夜雨聆风
夜雨聆风
AI 越熟,越容易平庸。
最近一年我在 AI 编程教学一线反复看到一个现象——熟练用 AI 的学员,输出反而越来越像。
不是 AI 不够强。是大多数人没意识到,AI 时代真正稀缺的不是输出,是输入。
写下这句话的时候,我刚改完一个学员群的作业。五份草稿摆在面前,主题都是「用 Claude 写一篇 AI 编程方向的公众号文章」。五个人,五份初稿,开头几乎一致——「在 AI 时代,知识工作者面临前所未有的挑战……」
不是他们不努力。每个人都老老实实把提示词四件套填齐了:角色、格式、约束、评价标准,一项不少。
问题出在更早一步。任务一进 AI,输出的天花板就已经定了。
这就是双三角要解决的问题。
双三角是什么
双三角不是我提出的概念。源头在一堂行动营提出的「AI 调研新范式」,原图(带一堂二维码)附在文末。我把它从调研工具扩展到了 AI 编程任务输入诊断这条线,一年下来,挡掉了至少一半本可以避免的返工。
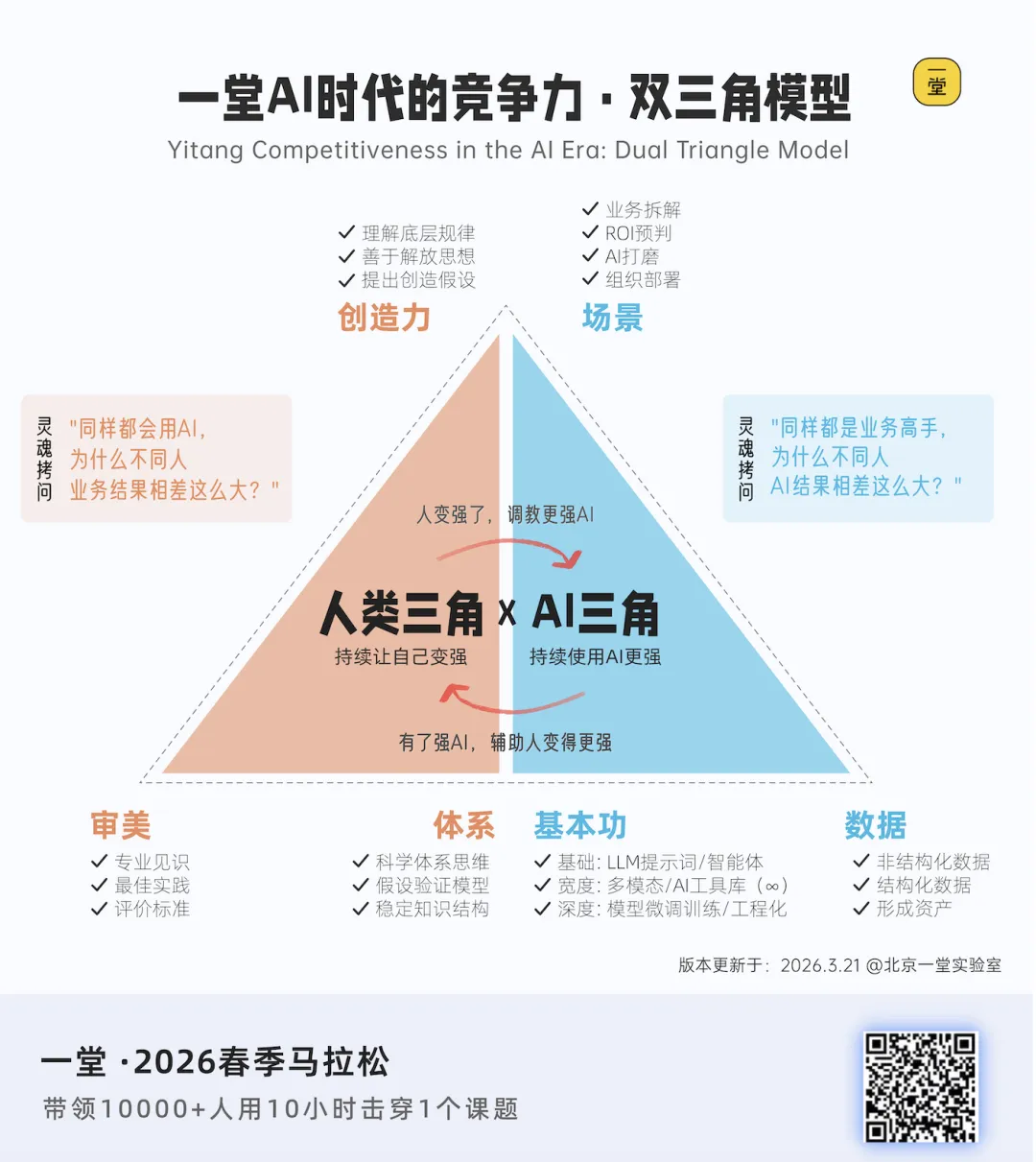
简单说,任何一个让 AI 执行的任务,输入端都有六个维度,组成两个三角。
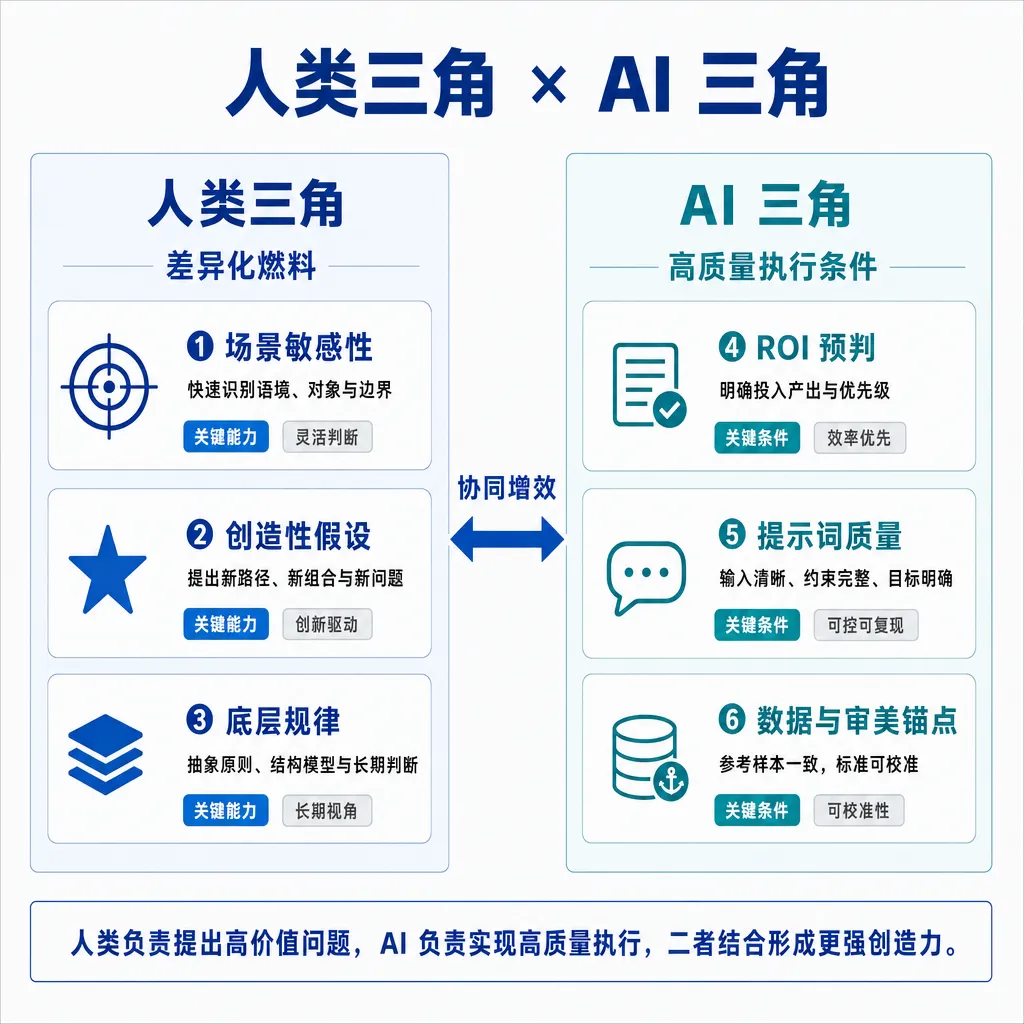
人类三角——你的差异化燃料:
① 场景敏感性——给谁看、在哪用、什么时机?
症状:任务里没有「具体的人在具体的时机做具体的事」。 例子:「写一篇 AI 工具使用技巧」(公约数)vs「写给技术总监在季度汇报会前 5 分钟速读的 AI 编程内化方法」(差异化)。 对应武器库:场景三要素、STAR 场景模型(下一篇 T2 详拆)。
② 创造性假设——你想测试什么观点、要反驳什么常识?
