便在新的分割中处理这些输入张量。if (src->buffer != NULL && src->buffer->usage == GGML_BACKEND_BUFFER_USAGE_WEIGHTS) {int src_backend_id = tensor_backend_id(src);if (src_backend_id != cur_backend_id && !ggml_backend_sched_buffer_supported(sched, src, cur_backend_id)) { need_new_split = true;break; } }// check if the split has too many inputs// FIXME: count the number of inputs instead of only checking when full// 检查分割是否有太多输入,当前的实现是当输入数量达到最大值时才检查,这可能会导致在达到最大输入数量之前就开始一个新的分割。// 理想情况下,应该在每次添加输入时都检查输入数量,以便更早地开始新的分割,从而更好地利用分割的能力。if (split->n_inputs == GGML_SCHED_MAX_SPLIT_INPUTS) {constsize_t id = hash_id(src);int src_backend_id = sched->hv_tensor_backend_ids[id];bool supported = ggml_backend_sched_buffer_supported(sched, src, cur_backend_id);if (src_backend_id != cur_backend_id && tensor_id_copy(id, cur_backend_id, 0) == NULL && !supported) { need_new_split = true;break; } } } }// 如果当前节点的后端与当前分割的后端不同,或者当前节点的输入张量需要在不同且不兼容的后端之间复制,那么就结束当前分割并开始一个新的分割。if (node_backend_id != cur_backend_id || need_new_split) { split->i_end = i; i_split++;if (i_split >= sched->splits_capacity) { sched->splits_capacity *= 2; sched->splits = (ggml_backend_sched_split *)realloc(sched->splits, sched->splits_capacity * sizeof(struct ggml_backend_sched_split));GGML_ASSERT(sched->splits != NULL); } split = &sched->splits[i_split]; split->backend_id = node_backend_id; split->i_start = i; split->n_inputs = 0; cur_backend_id = node_backend_id; }// find inputs that are not on the same backend// 对于当前节点的每个输入张量,如果输入张量的后端与当前分割的后端不同,并且当前分割的后端不支持跨后端复制,那么就需要在当前分割中添加该输入张量,以便在当前分割中处理该输入张量。for (int j = 0; j < GGML_MAX_SRC; j++) {structggml_tensor * src = node->src[j];if (src == NULL) {continue; }size_t src_id = hash_id(src);constint src_backend_id = sched->hv_tensor_backend_ids[src_id];GGML_ASSERT(src_backend_id != -1); // all inputs should be assigned by now// 如果输入张量的后端与当前分割的后端不同,并且当前分割的后端不支持跨后端复制,那么就需要在当前分割中添加该输入张量,以便在当前分割中处理该输入张量。if (src->flags & GGML_TENSOR_FLAG_INPUT && sched->n_copies > 1) {// 如果输入张量是图的输入,并且分割器配置为允许多个副本,那么就需要为该输入张量创建一个副本,以便在当前分割中处理该输入张量。if (tensor_id_copy(src_id, src_backend_id, 0) == NULL) {ggml_backend_t backend = sched->backends[src_backend_id];for (int c = 0; c < sched->n_copies; c++) {structggml_tensor * tensor_copy;if (c == sched->cur_copy) { tensor_copy = src; // use the original tensor as the current copy } else { tensor_copy = ggml_dup_tensor_layout(sched->ctx, src);ggml_format_name(tensor_copy, "%s#%s#%d", ggml_backend_name(backend), src->name, c); }ggml_set_input(tensor_copy);ggml_set_output(tensor_copy); // prevent ggml-alloc from overwriting the tensortensor_id_copy(src_id, src_backend_id, c) = tensor_copy;SET_CAUSE(tensor_copy, "4.cpy"); }int n_graph_inputs = sched->n_graph_inputs++;GGML_ASSERT(n_graph_inputs < GGML_SCHED_MAX_SPLIT_INPUTS); sched->graph_inputs[n_graph_inputs] = src; } }// 如果输入张量的后端与当前分割的后端不同,并且当前分割的后端不支持跨后端复制,那么就需要在当前分割中添加该输入张量,以便在当前分割中处理该输入张量。