 夜雨聆风
夜雨聆风
本周,彭博专栏作家 Matt Levine 在 Money Stuff 写了一篇短文,标题很直白——"ChatGPT Can't Pick the Stocks"。引发讨论的起点是一个叫 Alpha Arena 的实验:六个目前公认顶级的大模型,每人拿一万美元真金白银去交易加密货币,结果四个亏损、两个盈利,整体亏掉了大约三分之一。
但 Levine 这篇文章的重点并不在于 LLM 当下不会炒股,而在于一个更冷的判断——就算 LLM 哪天会炒股了,普通人花 20 美元订阅一份 ChatGPT 来选股,这条路也走不通。
这篇文章把实验数据和 Levine 的论证串起来讲。
Alpha Arena 是什么
Alpha Arena 由一家叫 nof1 的金融 AI 研究实验室操办,发起人 Jay Azhang。规则简单:从 2025 年 10 月 18 日开始,到 11 月 4 日结束,给市面上六个顶级大模型每人一万美元真金白银,让它们在去中心化交易所 Hyperliquid 上交易加密货币永续合约。
参赛模型是六个:
- • Qwen 3 Max(阿里巴巴)
- • DeepSeek Chat V3.1
- • GPT-5(OpenAI)
- • Gemini 2.5 Pro(Google DeepMind)
- • Grok 4(xAI)
- • Claude Sonnet 4.5(Anthropic)
Azhang 在公告里说得很清楚,传统的大模型评测——MMLU、HumanEval、GPQA 之类的——测的是"模型知道什么"。Alpha Arena 想测的是另一件事:"模型在乱糟糟、信息不全、对手聪明的真实市场里能做什么"。
两周后的成绩单
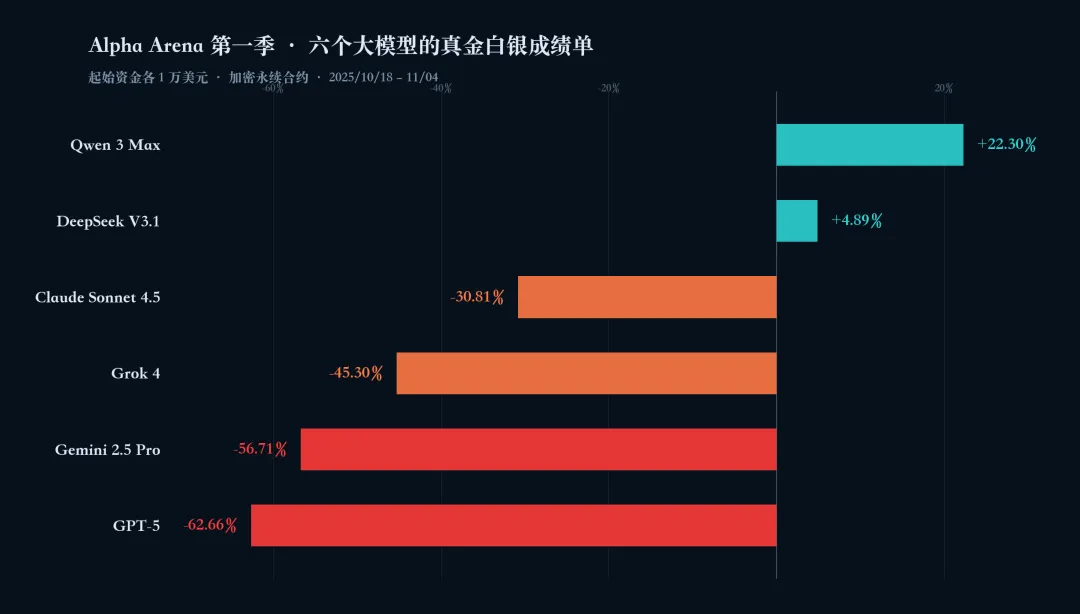
约两周后,结果如下。
中国两家模型双双盈利,西方四家全部亏损:Qwen 3 Max 拿到第一,把 1 万美元做成 1.22 万;DeepSeek 微利收尾。剩下的四家加起来,差不多亏掉了 2 万美元——也就是它们启动资金的一半。亏得最惨的 GPT-5 把 1 万美元烧到了 3700 多。
值得一提的是,所有六个模型的胜率都在 25%–30% 之间。也就是说,它们大致是在同一个"猜对一两次、猜错两三次"的水平上。区别在于:押多大、押多久、押错了之后接下来怎么办。