症状:任务里没有任何「我认为」「我想验证」「我想反驳」。 例子:「写一篇 AI 应用现状」(中立罗列)vs「测试一个反共识假设:AI 不替代人,是替代「假装在判断的人」」(差异化)。 对应武器库:WHY 追问法、反常识假设、假设验证 Q 循环(T2)。
③ 底层规律——这件事为什么有效、依赖什么前提?
症状:你能列结论,但说不出「为什么这样做就成立」。 例子:「列 5 个 RAG 最佳实践」(清单)vs「定义 RAG 在哪三个底层条件成立,缺一就崩」(结构化)。 对应武器库:第一性原理、上层规则 vs 下层规律(T2)。
AI 三角——让 AI 高质量执行的条件:
④ ROI 预判——范围多大、优先级如何?
症状:任务范围模糊,「全面分析」「详细整理」「越多越好」。 例子:「全面分析这家竞品」(5000 字废话)vs「只分析竞品在中国市场的定价策略,500 字内」(可执行)。 对应武器库:范围约束、优先级排序、多维 ROI 评估(下一篇 T3 详拆)。
⑤ 提示词质量——角色 / 格式 / 约束 / 评价标准 四件套是否齐全?
症状:四件套缺一项就废。比如缺角色,AI 默认助手口吻;缺评价标准,AI 不知道「够用」的最低线在哪。 例子:「帮我写一篇关于 RAG 的文章」(裸任务)vs「以资深 AI 编程讲师视角 / Markdown 格式 / 不超过 1500 字 / 80 分 = 反共识 + 1 案例 + 可截屏 三特征齐全」(工程化)。 对应武器库:提示词四件套对照表 + 完整可复制模板(T3)。
⑥ 数据与审美锚点——80 分长什么样、哪些方向坚决不要?
症状:你说不清「什么叫好」。「写得有趣一点」「更专业些」,AI 改了几个词反而更糟。 例子:「写好一点」(空集)vs「80 分 = 有 1 个反共识观点 + 1 个真实案例 + 一段读完想转发」(可检测)。 对应武器库:评分锚点法、正面案例库、禁止清单(T3)。
一句话定义:双三角是任务输入端的六维诊断器,决定 AI 能不能给你 80 分以上的输出。
为什么 AI 越强,你越平庸
这是这一篇真正想说的部分。三个真相,一层一层往下走。
第一个真相:AI 把执行差距抹平了。
三年前,会写代码的人和不会写代码的人,输出差一个数量级。今天,会写 prompt 的人和会写 prompt 的人,输出差不到两成——因为大家调用的是同一个底层模型。
执行端能拿到的红利,已经被压到很薄。
第二个真相:差异化只能来自输入端。
如果模型都一样,提示词模板都从同样的来源抄,那一个人和另一个人之间唯一的差距,就是给 AI 的任务本身有没有差异化。
而所谓任务的差异化,恰好对应人类三角的三件事——给谁看(场景)、想测什么观点(假设)、为什么这样做(底层规律)。
回到我开头说的五个学员的案例。
五份草稿,提示词四件套都填得很完整:「以资深内容策略师视角 / Markdown 格式 / 不超过 1500 字 / 80 分逻辑清晰,有具体案例」。
但内容大半重叠。
为什么?因为没人回答前三件事:
你的读者是 B 端学员还是 C 端开发者?(场景) 你想说 AI 替代知识工作者,还是放大知识工作者的判断力?(假设) 你认为读者真正卡在哪一步?是不会用,还是用了不出活?(底层规律)
这三件事不在任何提示词模板里,但它们决定了文章是不是有「这个人写出来的味道」。
第三个真相:大多数 AI 教学只解决了 1/6 的问题。
打开任意一篇 AI 提示词教程,几乎都在讲提示词四件套。但提示词四件套只是 AI 三角里的一维——「提示词质量」。
其他五维:场景、假设、底层规律、ROI、数据审美——基本不被提及。
提示词工程只解决了执行的精度,没解决任务的稀缺度。任务本身没差异化,再精确的执行也只能给你一份平均分的内容。
同样任务,过 vs 不过双三角的对照
我做过一个真实对照实验。
同一个任务:「写一篇 AI 编程方法论的文章」,分两组学员写。
A 组(5 人):直接写提示词四件套,开始写。 B 组(5 人):先过双三角六维,过完才写。
A 组 5 篇里有 4 篇开头高度相似,我能一眼看出是 GPT 默认风格;剩下 1 篇有些个人语气,但核心论点站不住。