if (src_backend_id != cur_backend_id && !ggml_backend_sched_buffer_supported(sched, src, cur_backend_id)) {// create a copy of the input in the split's backendif (tensor_id_copy(src_id, cur_backend_id, 0) == NULL) {ggml_backend_t backend = sched->backends[cur_backend_id];for (int c = 0; c < sched->n_copies; c++) {structggml_tensor * tensor_copy = ggml_dup_tensor_layout(sched->ctx, src);ggml_format_name(tensor_copy, "%s#%s#%d", ggml_backend_name(backend), src->name, c);if (sched->n_copies > 1) {ggml_set_input(tensor_copy);ggml_set_output(tensor_copy); // prevent ggml-alloc from overwriting the tensor }tensor_id_copy(src_id, cur_backend_id, c) = tensor_copy;SET_CAUSE(tensor_copy, "4.cpy"); }int n_inputs = split->n_inputs++;GGML_ASSERT(n_inputs < GGML_SCHED_MAX_SPLIT_INPUTS); split->inputs[n_inputs] = src; } node->src[j] = tensor_id_copy(src_id, cur_backend_id, sched->cur_copy); } } } split->i_end = graph->n_nodes; sched->n_splits = i_split + 1; }if (sched->debug) {ggml_backend_sched_print_assignments(sched, graph); }// swap node_backend_ids and leaf _backend_ids with prevs// 在分割图之前,调度器使用 node_backend_ids 和 leaf_backend_ids 数组来跟踪每个节点和叶子节点的后端分配情况。// 在分割图之后,这些数组已经被更新为新的分配情况,因此需要将它们与 prev_node_backend_ids 和 prev_leaf_backend_ids 交换,以便在下一次分割图时使用新的分配情况进行比较和优化。 {int * tmp = sched->node_backend_ids; sched->node_backend_ids = sched->prev_node_backend_ids; sched->prev_node_backend_ids = tmp; tmp = sched->leaf_backend_ids; sched->leaf_backend_ids = sched->prev_leaf_backend_ids; sched->prev_leaf_backend_ids = tmp; }// 创建分割后的图的副本,并将输入张量添加到分割后的图中,以便在分割后的图中进行计算。// 分割后的图将包含原始图中的节点和叶子节点,以及为处理跨后端输入张量而创建的副本节点。int graph_size = std::max(graph->n_nodes, graph->n_leafs) + sched->n_splits*GGML_SCHED_MAX_SPLIT_INPUTS*2*sched->n_copies;// remember the actual graph_size for performing reallocation checks later [GGML_SCHED_DEBUG_REALLOC] sched->debug_prev_graph_size = sched->debug_graph_size; sched->debug_graph_size = graph_size;if (sched->graph.size < graph_size) { sched->graph.size = graph_size; sched->graph.nodes = (ggml_tensor **) realloc(sched->graph.nodes, graph_size * sizeof(struct ggml_tensor *)); sched->graph.leafs = (ggml_tensor **) realloc(sched->graph.leafs, graph_size * sizeof(struct ggml_tensor *));GGML_ASSERT(sched->graph.nodes != NULL);GGML_ASSERT(sched->graph.leafs != NULL); } sched->graph.n_nodes = 0; sched->graph.n_leafs = 0;// 分割后的图的副本,用于在分割后的图中进行计算。