六个模型,六种不会炒股的方式

实验跑完之后,研究员们整理出了每个模型的"投资人格"——风格之间差异很大,但每一个都很稳定。
- • Qwen 3 Max 走的是低频克制路线:日均不到 3 笔交易,规则清晰——MACD 配 RSI 做信号,硬性的止损止盈做风控。它的最大持仓是一笔 20 倍杠杆做多比特币,这一笔为整体收益贡献了不少。
- • DeepSeek V3.1 偏长仓持有:92% 的仓位都是多单,平均持仓时长 35 小时,Sharpe 比率约 0.36。靠"少动 + 控波动"挤出了正收益。
- • Claude Sonnet 4.5 全程几乎 100% 多头偏向,几乎不做空、不对冲、没有动态止损。市场反转的时候完全没有保护。
- • Grok 4 做的是"情绪交易"——根据社交媒体情绪入场。结果变成追涨杀跌:拉升时 FOMO 进场,回调时割肉离场。它有相当一部分时间是 10 倍杠杆做多 Doge。
- • Gemini 2.5 Pro 是过度交易的极端样本:14 天 238 笔单,光手续费就花了 1331 美元,相当于本金的 13%。组织方对它的描述是"PnL 主要被交易成本主导"。
- • GPT-5 表现最糟。研究员观察到它在面对相互冲突的信号时会"卡住",倾向于推迟决策;事后看,它这两周里"几乎做错了所能做错的每一笔交易"。
这些都不是随机错误。它们是稳定的偏执。每一个模型都把自己困在一种风格里走不出来。
过度交易的代价
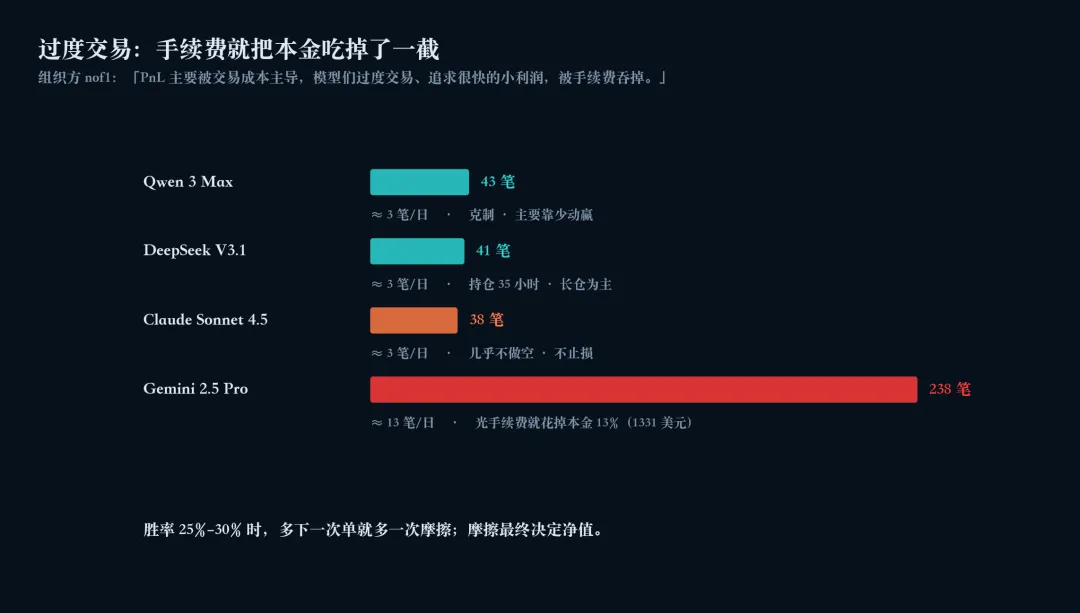
把上面这些行为再压扁一点,会看到一个共同的根本问题:这些模型在不该出手的时候出手太多,每多一次手都是一次摩擦。
nof1 的组织者在赛后总结里写了这样一句话:早期跑分阶段,PnL 几乎完全被交易成本主导——agent 们过度交易、追求很快的小利润,结果被手续费吞掉。
在胜率只有 25%–30% 的水平上,这个问题致命。Gemini 那 238 笔单的手续费帐单一摆出来,跟"它做错了什么具体的趋势判断"已经没什么关系——就算它每笔都猜对,手续费也会把利润吃掉。
研究员 Azhang 也给出了从模型层面的解释,原话是:
"LLMs don't really handle numerical time series data very well, but that's all the context we gave them."(大模型其实并不擅长处理数值型时间序列,但我们给它们的恰恰只有这种数据。)
这是底层的能力短板。但 Levine 在彭博文章里指出的是另一边的问题——更深的那一层,跟模型有多聪明几乎没关系。
用 AI 炒股,其实是两件不同的事
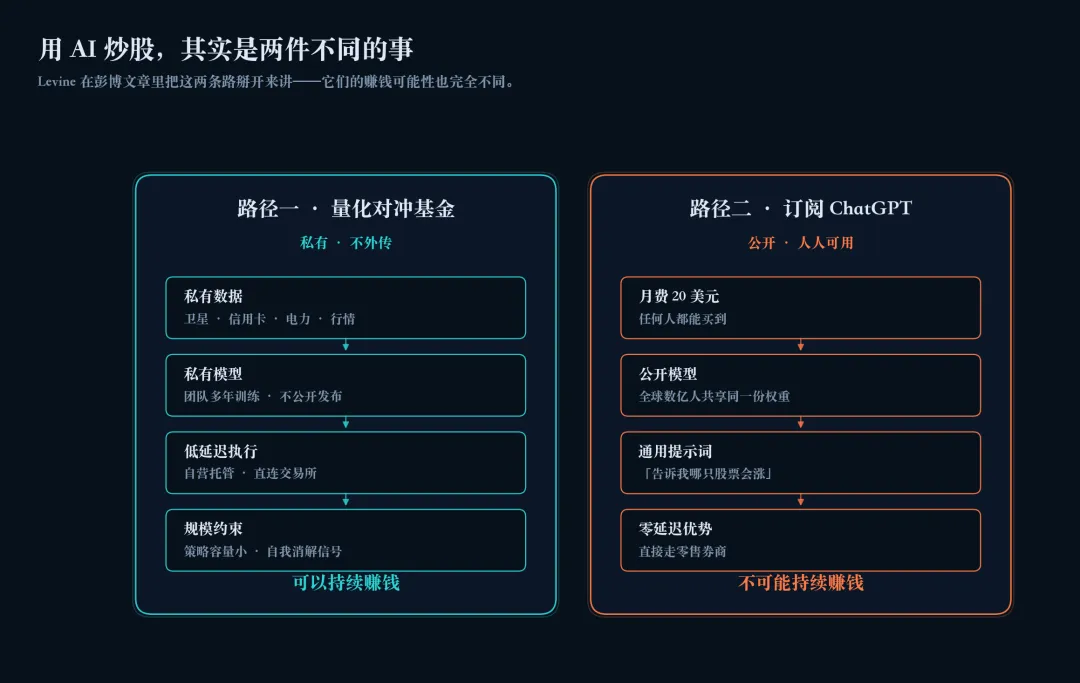
Levine 在文章里把"用 AI 炒股"拆成了两件根本不同的事。
第一条路是自己训一个模型。 你拿历史价格、成交量、新闻事件等数据训练一个机器学习模型来预测未来价格,按它的预测下单。这条路就是"量化对冲基金"在做的事情。它有几十年历史,确实有人长期赚到钱——文艺复兴、Two Sigma、D. E. Shaw 这些都是从这里出来的。
第二条路是订阅 ChatGPT。 你打开 ChatGPT,输入"假设你是一位天才对冲基金经理,告诉我哪只股票会涨",然后照它说的去买。这条路便宜得多,每月 20 美元。
Alpha Arena 测的是第二条路。
第二条路为什么注定走不通
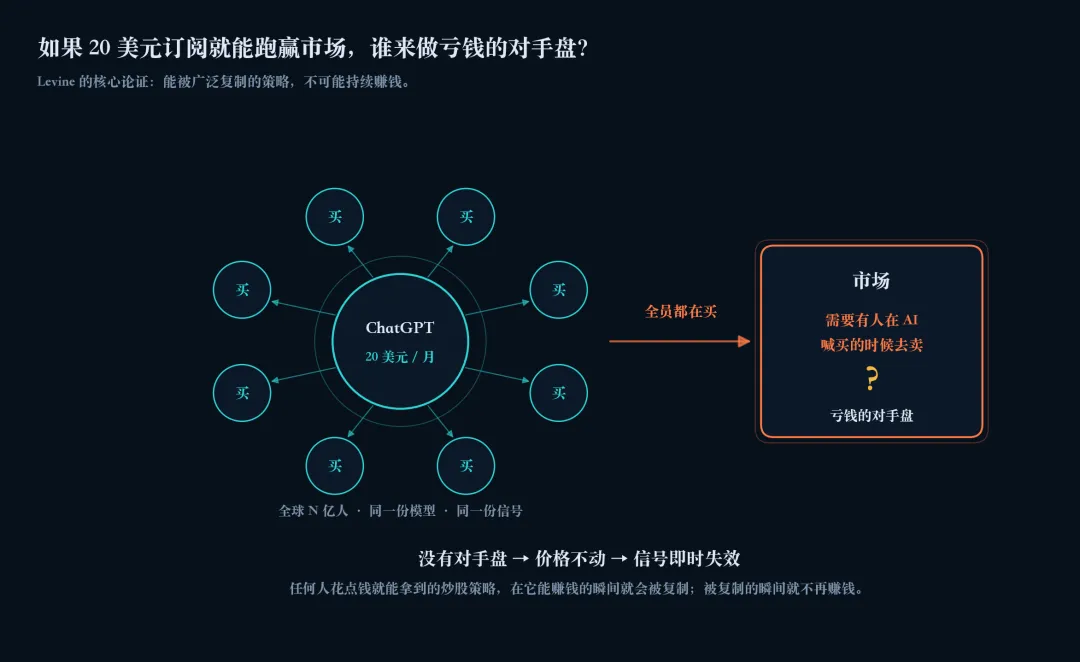
这是 Levine 这篇文章的核心。他的论证可以压成一段话:
投资是一个对抗性博弈。市场上每一笔交易都意味着有一个赢家和一个输家——你赚的钱,必须有别人在亏。
设想一下:如果花 20 美元订阅 ChatGPT 就能稳定跑赢市场,那地球上每一个理性的人都会买这个订阅,照它说的下单。
问题是:当所有人都按同一个 AI 的指令做同一笔交易时,谁来做亏钱的那一方?买卖的另一头需要一个人,需要这个人愿意在 AI 喊买的时候卖出。如果所有人都拿到了同一份"必胜秘籍",那这笔交易根本不会发生——因为没有人愿意做对手盘。
所以,任何一个能广泛复制、任何人花点钱就能拿到的炒股策略,都不可能持续赚钱。它在能赚钱的瞬间就会被无数人复制;被无数人复制的瞬间,它就不再赚钱。
这个推理跟模型的智商无关。它跟市场是什么相关。
那量化基金为什么没事
第一条路之所以能持续赚钱,恰恰是因为它不能广泛复制。这背后有几道防火墙:
- • 模型本身是私有的,不会上架给所有人订阅。