B 组 5 篇全都能看出不同切入角:讲师视角、学员转型场景、Agent Team 工业化、团队培训落地、个人作品集复盘。从标题到第一段,我能一眼看出是谁写的。
差距不在文笔,差在六维过没过。
不过双三角,AI 给你公约数。过了双三角,AI 给你你的版本。
CEO + 员工的角色分工

一堂的原图里有一个特别关键的隐喻:人类是 CEO,AI 是员工。
CEO 负责四件事:审美 / 体系 / 创造力 / 价值判断。
员工负责四件事:分析 / 执行 / 调研 / 批量。
把这个映射回双三角:
人类三角的三维(场景 / 假设 / 底层规律)= CEO 的判断力 AI 三角的三维(ROI / 提示词 / 数据审美)= 员工能跑起来的条件
关键反共识来了:AI 时代要做的不是把 AI 训练得更聪明,而是把自己重新当 CEO,明确知道哪三件事 AI 做不了。
听起来像一句口号,落到实操是这样的:
AI 不能替你判断「这个选题对你的读者重要吗」——这是场景敏感性 AI 不能替你提「这个观点的反共识在哪里」——这是创造性假设 AI 不能替你回答「为什么这件事这样做有效」——这是底层规律
你越早意识到这三件事不是 AI 教程能教的,你的输出就越早脱离平均分。
我在带学员的时候,把这件事说得更直白:AI 不缺脑力,缺的是判断力。判断力来自你对场景的熟悉、对观点的胆识、对规律的追问——这三件事是 CEO 的活,外包不掉。
双三角不只是个人方法论
你以为双三角只是写提示词的个人诊断器?
我把它写进了我自己的 AI Agent Team 流水线,作为 Step 0 前置门控——任何 Agent 开工前必须过六维扫描,人类三角任一缺失就硬性阻断,连开始都不让开始。
第一年我没加这道门,按周复盘观察值,平均每周有 2-3 个 Agent 任务需要重写输入。加了之后,最近一个三个月周期里只出现 1 次同类返工。这是我自己工作流的实际计数,不是行业统计,量级供你参考。
差距不在 Agent 变聪明了——是「输入端的不能开始」省掉了「执行端的浪费」。
返工是 AI 协作里最贵的事。一次返工 = 一次人类二次输入 + 一次 AI 二次执行 + 一次结果再审查。在我的工作流里,一次返工至少耗掉半小时,多则半天,成本至少高出开工前 60 秒双三角扫描一个数量级。
双三角从个人方法论升级为工业化基建,才是它真正的价值。
如果你的工作流里只有一个人和一个 AI,双三角是诊断器。如果你的工作流里有 Agent Team、有协作伙伴、有规模化产出,双三角是「开工许可证」。
六维自检清单
下次启动一个 AI 任务之前,花 60 秒过一遍这六问。
人类三角自检:
这个任务是给谁看 / 在哪用 / 什么时机? 我想测试什么观点 / 要反驳什么常识? 这件事为什么有效 / 依赖什么前提?
AI 三角自检:
范围多大 / 优先级如何? 提示词四件套(角色 / 格式 / 约束 / 评价标准)齐了吗? 80 分长什么样 / 哪些方向坚决不要?
说实话,我自己的判断标准就这么粗暴:六维 ≥ 5 个 ✅ 才动手。不到这个标准,必须回去补输入,比启动后修改成本低十倍。
今晚就能做的 1 件事
如果你今晚要写一段 AI 提示词,做一件事:
打开你的提示词,逐项问六个问题。任意一项答不出来,先回去补,别开始。
人类三角的三个问题答不出来——你的输入没差异化价值,AI 给你的是平均分。 AI 三角的三个问题答不出来——AI 自由发挥的方向不会是你想要的。
这一招我自己用了一年,挡掉的不是返工——挡掉的是「自以为开始了,其实在浪费时间」。
如果只能记住一句话——AI 时代的稀缺资源不是算力,是你愿不愿意把任务想清楚。
下一篇 T2 拆人类三角的具体武器库:场景 / 创造性假设 / 底层规律分别有哪些可复制的工具,怎么从识别缺口到补齐缺口。再下一篇 T3 拆 AI 三角武器库:提示词四件套缺一不可,附完整可复制模板和 80 分锚点法。三篇组合是完整闭环,T1 是入口,T2 + T3 才是落地工具。
P.S. 双三角概念源自一堂行动营提出的「AI 调研新范式」,我在 AI 编程教学一线把它从调研工具扩展到了任务输入诊断。原图(带一堂二维码)附在下方,感兴趣可扫码深入了解一堂的完整体系。