分割后的图将包含原始图中的节点和叶子节点,以及为处理跨后端输入张量而创建的副本节点。structggml_cgraph* graph_copy = &sched->graph;// 循环遍历每个分割,将原始图中的节点添加到分割后的图中,并为每个分割创建一个视图,以便在分割后的图中进行计算。// 对于每个分割,还需要将输入张量添加到分割后的图中,以便在分割后的图中进行计算。for (int i = 0; i < sched->n_splits; i++) {structggml_backend_sched_split * split = &sched->splits[i]; split->graph = ggml_graph_view(graph, split->i_start, split->i_end);// Optimize this split of the graph. This needs to happen before we make graph_copy,// so they are in sync.// 优化图的这个分割。这需要在我们制作 graph_copy 之前发生,以便它们保持同步。ggml_backend_graph_optimize(sched->backends[split->backend_id], &split->graph);// add inputs to the graph copy so that they are allocated by ggml-alloc at the start of the split// 对于每个分割,将输入张量添加到分割后的图中,以便在分割后的图中进行计算。对于每个输入张量,还需要创建一个副本,以便在分割后的图中进行计算。for (int j = 0; j < split->n_inputs; j++) {assert(graph_copy->size > (graph_copy->n_nodes + 1));structggml_tensor * input = split->inputs[j];constsize_t input_id = hash_id(input);structggml_tensor * input_cpy = tensor_id_copy(input_id, split->backend_id, sched->cur_copy);// add a dependency to the input source so that it is not freed before the copy is done// 将依赖关系添加到输入源,以便在复制完成之前不会被释放structggml_tensor * input_dep = ggml_view_tensor(sched->ctx, input); input_dep->src[0] = input; sched->node_backend_ids[graph_copy->n_nodes] = sched->hv_tensor_backend_ids[input_id]; graph_copy->nodes[graph_copy->n_nodes++] = input_dep;// add a dependency to the input copy so that it is allocated at the start of the split// 将依赖关系添加到输入副本,以便在分割开始时分配它 sched->node_backend_ids[graph_copy->n_nodes] = split->backend_id; graph_copy->nodes[graph_copy->n_nodes++] = input_cpy; }for (int j = split->i_start; j < split->i_end; j++) {assert(graph_copy->size > graph_copy->n_nodes); sched->node_backend_ids[graph_copy->n_nodes] = tensor_backend_id(graph->nodes[j]); graph_copy->nodes[graph_copy->n_nodes++] = graph->nodes[j]; } }// 如果调度器配置为允许多个副本,那么还需要将图的输入张量添加到分割后的图中,以便在分割后的图中进行计算。// 对于每个输入张量,还需要创建一个副本,以便在分割后的图中进行计算。if (sched->n_copies > 1) {// add input copies as leafs so that they are allocated first// 将输入副本作为叶子节点添加,以便它们首先被分配for (int i = 0; i < sched->n_graph_inputs; i++) {structggml_tensor * input = sched->graph_inputs[i];size_t id = hash_id(input);int backend_id = tensor_backend_id(input);for (int c = 0; c < sched->n_copies; c++) {structggml_tensor * input_cpy = tensor_id_copy(id, backend_id, c); sched->leaf_backend_ids[graph_copy->n_leafs] = backend_id;assert(graph_copy->size > graph_copy->n_leafs); graph_copy->leafs[graph_copy->n_leafs++] = input_cpy; } }// 添加分割输入的副本作为叶子节点,以便它们首先被分配for (int i = 0; i < sched->n_splits; i++) {structggml_backend_sched_split * split = &sched->splits[i];int backend_id = split->backend_id;for (int j = 0; j < split->n_inputs; j++) {structggml_tensor * input = split->inputs[j];size_t id = hash_id(input);for (int c = 0; c < sched->n_copies; c++) {structggml_tensor * input_cpy = tensor_id_copy(id, backend_id, c); sched->leaf_backend_ids[graph_copy->n_leafs] = backend_id;assert(graph_copy->size > graph_copy->n_leafs); graph_copy->leafs[graph_copy->n_leafs++] = input_cpy; } } } }// add leafs from the original graph// 添加原始图中的叶子节点到分割后的图中,以便在分割后的图中进行计算。for (int i = 0; i < graph->n_leafs; i++) {structggml_tensor * leaf = graph->leafs[i]; sched->leaf_backend_ids[graph_copy->n_leafs] = tensor_backend_id(leaf);assert(graph_copy->size > graph_copy->n_leafs); graph_copy->leafs[graph_copy->n_leafs++] = leaf; }}...// GGML 后端调度器的核心函数之一,用于计算图的分割和输入张量的复制,以便在不同的后端上执行图的不同部分。// 该函数首先检查调度器中的分割信息,然后遍历每个分割,处理每个分割的输入张量。// 如果输入张量来自用户,则立即复制到分割的后端,以防止用户在复制完成之前覆盖数据。// 如果输入张量不是来自用户,则等待分割的后端完成对输入张量的使用,然后再进行复制。// 在处理 MoE 权重时,可以通过仅复制使用的专家来减少复制的数据量。staticenum ggml_status ggml_backend_sched_compute_splits(ggml_backend_sched_t sched){GGML_ASSERT(sched); // 断言调度器 sched 不为 NULLstructggml_backend_sched_split* splits = sched->splits; // 获取调度器中的分割信息 ggml_tensor* prev_ids_tensor = nullptr; // 用于跟踪前一个 ID 张量的指针,初始值为 nullptr std::vector<int32_t> ids; // 用于存储 ID 的向量 std::vector<ggml_bitset_t> used_ids; // 用于存储已使用 ID 的位集合向量// 遍历所有分割,处理每个分割的输入张量for (int split_id = 0; split_id < sched->n_splits; split_id++) {structggml_backend_sched_split* split = &splits[split_id]; // 获取当前分割的信息int split_backend_id = split->backend_id; // 获取当前分割的后端 IDggml_backend_t split_backend = sched->backends[split_backend_id]; // 获取当前分割的后端对象// copy the input tensors to the split backend// 拷贝输入张量到分割的后端for (int input_id = 0; input_id < split->n_inputs; input_id++) {// 获取输入张量的后端 ID 和张量对象ggml_backend_t input_backend = ggml_backend_sched_get_tensor_backend(sched, split->inputs[input_id]);structggml_tensor* input = split->inputs[input_id]; // 获取当前输入张量structggml_tensor* input_cpy = tensor_copy(input, split_backend_id, sched->cur_copy); // 获取当前输入张量在分割后端的副本// 如果输入张量来自用户,则立即复制到分割的后端,以防止用户在复制完成之前覆盖数据if (input->flags & GGML_TENSOR_FLAG_INPUT) { // inputs from the user must be copied immediately to prevent the user overwriting the data before the copy is done// 输入来自用户,必须立即复制到分割的后端,以防止用户在复制完成之前覆盖数据if (sched->events[split_backend_id][sched->cur_copy] != NULL) {ggml_backend_event_synchronize(sched->events[split_backend_id][sched->cur_copy]); // 同步等待分割后端的事件完成 } else {ggml_backend_synchronize(split_backend); // 