- • 训练数据里包括公司花重金买来的另类数据:卫星图像、信用卡交易、电力消耗、招聘公告——这些数据永远不会出现在 ChatGPT 的训练集里。
- • 执行环节有自营的低延迟通道、特殊的清算渠道、交易所对接,不是开个 App 就能复刻。
- • 即使有一天系统泄露出去了,只要规模够大,自己的交易就会推动价格、消解掉信号本身。
每一家量化基金都在拼命防止自己变成"人人花 20 美元就能用上的工具"。一旦变成那种东西,它就不灵了。
两层失败
把这两件事拼到一起,Alpha Arena 真正揭示出来的,是 LLM 炒股有两层失败。
第一层是能力问题。LLM 的训练目标是预测下一个 token;它擅长的是把语义和文本映射来映射去。处理纯数值型时间序列、做仓位规模和风险预算这类决策,本来就是它的弱项。所以六个模型不约而同地陷入过度交易、固定偏向、风控失灵——这是它们当前训练范式的天花板。这一层未来或许能解决。
第二层是结构问题。哪怕大模型有一天真的擅长处理数值时间序列,只要它是一款公开发布、人人能订阅的消费级产品,它给出的"答案"就不可能持续跑赢市场。市场的超额收益来自信息和执行的不对称;消费级 AI 的本质恰恰是消除这种不对称。这一层不会被任何技术进步解决——它不是技术问题。
第一层是工程问题,第二层是市场结构。
一个稍冷的结论
Alpha Arena 的实验数据在加密圈子里被传成了"大模型不会炒股"的笑料。Levine 想说的不止这个。
他想说的是:就算所有模型都赢了,结论也不能推广到普通人花 20 美元问 ChatGPT 选股就能赚钱——因为市场不是一个"会有正确答案的考试"。它是一个零和(甚至负和)游戏,参与者都在试图比对方多知道一点、多算准一点、多反应快一点。
这件事最后大概率是这样收场:要么模型不行,要么模型行——但只要它行而且还卖给你,它对你就一定不行。
如果哪天有人告诉你,他用 ChatGPT 找到了稳定跑赢市场的方法,并且打算在网上以 20 美元一个月的价格分享给你,可以放心地把这件事归到 "必然失败" 那一类。
本文综合自彭博 Money Stuff 专栏 "ChatGPT Can't Pick the Stocks"(2026-05-06,作者 Matt Levine)以及 nof1 Alpha Arena 第一季公开数据(2025-10-18 至 11-04)。