同步等待分割后端完成当前操作 }ggml_backend_tensor_copy(input, input_cpy); // 复制输入张量到分割的后端 }else { // 如果输入张量不是来自用户,则等待分割的后端完成对输入张量的使用,然后再进行复制// wait for the split backend to finish using the input before overwriting it// 等待分割的后端完成对输入张量的使用,然后再进行复制if (sched->events[split_backend_id][sched->cur_copy] != NULL) {ggml_backend_event_wait(split_backend, sched->events[split_backend_id][sched->cur_copy]); } else {ggml_backend_synchronize(split_backend); }// when offloading MoE weights, we can reduce the amount of data copied by copying only the experts that are used// 当卸载 MoE 权重时,我们可以通过仅复制使用的专家来减少复制的数据量 ggml_tensor* node = split->graph.nodes[0]; // 获取当前分割的第一个节点// 检查当前分割的图是否包含节点,并且输入张量是否是权重,并且输入张量是否在主机内存中,以及当前节点是否是矩阵乘法或加法操作,并且输入张量是当前节点的第一个或第二个源张量if (split->graph.n_nodes > 0 &&ggml_backend_buffer_get_usage(input->buffer) == GGML_BACKEND_BUFFER_USAGE_WEIGHTS &&ggml_backend_buffer_is_host(input->buffer) && ( (node->src[0] == input_cpy && node->op == GGML_OP_MUL_MAT_ID)//|| (node->src[1] == input_cpy && node->op == GGML_OP_ADD_ID) /* GGML_OP_ADD_ID weights are small and not worth splitting */ )) {constint64_t n_expert = node->op == GGML_OP_MUL_MAT_ID ? input->ne[2] : input->ne[1]; // 获取专家数量constsize_t expert_size = node->op == GGML_OP_MUL_MAT_ID ? input->nb[2] : input->nb[1]; // 获取每个专家的大小ggml_backend_synchronize(input_backend); // 同步等待输入张量所在的后端完成当前操作// get the ids ggml_tensor* ids_tensor = node->src[2]; // 获取 ID 张量,假设 ID 张量是当前节点的第三个源张量ggml_backend_t ids_backend = split_backend; // 默认情况下,ID 张量在分割的后端// if the ids tensor is also an input of the split, it may not have been copied yet to the split backend// in that case, we use the original ids tensor// 如果 ID 张量也是分割的输入,它可能尚未被复制到分割的后端// 在这种情况下,我们使用原始的 ID 张量for (int i = input_id + 1; i < split->n_inputs; i++) {if (ids_tensor == tensor_copy(split->inputs[i], split_backend_id, sched->cur_copy)) { ids_tensor = split->inputs[i]; ids_backend = ggml_backend_sched_get_tensor_backend(sched, split->inputs[i]);break; } }// 如果 ID 张量发生变化,我们需要从新的 ID 张量中获取数据,并找到使用的专家if (ids_tensor != prev_ids_tensor) { ids.resize(ggml_nbytes(ids_tensor) / sizeof(int32_t)); // 调整 ID 向量的大小以适应 ID 张量的字节大小// 尝试异步获取 ID 张量的数据,如果不支持异步获取,则同步等待分割后端完成当前操作,然后再获取数据ggml_backend_tensor_get_async(ids_backend, ids_tensor, ids.data(), 0, ggml_nbytes(ids_tensor));ggml_backend_synchronize(ids_backend); // 同步等待 ID 张量所在的后端完成当前操作// find the used experts// 找到使用的专家 used_ids.clear(); used_ids.resize(ggml_bitset_size(n_expert)); // 调整已使用 ID 的位集合的大小以适应专家数量// 遍历 ID 张量的所有元素,标记使用的专家 IDfor (int64_t i1 = 0; i1 < ids_tensor->ne[1]; i1++) {for (int64_t i0 = 0; i0 < ids_tensor->ne[0]; i0++) {int32_t id = ids[i1 * ids_tensor->nb[1]/sizeof(int32_t) + i0 * ids_tensor->nb[0]/sizeof(int32_t)];GGML_ASSERT(id >= 0 && id < n_expert);ggml_bitset_set(used_ids.data(), id); } } prev_ids_tensor = ids_tensor; }// group consecutive experts and copy them together// 将连续的专家分组并一起复制auto copy_experts = [&](int32_t first_id, int32_t last_id) {constsize_t expert_offset = first_id * expert_size;constsize_t expert_size_copy = (last_id - first_id + 1) * expert_size;constsize_t padding = std::min<size_t>(expert_size, 512);constsize_t padding_end = last_id < n_expert - 1 ? padding : 0;// 尝试异步复制专家数据,如果不支持异步复制,则同步等待输入张量所在的后端和分割后端完成当前操作,然后再进行复制ggml_backend_tensor_set_async(split_backend, input_cpy, (constuint8_t *)input->data + expert_offset, expert_offset,// copy a bit extra at the to ensure there are no NaNs in the padding of the last expert// this is necessary for MMQ in the CUDA backend expert_size_copy + padding_end); };// 遍历所有专家 ID,找到连续的使用的专家,并一起复制它们的数据int id = 0;while (!ggml_bitset_get(used_ids.data(), id)) { id++; }int32_t first_id = id;int32_t last_id = first_id;for (++id; id < n_expert; ++id) {if (!ggml_bitset_get(used_ids.data(), id)) {continue; }if (id == last_id + 1) { last_id = id;continue; }copy_experts(first_id, last_id); first_id = id; last_id = id; }copy_experts(first_id, last_id); } else {// try async copy, but if not possible, we can still use a sync copy without synchronizing the dst backend, since we handle the synchronization here with multiple copies and events// TODO: add public function to facilitate this, since applications do not have direct access to the backend interface// 尝试异步复制,但如果不可能,我们仍然可以使用同步复制而不需要同步目标后端,因为我们在这里通过多个副本和事件来处理同步if (!split_backend->iface.cpy_tensor_async || !split_backend->iface.cpy_tensor_async(input_backend, split_backend, input, input_cpy)) {ggml_backend_synchronize(input_backend);if (sched->events[split_backend_id][sched->cur_copy] != NULL) {ggml_backend_event_synchronize(sched->events[split_backend_id][sched->cur_copy]); } else {ggml_backend_synchronize(split_backend); }ggml_backend_tensor_copy(input, input_cpy); } } } }// 如果调度器没有提供回调函数来评估图的节点,我们可以直接异步计算整个分割的图;// 否则,我们需要逐个节点地计算,并在每个节点之后调用回调函数来检查用户是否需要该节点的数据if (!sched->callback_eval) {enumggml_status ec = ggml_backend_graph_compute_async(split_backend, &split->graph); // 直接异步计算整个分割的图if (ec != GGML_STATUS_SUCCESS) {return ec; } } else {// similar to ggml_backend_compare_graph_backend// 循环遍历分割的图的所有节点,逐个节点地计算,并在每个节点之后调用回调函数来检查用户是否需要该节点的数据for (int j0 = 0; j0 < split->graph.n_nodes; j0++) {struct ggml_tensor * t = split->graph.nodes[j0];// check if the user needs data from this nodebool need = sched->callback_eval(t, true, sched->callback_eval_user_data);int j1 = j0;// determine the range [j0, j1] of nodes that can be computed togetherwhile (!need && j1 < split->graph.n_nodes - 1) { t = split->graph.nodes[++j1]; need = sched->callback_eval(t, true, sched->callback_eval_user_data); }// 计算范围 [j0, j1] 的节点structggml_cgraph gv = ggml_graph_view(&split->graph, j0, j1 + 1);enumggml_status ec = ggml_backend_graph_compute_async(split_backend, &gv);if (ec != GGML_STATUS_SUCCESS) {return ec; }// TODO: pass backend to the callback, then the user can decide if they want to synchronizeggml_backend_synchronize(split_backend); // 同步等待分割后端完成当前操作if (need && !sched->callback_eval(t, false, sched->callback_eval_user_data)) {break; } j0 = j1; } }// record the event of this copy// 记录此复制的事件if (split->n_inputs > 0) {if (sched->events[split_backend_id][sched->cur_copy] != NULL) {ggml_backend_event_record(sched->events[split_backend_id][sched->cur_copy], split_backend); } } }return GGML_STATUS_SUCCESS;}这一部分的代码还是有一些不好理解的,需要多读几遍进行理解消化,这里我将其进行职责划分为:分割器和调度器。
Splitter:分割器
根据注释 ggml_backend_sched_split_graph(...) 函数被分为 5个Pass ,其核心是一个“编排算法”!
这里先解读一下这五个 Pass ,然后我在举一个分割示例,就应该明白该函数的用意了:
• Pass 1:初始 backend 分配 • 先遍历 leafs,按已有 buffer / 用户指定 / 当前信息推导 backend。• 再遍历 nodes做初始 backend 归属。• 已有用户显式赋值不会被覆盖。 • Pass 2:邻接扩展进行 4 轮处理:GPU down(前向)、GPU up(反向)、rest down(前向)、rest up(反向)思想:让相邻可支持节点尽量落在同 backend,降低切分和拷贝开销。 • Pass 3:升级 + 补全 • 未分配节点:选择“支持输入最多”的 backend。 • 已分配节点:尝试升级到更高优先级 backend(需 op 支持 + buffer 兼容)。 • Pass 4:补齐 src/view_src 归属 • view张量跟随view_srcbackend。• 未分配 src继承当前节点或其view_src。• 最终保证每个 node 都有 backend。 • Pass 5:真正切 split + 标记 copy 输入 • 扫描节点,backend 变化或触发 need_new_split时开新 split。• 对跨 backend 且 buffer 不兼容的 src:创建目标 backend 的tensor_copy,记录到split->inputs[],把node->src[j]改指向 copy(当前 copy 槽位)
最后构建 sched->graph(graph_copy)。
接下来我用示例说明一下:
可以把一张计算图想成一条流水线,节点顺序大致是:A -> B -> C -> D -> E -> F
假设 backend 分配结果是:
• A B C在 CUDA• D只能在 CPU• E F又可以回到 CUDA
那么 split 通常会变成:
• split0(CUDA): A B C• split1(CPU): D• split2(CUDA): E F
也就是说,同一 backend 且可连续执行的一段节点,会被合并成一个 split;一旦 backend 改变,或者出现“输入太多/权重不兼容需要提前切开”等条件,就会开新 split。

Scheduler:调度器
这里详细讲解ggml_backend_sched_compute_splits(...)函数:
• 入口与缓存变量:用于 MoE 优化:如果多个输入共享同一 ids tensor,就复用“哪些 expert 被使用”的计算结果,避免重复扫描。• 外层循环:逐 split 执行,每个 split 都有固定执行 backend: split_backend = sched->backends[split->backend_id]。• 输入拷贝逻辑:找到源 backend(输入当前所在)与目标 backend(split backend),取目标副本 input_cpy,分两类处理:• 用户输入( GGML_TENSOR_FLAG_INPUT):立即拷贝。• 非用户输入:先确保目标 backend 不再使用旧 copy,再写入新数据。 • MoE 优化路径:是 compute_splits里最关键的“MoE 只拷贝命中专家”优化。• 普通路径:异步拷贝优先,失败再同步拷贝,设计目标是:尽量异步,失败也保证正确性。 • split 计算执行:分两种模式 • 无 eval 回调:直接 ggml_backend_graph_compute_async(split_backend, &split->graph)。• 有 eval 回调:先按节点扫描,把若干节点组成区间 graph_view执行;每段后同步并回调,允许用户中途消费/截断。• 事件记录:若当前 split 有输入拷贝,则在 split backend 上 event_record。作用:后续 copy 槽位切换或下一轮覆盖时,有明确同步点可等待。
这里的关键点在于:专家选择不是调度器决定的。
• “选哪个 expert”来自模型图里的路由计算结果( ids tensor)。• 在 compute_splits里,调度器只是读取node->src[2]这个ids tensor。• 然后根据 ids 统计“本次实际用到哪些 expert”,只拷贝这些 expert 的权重分片。
所以可以理解成两层分工:
• MoE 路由层(模型算子):产出 ids(例如每 token 命中的 expert 编号) • 调度层(scheduler):根据 ids 做“按需搬运”,不参与路由决策本身
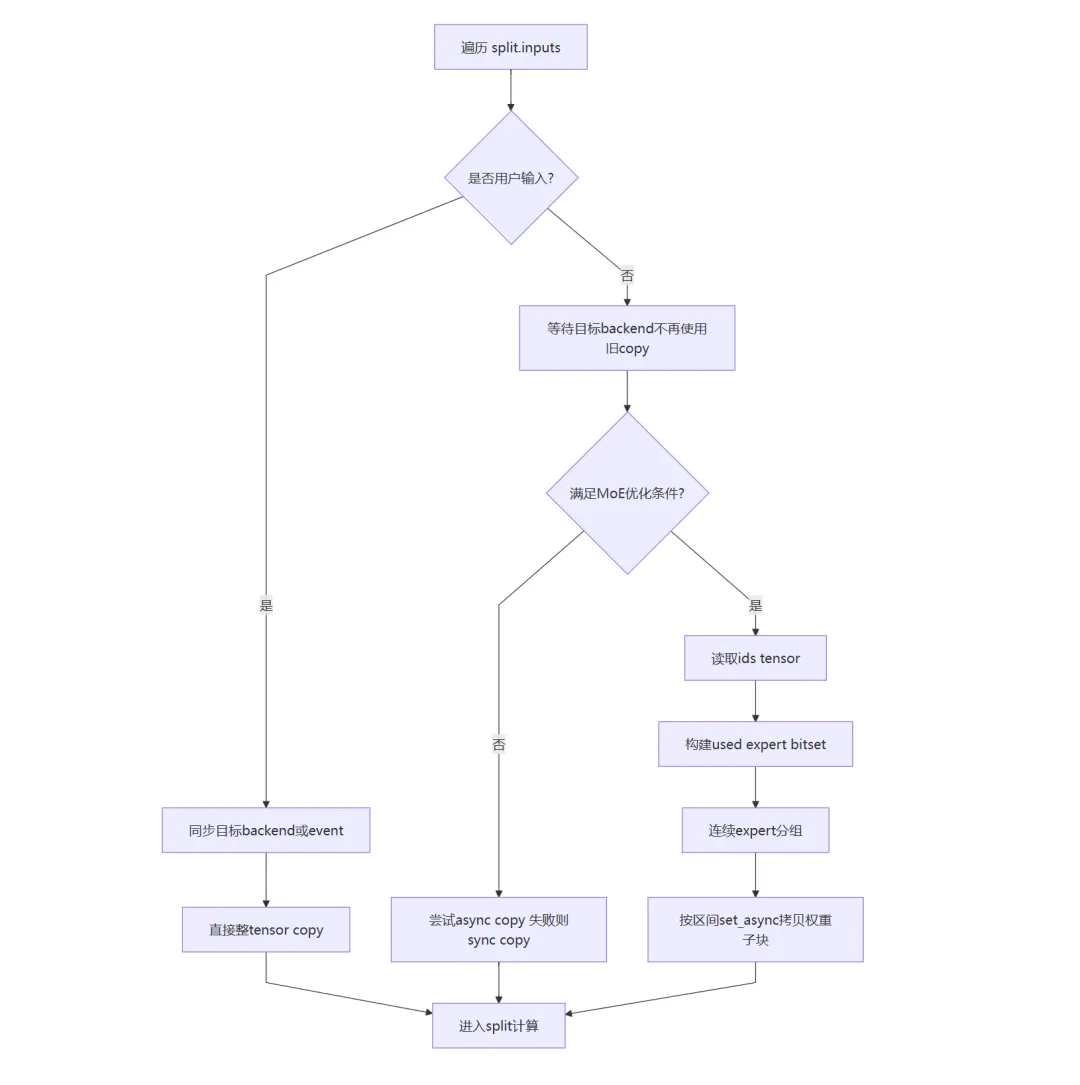
这里还是举例说明一下:
假设共有 8 个 experts(0~7),本批次 ids 里只出现:[1, 1, 4, 6, 6]
那么调度器会得到 used_ids = {1,4,6},最终只复制 experts 1/4/6 的权重块,而不是把 0~7 全部搬到目标 backend。
如果出现连续区间(比如 4,5,6),会合并成一段做批量拷贝,减少 copy 调用次数。
MoE 概述
既然讲到了 MoE,MoE(Mixture of Experts,混合专家),这里便要简单聊一聊。
传统稠密模型 (Dense Model),必须激活其绝大部分甚至全部参数来处理每一个输入(Token),这一方面导致了处理简单问题也动用庞大算力,其次模型总参数量的直接增加、线性地推高每次推理的计算成本和延迟。
混合专家模型 (MoE) 的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,可以显著扩大模型或数据集的规模。
MoE 主要由两个关键部分组成:
• 稀疏 MoE 层:MoE 层代替传统 Transformer 中 FFN 层。MoE 层包含若干“专家 Expert”,每个专家本身是一个独立的神经网络。 • 门控网络或路由:用于决定哪些 token 发送到哪个专家。例如,More 可能被发送到第二个专家 FFN2,Parameters 被发送到第一个专家 FFN1。有时,一个 token 可以被发送到多个专家 Expert。 token 的路由方式是 MoE 中一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
这里又要讲 MOE 的发展史了,三个不同版本的 MOE:
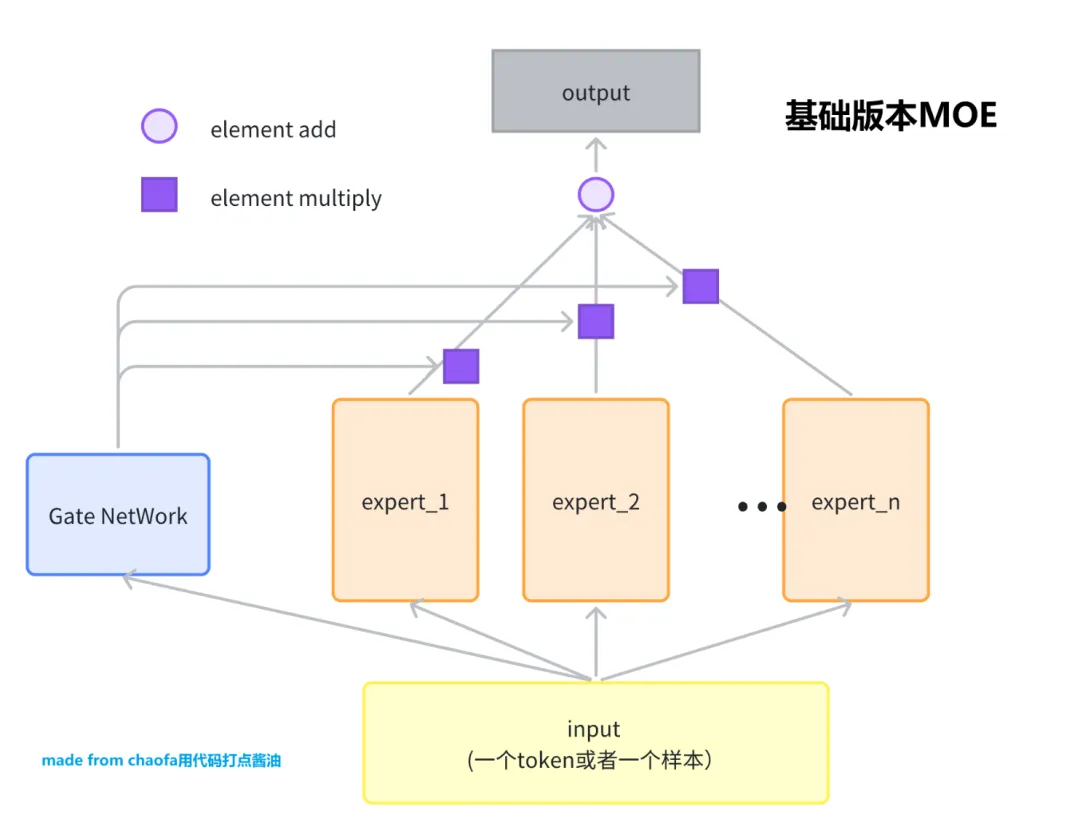
基础版 MOE(Dense MoE)
输入是一个 Token, 输出是一个 Token Embedding。暂时先不考虑 MOE 得到的 Embedding 怎么使用。
因为 MOE 网络对应着 Expert,这个 Expert 一般是一个 FeedForward Network,FFN。
基础版本的 MOE 可以看这个图,非常的简单:所有专家都参与计算,门控网络为每个专家分配一个权重。
公式:
门控网络(Gating Network):
最终输出为所有专家输出的加权求和:
其中:
• 是输入 token 的隐藏状态 • 是专家总数 • 是门控网络的可学习权重矩阵 • 是第 个专家的门控权重(所有权重之和为 1) • 是第 个专家(FFN)的输出
基础版 MOE 的问题:所有 个专家都要参与计算,计算量与专家数成正比,无法实现"参数量大但计算量小"的目标。
可以看出,ggml 中便是最基础版的 MoE。
大模型训练用的 SparseMoE(稀疏混合专家)
核心改进:每个 token 只激活 Top-K 个专家(通常 或 ),而非全部专家。这样模型可以拥有大量专家(大参数量),但每次推理只使用少量专家(低计算量)。
公式:
首先计算门控 logits 并选取 Top-K:
对 Top-K 后的结果做 Softmax 得到归一化门控权重:
最终输出(仅对被选中的 个专家求和):
其中 ,即门控分数最大的 个专家的索引集合。
其中:
• 通常取 1 或 2(如 Mixtral 8x7B 取 ,Switch Transformer 取 ) • 未被选中的专家门控权重为 0,不参与计算 • 负载均衡损失(Auxiliary Load Balancing Loss)通常被加入训练目标,防止所有 token 都路由到少数专家
DeepSeek 用的比较多的 shared_expert 的 SparseMoE(共享专家 + 路由专家)
核心改进:在稀疏路由专家的基础上,引入若干共享专家(Shared Experts),这些共享专家对所有 token 始终激活,用于捕获通用知识;而路由专家负责捕获特定领域知识。
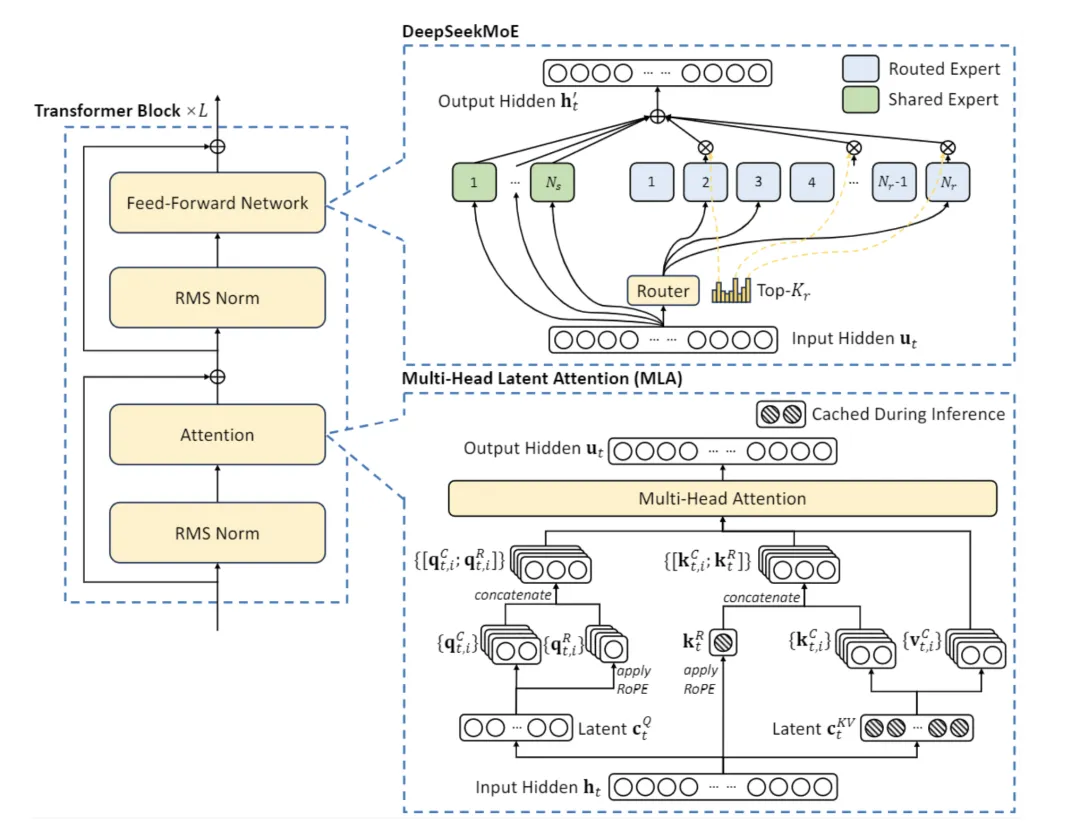
公式:
共享专家部分(始终激活,无门控):
路由专家部分(稀疏激活,与标准 SparseMoE 相同):
最终输出为两部分之和:
其中:
• 是共享专家的数量(DeepSeek-V2/V3 中通常为 1~2 个) • 是第 个共享专家,对所有 token 始终激活 • 是第 个路由专家,仅被 TopK 选中时才激活 • DeepSeek-V2 采用 , , 的配置 • DeepSeek-V3 采用 , , 的配置
共享专家的优势:
1. 减少路由专家间的知识冗余,提高专家利用率 2. 共享专家捕获通用模式,路由专家专注于特定子任务 3. 即使路由决策不完美,共享专家仍能保证基础能力
